







前言:本文将力图说清楚如何使用kubeadm快速部署一个Kubernetes v1.32.2集群,并简单说明如何在集群上部署Cilium网络插件。
一、主机环境预设
本示例中的Kubernetes集群部署将基于以下环境进行。
-
OS: Ubuntu 24.04
-
Kubernetes:v1.32.2
-
Continerd.io:1.7.25
-
Nerdctl:v2.0.1
-
BuildKitd:v0.18.1
二、测试环境说明
测试使用的Kubernetes集群可由一个master主机及一个以上(建议至少两个)node主机组成,这些主机可以是物理服务器,也可以运行于vmware、virtualbox或kvm等虚拟化平台上的虚拟机,甚至是公有云上的VPS主机。
本测试环境将由k8s-master01、k8s-node01、k8s-node02和k8s-node03四个独立的主机组成,它们分别拥有4核心的CPU及8G的内存资源,操作系统环境均为最小化部署的Ubuntu Server 24.04.1 LTS。此外,各主机需要预设的系统环境如下:
(1)借助于chronyd服务(程序包名称chrony)设定各节点时间精确同步;
(2)通过DNS完成各节点的主机名称解析;
(3)各节点禁用所有的Swap设备;
(4)各节点禁用默认配置的iptables防火墙服务;
三、设定时钟同步
若节点可直接访问互联网,安装chrony程序包后,可直接启动chronyd系统服务,并设定其随系统引导而启动。随后,chronyd服务即能够从默认的时间服务器同步时间。
~# apt update && apt install chrony -y
~# vim /etc/chrony/chrony.conf
建议用户配置使用本地的的时间服务器,在节点数量众多时尤其如此。存在可用的本地时间服务器时,修改节点的/etc/chrony/chrony.conf配置文件,并将时间服务器指向相应的主机即可,配置格式如下:
server ntp.aliyun.com iburst四、主机名解析
出于简化配置步骤的目的,本测试环境使用hosts文件进行各节点名称解析,文件内容如下所示。其中,我们使用kubeapi主机名作为API Server在高可用环境中的专用接入名称,也为控制平面的高可用配置留下便于配置的余地。
vim /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.31.5.1 k8s-master01 kubeapi.linux.com
172.31.5.11 k8s-node01
172.31.5.12 k8s-node02
172.31.5.13 k8s-node03五、禁用Swap设备
部署集群时,kubeadm默认会预先检查当前主机是否禁用了Swap设备,并在未禁用时强制终止部署过程。因此,在主机内存资源充裕的条件下,需要禁用所有的Swap设备,否则,就需要在后文的kubeadm init及kubeadm join命令执行时额外使用相关的选项忽略检查错误。
关闭Swap设备,需要分两步完成。首先是关闭当前已启用的所有Swap设备:
~# swapoff -a
而后编辑/etc/fstab配置文件,注释用于挂载Swap设备的所有行。另外,在Ubuntu 2004及之后版本的系统上,若要彻底禁用Swap,可以需要类似如下命令进一步完成。
~# systemctl --type swap
而后,将上面命令列出的每个设备,使用systemctl mask命令加以禁用。
~# systemctl mask SWAP_DEV
六、禁用默认的防火墙服务
Ubuntu和Debian等Linux发行版默认使用ufw(Uncomplicated FireWall)作为前端来简化 iptables的使用,处于启用状态时,它默认会生成一些规则以加强系统安全。出于降低配置复杂度之目的,本文选择直接将其禁用。
~# ufw disable
~# ufw status
七、安装容器运行时 Containerd
提示:
-
以下操作需要在本示例中的所有四台主机上分别进行;
Ubuntu 2404上安装Containerd有两种选择,一是Ubuntu系统官方程序包仓库中的containerd,另一个则是Docker社区提供的containerd.io。本文将选择使用后者。
7.1: 安装并启动Containerd.io
首先,生成containerd.io相关程序包的仓库,这里以华为云的镜像服务器为例进行说明:
~# apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common
~# curl -fsSL https://mirrors.huaweicloud.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
~# sudo add-apt-repository "deb [arch=amd64] https://mirrors.huaweicloud.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
~# apt update
接下来,安装相关的程序包,Ubuntu 24.04上要使用的程序包名称为containerd.io。
~# apt-cache madison containerd
~# apt-get install containerd.io
7.2: 配置Containerd.io
首先,运行如下命令打印默认并保存默认配置
~# containerd config default > /etc/containerd/config.toml
接下来,编辑生成的配置文件,完成如下几项相关的配置:
1. 修改containerd使用SystemdCgroup
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true2. 配置containerd使用国内Mirror站点上的pause镜像及指定的版本
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.10"3. 配置containerd 使用国内的image加速服务,以加速image获取
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.mirrors.ustc.edu.cn"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"]
endpoint = ["https://registry.aliyuncs.com/google_containers"]最后,重新启动containerd服务即可。~# systemctl daemon-reload ~# systemctl restart containerd
7.3:配置crictl客户端
安装containerd.io时,会自动安装命令行客户端工具crictl,该客户端通常需要通过正确的unix sock文件才能接入到containerd服务。编辑配置文件/etc/crictl.yaml,添加如下内容即可。
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false随后即可正常使用crictl程序管理Image、Container和Pod等对象。另外,containerd.io还有另一个名为nerdctl的客户端程序可以,其功能也更为丰富。
7.4:配置nerdctl客户端
~# wget https://github.com/containerd/nerdctl/releases/download/v2.0.1/nerdctl-2.0.1-linux-amd64.tar.gz
~# tar xf nerdctl-2.0.1-linux-amd64.tar.gz
~# mv containerd* /usr/local/bin
~# mv nerdctl /usr/local/bin
vim /etc/nerdctl/nerdctl.toml
namespace = "k8s.io"
debug = false
debug_full = false
insecure_registry = true~# nerdctl version
7.5:配置buildkitd
必要基础知识:容器技术除了的docker之外,还有coreOS的rkt、google的gvisor、以及docker开源的containerd、redhat 的podman、阿⾥的pouch等,为了保证容器⽣态的标准性和健康可持续发展,包括Linux 基⾦会、Docker、微软、 红帽、⾕歌和IBM等公司在2015年6⽉共同成⽴了⼀个叫open container(OCI)的组织,其⽬的就是制定开放的标准的容器规范,⽬前OCI⼀共发布了两个规范,分别是runtime spec和image format spec,有了这两个规范,不同的容器公司开发的容器只要兼容这两个规范,就可以保证容器的可移植性和相互可操作性。
buildkit: 从Docker公司的开源出来的⼀个镜像构建⼯具包,⽀持OCI标准的镜像构建。
~# wget https://github.com/moby/buildkit/releases/download/v0.18.1/buildkit-v0.18.1.linux-amd64.tar.gz
~# tar xvf buildkit-v0.18.1.linux-amd64.tar.gz
~# mv bin/* /usr/local/bin
~# buildctl --help
vim /lib/systemd/system/buildkit.socket
[Unit]
Description=BuildKit
Documentation=https://github.com/moby/buildkit
[Socket]
ListenStream=%t/buildkit/buildkitd.sock
[Install]
WantedBy=sockets.target
vim /lib/systemd/system/buildkitd.service
[Unit]
Description=BuildKit
Requires=buildkit.socket
After=buildkit.socketDocumentation=https://github.com/moby/buildkit
[Service]
ExecStart=/usr/local/bin/buildkitd --oci-worker=false --containerd-worker=true
[Install]
WantedBy=multi-user.target~# systemctl daemon-reload && systemctl enable buildkitd && systemctl restart buildkitd && systemctl status buildkitd
7.6: 内核参数优化
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
vm.max_map_count=262144
kernel.pid_max=4194303
fs.file-max=1000000
net.ipv4.tcp_max_tw_buckets=6000
net.netfilter.nf_conntrack_max=2097152
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness=0
内核模块开机挂载:
vim /etc/modules-load.d/modules.conf
ip_vs
ip_vs_lc
ip_vs_lblc
ip_vs_lblcr
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs_dh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
ip_tables
ip_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
xt_set
br_netfilter
nf_conntrack
overlay
#重启后验证内核模块与内存参数:
root@k8s-master1:~# lsmod | grep br_netfilter
br_netfilter 32768 0
bridge 307200 1 br_netfilter
root@k8s-master1:~# sysctl -a | grep bridge-nf-call-iptables
net.bridge.bridge-nf-call-iptables = 1八、安装kubeadm
自 v1.28版本开始,Kubernetes官方变更了仓库的存储路径及使用方式(不同的版本将会使用不同的仓库),并提供了向后兼容至v1.24版本。因此,对于v1.24及之后的版本来说,可以使用如下有别于传统配置的方式来安装相关的程序包。以本示例中要安装的v1.32版本为例来说,配置要使用的程序包仓库,需要使用的命令如下。如若需要安装其它版本,则将下面命令中的版本号“v1.31.2”予以替换即可。
~# apt-get update
1. 更新 apt 包索引并安装使用 Kubernetes apt 仓库所需要的包:
~# apt-get install -y apt-transport-https ca-certificates curl gpg
2. 下载用于 Kubernetes 软件包仓库的公共签名密钥。
~# curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
3. 添加 Kubernetes apt 仓库。此仓库仅包含适用于 Kubernetes 1.32 的软件包; 对于其他 Kubernetes 次要版本,则需要更改 URL 中的 Kubernetes 次要版本以匹配你所需的次要版本。
~# echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.32/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
4. 更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本:
~# apt-get update
~# apt-get install -y kubelet kubeadm kubectl
安装完成后,要确保kubeadm等程序文件的版本,这将也是后面初始化Kubernetes集群时需要明确指定的版本号。
8.1: 初始化master节点(在master01上完成如下操作)
在运行初始化命令之前先运行如下命令单独获取相关的镜像文件,而后再运行后面的kubeadm init命令,以便于观察到镜像文件的下载过程。
~# kubeadm config images list
上面的命令会列出类似如下的Image信息,由如下的命令结果可以看出,相关的Image都来自于registry.k8s.io,该服务上的Image通常需要借助于代理服务才能访问到。
registry.k8s.io/kube-apiserver:v1.32.2
registry.k8s.io/kube-controller-manager:v1.32.2
registry.k8s.io/kube-scheduler:v1.32.2
registry.k8s.io/kube-proxy:v1.32.2
registry.k8s.io/coredns/coredns:v1.11.3
registry.k8s.io/pause:3.10
registry.k8s.io/etcd:3.5.16-0若需要从国内的Mirror站点下载Image,还需要在命令上使用“--image-repository”选项来指定Mirror站点的相关URL。例如,下面的命令中使用了该选项将Image Registry指向国内可用的Aliyun的镜像服务,其命令结果显示的各Image也附带了相关的URL。
~# kubeadm config images list --image-repository=registry.aliyuncs.com/google_containers
运行下面的命令即可下载需要用到的各Image。需要注意的是,如果需要从国内的Mirror站点下载Image,同样需要在命令上使用“--image-repository”选项来指定Mirror站点的相关URL。
~# kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.32.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.32.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.32.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.32.2
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.11.3
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.10
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.16-0而后即可进行master节点初始化。kubeadm init命令支持两种初始化方式,一是通过命令行选项传递关键的部署设定,另一个是基于yaml格式的专用配置文件,后一种允许用户自定义各个部署参数,在配置上更为灵活和便捷。下面使用的通过命令行选项来初始化。
~# kubeadm init \
--control-plane-endpoint="kubeapi.linux.com" \
--kubernetes-version=v1.32.2 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--upload-certs \
--skip-phases=addon/kube-proxy命令中的各选项简单说明如下:
-
--kubernetes-version:kubernetes程序组件的版本号,它必须要与安装的kubelet程序包的版本号相同;
-
--control-plane-endpoint:控制平面的固定访问端点,可以是IP地址或DNS名称,会被用于集群管理员及集群组件的kubeconfig配置文件的API Server的访问地址;单控制平面部署时可以不使用该选项;
-
--pod-network-cidr:Pod网络的地址范围,其值为CIDR格式的网络地址,通常,Flannel网络插件的默认为10.244.0.0/16,Project Calico插件的默认值为192.168.0.0/16,而Cilium的默认值为10.0.0.0/8;
-
--service-cidr:Service的网络地址范围,其值为CIDR格式的网络地址,kubeadm使用的默认为10.96.0.0/12;通常,仅在使用Flannel一类的网络插件需要手动指定该地址;
-
--apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址;
-
--skip-phases=addon/kube-proxy:跳过kube-porxy的部署,Cilium自身即为kubernetes CNI插件,同时还可以完全取代kube proxy的功能;
-
--token-ttl:共享令牌(token)的过期时长,默认为24小时,0表示永不过期;为防止不安全存储等原因导致的令牌泄露危及集群安全,建议为其设定过期时长。未设定该选项时,在token过期后,若期望再向集群中加入其它节点,可以使用如下命令重新创建token,并生成节点加入命令。
kubeadm token create --print-join-command8.2: 初始化完成后的操作步骤
对于Kubernetes系统的新用户来说,无论使用上述哪种方法,命令运行结束后,请记录最后的kubeadm join命令输出的最后提示的操作步骤。下面的内容是需要用户记录的一个命令输出示例,它提示了后续需要的操作步骤。
# 下面是成功完成第一个控制平面节点初始化的提示信息及后续需要完成的步骤
Your Kubernetes control-plane has initialized successfully!
# 为了完成初始化操作,管理员需要额外手动完成几个必要的步骤
To start using your cluster, you need to run the following as a regular user:
# 第1个步骤提示, Kubernetes集群管理员认证到Kubernetes集群时使用的kubeconfig配置文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 我们也可以不做上述设定,而使用环境变量KUBECONFIG为kubectl等指定默认使用的kubeconfig;
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
# 第2个步骤提示,为Kubernetes集群部署一个网络插件,具体选用的插件则取决于管理员;
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
# 第3个步骤提示,向集群添加额外的控制平面节点,但本文会略过该步骤,并将在其它文章介绍其实现方式。
You can now join any number of the control-plane node running the following command on each as root:
# 在部署好kubeadm等程序包的其他控制平面节点上以root用户的身份运行类似如下命令,
# 命令中的hash信息对于不同的部署环境来说会各不相同;该步骤只能在其它控制平面节点上执行;
kubeadm join kubeapi.linux.com:6443 --token ss09jc.qhvkk48lwtdb5xz7 \
--discovery-token-ca-cert-hash sha256:2f8028974b3830c5cb13163e06677f52711282b38ee872485ea81992c05d8a78 \
--control-plane --certificate-key e01e6227c40c076dcebd1483d09191207da018610aab48fc240fa74a6ccefb80
# 因为在初始化命令“kubeadm init”中使用了“--upload-certs”选项,因而初始化过程会自动上传添加其它Master时用到的数字证书等信息;
# 出于安全考虑,这些内容会在2小时之后自动删除;
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
# 第4个步骤提示,向集群添加工作节点
Then you can join any number of worker nodes by running the following on each as root:
# 在部署好kubeadm等程序包的各工作节点上以root用户运行类似如下命令;
kubeadm join kubeapi.linux.com:6443 --token ss09jc.qhvkk48lwtdb5xz7 \
--discovery-token-ca-cert-hash sha256:2f8028974b3830c5cb13163e06677f52711282b38ee872485ea81992c05d8a78另外,kubeadm init命令完整参考指南请移步官方文档,地址为https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/。
8.3: 设定kubectl
kubectl是kube-apiserver的命令行客户端程序,实现了除系统部署之外的几乎全部的管理操作,是kubernetes管理员使用最多的命令之一ubectl需经由API server认证及授权后方能执行相应的管理操作,kubeadm部署的集群为其生成了一个具有管理员权限的认证配置文件/etc/kubernetes/admin.conf,它可由kubectl通过默认的“$HOME/.kube/config”的路径进行加载。当然,用户也可在kubectl命令上使用--kubeconfig选项指定一个别的位置。
下面复制认证为Kubernetes系统管理员的配置文件至目标用户(例如当前用户root)的家目录下:
~# mkdir -p ~/.kube
~# cp -i /etc/kubernetes/admin.conf ~/.kube/config
九、部署网络插件Cilium
9.1:Cilium工作机制及组件介绍
简介:基于eBPF和XDP的kubernetes高性能网络插件,直接在内核级或插件级支持可观测性和安全机制,包括(network policy),同时还是ServiceMesh(服务网格)的数据平面,istio 完全可以把cilium 直接作为原生的内核级原生的数据平面,所以在一定程度上避免了像基于envoy这样的不得不损耗百分之二三十性能来获取高级流量路由逻辑的功能,结合cilium这个问题几乎将不存在或者说它的性能开销极小极小可以忽略不计。
Cilium 关键组件
- Agent
1.由Daemonset编排运行集群中的每个节点上
2.从kubernetes或API接口接受配置:网络、LB(负载均衡)、Network Policy等
3.基于SDK调用节点上的eBPF实现相关的功能
- 将用户提供的 例如:网络、LB(负载均衡)、Network Policy 这样配置转化成代码并配置内核级实现,当需要改变配置在内核级实现自定义功能时,通过配置文件编写以后,将配置文件装入给cilium agent,由cilium agent自动转换成eBPF 并提交给内核级eBPF引擎来执行。
- Cilium Client
1.命令行工具,通过Rest API同当前节点上的Cilium Agent进行交互
2.常用与检查本地Cilium Agent的状态
3.也可用于直接访问eBPF Map(eBPF 映射信息)
4.另外还有一个客户端工具成为Cilium CLI,负责管理整个Cilium,而非当前的Cilium Agent
5.Cilium Client只是单节点的工作端工具,Cilium CLI 才是负责管理整个Cilium集群的。
- Operator
1.负责监视和维护整个集群
2.同Cilium的网络功能和网络策略机制不相关
- 其故障并不会影响报文转发和网络策略的进行
- 但会影响IPAM(地址分配)和kvstore的数据存取
- CNI Plugin
1.Cilium自身即为kubernetes CNI插件,同时还可以完全取代kube proxy的功能
hubble
- servier
- Realy
- Client(CLI)
- Graphical UI
eBPF
Data Store
- Kubernetes CRDs(Default)
- Key-Value Store9.2:部署cilium
Kubernetes系统上Pod网络的实现依赖于第三方插件进行,这类插件有近数十种之多,较为著名的有flannel、calico、Cilium等,下面的命令用于在线部署Cilium至Kubernetes系统之上,我们需要在初始化的第一个master节点k8s-master01上运行如下命令,以完成部署。
~# curl -LO https://github.com/cilium/cilium-cli/releases/download/v0.17.0/cilium-linux-amd64.tar.gz
~# tar xf cilium-linux-amd64.tar.gz
~# mv cilium /usr/local/bin/
完成以上这些步骤就可以直接执行cilium命令了
~# cilium --help
使用 cilium install 就可以直接安装cilium了
cilium install \
--set kubeProxyPeplacement=strict \
--set ipam.mode=kubernetes \
--set routingMode=tunnel \
--set tunnelProtocol=vxlan \
--set ipam.operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16 \
--set ipam.Operator.ClusterPoolIPv4MaskSize=24命令中的各选项简单说明如下:
-
--set kubeProxyPeplacement=strict:kube-proxy替换方法strict,完全取代proxy。
-
--set ipam.mode=kubernetes:地址模式,地址分配要基于kubernetes自己节点上的所分配给每个节点的CIDR来完成地址分配。
-
--set routingMode=tunnel:路由模式tunnel
-
--set tunnelProtocol=vxlan:隧道协议vxlan
-
--set ipam.operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16:使用的网络10.244.0.0/16
-
--set ipam.Operator.ClusterPoolIPv4MaskSize=24:并且每个节点子网掩码划分使用的是24位掩码
使用 ~# cilium status 查看状态信息
root@k8s-master01:~# cilium status
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Envoy DaemonSet: OK
\__/¯¯\__/ Hubble Relay: disabled
\__/ ClusterMesh: disabled
DaemonSet cilium Desired: 1, Ready: 1/1, Available: 1/1
DaemonSet cilium-envoy Desired: 1, Ready: 1/1, Available: 1/1
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
Containers: cilium Running: 1
cilium-envoy Running: 1
cilium-operator Running: 1
clustermesh-apiserver
hubble-relay
Cluster Pods: 2/2 managed by Cilium
Helm chart version: 1.17.0到此cilium网络插件就部署到kubernetes集群上了
另外,也可以进入到每个节点的集群内部去查看更为详细的状态信息
root@k8s-master01:~# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
cilium-envoy-cgpds 1/1 Running 0 4m54s
cilium-kx4p5 1/1 Running 0 4m54s
cilium-operator-79574bf9b8-4bkkl 1/1 Running 0 4m54s
coredns-668d6bf9bc-hqxlz 1/1 Running 0 57m
coredns-668d6bf9bc-vnrrr 1/1 Running 0 57m
etcd-k8s-master01 1/1 Running 0 57m
kube-apiserver-k8s-master01 1/1 Running 0 57m
kube-controller-manager-k8s-master01 1/1 Running 0 57m
kube-scheduler-k8s-master01 1/1 Running 0 57m
#使用kubectl exec 进入交互式bash接口
root@k8s-master01:~# kubectl exec -it cilium-kx4p5 -n kube-system -- /bin/bash
root@k8s-master01:/home/cilium# cilium status
KVStore: Disabled
Kubernetes: Ok 1.32 (v1.32.2) [linux/amd64]
Kubernetes APIs: ["EndpointSliceOrEndpoint", "cilium/v2::CiliumClusterwideNetworkPolicy", "cilium/v2::CiliumEndpoint", "cilium/v2::CiliumNetworkPolicy", "cilium/v2::CiliumNode", "cilium/v2alpha1::CiliumCIDRGroup", "core/v1::Namespace", "core/v1::Pods", "core/v1::Service", "networking.k8s.io/v1::NetworkPolicy"]
KubeProxyReplacement: True [ens33 172.31.5.1 fe80::20c:29ff:fe44:4539 (Direct Routing)]
Host firewall: Disabled
SRv6: Disabled
CNI Chaining: none
CNI Config file: successfully wrote CNI configuration file to /host/etc/cni/net.d/05-cilium.conflist
Cilium: Ok 1.17.0 (v1.17.0-c2bbf787)
NodeMonitor: Listening for events on 128 CPUs with 64x4096 of shared memory
Cilium health daemon: Ok
IPAM: IPv4: 4/254 allocated from 10.244.0.0/24,
IPv4 BIG TCP: Disabled
IPv6 BIG TCP: Disabled
BandwidthManager: Disabled
Routing: Network: Tunnel [vxlan] Host: Legacy
Attach Mode: TCX
Device Mode: veth
Masquerading: IPTables [IPv4: Enabled, IPv6: Disabled]
Controller Status: 31/31 healthy
Proxy Status: OK, ip 10.244.0.97, 0 redirects active on ports 10000-20000, Envoy: external
Global Identity Range: min 256, max 65535
Hubble: Ok Current/Max Flows: 4095/4095 (100.00%), Flows/s: 24.01 Metrics: Disabled
Encryption: Disabled
Cluster health: 1/1 reachable (2025-02-23T10:58:11Z)
Name IP Node Endpoints
Modules Health: Stopped(0) Degraded(0) OK(55)
#这时会发现和在外面执行cilium status的结果不一样,是因为这是cilium client 只跟本地节点交互,刚才不是在容器内部执行的称为 cilium cli是管理整个集群的使用 ~# cilium status --verbose 还可以显示出更加详细的信息
到此为止,主节点就没问题了插件也部署上来了,就可以添加node节点了。
十、添加node节点
root@k8s-node01:~# kubeadm join kubeapi.linux.com:6443 --token ss09jc.qhvkk48lwtdb5xz7 \
--discovery-token-ca-cert-hash sha256:7f647e860a2f59b56fe0abfc31a943e7799f2b0edb9ee5436e965613e7ad49cc
[preflight] Running pre-flight checks
[preflight] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[preflight] Use 'kubeadm init phase upload-config --config your-config.yaml' to re-upload it.
W0223 19:09:44.266345 5024 configset.go:78] Warning: No kubeproxy.config.k8s.io/v1alpha1 config is loaded. Continuing without it: configmaps "kube-proxy" is forbidden: User "system:bootstrap:ss09jc" cannot get resource "configmaps" in API group "" in the namespace "kube-system"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.002114321s
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
#在master节点查看
root@k8s-master01:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 70m v1.32.2
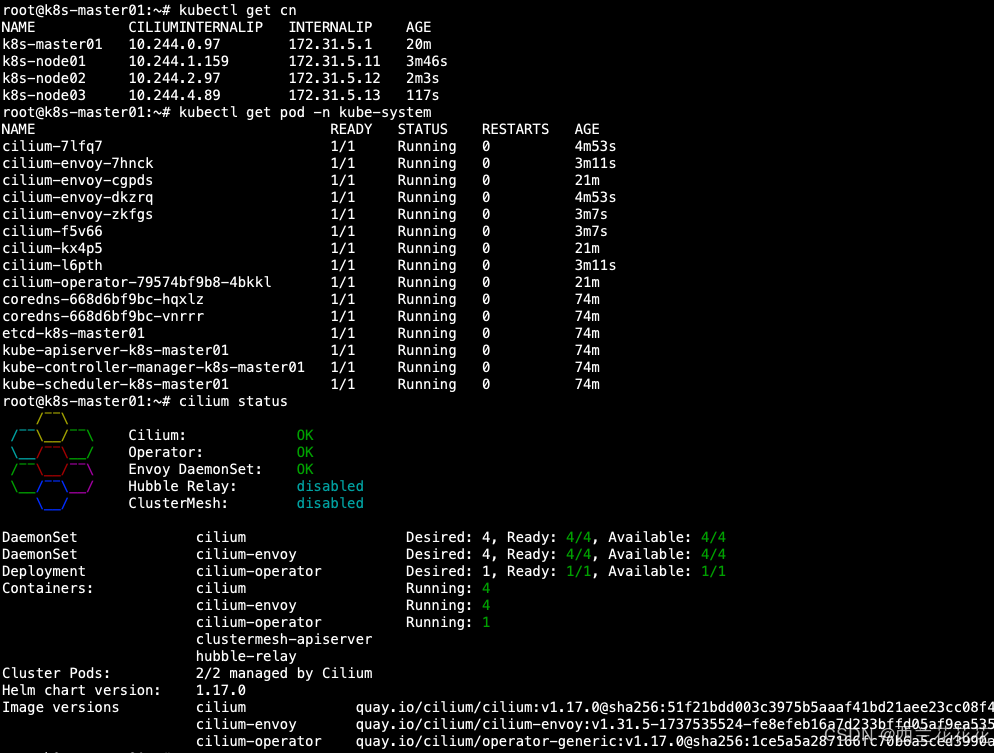
k8s-node01 Ready <none> 57s v1.32.2使用 ~# kubectl get cn 来插件cilium节点,cn 就是cilium node的简写。
root@k8s-master01:~# kubectl get cn
NAME CILIUMINTERNALIP INTERNALIP AGE
k8s-master01 10.244.0.97 172.31.5.1 17m
k8s-node01 10.244.1.159 172.31.5.11 77s因为node02和node03还没有将cilium部署完成,所以使用kubectl get cn 没有显示node02和node03。
等node02和node03 Ready以后再次查看cilium
10.1: 测试跨节点通讯
#创建测试pod
root@k8s-master01:~# kubectl create deployment demoapp -registry.cn-beijing.aliyuncs.com/linux/demoapp:v1.0 --replicas=3
#如果能正常运行就证明cilium状态是正常的
root@k8s-master01:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demoapp-5b7d586f5b-fx8gd 1/1 Running 0 17s 10.244.4.48 k8s-node03 <none> <none>
demoapp-5b7d586f5b-t6hx2 1/1 Running 0 17s 10.244.1.251 k8s-node01 <none> <none>
demoapp-5b7d586f5b-t7lzf 1/1 Running 0 17s 10.244.2.48 k8s-node02 <none> <none>
#在宿主机访问pod地址测试
root@k8s-master01:~# curl 10.244.4.48
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!
root@k8s-master01:~# curl 10.244.4.48
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!
root@k8s-master01:~# curl 10.244.1.251
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t6hx2, ServerIP: 10.244.1.251!
root@k8s-master01:~# curl 10.244.1.251
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t6hx2, ServerIP: 10.244.1.251!
#进入pod中测试pod之间通讯
root@k8s-master01:~# kubectl exec -it demoapp-5b7d586f5b-t6hx2 -- /bin/sh
[root@demoapp-5b7d586f5b-t6hx2 /]# curl 10.244.2.48
demoapp v1.0 !! ClientIP: 10.244.1.251, ServerName: demoapp-5b7d586f5b-t7lzf, ServerIP: 10.244.2.48!10.2: 测试svc是否可以帮助pod接入请求
注意:我们在k8s集群的整个节点之上并没有kube-proxy,在kube-system名称空间下可以看到完全没有kube-proxy组件。
root@k8s-master01:~# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
cilium-7lfq7 1/1 Running 0 17m
cilium-envoy-7hnck 1/1 Running 0 15m
cilium-envoy-cgpds 1/1 Running 0 33m
cilium-envoy-dkzrq 1/1 Running 0 17m
cilium-envoy-zkfgs 1/1 Running 0 15m
cilium-f5v66 1/1 Running 0 15m
cilium-kx4p5 1/1 Running 0 33m
cilium-l6pth 1/1 Running 0 15m
cilium-operator-79574bf9b8-4bkkl 1/1 Running 0 33m
coredns-668d6bf9bc-hqxlz 1/1 Running 0 86m
coredns-668d6bf9bc-vnrrr 1/1 Running 0 86m
etcd-k8s-master01 1/1 Running 0 86m
kube-apiserver-k8s-master01 1/1 Running 0 86m
kube-controller-manager-k8s-master01 1/1 Running 0 86m
kube-scheduler-k8s-master01 1/1 Running 0 86m
#创建service,测试能否帮pod接入请求
root@k8s-master01:~# kubectl create service nodeport demoapp --tcp=80:80
service/demoapp created
root@k8s-master01:~# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demoapp NodePort 10.108.16.193 <none> 80:30932/TCP 5s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 90m
#集群内部可以直接访问,集群外部可以通过30932端口来访问。
root@k8s-master01:~# curl 10.108.16.193
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t6hx2, ServerIP: 10.244.1.251!
root@k8s-master01:~# curl 10.108.16.193
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!
root@k8s-master01:~# curl 10.108.16.193
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t6hx2, ServerIP: 10.244.1.251!
root@k8s-master01:~# curl 10.108.16.193
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t7lzf, ServerIP: 10.244.2.48!
root@k8s-master01:~# curl 10.108.16.193
demoapp v1.0 !! ClientIP: 10.244.0.97, ServerName: demoapp-5b7d586f5b-t7lzf, ServerIP: 10.244.2.48!
#这里可以被负载均衡到每一个pod上去,意味着即便没有kube-proxy 完全没了iptables或者ipvs规则,这里的整体服务的调度 服务的发现所有的功能依然可以实现。
#在集群外部访问
apple@Kxxeiiyy ~ % curl 172.31.5.11:30932
demoapp v1.0 !! ClientIP: 10.244.1.159, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!
apple@Kxxeiiyy ~ % curl 172.31.5.11:30932
demoapp v1.0 !! ClientIP: 10.244.1.159, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!
apple@Kxxeiiyy ~ % curl 172.31.5.11:30932
demoapp v1.0 !! ClientIP: 10.244.1.159, ServerName: demoapp-5b7d586f5b-fx8gd, ServerIP: 10.244.4.48!十一、Hubble以及prometheus指标
简介:hubble是一个分布式的网络可观测平台有四个组件,建立在cilium和eBPF之上 原生就是为了更好的观测cilium和eBPF,主要作用就是存储、展示从Cilium获取到的相关数据。
相关组件:
-
hubble UI:图形化界面,可以展示所有抓取的通信链路跟踪的相关状态信息非常直观、非常漂亮。
-
hubble CLI:用来和hubble服务器交互
-
hubble metrics:数据指标
-
hubble server:hubble能够暴露出hubble所抓取的底层的各种pod通信指标并通过暴露接口暴露出来并允许prometheus来抓取,另外cilium自身也有指标,基于cilium通信的组件间有指标,但是cilium自身作为组件来讲也有指,这些也能够暴露出来由prometheus来抓取并通过grafana展示。
11.1: 配置Cilium启用hubble
其实在cilium部署完以后启用hubble的方式非常简单,只需要在部署cilium的时候直接使用命令启动就可以或者使用 ~# cilium hubble enbale --ui 将它内置的ui也部署上去,不加--ui 就是启用了hubble而没有部署它的ui的专用pod
#部署cilium时直接启用,可以在cilium install 命令添加--set选项
cilium install \
--set kubeProxyPeplacement=strict \
--set ipam.mode=kubernetes \
--set ipam.operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16 \
--set ipam.Operator.ClusterPoolIPv4MaskSize=24 \
--set hubble.enabled="true" \
--set hubble.listenAddress="4244" \
--set hubble.relay.enabled="true" \
--set hubble.ui.enabled="true"
--set prometheus.enabled=true \
--set operator.prometheus.enabled=true \
--set hubble.metrics.enableOpenMetrics=true \
--set hubble.metrics.port=9665 \
--set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}"-
--set hubble.enabled="true" :启动hubble
-
--set hubble.listenAddress="4244" :hubble的端口
-
--set hubble.relay.enabled="true" :启动hubble的relay
-
--set hubble.ui.enabled="true" :启动hubble的ui
-
--set prometheus.enabled=true :把每一个cilium agent都打开它的端口并暴露prometheus的指标
-
--set operator.prometheus.enabled=true:暴露operator的指标
-
--set hubble.metrics.port=9965:指标端口9665,其实它还有9964和9963等端口分别暴露不同的指标
-
--set hubble.metrics.enableOpenMetrics=true:允许打开所有的指标
-
--set hubble.metrics.enabled:允许暴露出来的所有的指标,这是官网所给出的,暴露所有应用所有指标的路径包括七层指标信息。
11.2:重新部署cilium并启用hubble以及暴露指标数据
cilium install \
--set kubeProxyPeplacement=strict \
--set ipam.mode=kubernetes \
--set ipam.operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16 \
--set ipam.Operator.ClusterPoolIPv4MaskSize=24 \
--set prometheus.enabled=true \
--set operator.prometheus.enabled=true \
--set hubble.enabled=true \
--set hubble.metrics.enableOpenMetrics=true \
--set hubble.ui.enabled=true \
--set hubble.relay.enabled="true" \
--set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}"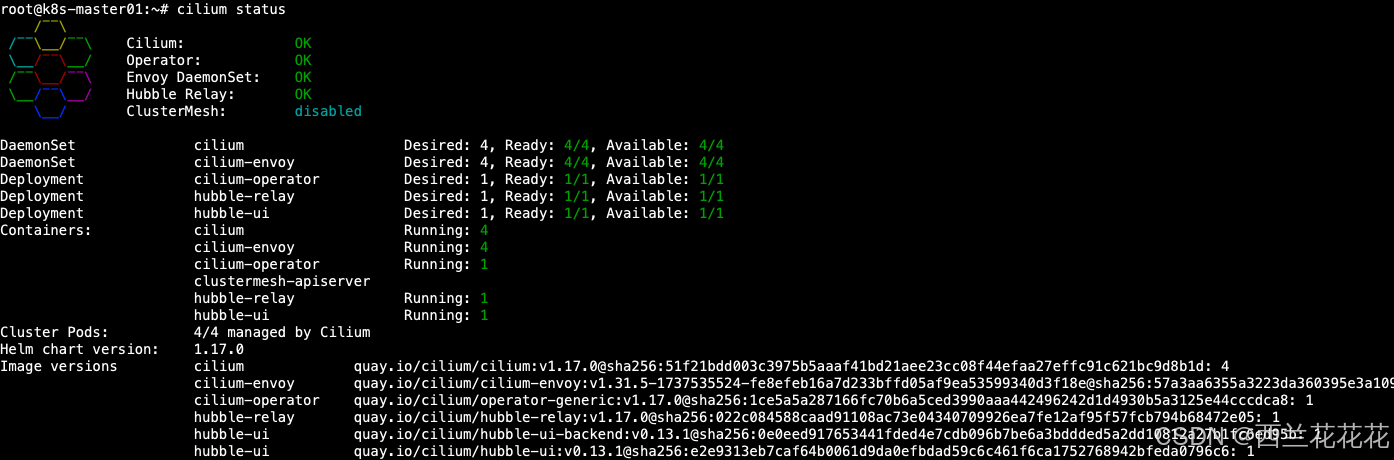
11.3:暴露hubble ui让外部访问
root@k8s-master01:~# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default demoapp NodePort 10.101.238.179 <none> 80:30337/TCP 35s
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4h38m
kube-system cilium-envoy ClusterIP None <none> 9964/TCP 112s
kube-system hubble-metrics ClusterIP None <none> 9965/TCP 112s
kube-system hubble-peer ClusterIP 10.103.148.176 <none> 443/TCP 112s
kube-system hubble-relay ClusterIP 10.100.90.249 <none> 80/TCP 112s
kube-system hubble-ui ClusterIP 10.103.176.159 <none> 80/TCP 112s
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 4h38m
#将spec.type 修改成NodePort
root@k8s-master01:~# kubectl edit svc -n kube-system hubble-ui
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: cilium
meta.helm.sh/release-namespace: kube-system
creationTimestamp: "2025-02-23T14:37:13Z"
labels:
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: hubble-ui
app.kubernetes.io/part-of: cilium
k8s-app: hubble-ui
name: hubble-ui
namespace: kube-system
resourceVersion: "38724"
uid: e53b2218-c701-43bd-8294-7f92038777a8
spec:
clusterIP: 10.103.176.159
clusterIPs:
- 10.103.176.159
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8081
selector:
k8s-app: hubble-ui
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
#在宿主机模拟访问k8s应用
apple@Kxxeiiyy ~ % while true; do curl 172.31.5.11:30337; sleep 0.$[$RANDOM%10]; done允许分名称空间来查看应用间的通信
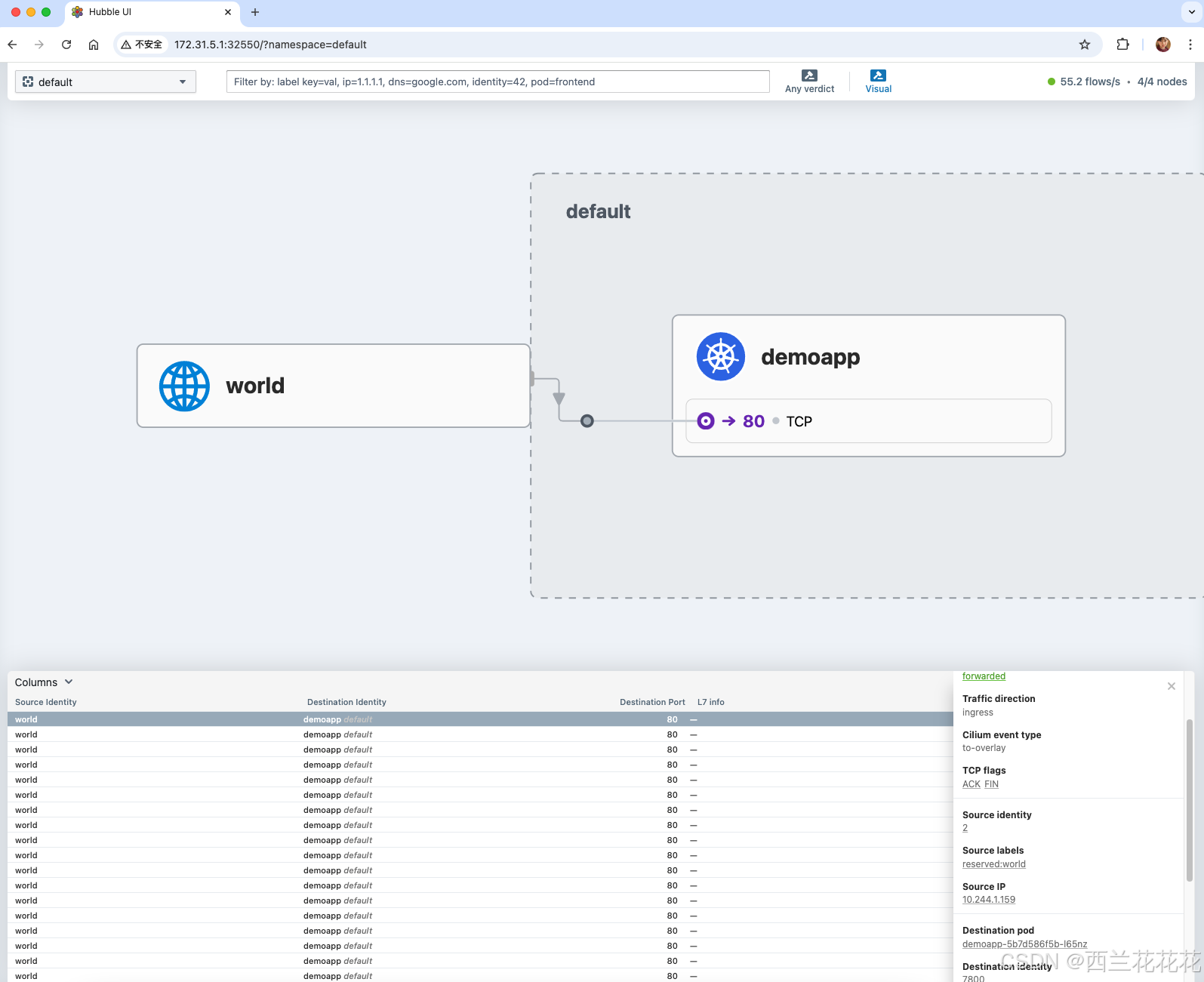
可以看到有外部请求访问到 daemapp来了,底下是通信链路,能显示通信链路的方向它在eBPF上是怎么被处理的原地址是什么,目的地址什么等等 在hubble ui都可以正常显示。
11.4: 配置prometheus发现cilium指标
简介:在之前cilium启用指标后,所有cilium组件都将具有以下注释。它们可用于向 Prometheus 发出信号,告知其是否要抓取指标:
prometheus.io/scrape: true
prometheus.io/port: 9962
配置以下选项,Prometheus 将自动获取 Cilium 和 Envoy 指标scrape_configs:
scrape_configs:
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: ${1}:${2}
target_label: __address__

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









