






1.遇到的第一个问题就是不知道该怎样去使用自己的数据集训练模型。
第一步:是在GitHub上下了yolo8(yolo本地测试也可以正常运行),但是不知道该怎么用自己的数据集。
再把自己的数据存放到datasets下就好,再将images和labels都分成train和val(images和labels里的图片命名要保持一致!)至于labels怎么根据images生成,可以去看看别的博主的,我搜的时候看见过好几个,这里不再过多赘述。
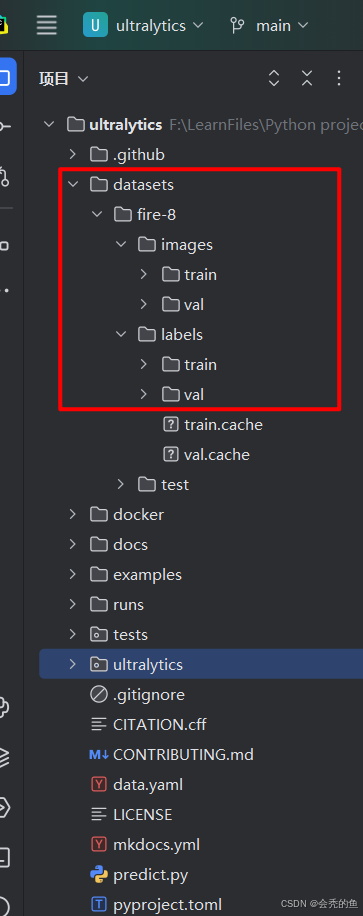
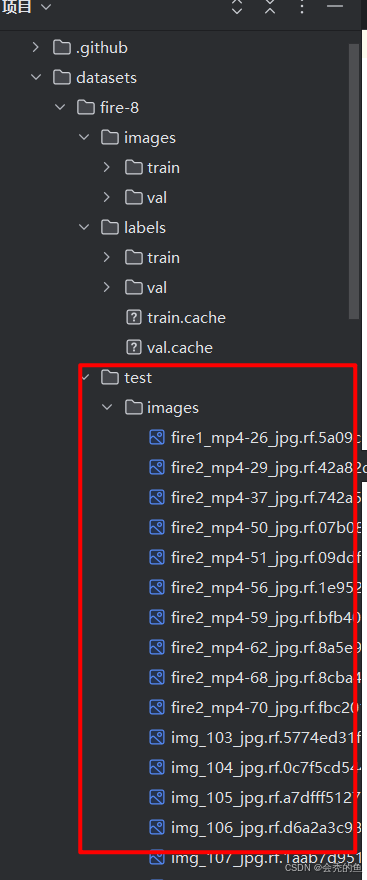
至于测试数据集,看自己情况,test也是分成images和labels。(labels为.txt文件夹)
第二步:其实在根目录下边创建一个.yaml和train.py文件就好。
yaml文件就是定义自己数据集的位置以及标签的名称。我的yaml内容如下:
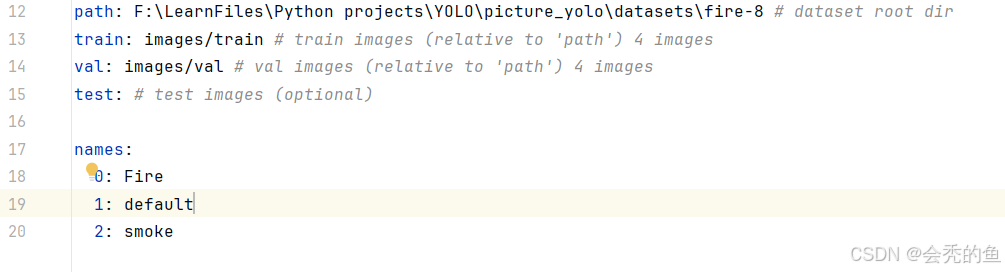
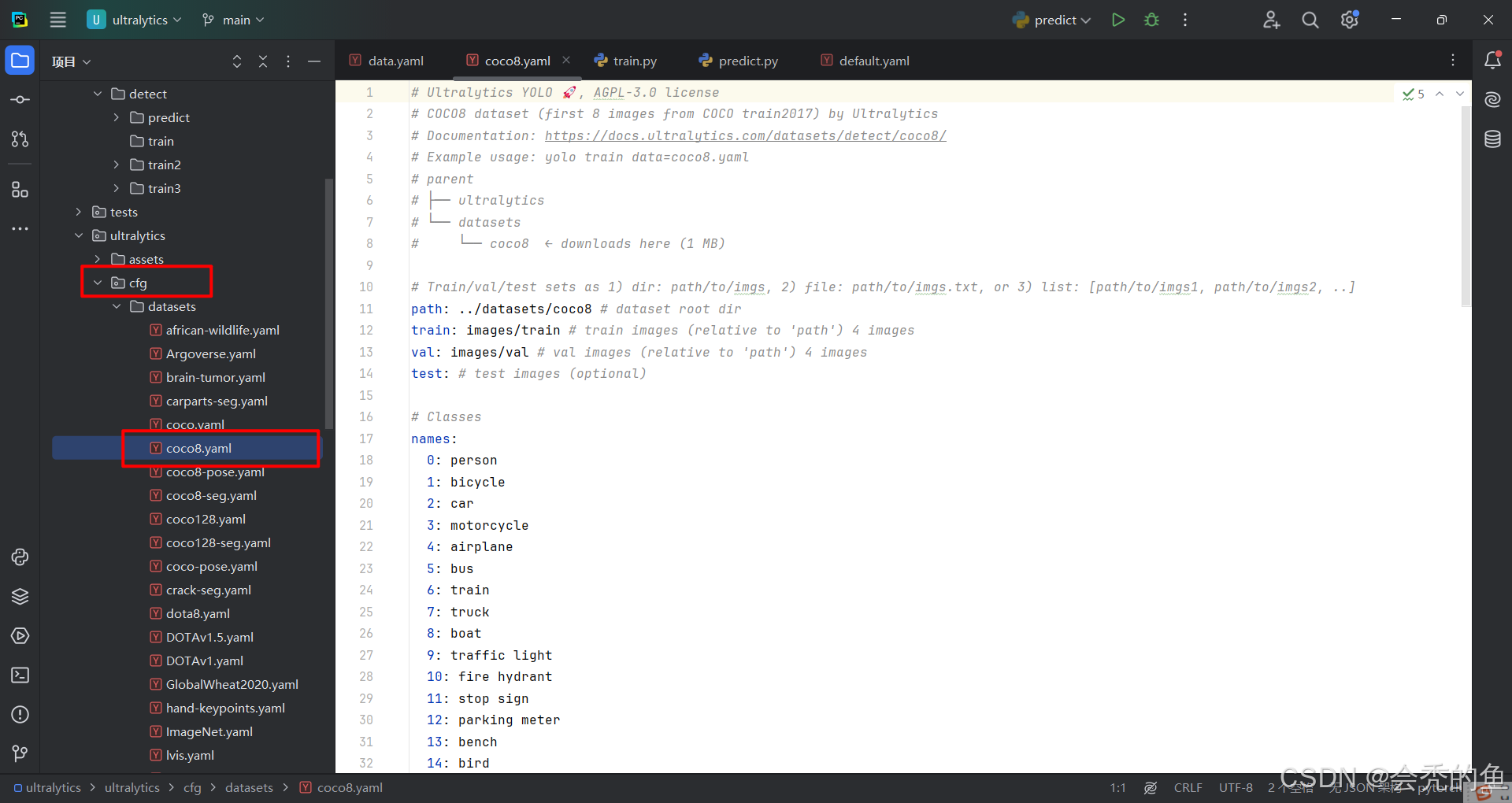
我们只需要把yolo文件夹cfg文件夹下的coco8.yaml复制到根目录下,改成自己的data.yaml文件就好。
在根目录下,创建一个train.py,train.py是用来训练自己的模型的。其实就两行代码。

相关的具体参数这里也不再过多赘述。windows系统的话建议works设为0,要不然容易报错!
2.当模型正常训练后,我遇到了第二个问题:有报错,'str' object has no attribute 'items'
这个问题很简单,就是你的yaml文件少空格了!!
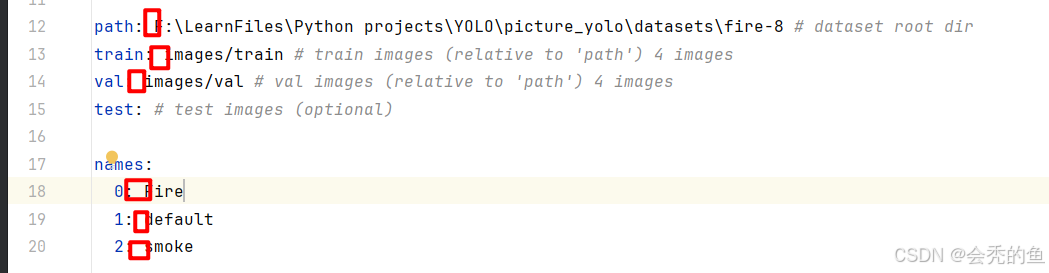
我都加上空格之后就好了。
3.模型训练完成后,会将计算好的 权重保存到保存到runs/train3/weights下

best.pt为最好,last.pt为最差。
好!现在模型训练好了,就差预测了。
在根目录创建一个predict.py,也就几行代码。
# 导入ultralytics的YOLO库
from ultralytics import YOLO
# 加载模型
model = YOLO('runs/detect/train3/weights/best.pt') # 加载自定义的训练模型
if __name__ == '__main__':
results = model.predict(
"datasets/fire-8/test/images",save=True)运行结束后,会将预测后的结果保存到runs下的predict文件夹下。这是出现了第三个问题。
3.调用自己训练后的模型,发现没有预测结果,也就是所谓的标签框
这个问题困惑了我好久,下面直接说发现这个问题的具体过程以及解决方法:
我发现在runs/train3下的results.csv文件中的val/box_loss,val/cls_loss,val/dfl_loss这三列的数据显示为nan,这就很奇怪。
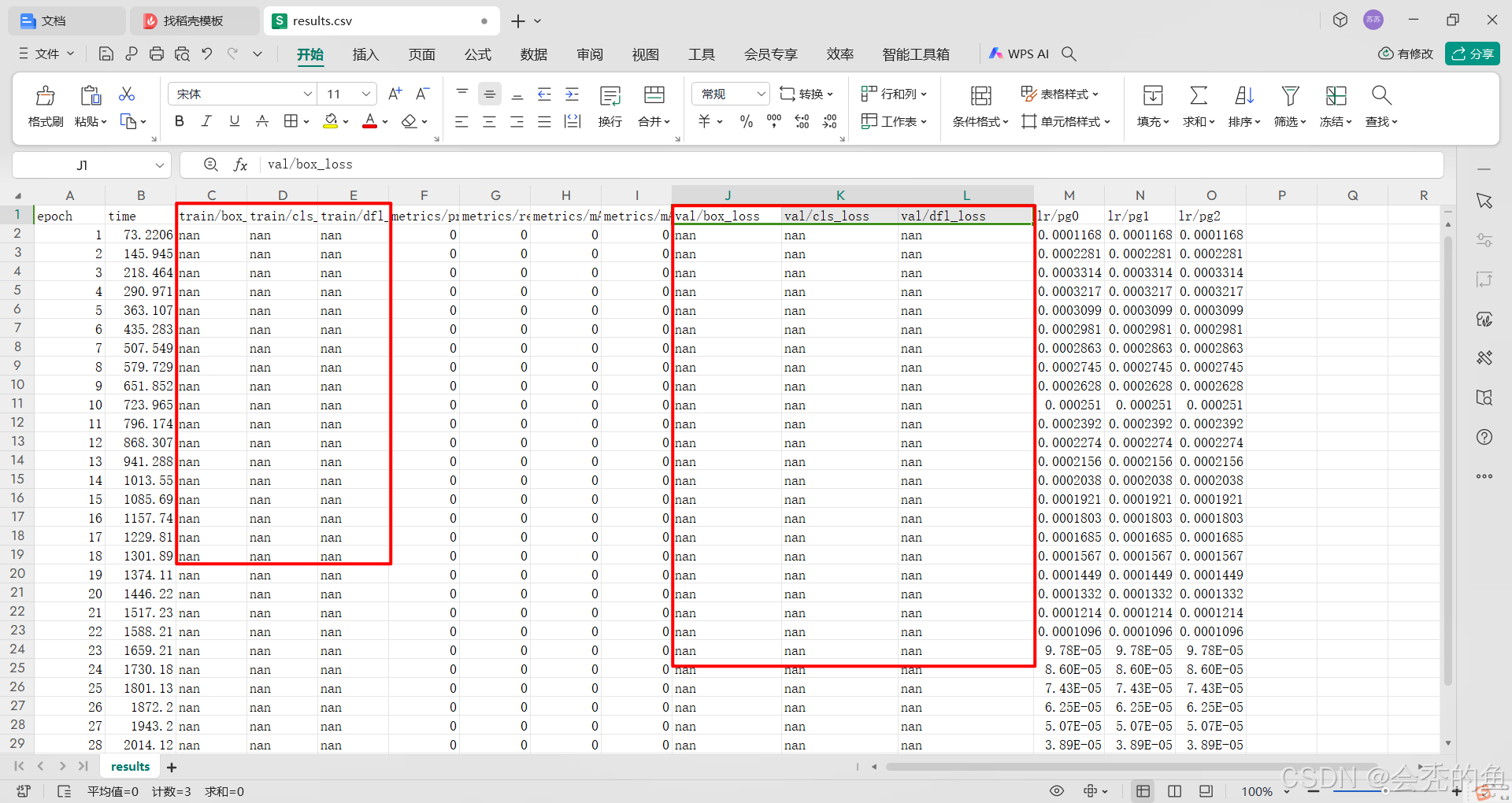
直接说解决办法:
在cfg文件夹下找到default.yaml,将其中的amp改为False!
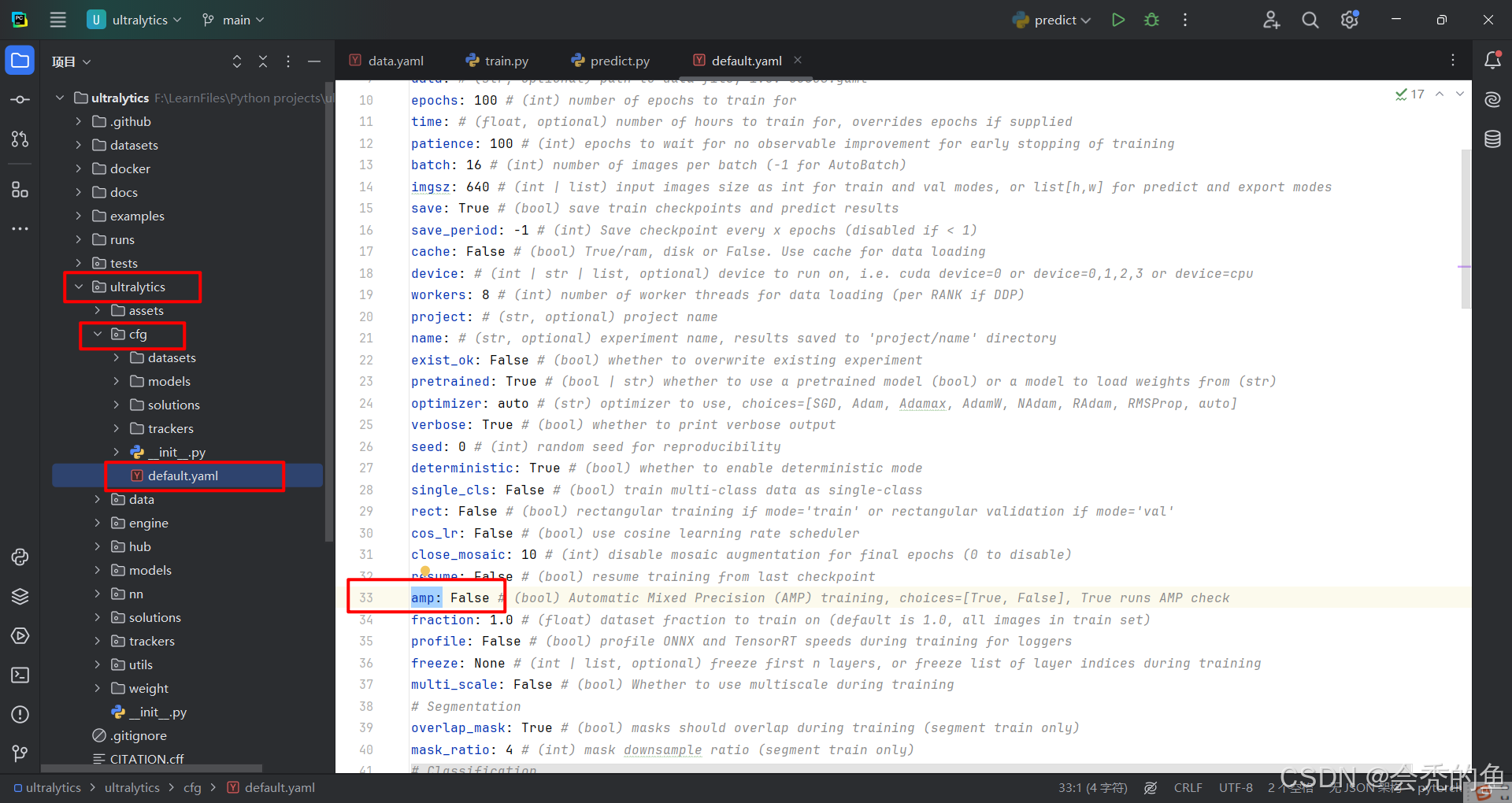
之后再重新训练,就恢复正常了,可以使用自己训练的模型进行预测!!!
完结撒花!


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









