







1、结果集过大问题
产生结果集过大的原因以及解决方法:
epointframe.properties 配置文件中 maxQuerySize 参数配置的数量为检查结果集大小的参数(默认3000),如果数量大于此值则在日志中记录。可以根据自己的系统情况以及系统性能来修改参数(市县一体化的项目一般部门数量、事项数量都比较大)。
如果产生此问题需要分析一下是否因为sql查询不符合逻辑。
是否查询数量的sql写成了查询列表?
为何不应用分页?
日志如下:关键字,结果集
#### 20241015 00:00:12,052 | com.epoint.core.dao.CommonDao.findList(ii:371) | WARN | sql: SELECT DISTINCT c.CatalogCode, c.DeptCode FROM ( SELECT a.CatalogCode,b.DeptCode from task_directory a , task_check_basic b where a.CatalogCode=b.CatalogCode and b.TaskState=1 UNION ALL SELECT a.CatalogCode,b.DeptCode from task_directory a , task_general_basic b where a.CatalogCode=b.CatalogCode and b.TaskState=1 UNION ALL SELECT a.CatalogCode,b.DeptCode from task_directory a , task_handle_basic b where a.CatalogCode=b.CatalogCode and b.TaskState=1 UNION ALL SELECT a.CatalogCode,b.DeptCode from task_directory a , task_public_basic b where a.CatalogCode=b.CatalogCode and b.TaskState=1 UNION ALL SELECT a.CatalogCode,b.DeptCode from task_directory a , task_punish_basic b where a.CatalogCode=b.CatalogCode and b.TaskState=1) c args: [] 查询结果集size超过10000条,请优化程序设计..
。。。。。。如果一切都合理,且数量也不是特别大(如果查询的数据量的很大,足以大于JVM虚拟机的内存大小,则系统会出现堆栈溢出导致崩溃),可以选择备案。
2、链接泄露问题 (druid连接池,目前本公司项目采用的都是此连接池)
1、为什么会产生连接泄露?
- 连接未正常归还:在使用完连接后,如果没有正确关闭连接,连接会被长时间占用,导致连接泄露。
- 代码问题:代码中的错误或不当操作也会导致连接泄露。例如,在异常处理时没有关闭连接,或者在业务逻辑中不必要地持有连接。
- 配置不当:连接池的配置不合理,如最大连接数设置过高或过低,可能导致资源耗尽或连接无法及时释放。
2、为了避免连接泄露做了哪些操作?
在配置文件jdbc.properties中新增参数,两个参数要一起用
#用来检测连接泄露的配置,当超过指定时间连接未关闭时,将会强制关闭,同时输出abandon的错误
removeAbandoned=true
#超时时间;单位为秒。180秒=3分钟
removeAbandonedTimeout=180
# removeAbandoned,从字面意思来看,作用是移除被遗弃的对象。- 如果配置了以上参数,则如果从druid的连接池里面拿到了连接没有按照配置的时间进行归还到连接池,并且被druid的监控线程监控到,则会抛出异常:关键字 removeAbandoned
#### 20241015 00:03:20,823 | com.alibaba.druid.pool.DruidDataSource.removeAbandoned(DruidDataSource.java:2198) | ERROR | abandon connection, owner thread: zwfw_Worker-28, connected time nano: 43940663091939347 requestUrl: null, objid: 732944521, open stackTrace at java.lang.Thread.getStackTrace(Thread.java:1552) at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1047) at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4572) at com.alibaba.druid.filter.FilterAdapter.dataSource_getConnection(FilterAdapter.java:2723) at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4568) at com.alibaba.druid.filter.logging.LogFilter.dataSource_getConnection(LogFilter.java:827) at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4568) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:967) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:959) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:104) at com.epoint.database.jdbc.connection.DatasourceConnectionProvider.getConnection(ci:311) at com.epoint.database.jdbc.impl.DBImpl.getConnection(xd:212) at com.epoint.database.jdbc.transaction.JDBCTransaction.begin(tc:335) at com.epoint.database.jdbc.impl.DBImpl.begin(xd:326) at com.epoint.database.peisistence.PersistenceService.beginTransaction(jb:3) at com.epoint.core.dao.CommonDao.beginTransaction(ii:1014) at com.epoint.core.EpointFrameDsManager.inject(eg:32) at com.epoint.core.EpointFrameDsManager.begin(eg:311) at com.epoint.taskgz.taskdirectory.job.TaskdirectoryJob.execute(TaskdirectoryJob.java:36) at org.quartz.core.JobRunShell.run(JobRunShell.java:202) at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573) #### 20241015 00:03:20,831 | | ERROR | 【连接泄露】线程:zwfw_Worker-28,连接时长:200s 状态:RUNNABLE 当前运行堆栈如下,请检查是否运行时间过长: at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:101) at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:144) at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:174) at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3001) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3462) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3452) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3893) at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2526) at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2673) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2549) at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1861) at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2073) at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2009) at com.mysql.jdbc.PreparedStatement.executeLargeUpdate(PreparedStatement.java:5098) at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1994) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_executeUpdate(FilterChainImpl.java:2741) at com.alibaba.druid.filter.FilterAdapter.preparedStatement_executeUpdate(FilterAdapter.java:1069) at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_executeUpdate(FilterEventAdapter.java:491) at com.epoint.locktimeout.WatchFilter.preparedStatement_executeUpdate(WatchFilter.java:52) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_executeUpdate(FilterChainImpl.java:2739) at com.alibaba.druid.filter.FilterAdapter.preparedStatement_executeUpdate(FilterAdapter.java:1069) at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_executeUpdate(FilterEventAdapter.java:491) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_executeUpdate(FilterChainImpl.java:2739) at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.executeUpdate(PreparedStatementProxyImpl.java:158) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeUpdate(DruidPooledPreparedStatement.java:253) at com.epoint.database.jdbc.impl.DBImpl.execute(xd:91) at com.epoint.database.jdbc.impl.DBImpl.execute(xd:194) at com.epoint.database.peisistence.crud.impl.PrimarySqlImpl.executeSqlNative(ob:245) at com.epoint.database.peisistence.crud.CRUDService.executeSqlNative(hc:456) at com.epoint.database.peisistence.crud.CRUDService.executeSqlNative(hc:95) at com.epoint.core.dao.CommonDao.execute(ii:85) at com.epoint.taskgz.taskdirectory.impl.YlTaskDirectoryService.addTaskRl(YlTaskDirectoryService.java:73) at com.epoint.taskgz.taskdirectory.job.TaskdirectoryJob.doService(TaskdirectoryJob.java:61) at com.epoint.taskgz.taskdirectory.job.TaskdirectoryJob.execute(TaskdirectoryJob.java:37) at org.quartz.core.JobRunShell.run(JobRunShell.java:202) at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
-
可能出现此问题的场景:
-
1、在Job的使用中直接new了impl层的对象,在impl层代码里面直接在无参变量里面声明了Dao,在使用完Dao之后没有进行处理。
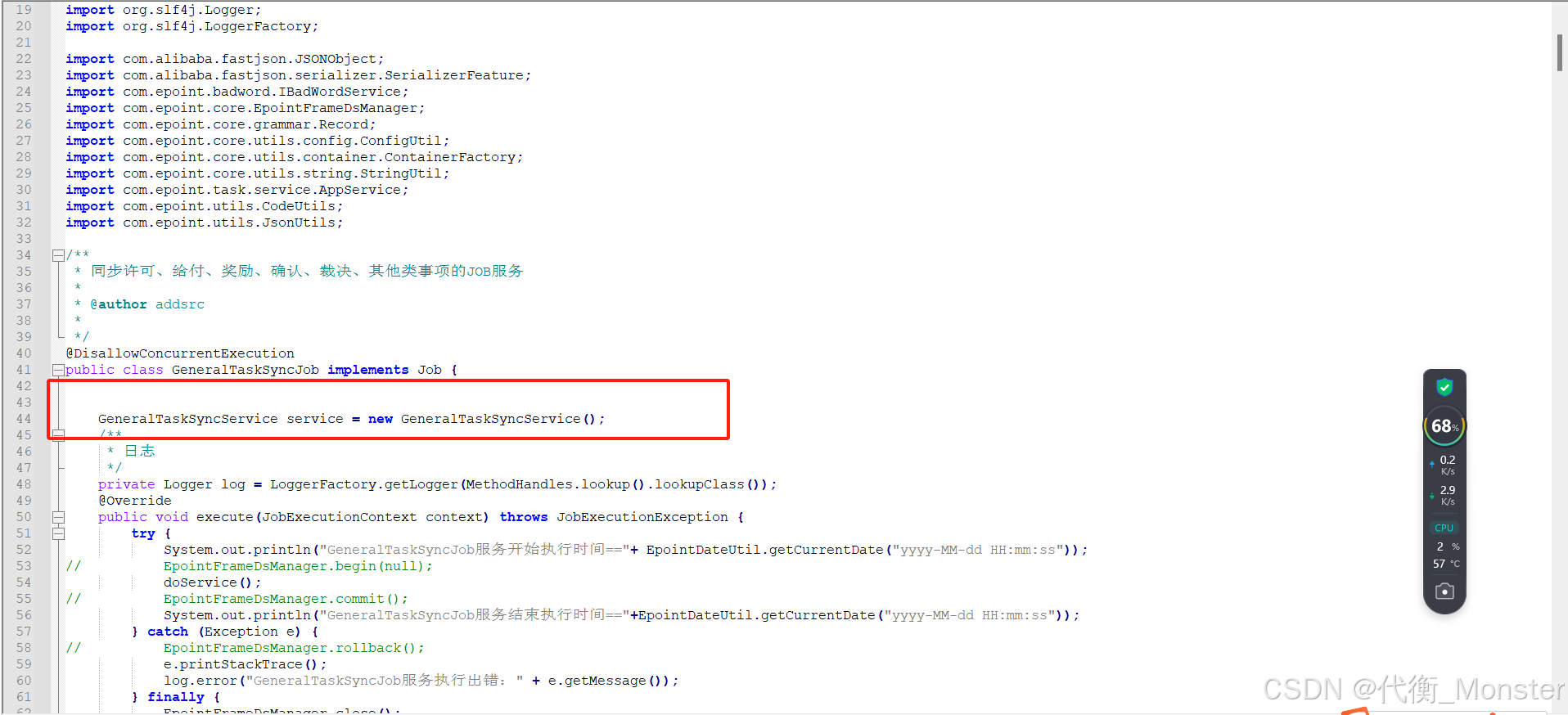
使用完之后 ICommonDao commonDaoToQzk= CommonDao.getInstance(); if (commonDaoToQzk != null) { commonDaoToQzk.close(); }获取系统参数或者配置文件参数
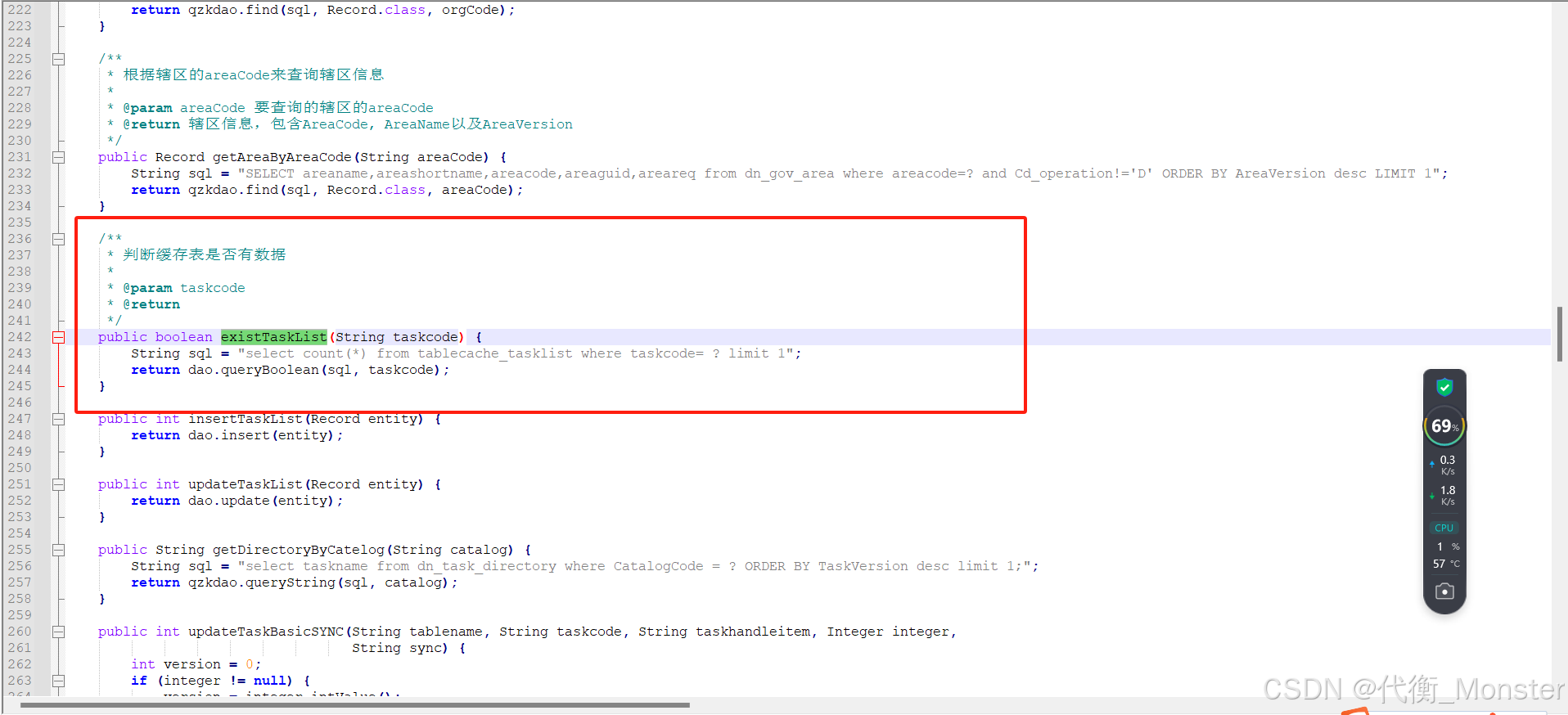
-
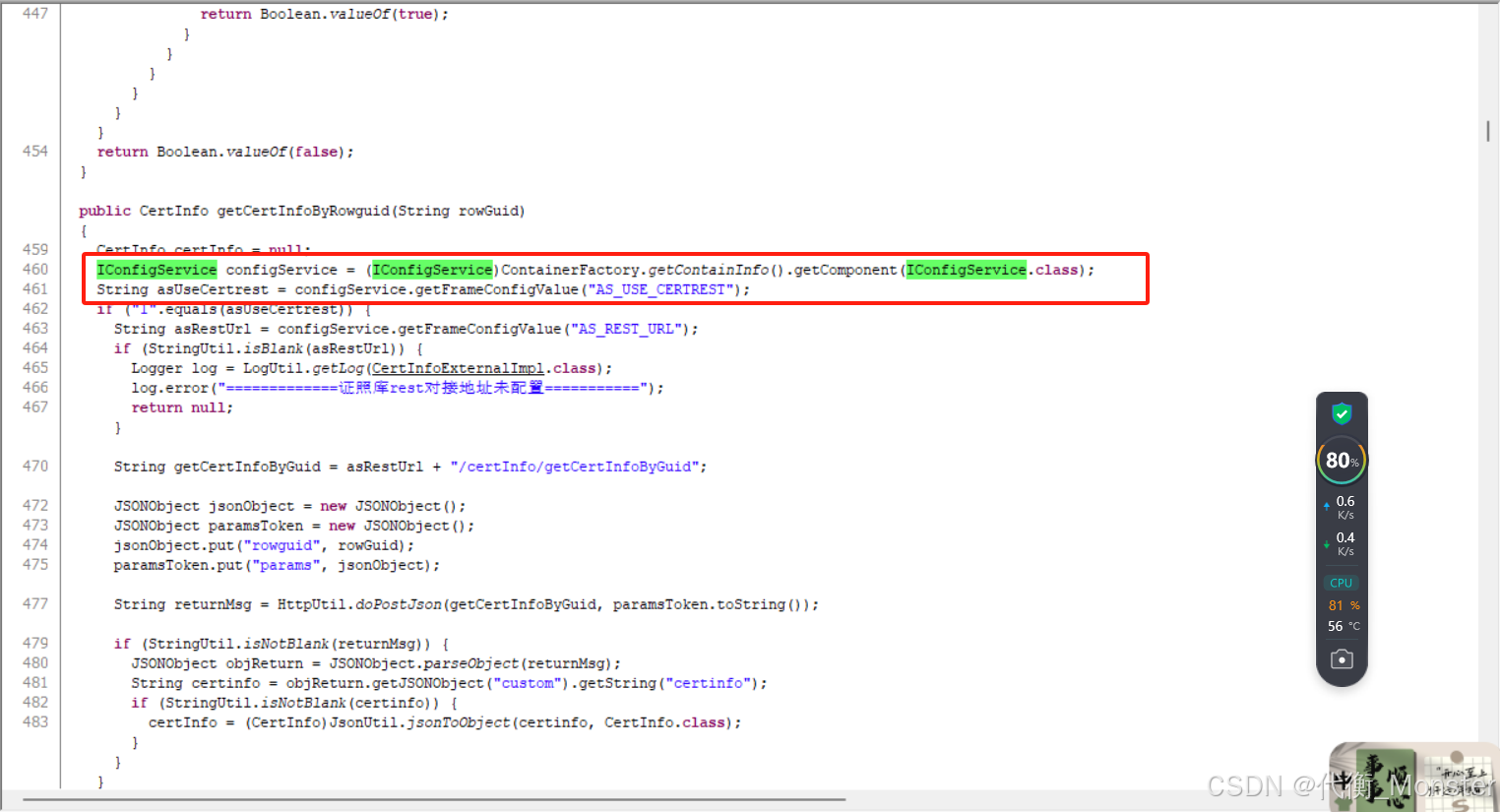 建议直接在系统启动的时候加载此参数,不要写到方法内部进行加载
建议直接在系统启动的时候加载此参数,不要写到方法内部进行加载 -
Redis连接泄露:存在关键字“JedisConnectionException: Could not get a resource from the pool” 使用完之后必须关闭
-
try { // 创建Redis连接 jedis = new Jedis("localhost"); // 使用Redis jedis.set("key", "value"); } catch (Exception e) { // 处理异常 e.printStackTrace(); } finally { // 确保释放资源 if (jedis != null) { jedis.close(); } }3、死锁 :关键字(Lock)
-
#### 20191219 10:10:10,234 com.alibaba.druid.filter.logging.Log4jFilter.statementLogError(Log4jFilter.java:152) | ERROR | {conn-10593, pstmt-38675} execute error. update xxx set xxx = ? , xxx = ? where RowGuid = ? com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction当项目中出现如上报错时,代表在那一时刻,SQL因为无法获取到对应的行锁而超时报错(bin包默认行锁超时时间为5秒),如果想要排查具体原因,只能通过开启监控,再等待问题复现后排查。
如下提供一套
Event + Procedure的行锁等待监控方法,会定时扫描MySQL中是否存在行锁等待,如果存在则会将阻塞状态记录到日志表中,事后我们就针对日志表分析原因。 -
创建监控库(可以根据此方法在数据库层间进行行锁的监控)
-
create database if not exists `innodb_monitor`;创建存储过程
-
dbeaver中创建存储过程需要选择执行SQL脚本,否则无法创建。MySQL版本查看:
select version();MySQL5.7与MySQL8.0的存储过程略有不同,主要是系统表名发生了变化,请针对版本创建存储过程。 -
# <MySQL5.7版本> use innodb_monitor; drop procedure if exists pro_innodb_lock_wait_check; delimiter go CREATE PROCEDURE pro_innodb_lock_wait_check() BEGIN declare wait_rows int; set group_concat_max_len = 1024000; CREATE TABLE IF NOT EXISTS `innodb_lock_wait_log` ( `report_time` datetime DEFAULT NULL, `waiting_id` int(11) DEFAULT NULL, `blocking_id` int(11) DEFAULT NULL, `duration` varchar(50) DEFAULT NULL, `state` varchar(50) DEFAULT NULL, `waiting_query` longtext DEFAULT NULL, `blocking_current_query` longtext DEFAULT NULL, `blocking_thd_last_query` longtext, `thread_id` int(11) DEFAULT NULL ); select count(*) into wait_rows from information_schema.innodb_lock_waits ; if wait_rows > 0 THEN insert into `innodb_lock_wait_log` SELECT now(),r.trx_mysql_thread_id waiting_id,b.trx_mysql_thread_id blocking_id,concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration, t.processlist_command state,r.trx_query waiting_query,b.trx_query blocking_current_query,group_concat(left(h.sql_text,10000) order by h.TIMER_START DESC SEPARATOR ';\n') As blocking_thd_query_history,thread_id FROM information_schema.innodb_lock_waits w JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id LEFT JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id LEFT JOIN performance_schema.events_statements_history h USING(thread_id) group by thread_id,r.trx_id order by r.trx_wait_started; end if; END go # <MySQL8.0版本> use innodb_monitor; drop procedure if exists pro_innodb_lock_wait_check; delimiter go CREATE PROCEDURE pro_innodb_lock_wait_check() BEGIN declare wait_rows int; set group_concat_max_len = 1024000; CREATE TABLE IF NOT EXISTS `innodb_lock_wait_log` ( `report_time` datetime DEFAULT NULL, `waiting_id` int(11) DEFAULT NULL, `blocking_id` int(11) DEFAULT NULL, `duration` varchar(50) DEFAULT NULL, `state` varchar(50) DEFAULT NULL, `waiting_query` longtext DEFAULT NULL, `blocking_current_query` longtext DEFAULT NULL, `blocking_thd_last_query` longtext, `thread_id` int(11) DEFAULT NULL ); select count(*) into wait_rows from performance_schema.data_lock_waits; if wait_rows > 0 THEN insert into `innodb_lock_wait_log` SELECT now(),r.trx_mysql_thread_id waiting_id,b.trx_mysql_thread_id blocking_id,concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration, t.processlist_command state,r.trx_query waiting_query,b.trx_query blocking_current_query,group_concat(left(h.sql_text,10000) order by h.TIMER_START DESC SEPARATOR ';\n') As blocking_thd_query_history,thread_id FROM performance_schema.data_lock_waits w JOIN information_schema.innodb_trx b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID JOIN information_schema.innodb_trx r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID LEFT JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id LEFT JOIN performance_schema.events_statements_history h USING(thread_id) group by thread_id,r.trx_id order by r.trx_wait_started; end if; END go创建事件
-
dbeaver中创建事件需要选择执行SQL脚本,是否无法创建。默认
每隔5秒执行一次,持续监控7天,结束后会自动删除事件,可以自定义修改保留时长。当事件超过7天被自动删除后,可以重新建立事件继续运行。 -
use innodb_monitor; drop event if exists event_innodb_lock_wait_check; delimiter go CREATE EVENT `event_innodb_lock_wait_check` ON SCHEDULE EVERY 5 SECOND STARTS CURRENT_TIMESTAMP ENDS CURRENT_TIMESTAMP + INTERVAL 7 DAY ON COMPLETION NOT PRESERVE ENABLE DO call pro_innodb_lock_wait_check(); go 默认不需要进行如下命令,事件创建后会自动执行,如需手动停止Event则可以参考如下命令。 # 1为全局开启事件,0为全局关闭事件 mysql> SET GLOBAL event_scheduler = 1; # 临时关闭事件 mysql> ALTER EVENT event_innodb_lock_wait_check DISABLE; # 关闭开启事件 mysql> ALTER EVENT event_innodb_lock_wait_check ENABLE; # 查看事件状态 mysql> select * from information_schema.EVENTS;最后我们可以根据日志表
innodb_monitor.innodb_lock_wait_log中的记录,分析行锁等待原因,其中主要有2种场景: -
blocking_current_query列不为空:说明阻塞事务处于
运行状态,这时候需要分析当前运行SQL是否存在性能问题。 -
blocking_current_query为空,state为Sleep:此时阻塞事务处于
挂起状态(即不在运行SQL),此时需要通过分析blocking_thd_last_query分析挂起事务上下文,注意该列中的SQL为时间降序,即从下往上执行(默认只能保留10条记录)。 -
下图是手动模拟的行锁等待场景,因为blocking_current_query为空,说明阻塞事务处于挂起状态,从
blocking_thd_last_query列可以看到阻塞事务之前执行过的SQL,而Waiting_query列则代表当前被阻塞的SQL语句,往往也是web日志中执行超时的报错SQL。 -
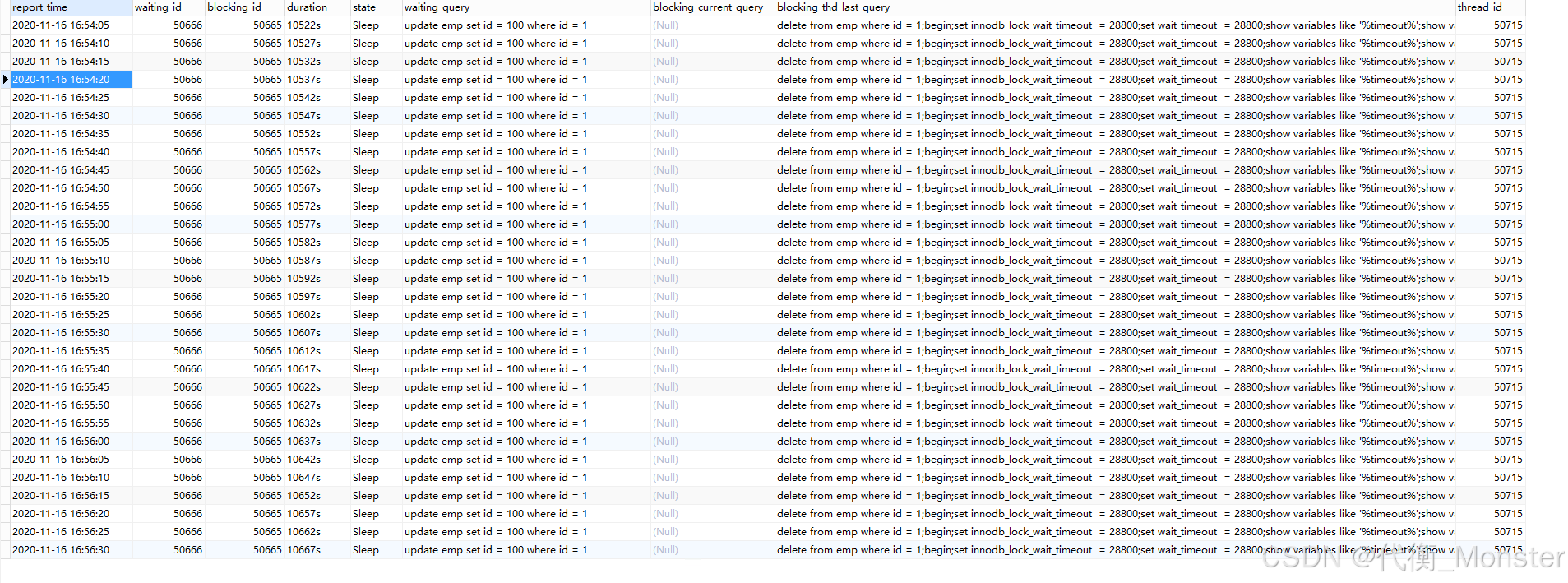
-
Druid 的sql监控页面可以查看程序运行时的Sql.具体操作如下:
-
web.xml进行如下配置
-
<filter> <filter-name>DruidWebStatFilter</filter-name> <filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> <async-supported>true</async-supported> <init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,*.jsp,/druid/*,/download/*</param-value> </init-param> <init-param> <param-name>sessionStatEnable</param-name> <param-value>false</param-value> </init-param> <init-param> <param-name>profileEnable</param-name> <param-value>false</param-value> </init-param> </filter> <filter-mapping> <filter-name>DruidWebStatFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <servlet> <servlet-name>DruidStatView</servlet-name> <servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class> <init-param> <param-name>resetEnable</param-name> <param-value>true</param-value> </init-param> <init-param> <!-- 用户名 --> <param-name>loginUsername</param-name> <param-value>OdMBLNGI1Mbc+d6Zr9Goeajg/HjaRegky6dwSwBtSbQ5/LF8z5CLjIMxsNpBiL3yhHSTYBjk/TNdxtB3gypAOg==</param-value> </init-param> <init-param> <!-- 密码 --> <param-name>loginPassword</param-name> <param-value>NgP3sOGmM04KJeEK6yKGQjpRkSD+K33gjExuDrTpnshLNuFAbtXecDJHFpf6OAN6g7LMCtf01UDz95A0FgwmWA==</param-value> </init-param> </servlet> <servlet-mapping> <servlet-name>DruidStatView</servlet-name> <url-pattern>/druid/*</url-pattern> </servlet-mapping>直接访问 :localhost:端口/项目/druid/index.html 即可进入页面。密码为在web.xml进行配置的密码。
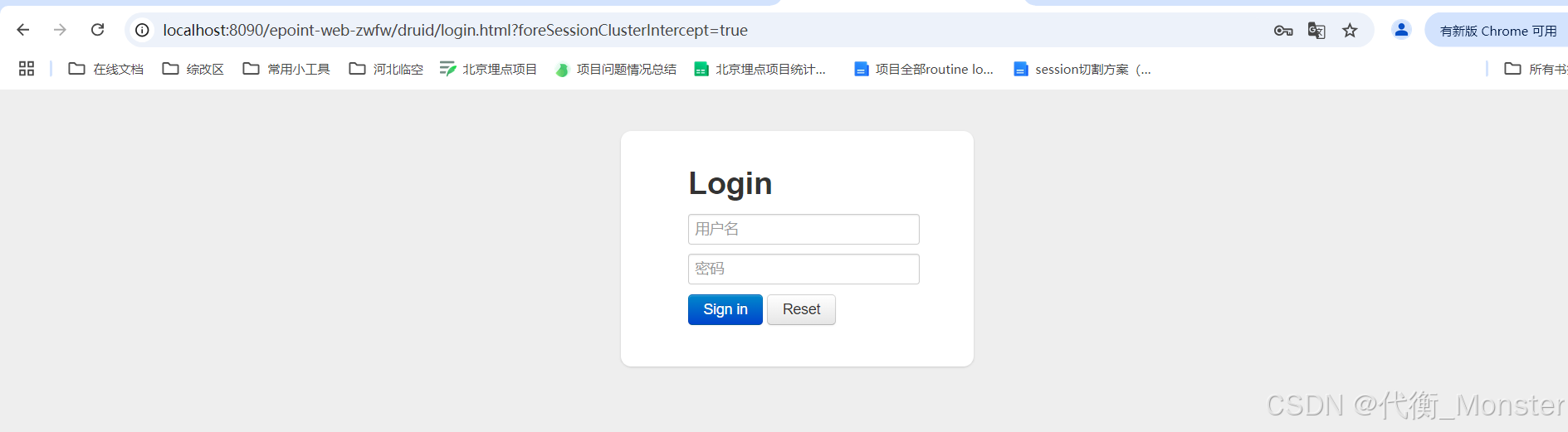
-
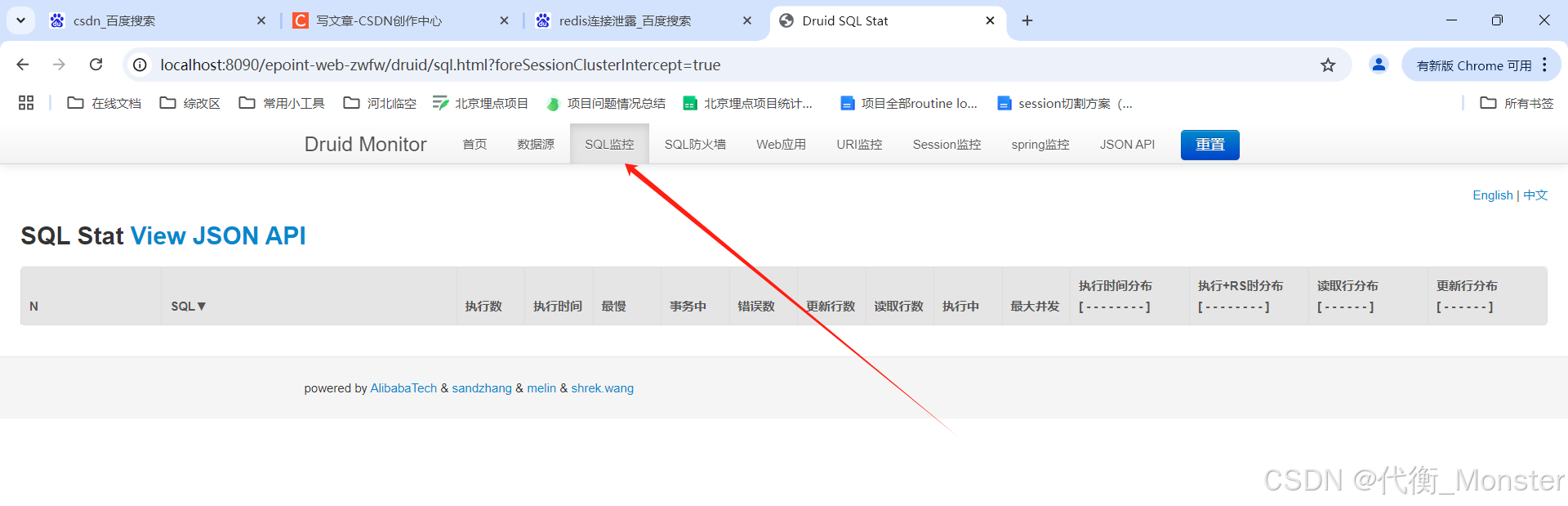
-
如果配置了框架的过滤器:
-
<filter> <filter-name>EpointSecurityGetFilter</filter-name> <filter-class>com.epoint.frame.security.filter.EpointSecurityGetFilter</filter-class> <async-supported>true</async-supported> </filter> <filter-mapping> <filter-name>EpointSecurityGetFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- shiro登录安全 --> <filter> <filter-name>shiroFilter</filter-name> <filter-class>com.epoint.authenticator.filter.EpointShiroFilter</filter-class> <async-supported>true</async-supported> </filter> <filter-mapping> <filter-name>shiroFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <filter> <filter-name>EpointSecurityPostFilter</filter-name> <filter-class>com.epoint.frame.security.filter.EpointSecurityPostFilter</filter-class> <async-supported>true</async-supported> </filter> <filter-mapping> <filter-name>EpointSecurityPostFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- cxf webservice --> <servlet> <servlet-name>CXFServlet</servlet-name> <servlet-class>org.apache.cxf.transport.servlet.CXFServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>CXFServlet</servlet-name> <url-pattern>/services/*</url-pattern> </servlet-mapping>则访问页面时优先会被框架安全拦截,密码为:
-
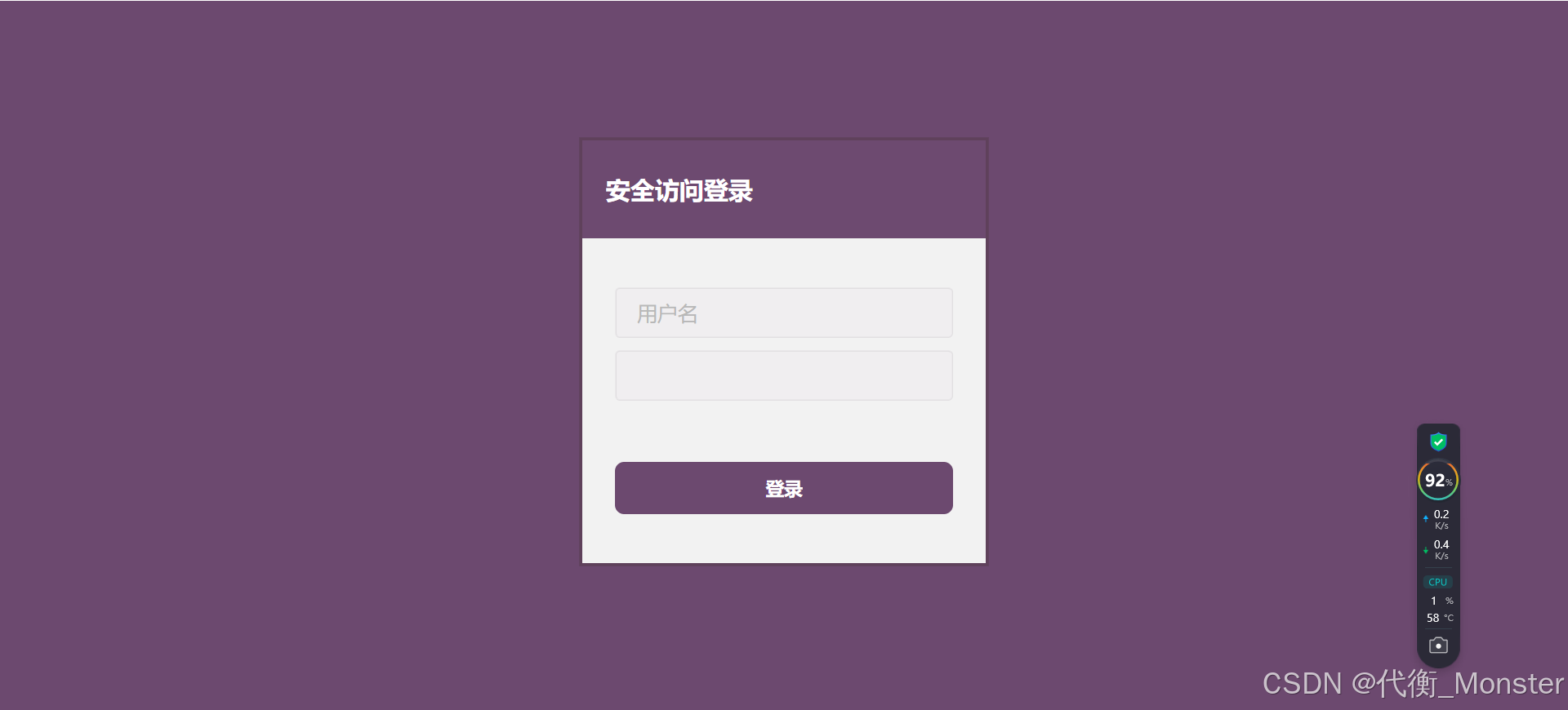
-

-
可以根据里面的Sql进行优化
-
MongDB数据库,由于我方业务层面只会用certinfoguid值进行查询,所以必须建立索引
-
查询索引是否存在:db.certinfoextension.getIndexes()
创建索引:db.certinfoextension.createIndex({certinfoguid:1}) -
4、Mysql 慢Sql 以及数据库的处理和优化
-
数据库层面的优化:
检查MYSQL数据库缓存配置,innodb_buffer_pool_size的大小
Ø 在数据库中执行该语句可直接查出,单位字节
show variables like 'innodb_buffer_pool%' ##可以查出多个参数值
select @@innodb_buffer_pool_size/1024/1024/1024 ##字节转G
Ø 调整innodb_buffer_pool_size的大小(字节大小按服务器物理内存的60%-70%计算出的值配置)
① 在线调整
SET GLOBAL innodb_buffer_pool_size = 3221225472 ##单位字节
② 配置文件调整
Windows操作系统:Mysql/my.ini⽂件并打开,innodb_buffer_pool_size的大小修改,并重启MYSQL服务
Linux操作系统:etc/my.cnf文件并打开,innodb_buffer_pool_size的大小修改,并重启MYSQL服务
上述2个调整方式二选一调整即可。
注:缓存配置太低,会导致经常读磁盘,缓存页一直在换入换出,导致sql第一次执行慢,第二次执行快的情况,从而也导致系统功能卡顿,这个缓存是根据最近使用原则淘汰的,越久没使用的就容易换出。
-
设置超时时间:更改当前锁超时时间为10秒
SET innodb_lock_wait_timeout=10;更改全局锁超时时间为10秒
SET GLOBAL innodb_lock_wait
建立索引(所有的优缺点在这里就不做赘述了)
采用 explain 查看执行计划
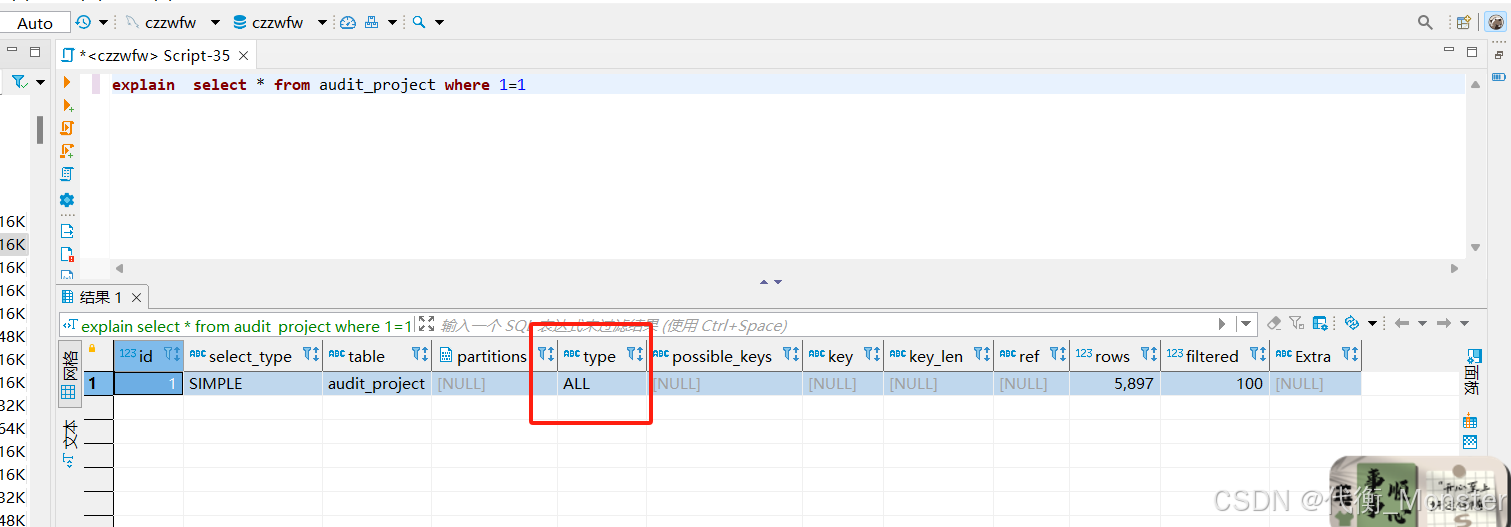
从最好到最差依次是 system > const > eq_ref >ref >range>index > All
在建索引的时候要根据Sql的执行顺序以及数据类型进行建立符合索引,避免建立重复复合索引,导致索引被影响
多表联合查询时,注意哪个表为基表!(在查看执行计划的时候,第一个为基表)
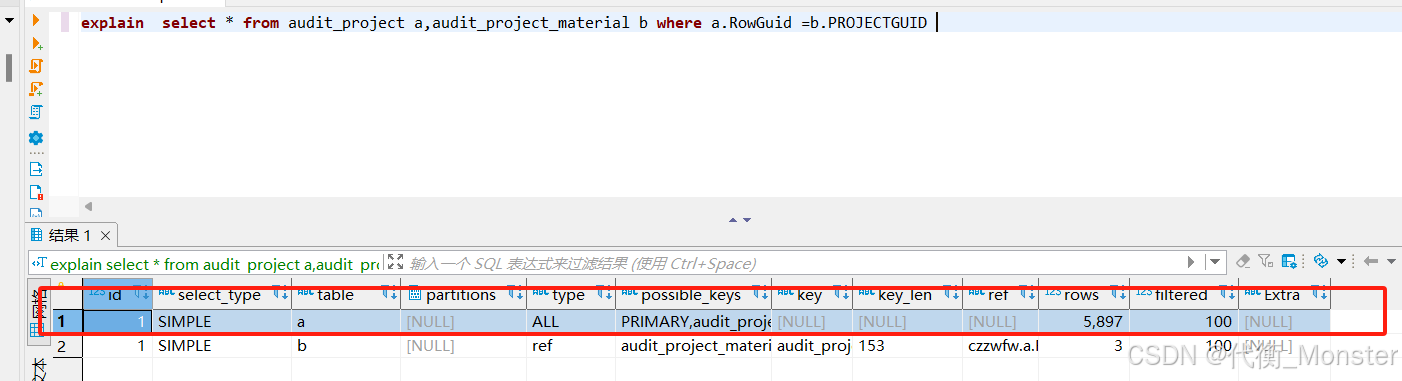
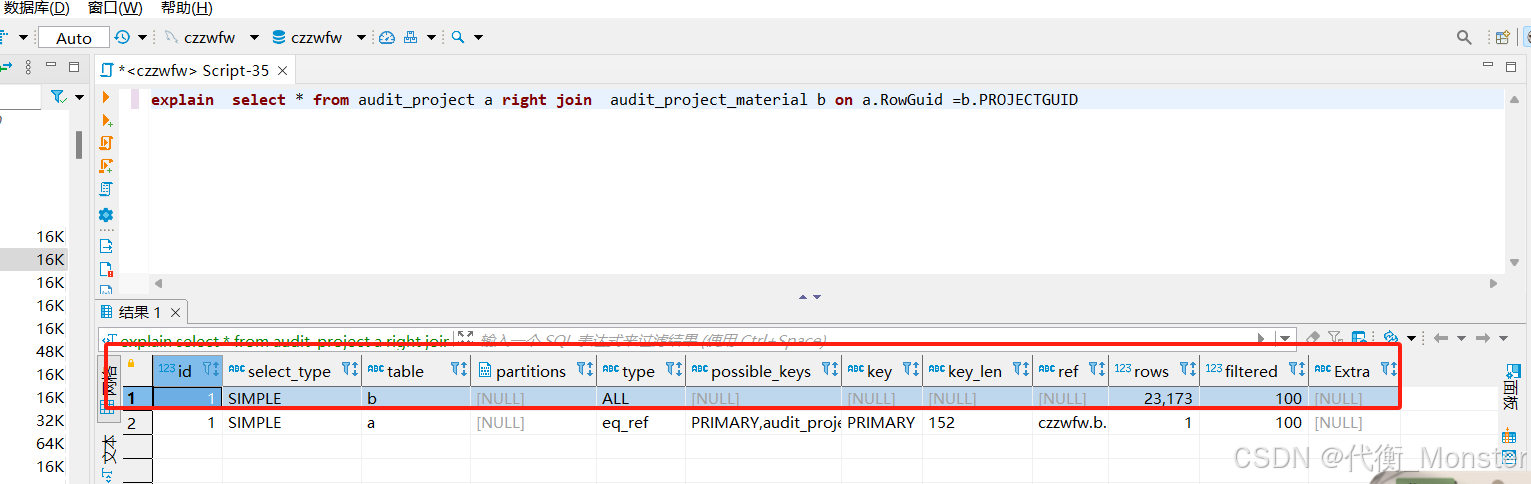
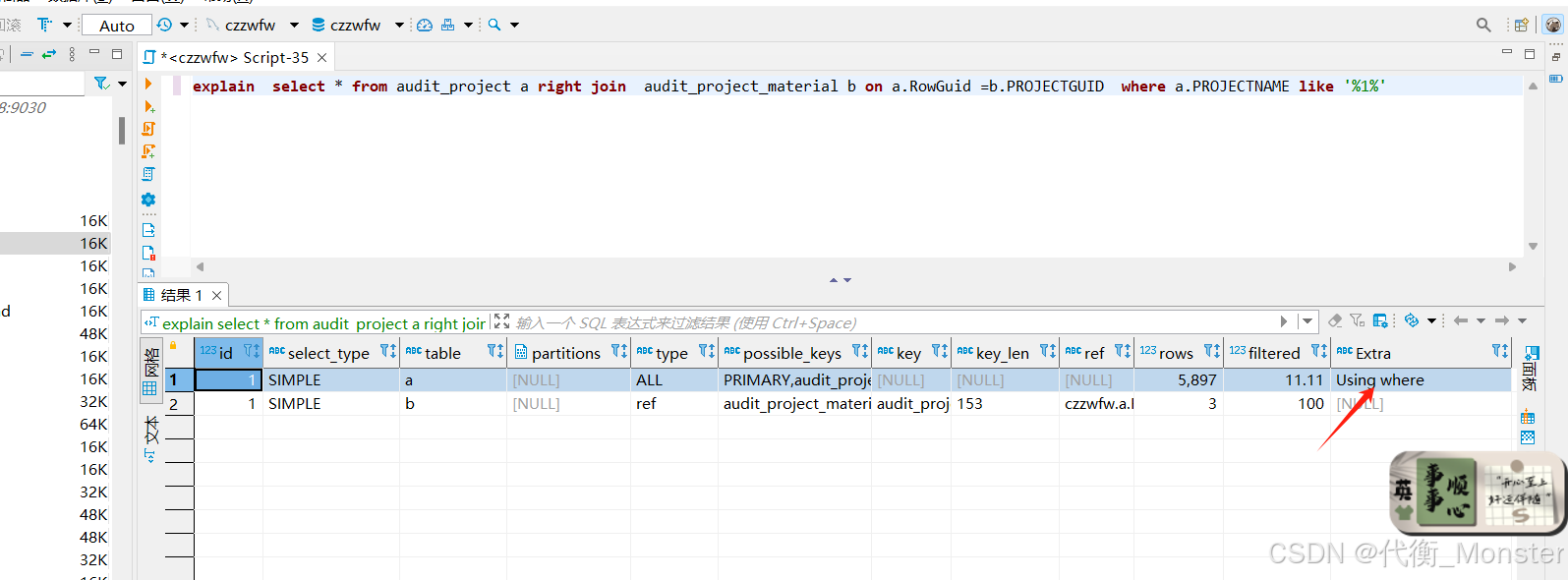
联表时索引必须全部命中才会生效,如果单独建立索引引发回表查询则不能生效最佳索引!
有Using where 则证明回表查询,说明不能直接从索引里面返回结果
索引设计原则
1、代码先行,索引后上
建完表立刻建立索引是错误的做法,应该等到主体业务功能开发完毕,将涉及到该表相关的 SQL 集中出来进行分析后再建立索引。
2、联合索引尽量覆盖条件
比如可以设计一个或者两三个联合索引(尽量少建单值索引),让每一个联合索引都尽量去包含 SQL 语句里的 where、order by、group by 的字段,还要确保这些联合索引的字段顺序尽量满足 SQL 查询的最左前缀原则。
3、不要在小基数字段上建立索引
索引基数是指这个字段在表里总共有多少个不同的值,比如一张表总共 100 万行记录,其中有个性别字段,其值不是男就是女,那么该字段的基数就是 2。
若对这种小基数字段建立索引的话,不如全表扫描,因为在索引树里就包含男和女两种值,无法进行快速的二分查找,在此使用索引毫无意义。
一般建立索引,尽量使用基数比较大的字段,即值的种类比较多的字段,才能发挥出 B+ 树快速二分查找的优势。
4、长字符串我们可以采用前缀索引
尽量对字段类型较小的列设计索引,例如 tinyint 等,因为字段类型较小,则占用磁盘空间也会比较小,此时在搜索时性能也相对好些。
但并非绝对,很多时候需要针对 varchar(255) 这类字段建立索引,此时多占用一些磁盘空间则变成必要。
对于 varchar(255) 这类的大字段可能会比较占用磁盘空间,因此需考虑优化,例如针对此字段的前 20 个字符建立索引,即将此字段里每个值的前 20 个字符放在索引树里,类似于 KEY index(name(20),age,position)。
此时在 where 条件里搜索时,若是根据 name 字段来搜索,便会先到索引树里根据 name 字段的前 20 个字符去搜索,定位到前缀匹配的部分数据之后,再回到聚簇索引提取完整的 name 字段值进行比对。
但若 order by name 时,name 会因为在索引树里仅包含前 20 个字符,导致此排序无法使用索引, group by 亦同理。
5、where与order by冲突时优先where
一般是让 where 条件去使用索引来快速筛选出来一部分指定的数据,接着再进行排序。
因为大多数情况基于索引进行 where 筛选往往可以最快速度筛选出需要的少部分数据,之后再排序,这样成本可能会小很多。
内存溢出问题:
如果epass平台没有产生这个文件,需要检查这个配置文件是否配置此文件(tomcat/bin/wrapper.conf这个路径下)
是内存溢出后tomcat才会自动导出这个文件。并且,新的没法覆盖旧的,也就是如果老的heapdump.hprof还在logs下放着,就算后面再次内存溢出了,新的heapdump.hprof也会因为老的还存在无法完成导出。所以,发现内存溢出下载了这个文件后就把它删掉,避免影响下次生成。
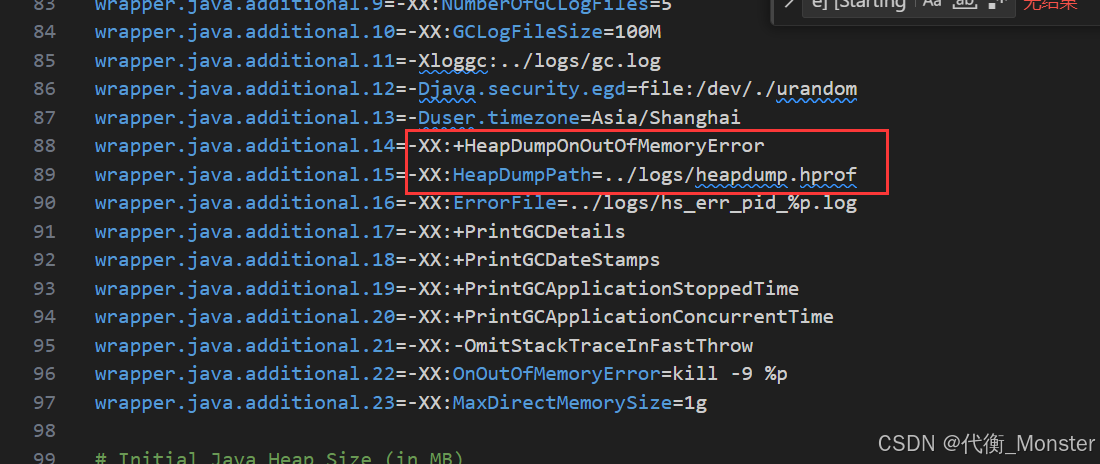
堆栈内容在jvm是实时变化的,但是不会生成内存快照。只这么配置了才会在内存溢出时生成一份。
是整个jvm堆栈信息,尤其时内存溢出时,因为堆满了,所以大小会达到-Xmx的大小。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











