







该功能是在这个项目代码的基础上进行了一些删减和添加,并融合了一些其他功能使其更加完整。
链接:https://pan.baidu.com/s/1tygXjQiE8OWikEoPHSkbNA?pwd=dipp
提取码:dipp
参考链接:MATLAB纸面字符分割,字符提取_对图像二值化,将文字从背景中分离出来 matlab-优快云博客
【数图大作业】基于模板匹配的文字识别(二)(文字行列分割)_模板分割和识别-优快云博客
第一步:对待识别的文字图像进行预处理,并分割成单个字符
字符分割是先按行进行分割,再对每行字符进行按列进行分割

第二步:进行文字识别
文字识别之前要先训练grnn模型,步骤如下:
1.提前准备训练样本图片并保存在train文件中,所有文字图片按数值升序方式命名。
在wzsb.m的文件中修改需要加入训练库中的文字图片,并进行运行,之后字符就会保存到train文件夹中了。
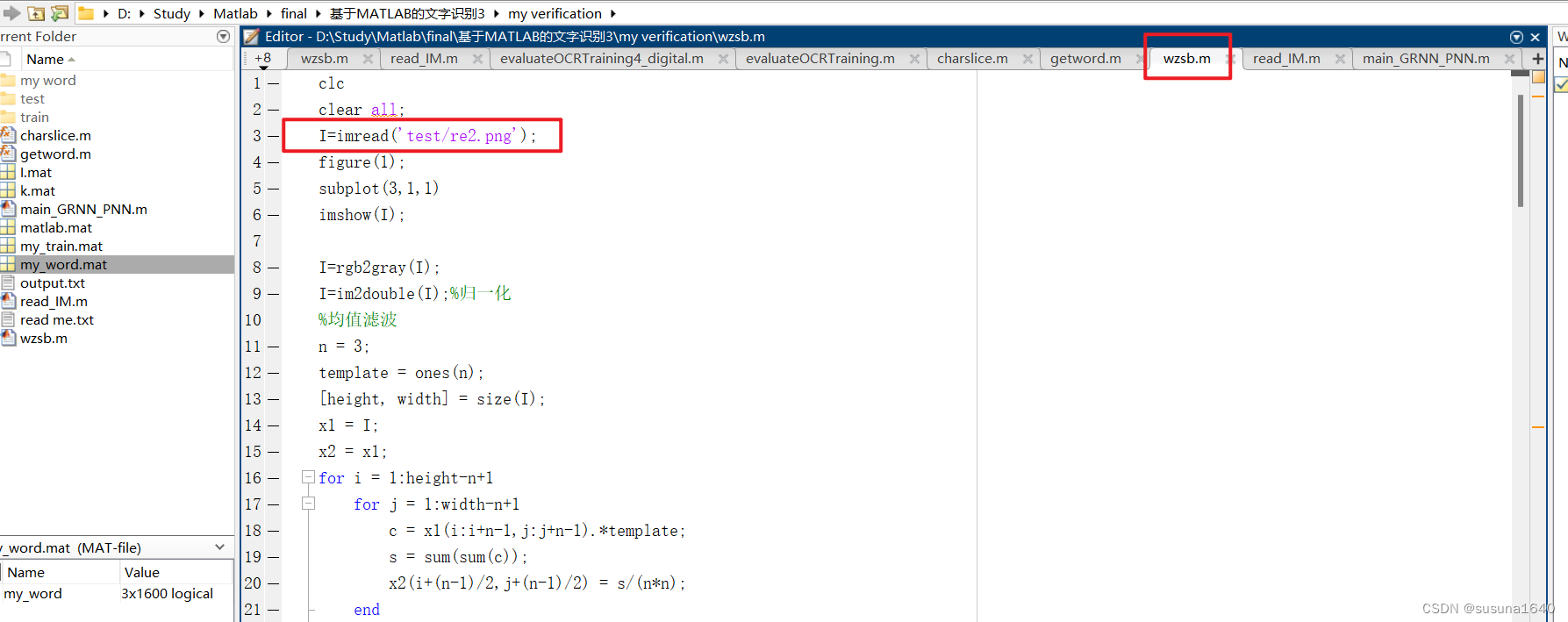
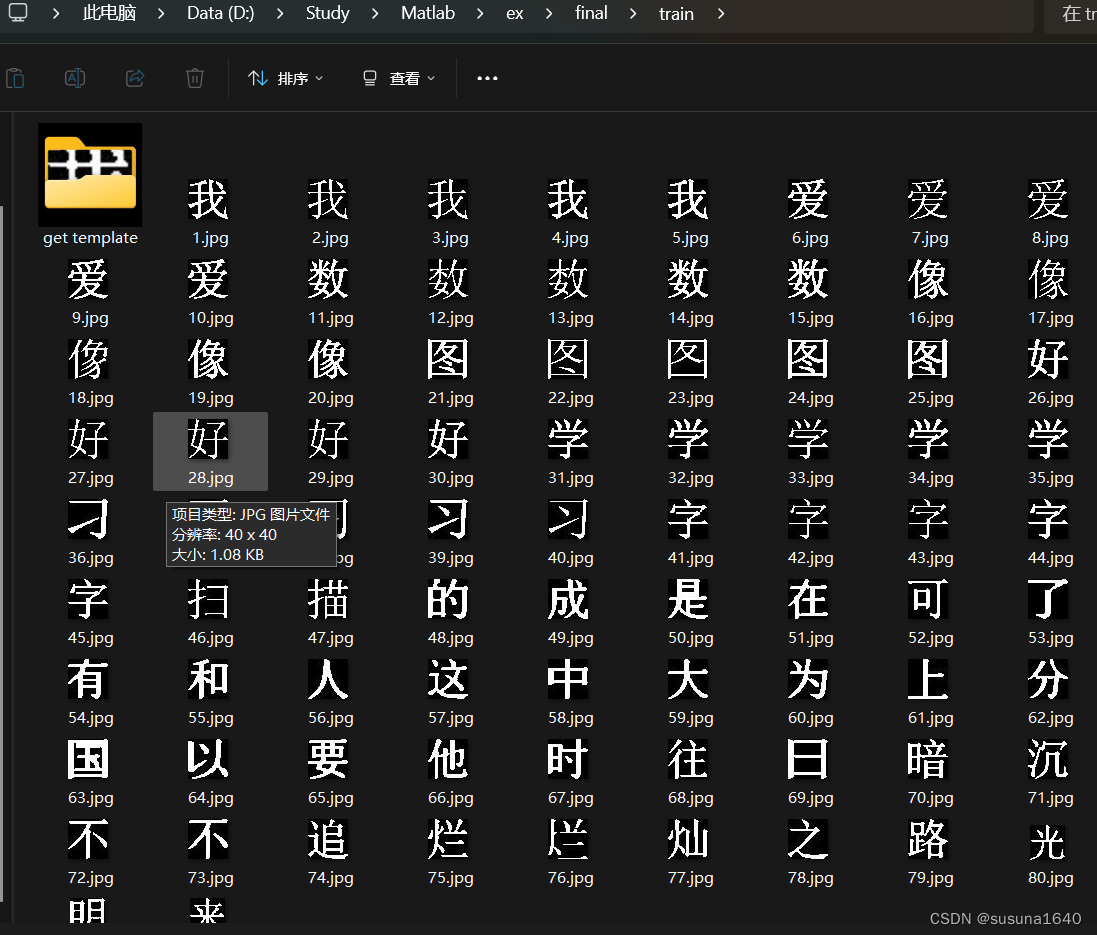
2.read_IM.m得到训练矩阵的信息my_train.mat
在read_IM.m中需要添加待训练的图片信息,该步骤保留之前的添加格式进行添加即可,如果图片信息过多,也可以试试写一个循环代码来读取。(修改好后需要运行一下)
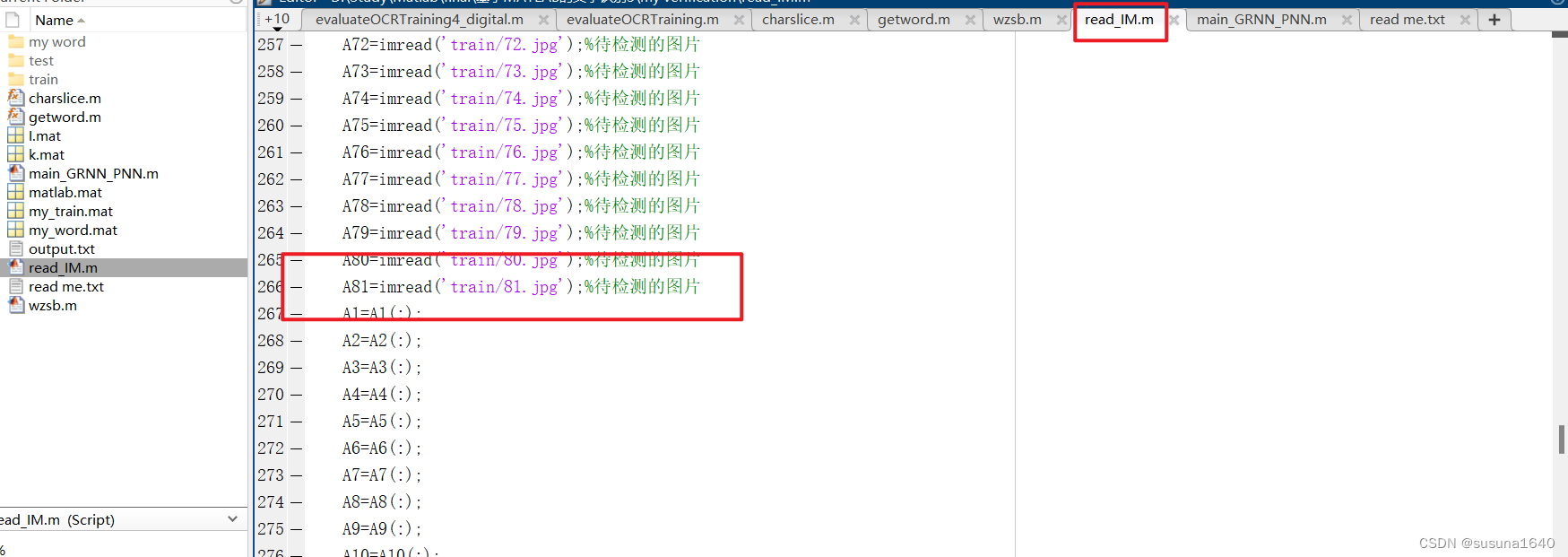
3.以下是利用grnn进行文字识别的主代码:
注意训练集产生部分的样本数和字符个数的区别。
% Button pushed function: Button_Extracttext
function Button_ExtracttextPushed(app, event)
%按钮-提取文字
img_RGB=app.Temp_Img;%文件图片
img = im2gray(img_RGB);
ii=imcomplement(img);
y=charslice(ii);%去除四周多余像素
img_y=imcomplement(y);
im3=im2bw(img_y);
im3=imcomplement(im3);
%膨胀
se = strel("line",45,0);
im4_3 = imdilate(im3,se);
% figure;
% imshow(im4_3);
%连通域识别
BWimg = im4_3;
%统计标注连通域
[l,num_l] = bwlabel(BWimg,8);
status=regionprops(l,'BoundingBox');%获取连通域属性-最小外接框的位置和大小
centroid = regionprops(l,'Centroid');%获取连通域属性-质心
figure('Visible','off');
for i=1:num_l
%绘制外接矩形框
rectangle('position',status(i).BoundingBox,'edgecolor','r');
%标记形心
text(centroid(i,1).Centroid(1,1)-15,centroid(i,1).Centroid(1,2)-15, num2str(i),'Color', 'r')
end
% figure;
% imshow(BWimg);
% 获取所有连通区域
cc = regionprops(BWimg, 'BoundingBox');
imageArray=cell(1,length(cc));
% 循环遍历每个连通区域,截取子图像并保存
for i = 1:length(cc)
% 获取当前连通区域的边界框
bbox = cc(i).BoundingBox;
% 截取子图像
subimg = imcrop(img_y, bbox);
imageArray{i}=subimg;
% figure;
% imshow(subimg);
end
% ------------------
% a---共有几行 count---分割出的单个字符个数
count=0;
for a=1:length(imageArray)
hangvalue=0;
I=imageArray{a};
I=im2double(I);%归一化
thresh = graythresh(I);%大津法
I=(I>=thresh);%I为二值图像
ii=double(I);
[m,n]=size(ii);
iiXY=ii(:,:);
ii=(iiXY~=1);
myI=charslice(ii);%去除行字符中多余区域
k=1;
while size(myI,2)>10 %当myI的长度小等于10,可确定没有字符了
[word{k},myI]=getword(myI); %获取字符
% figure;
% imshow(word{k});
k=k+1;
end
c=k-1;
for j=1:c
count=count+1;
word{j}=imresize(word{j},[40 40]);%字符规格化成40×40的
imwrite(word{j},['testword/',int2str(count),'.jpg']);%保存字符到新模板
end
end
% -------------------------------
%训练集/测试集产生
%
% 1. 导入数据
load my_train.mat
mytrain=double(my_train);
classes=[1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 6 6 6 6 6 7 7 7 7 7 8 8 8 8 8 9 9 9 9 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 36 37 38 38 39 40 41 42 43 44];
%
% 2 产生训练集和测试集
P_train = [];
T_train = [];
P_test = [];%初始化测试集
T_test = [];%初始化测试集标签
% 训练集——82个样本
P_train = mytrain(:,1:82); %训练数据横行为特征纵行为样本
T_train = classes(1:82); %一个行矩阵,为标签
% 测试集——k个样本
% I=uint8(singlecell{1,1});
I=imread(['testword/1.jpg']);%待检测的图片
I1=I(:);
for i=2:count
I2=imread(['testword/',num2str(i),'.jpg']);%待检测的图片
% I2=uint8(singlecell{1,i});
I2=I2(:);
I1=[I1 I2];
end
P_test = I1; %存储测试集
T_test = ones(1,count);%设置测试集标签
%模型建立
result_grnn = [];
time_grnn = [];
p_train = P_train;
p_test = P_test;
% 1. GRNN创建及仿真测试
t = cputime;%计时开始
% 创建网络
net_grnn = newgrnn(p_train,T_train);%创建GRNN网络
% 仿真测试
t_sim_grnn = sim(net_grnn,p_test);%在测试集上进行仿真
T_sim_grnn = round(t_sim_grnn);%对仿真结果四舍五入
t = cputime - t;%计算耗时
time_grnn = [time_grnn t];%存储耗时
result_grnn = [result_grnn T_sim_grnn'];%存储GRNN的预测结果
% 性能评价
%
% 1. 正确率
accuracy_grnn = [];
time = [];
i=1;
accuracy_1 = length(find(result_grnn(:,i) == T_test'))/length(T_test);
accuracy_grnn = [accuracy_grnn accuracy_1];
%%
% 2. 结果对比
result = result_grnn; %结果
a=0;
str_text='';
for i=1:count
a=a+1;
% fid = fopen('output.txt','a');
if (result_grnn(a,1)==1)
str='我';
elseif (result_grnn(a,1)==2)
str='爱';
elseif (result_grnn(a,1)==3)
str='数';
elseif (result_grnn(a,1)==4)
str='像';
elseif (result_grnn(a,1)==5)
str='图';
elseif (result_grnn(a,1)==6)
str='好';
elseif (result_grnn(a,1)==7)
str='学';
elseif (result_grnn(a,1)==8)
str='习';
elseif (result_grnn(a,1)==9)
str='字';
elseif (result_grnn(a,1)==10)
str='扫';
elseif (result_grnn(a,1)==11)
str='描';
elseif (result_grnn(a,1)==12)
str='的';
elseif (result_grnn(a,1)==13)
str='成';
elseif (result_grnn(a,1)==14)
str='是';
elseif (result_grnn(a,1)==15)
str='在';
elseif (result_grnn(a,1)==16)
str='可';
elseif (result_grnn(a,1)==17)
str='了';
elseif (result_grnn(a,1)==18)
str='有';
elseif (result_grnn(a,1)==19)
str='和';
elseif (result_grnn(a,1)==20)
str='人';
elseif (result_grnn(a,1)==21)
str='这';
elseif (result_grnn(a,1)==22)
str='中';
elseif (result_grnn(a,1)==23)
str='大';
elseif (result_grnn(a,1)==24)
str='为';
elseif (result_grnn(a,1)==25)
str='上';
elseif (result_grnn(a,1)==26)
str='分';
elseif (result_grnn(a,1)==27)
str='国';
elseif (result_grnn(a,1)==28)
str='以';
elseif (result_grnn(a,1)==29)
str='要';
elseif (result_grnn(a,1)==30)
str='他';
elseif (result_grnn(a,1)==31)
str='时';
elseif (result_grnn(a,1)==32)
str='往';
elseif (result_grnn(a,1)==33)
str='日';
elseif (result_grnn(a,1)==34)
str='暗';
elseif (result_grnn(a,1)==35)
str='沉';
elseif (result_grnn(a,1)==36)
str='不';
elseif (result_grnn(a,1)==37)
str='追';
elseif (result_grnn(a,1)==38)
str='烂';
elseif (result_grnn(a,1)==39)
str='灿';
elseif (result_grnn(a,1)==40)
str='之';
elseif (result_grnn(a,1)==41)
str='路';
elseif (result_grnn(a,1)==42)
str='光';
elseif (result_grnn(a,1)==43)
str='明';
elseif (result_grnn(a,1)==44)
str='来';
else
disp('not Found');
clear
end
str_text=strcat(str_text,str);
end
disp(str_text);
app.EditField_text.Value=str_text;
end其中,行分割是通过连通域区域提取来实现的,列分割是通过getword函数遍历每列像素,在列像素值之和为0的位置进行分割的。
getword.m:
%字符获取---切割出单个字符
function [word,result]=getword(ii)
word=[];
flag=0;
y1=8;
y2=0.5;
while flag==0
[m,n]=size(ii);
wide=0;%初始化宽度
%列和非0
while sum(ii(:,wide+1))~=0 && wide<=n-2
wide=wide+1;
end
%切割
temp=charslice(imcrop(ii,[1 1 wide m]));
[m1,n1]=size(temp);
%若切割字符的行列无效
if wide<y1 && nl/ml>y2
ii(:,1:wide)=0;%将ii的前wide列置零
%若仍存在字符
if sum(sum(ii))~=0
ii=charslice(ii);%切割掉多余边缘,继续分割字符
%不存在字符
else
word=[];
flag=1;%结束while
end
%有效
else
word=charslice(imcrop(ii,[1 1 wide m]));%存进结果
ii(:,1:wide)=0;%将ii的前wide列置零
%若ii中仍存在字符
if sum(sum(ii))~=0
ii=charslice(ii); %切割调多余边缘
flag=1; %结束while
%若ii中已无字符
else
ii=[];
end
end
end
result=ii;但这种方法对于左右结构或左中右结构的字符分割效果不好,可以参考一下这个链接:【数图大作业】基于模板匹配的文字识别(二)(文字行列分割)_模板分割和识别-优快云博客
(如果在已有代码的基础上解决了这个问题的小伙伴可以在评论区call我吗,非常感谢!)
charslice.m文件是用于裁剪掉文字图片四周多余部分的函数:
%字符分割
function y=charslice(ii)
[m,n]=size(ii);
%初始化上下左右边界
top=1;bottom=m;left=1;right=n;
%循环检查图像上边界,直到找到第一个非零行或图像底部
while sum(ii(top,:))==0 && top<m
top=top+1;
end
%循环检查图像下边界,直到找到第一个非零行或图像顶部
while sum(ii(bottom,:))==0 && bottom>=1
bottom=bottom-1;
end
%循环检查图像左边界,直到找到第一个非零行或图像右部
while sum(ii(:,left))==0 && left<n
left=left+1;
end
%循环检查图像右边界,直到找到第一个非零行或图像左部
while sum(ii(:,right))==0 && right>=1
right=right-1;
end
%计算字符区域的高度差异
ydiff=bottom-top;
%计算字符区域的宽度差异
xdiff=right-left;
%根据边界对原始图像进行裁剪
y=imcrop(ii,[left top xdiff ydiff]);最后,利用grnn广义回归神经网络进行文字识别的效果如图:
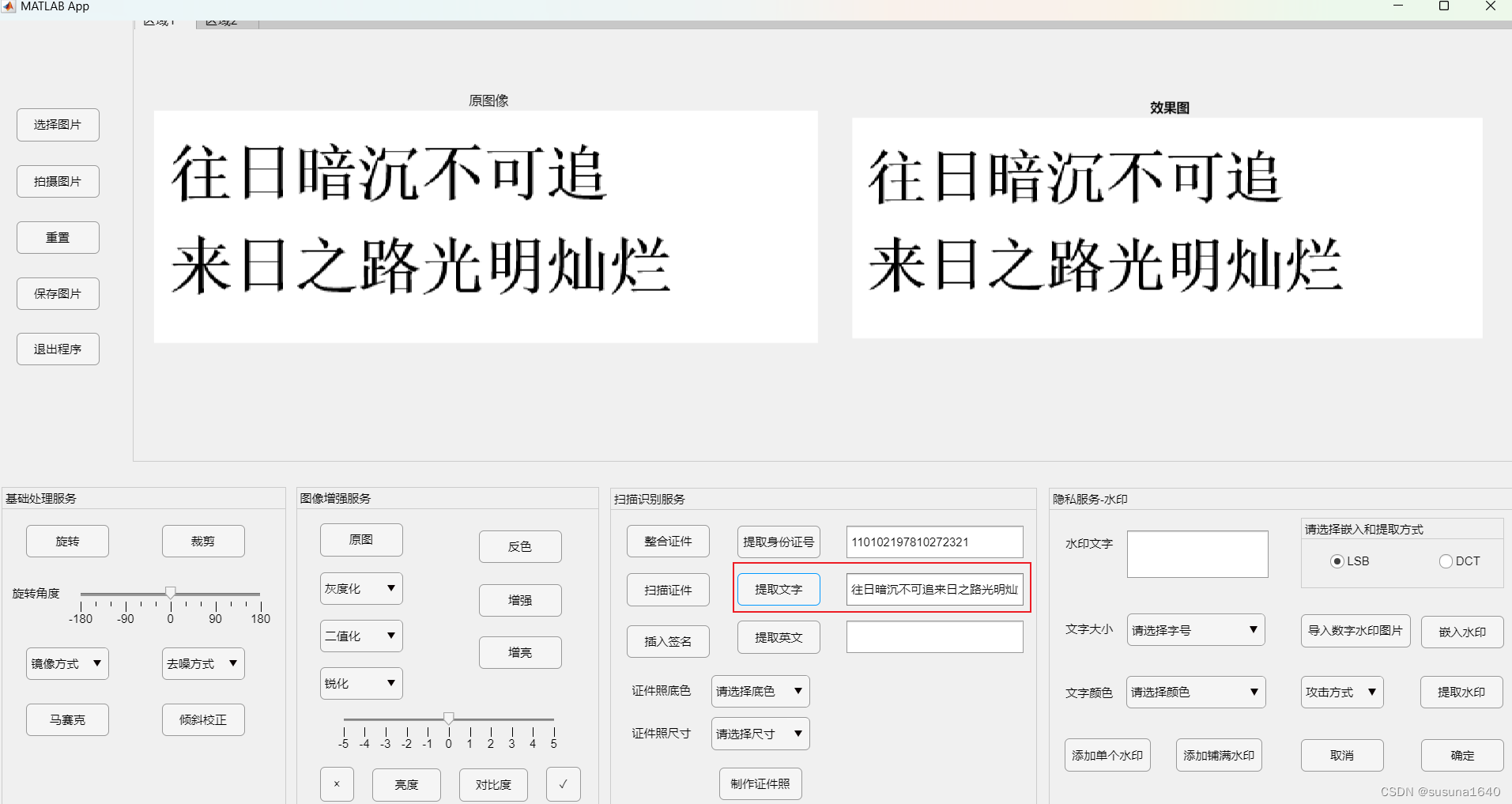

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









