







动态规划算法和分治算法类似,都是通过先求解子问题的解,再从子问题解中得到目标问题的解。基于动态规划算法的强化学习方法有两种:策略迭代和价值迭代。下面我们通过悬崖漫步问题来学习一下这两个算法。
问题定义
一个智能体从起点出发,避开悬崖行走,最终走到终点。
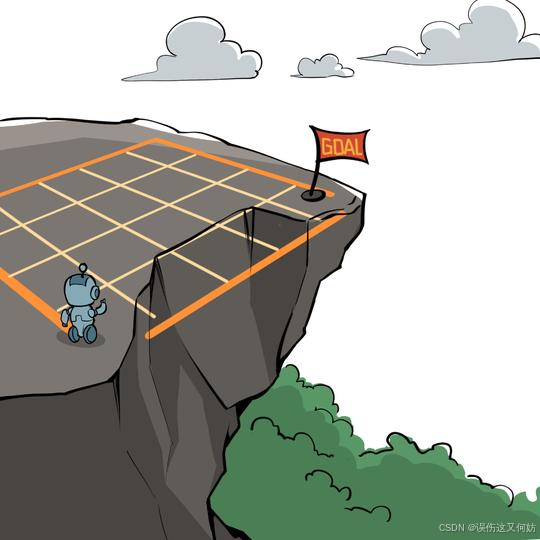
如图所示,智能体的起点是左下角,终点是左上角,我们的目标是避开悬崖走到中断。智能体可以采取的行动有4种:上、下、左、右。如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。智能体每走一步的奖励是 −1,掉入悬崖的奖励是 −100。
import copy
class CliffWalkingEnv:
""" 悬崖漫步环境"""
def __init__(self, ncol=12, nrow=4):
self.ncol = ncol # 定义网格世界的列
self.nrow = nrow # 定义网格世界的行
# 转移矩阵P[state][action] = [(p, next_state, reward, done)]包含下一个状态和奖励
self.P = self.createP()
def createP(self):
# 初始化
P = [[[] for j in range(4)] for i in range(self.nrow * self.ncol)]
# 4种动作, change[0]:上,change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# 定义在左上角
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
for i in range(self.nrow):
for j in range(self.ncol):
for a in range(4):
# 位置在悬崖或者目标状态,因为无法继续交互,任何动作奖励都为0
if i == self.nrow - 1 and j > 0:
P[i * self.ncol + j][a] = [(1, i * self.ncol + j, 0,
True)]
continue
# 其他位置
next_x = min(self.ncol - 1, max(0, j + change[a][0]))
next_y = min(self.nrow - 1, max(0, i + change[a][1]))
next_state = next_y * self.ncol + next_x
reward = -1
done = False
# 下一个位置在悬崖或者终点
if next_y == self.nrow - 1 and next_x > 0:
done = True
if next_x != self.ncol - 1: # 下一个位置在悬崖
reward = -100
P[i * self.ncol + j][a] = [(1, next_state, reward, done)]
return P
策略迭代算法
策略迭代的基本思想是不存在一个策略 π ′ \pi' π′ 的状态价值 V π ′ ( s ) V^{\pi'}(s) Vπ′(s),优于策略 π ∗ \pi^* π∗ 的状态价值 V π ∗ ( s ) V^{\pi^*}(s) Vπ∗(s)
回顾一下之前学习过的贝尔曼期望方程
V
π
(
s
)
=
π
(
a
∣
s
)
(
R
(
s
,
a
)
+
γ
∑
a
p
(
s
′
∣
s
,
a
)
V
π
(
s
′
)
)
V^\pi(s) = \pi(a|s)(R(s, a) + \gamma \sum_ap(s'|s, a)V^\pi(s'))
Vπ(s)=π(a∣s)(R(s,a)+γa∑p(s′∣s,a)Vπ(s′))
在迭代若干次后一定存在一个贝尔曼期望方程的不动点,使得
V
k
+
1
(
s
)
=
π
(
a
∣
s
)
(
R
(
s
,
a
)
+
γ
∑
a
p
(
s
′
∣
s
,
a
)
V
k
(
s
′
)
)
V^{k+1}(s) = \pi(a|s)(R(s, a) + \gamma \sum_ap(s'|s, a)V^{k}(s'))
Vk+1(s)=π(a∣s)(R(s,a)+γa∑p(s′∣s,a)Vk(s′))
也就是说迭代收敛了,这个时候我们就得到了在该策略 π \pi π 下的状态价值函数 V π ( s ) V^\pi(s) Vπ(s)
策略提升
假设存在一个策略
π
′
\pi'
π′, 在任意状态下都满足
Q
(
s
,
π
′
(
s
)
)
≥
V
π
(
s
)
Q(s,\pi'(s)) \geq V^\pi(s)
Q(s,π′(s))≥Vπ(s)
也就是
V
π
′
(
s
)
≥
V
π
(
s
)
V^{\pi'}(s) \geq V^\pi(s)
Vπ′(s)≥Vπ(s)
这种情况下,我们就可以贪心地选择动作价值最大的动作。
π
′
(
s
)
=
arg max
a
Q
π
(
s
,
a
)
=
arg max
a
r
(
s
,
a
)
+
γ
∑
s
′
P
(
s
′
∣
s
,
a
)
V
π
(
s
′
)
\begin{aligned} \pi'(s) &= \argmax_aQ^\pi(s, a) \\ &=\argmax_a r(s, a) + \gamma\sum_{s'}P(s'|s, a)V^\pi(s') \end{aligned}
π′(s)=aargmaxQπ(s,a)=aargmaxr(s,a)+γs′∑P(s′∣s,a)Vπ(s′)
策略迭代算法

class PolicyIteration:
def __init__(self, env, theta, gamma):
self.env = env
self.v = [0] * self.env.ncol * self.env.nrow
self.pi = [[0.25, 0.25, 0.25, 0.25] for i in range(self.env.ncol * self.env.nrow)]
self.theta = theta
self.gamma = gamma
def policy_evaluation(self):
cnt = 1
while 1:
max_diff = 0
new_v = [0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol * self.env.nrow):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(self.pi[s][a] * qsa)
new_v[s] = sum(qsa_list)
max_diff = max(max_diff, abs(new_v[s]-self.v[s]))
self.v = new_v
if max_diff < self.theta :break
cnt += 1
print("Policy Evaluation Finished After %d Counts"% cnt)
def policy_improvement(self):
for s in range(self.env.nrow * self.env.ncol):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
maxq = max(qsa_list)
cntq = qsa_list.count(maxq)
self.pi[s] = [1 / cntq if q == maxq else 0 for q in qsa_list]
print("Policy Improvement Finished")
return self.pi
def policy_iteration(self): # 策略迭代
while 1:
self.policy_evaluation()
old_pi = copy.deepcopy(self.pi) # 将列表进行深拷贝,方便接下来进行比较
new_pi = self.policy_improvement()
if old_pi == new_pi: break
价值迭代算法
相信大家已经看出来了,在进行策略迭代时,需要先得到状态价值函数再进行策略提升。但是这进行很多轮才能收敛得到某一策略的状态函数,这需要很大的计算量。
我们是否必须要完全等到策略评估完成后再进行策略提升呢?价值迭代算法就是这种策略,只在策略评估中进行一轮价值更新,然后直接根据更新后的价值进行策略提升。
价值迭代算法利用的是贝尔曼最优方程:
V
π
∗
(
s
)
=
max
a
{
R
(
s
,
a
)
+
γ
∑
a
p
(
s
′
∣
s
,
a
)
V
π
∗
(
s
′
)
}
V^{\pi^*}(s) =\max_a \{R(s, a) + \gamma \sum_ap(s'|s, a)V^{\pi^*}(s')\}
Vπ∗(s)=amax{R(s,a)+γa∑p(s′∣s,a)Vπ∗(s′)}
将其写成迭代形式
V
k
+
1
(
s
)
=
max
a
{
R
(
s
,
a
)
+
γ
∑
a
p
(
s
′
∣
s
,
a
)
V
k
(
s
′
)
}
V^{k+1}(s) =\max_a \{R(s, a) + \gamma \sum_ap(s'|s, a)V^{k}(s')\}
Vk+1(s)=amax{R(s,a)+γa∑p(s′∣s,a)Vk(s′)}
当迭代收敛时,我们就得到了最优策略
π
∗
\pi^*
π∗ 对应的状态价值函数,之后恢复出最优策略
π
∗
\pi^*
π∗
π
∗
(
s
)
=
arg max
a
r
(
s
,
a
)
+
γ
∑
s
′
P
(
s
′
∣
s
,
a
)
V
π
∗
(
s
′
)
\pi^*(s) = \argmax_a r(s, a) + \gamma\sum_{s'}P(s'|s, a)V^{\pi^*}(s')
π∗(s)=aargmaxr(s,a)+γs′∑P(s′∣s,a)Vπ∗(s′)
算法实现

class ValueIteration:
def __init__(self, env, theta, gamma):
self.env = env
self.v = [0] * self.env.ncol * self.env.nrow
self.theta = theta
self.gamma = gamma
self.pi = [None for i in range(self.env.ncol * self.env.nrow)]
def values_iteration(self):
cnt = 0
while 1:
max_diff = 0
new_v = [0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol * self.env.nrow):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
new_v[s] = max(qsa_list)
max_diff = max(max_diff, abs(new_v[s] - self.v[s]))
self.v = new_v
if max_diff < self.theta: break
cnt += 1
print("Values Iteration Finished After %d Counts"%cnt)
self.get_policy()
def get_policy(self):
for s in range(self.env.ncol*self.env.nrow):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
maxq = max(qsa_list)
cntq = qsa_list.count(maxq)
self.pi[s] = [1/cntq if q == maxq else 0 for q in qsa_list] # type:ignore



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











