






 本文介绍了Java操作数据库时关于自增主键的使用,包括自增主键的插入规则和删除后的自增情况。此外,还讲解了数据库的`desc`命令、外键约束的概念及其在数据删除时的注意事项,以及数据库设计中的三范式。最后,探讨了数据库的CURD进阶操作,如一次性插入多条记录、聚合函数和分组查询的使用。
本文介绍了Java操作数据库时关于自增主键的使用,包括自增主键的插入规则和删除后的自增情况。此外,还讲解了数据库的`desc`命令、外键约束的概念及其在数据删除时的注意事项,以及数据库设计中的三范式。最后,探讨了数据库的CURD进阶操作,如一次性插入多条记录、聚合函数和分组查询的使用。
目录
1). 自增主键可以 显示的插入null或者不写,都会触发自增操作
上集回顾


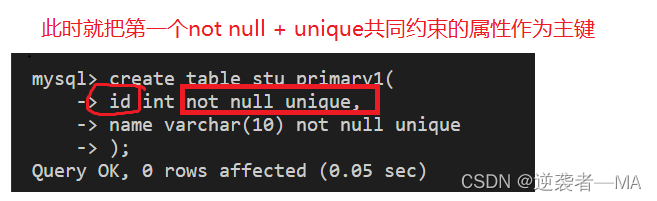
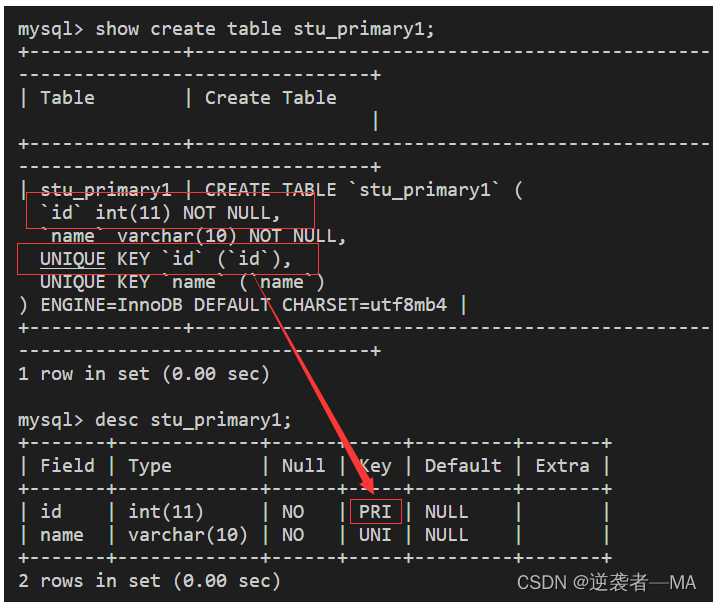 此时就把第一个not null + unique共同约束的属性作为主键
此时就把第一个not null + unique共同约束的属性作为主键
在这里就是id属性
d.自增主键 auto_increment
因为主键不重复且不为空,一般来说作为主键的列都是 int或者 定长的char类型
因此我们可以将主键的增长交给数据库自动执行
注释:这样做会提高被主键约束属性的效率
放在主键 primary key 后面修饰即可。
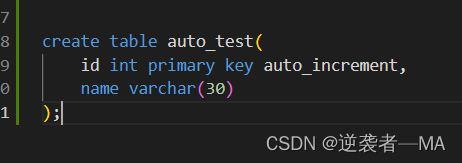
1). 自增主键可以 显示的插入null或者不写,都会触发自增操作
insert into auto_test(name) values('李云龙');
这语句我们只插入名称,不插入id
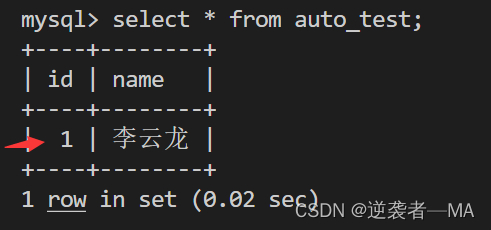
默认从 1 开始自增
insert into auto_test(id, name) values(null, '赵刚');
主动插入null,且看看自增操作id
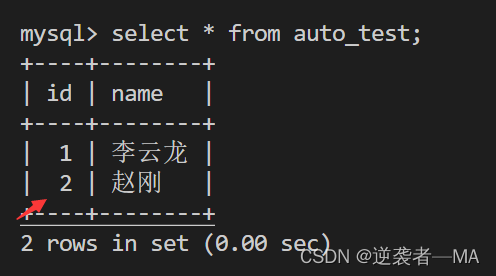
主动变成了 2
2).关于自增主键删除后的自增情况
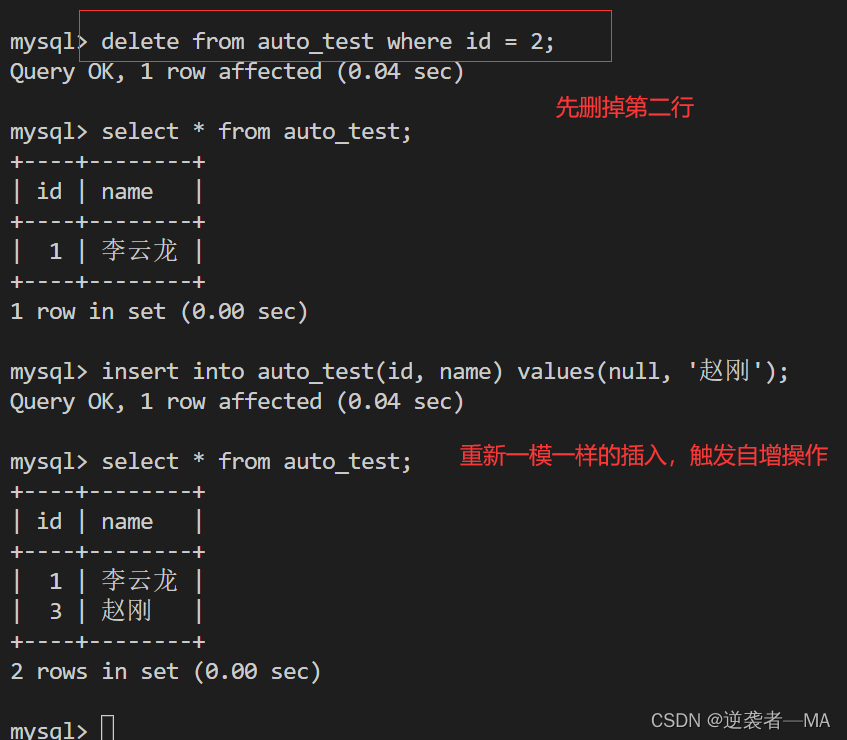
发现自增的结果不是原来的 2,而是变成 3 了
insert into auto_test(id, name) values(null, '楚云飞'); 再次插入看编号
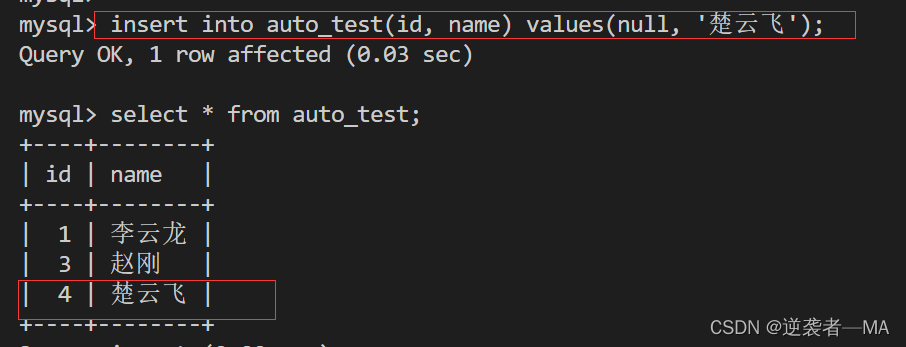
发现从表中最大的 3 变成了 4
结论:自增主键是以已经出现过的数字最大值+1
如果我现在主动输入编号插入 100,那么下次自增主键被触发时就会变成 101
注释:就算你把记录删了,操作系统里面会有记录你当前出现过的最大值
原因:delete 删除后的主键,下次再自增时是以出现过的最大值作为基准来自增!!
truncate删除表数据后自增主键的情况,truncate之后,会还原自增主键的值
delete删除后的数据还有恢复的可能,truncate删除是就文件所有数据全部清空!
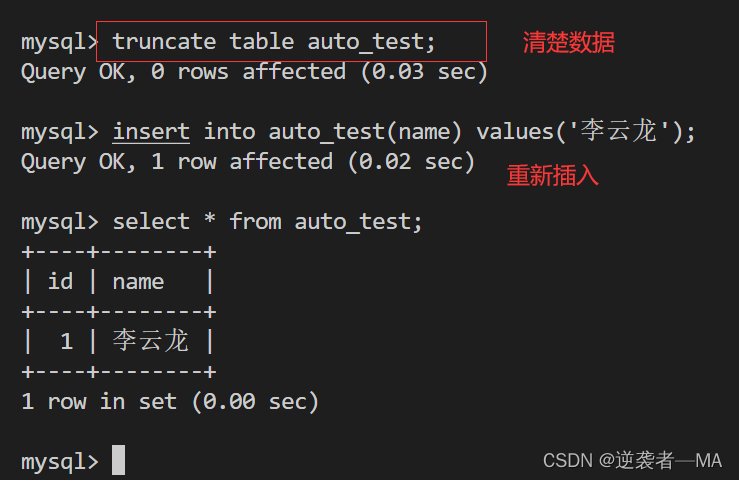
又恢复从 1 开始自增
小知识:` desc `
在设计表属性的时候,当用关键字作为属性的名称时, 用 ` ` 括起来
注释:是英文状态下的 波浪键 Tab键上面有个
外键约束
涉及多个表之间的关联约束
外键用于关联其他表的主键或唯一键,语法:
foreign key (当前表中的哪的属性) references 主表(列-关联属性)
比如:当前有一个学生表,还有一个班级表,学生表中有一列属性为该学生的班级信息,也就是记录你这个学生是哪个班级的。
如果有一天你在学校里面闯了祸,被教导主任抓着时,教导主任就会先问你是哪个班的?
你说:我是高二(三班)的,叫张飞,结果教导主任一查这个班级,根本就没这个人,就知道你小子肯定在说谎骗人!
如果他正确在你说的班级里找到了你的名字,那么他是先通过班级这个表中先找到你,然后对应编号找到你的学生表,里面有你全部的个人信息。
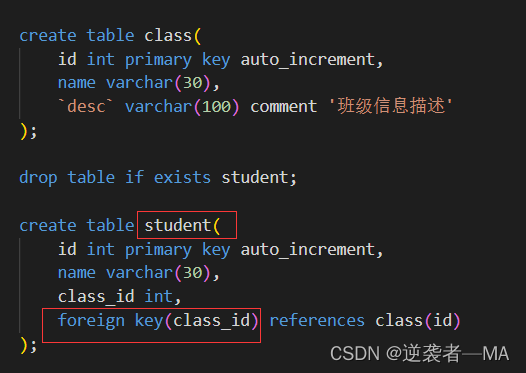
学生表中class_id关联class表的id属性
学生表插入数据时,class_id要能正确插入,必须在class表中id值存在的~~
换句话说,这个学生填写的班级必须要存在才能入这个班吧。
insert into student(name, class_id) values('李云龙', 1);
在主表中不存在 1 这个id编号时,我们对学生表插入信息

直接就报错了
现在先给班级表中插入一个班级及信息
insert into class(name, `desc`) values('银河火箭班', '只培养特殊人才');
然后再重新插入,发现就能成功插入id为 1 的班级了
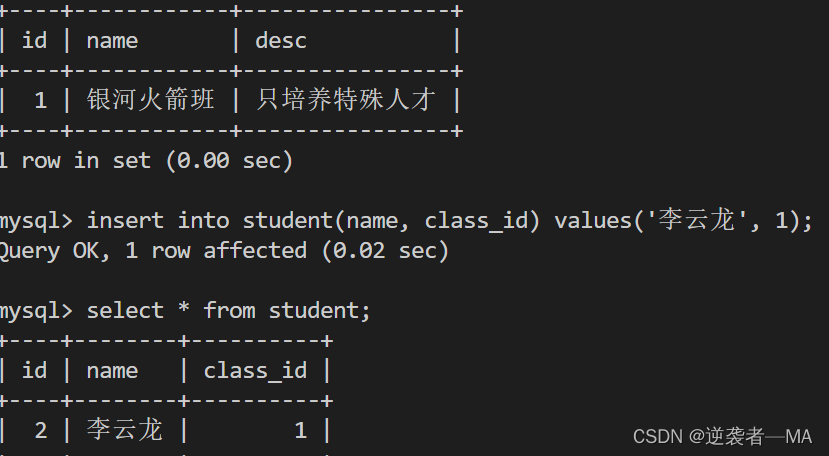
发现,此时学生表的自增主键居然不是从 1 开始的
原因:自增主键的性质,就算是插入失败,它也会增加一次,就是在原来最大值基础上 + 1 。
举例:先失败插入两次,再正确插入。
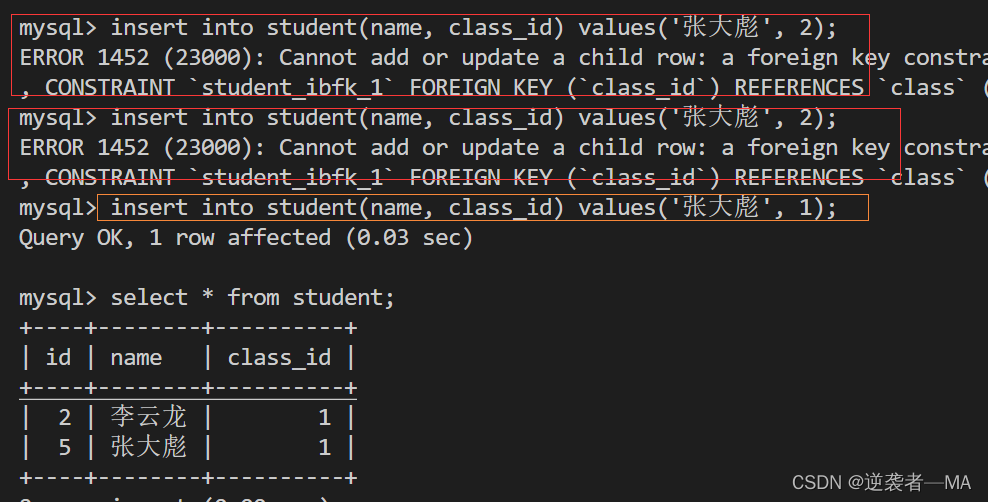
本来应该是3的,现在却是 5
删除的注意事项
在student从表中有信息记录关联到了主表class的id为1的这一行,若要删除主表class的id行,必须确保所有从表中关联的数据先删除
插入时,先看主表,主表中有这个属性值才能在从表中插入
删除时,先看从表,从表中该属性值关联的所有记录都删除之后才能在主表中删除。
举例:班级 和 学生
如果把班级比作一个房间的话,那么学生想要入这个班级(房间),那么总得要先存着这个班级才能去入吧。
如果清空一个班级(房子)做别的用,那么肯定要先驱散班级里面的学生吧
表的设计:(数据库三范式)
实体(表)间的四种关系
1. 一对一
2. 一对多
3. 多对多
4. 没关系
一对一的两个属性一般都可以放在一张表中
如:学生和学号关系都放在学生表中,姓名和身份证号的关系都放在公民信息表中
一对多:一个同学只能在一个班级,一个班级可以包含多个同学
学生和班级就属于一(班级)对多(学生)的关系。
一对多创建表时的方式:

多对多︰学生和课程的关系,一个学生可以选择多个课程,一个课程也可以同时被多个学生选择
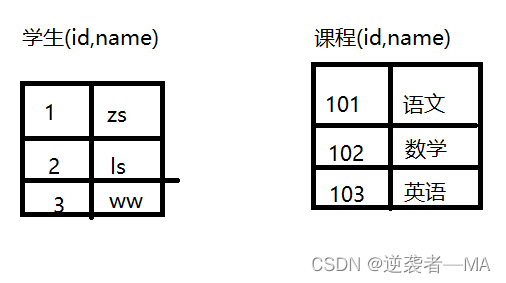
这种情况下该怎么办?
解决:再创建出一个临时表来记录。
多对多的关系——创建一个学生 和 课程 中间表来记录多对多的关系

第一范式:确保每列的原子性(设计表时,每一列都不能再次分解)
第二范式:当前表中所有属性都和主键相关
第三范式:表中所有属性都和主键直接相关而不是间接相关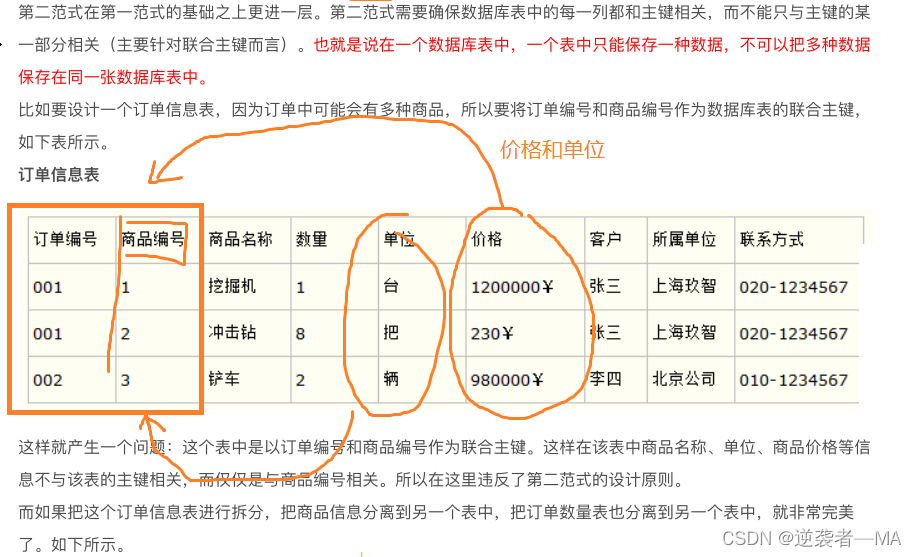
某些属性和主键不相关时,需要拆分表。让拆分后的表都和主键相关

三范式了解即可

CURD进阶
1.根据查询结果一次性插入多条记录
insert into tb_name(属性) select ...
根据select结果集插入表中数据,select出的属性要和插入的属性——对应。
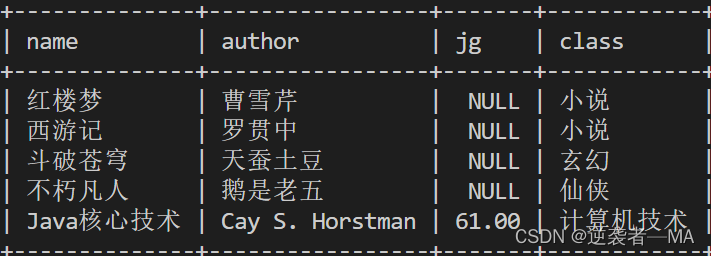
举例:比如我打算创建一个新表,想往这个表里面插入已经存在表中的书名称和作者
1. 先创建表,
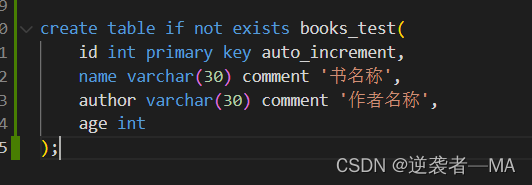
注释:当然可以给这个表中创建更多的属性,却只插入 这两个属性,这里只是为了方便
2. 再给这个表中插入name和作者,从books表中获取,且不为空的数据
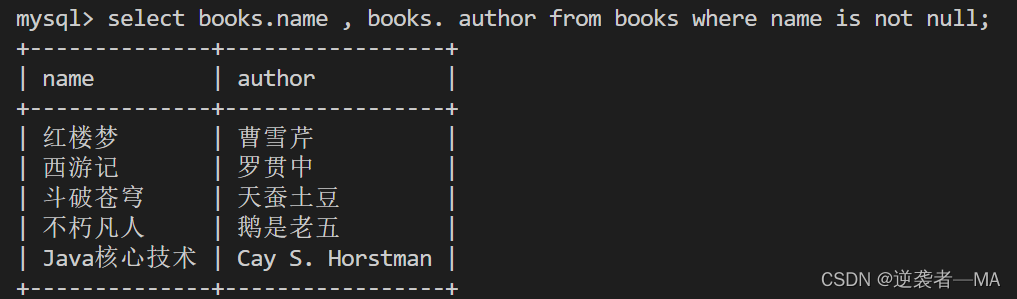
先查询看看要插入的数据
select books.name , books. author from books where name is not null;
给新表中插入
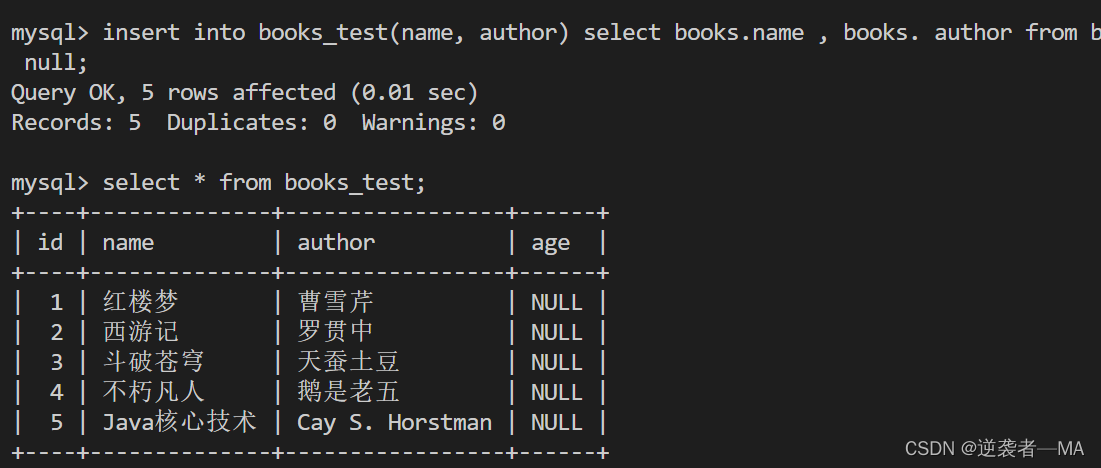
insert into books_test(name, author) select books.name , books. author from books where name is not null;
插入成功
2.聚合函数
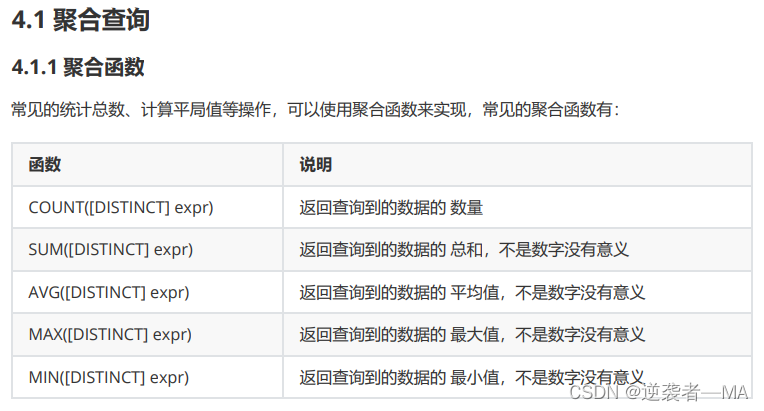
计算,求和,平均值,最大值,最小值。
聚合查询指的是把行之间的数据进行聚合,和列无关
使用最下面四个函数都必须传入数值属性不然没有意义
1).count(*)相当于select(*)效率比较低,全表扫描,统计总行
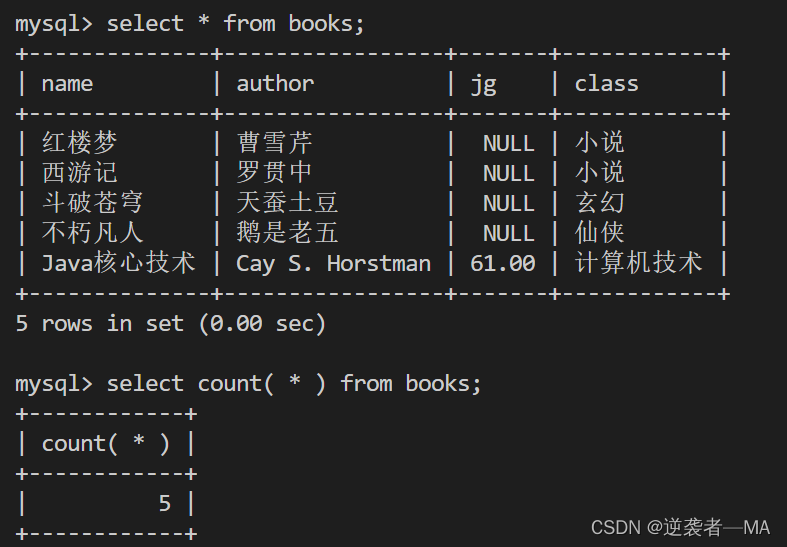
2).coun(属性),去除所有null的结果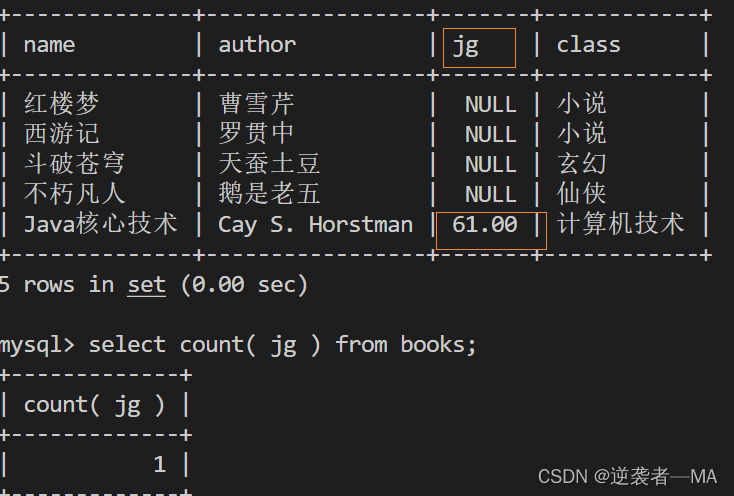
去除所有值为null的行,只统计不为null个数
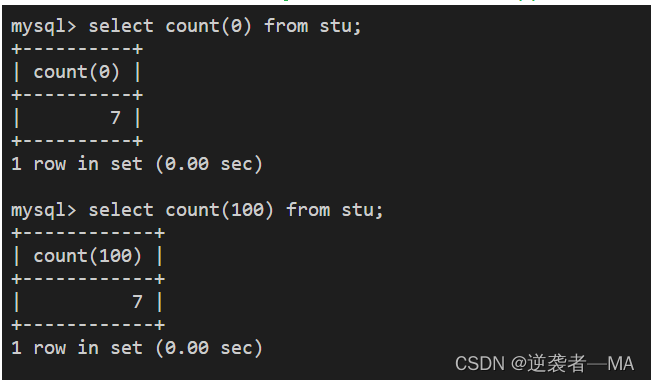
3).count(任意数值)
效果等同于count(*),相当于在临时表中创建了一列属性,值都是count(数值),统计一下当前表中有多少行,速度比count(*)快,会使用索引
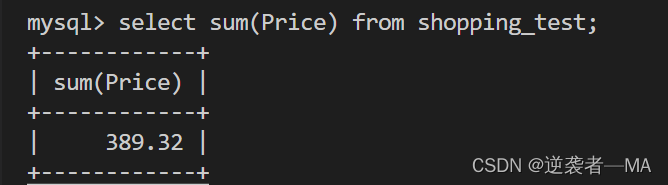
sum函数使用
查询每个电脑都买一台需要多少钱
根据聚合函数得到的属性可以起 别名as
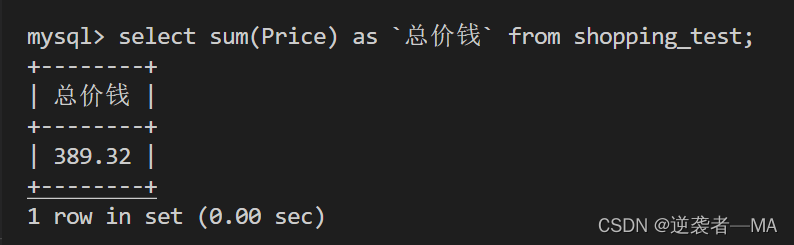
注释:别名称 必须用 ` ` 符合括起来
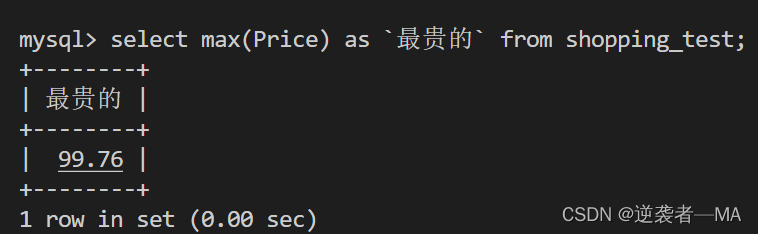
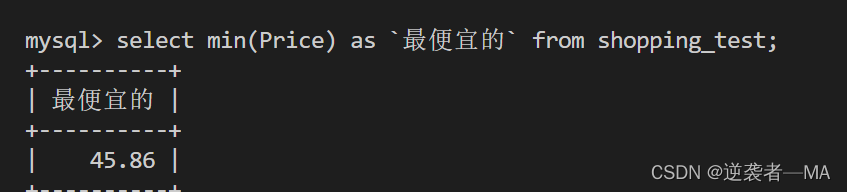
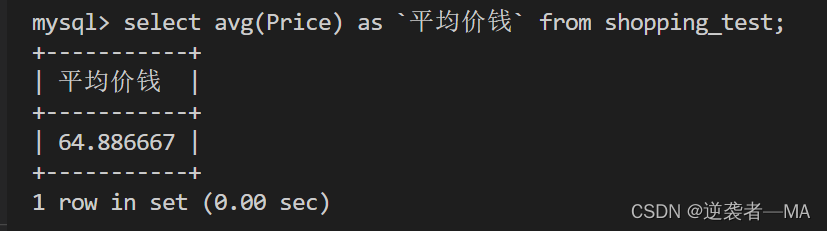
max 和 min 和 avg同理
查询最贵的电脑
查询最便宜的电脑
查询所用电脑的平均价
group by子句
—般聚合函数搭配group by 分组查询使用
select使用group by可以对指定查询的列进行分组。
1.统计每种笔记本类型的平均价钱 =》需要根据查询出来的结果按照笔记本类型进行分组
select spms, avg(Price) from shopping_test group by spms;
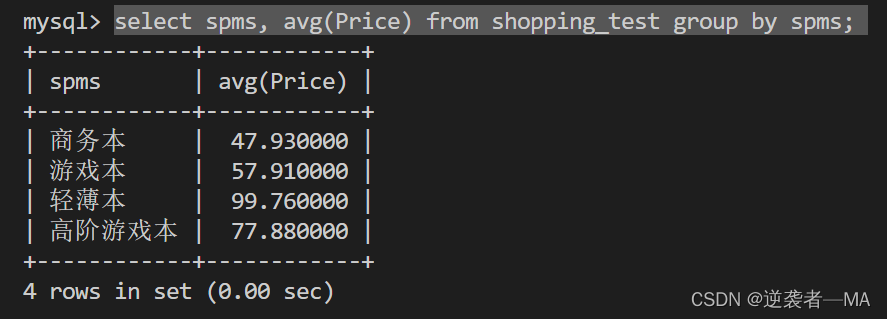
先按照spms进行分组,分组之后使用avg进行求平均值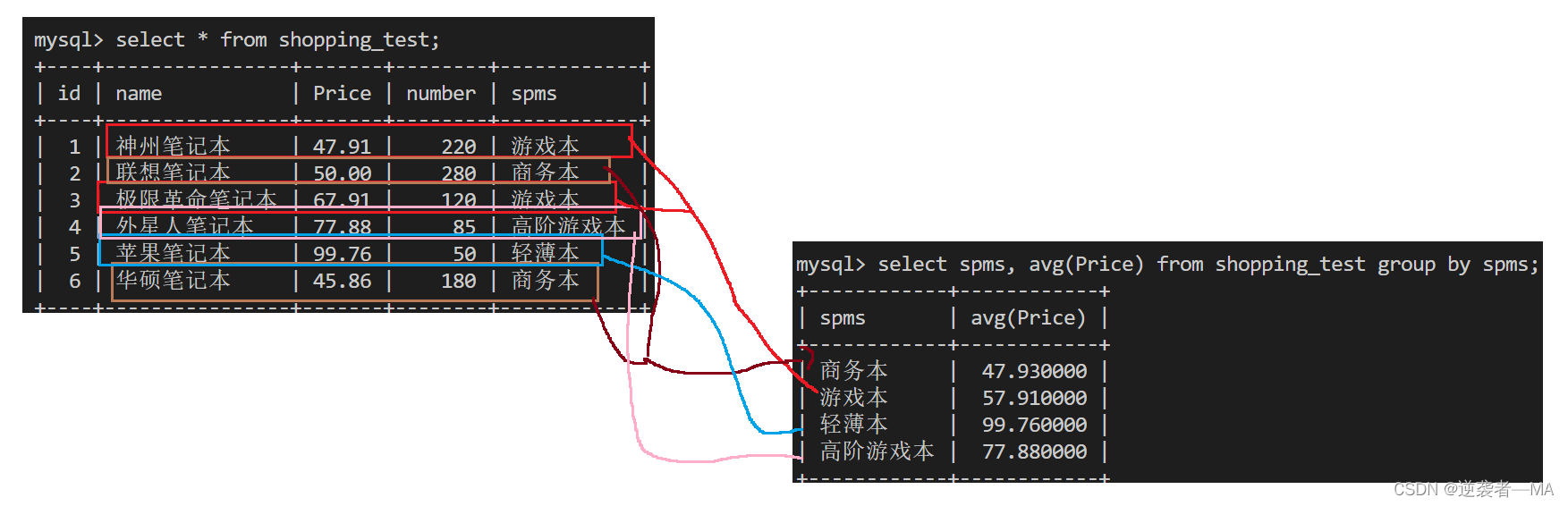
group by能否使用select中的别名?
可以,因为是先得得到临时表才聚合
查询每种类型的电脑的最大值和最低值
select spms as `电脑类型` ,max(Price), min(Price) from shopping_test group by spms;
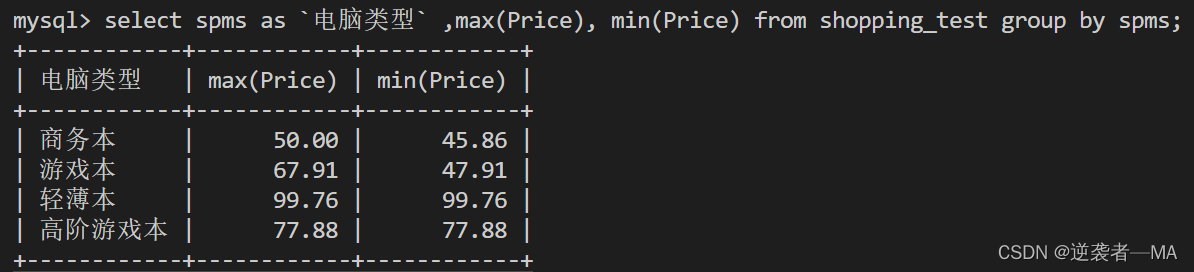
先得得到临时表才聚合
having 关键字
分组之后进行条件查询必须使用having
having :必须是聚合函数的条件
having 和group by搭配使用,聚合后的条件过滤使用)
举例:统计所有类型电脑的平均价钱,保留价钱 > 60的记录
select spms ,avg(Price) from shopping_test group by spms having avg(Price) > 60;
having就是在按条件聚合后再次进行条件筛选
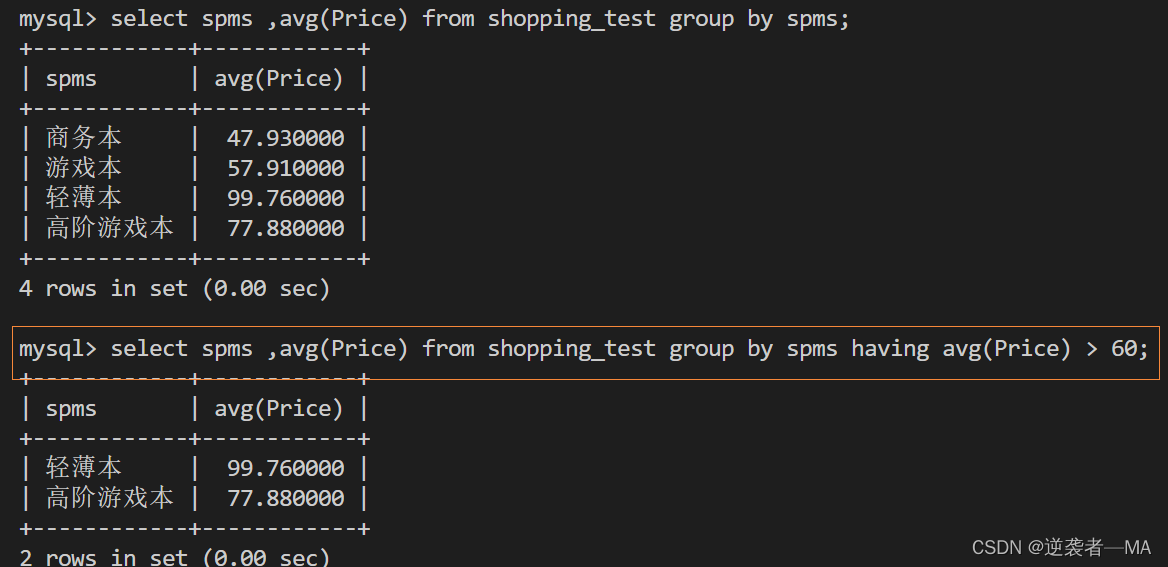
group by语句不是不能用where,是不能在聚合之后使用where
结论:
聚合之前的条件使用where
聚合之后的条件使用having
统计所有类型电脑的平均价钱,去除name = 苹果笔记本,保留平均薪资>60的记录
先where筛选取到 name = 苹果笔记本 ,再聚合group by求各类型的平均值,最后having筛选 》 60 的记录
select spms ,avg(Price) from shopping_test where name != '苹果笔记本' group by spms having avg(Price)>60;
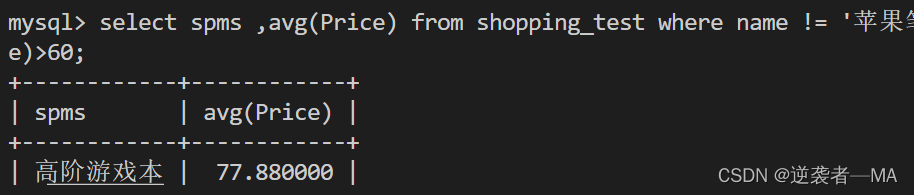
注释:having的条件—定是分组后的聚合函数过滤

















 3261
3261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









