







一. 深度学习的概念
与机器学习的差别
-
不需要人工特征工程
-
特征工程+分类/回归 使用一个网络来完成
优点
-
精确度高,性能好,效果好
-
拟合任意非线性的关系
-
框架多,不需我们自己造轮子
缺点
-
黑箱,可解释性差
-
网络参数多,超参数多
-
需要大量的数据进行训练,训练时间长,对算力有较高要求
-
小数据集容易过拟合
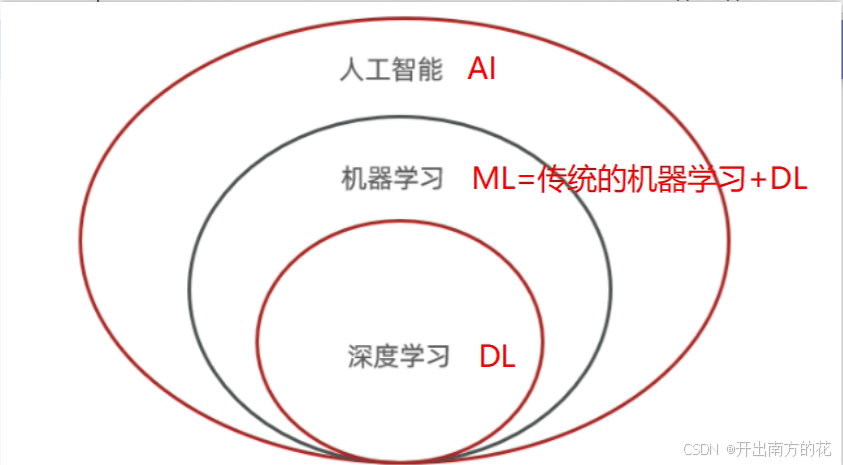
基本概念
-
人工智能(AI):这是最广泛的概念,指的是使
机器能够模拟人类智能行为的技术和研究领域。AI包括理解语言、识别图像、解决问题等各种能力。 -
机器学习:机器学习是实现人工智能的一种方法。它涉及到
算法和统计模型的使用,使得计算机系统能够从数据中“学习”和改进任务的执行,而不是通过明确的编程来实现。机器学习包括多种技术,如线性回归、支持向量机(SVM)、决策树等。 -
深度学习:
深度学习是机器学习中的一种特殊方法,它使用称为神经网络的复杂结构,特别是“深层”的神经网络,来学习和做出预测。深度学习特别适合处理大规模和高维度的数据,如图像、声音和文本。
总结
-
所有深度学习都是机器学习,但并非所有机器学习都是深度学习。深度学习的崛起源于其在处理特定类型的大数据问题上的卓越能力,尤其是那些传统机器学习算法难以处理的复杂问题。然而,对于某些任务和数据集,更简单的机器学习方法可能更加有效和适合。
-
这种技术使用被称为“神经网络”的算法结构,这些结构灵感来源于人脑的神经元网络。深度学习中的“深度”指的是神经网络中层的数量,这些层是进行数据处理和学习的核心单元。
-
在深度学习的过程中,每一层神经网络都对输入数据进行处理,从而学习到数据中的特征和模式。例如,在图像识别任务中,第一层可能会识别边缘,第二层可能会识别形状,更深的层则可能识别复杂的对象特征,如面孔。这些层通过大量数据的训练,逐渐优化它们的参数,从而提高模型的识别或预测能力。
-
深度学习的关键之一是“反向传播”算法,它通过计算损失函数(即实际输出与期望输出之间的差异)并将这种误差反馈回网络的每一层,来调整每层的权重。这种方法使得网络能够从错误中学习并不断改进。
-
深度学习的一个重要的概念是“特征学习”,这意味着深度学习模型能够自动发现和利用数据中的有用特征,而无需人工介入。这与传统的机器学习方法不同,后者通常需要专家提前定义和选择特征。
-
深度学习的成功依赖于大量的数据和强大的计算能力。随着数据量的增长和计算技术的发展,深度学习模型在图像和语音识别、自然语言处理、游戏、医疗诊断等多个领域取得了显著成就。它通过提供更精确和复杂的数据处理能力,推动了人工智能技术的飞速发展。然而,这种技术也面临挑战,如需求大量的训练数据,模型的复杂性和不透明性,以及对计算资源的高需求。尽管如此,深度学习仍然是当今最激动人心的技术前沿之一,其应用潜力巨大。
使用场景
图像识别和处理
-
物体检测:从图片中识别和定位不同的物体。
-
面部识别:用于安全系统和个性化服务。
-
医学影像分析:识别疾病标志,如癌症筛查中的肿瘤检测。
自然语言处理(NLP)
-
机器翻译:如谷歌翻译等工具。
-
语音识别:用于语音助手和自动语音转文字服务。
-
文本生成:自动撰写新闻稿、生成创意内容等。
音频处理
-
音乐生成:创造新的音乐作品。
-
语音合成:如智能助手中的自然语音反馈。
视频分析
-
行为分析:在安全监控中分析人类行为。
-
实时视频处理:用于增强现实和虚拟现实应用。
游戏和仿真
-
AI对战:在复杂的游戏中模拟人类玩家。
-
环境模拟:创建逼真的虚拟环境和情境。
自动驾驶汽车
-
环境感知:理解和解释周围环境。
-
决策制定:自动驾驶过程中的安全决策。
推荐系统
-
个性化推荐:在电子商务、社交媒体和娱乐平台中推荐产品或内容。
金融领域
-
风险评估:信贷评分和投资风险分析。
-
欺诈检测:识别异常交易行为。
医疗领域
-
药物发现:加速新药物的研发。
-
疾病预测和分析:基于患者数据预测疾病风险。
这些应用展示了深度学习如何通过其先进的数据分析和模式识别能力,在多个领域内提供创新和改进的解决方案。随着技术的不断进步,深度学习的应用范围还将不断扩大。
流行框架及算法
深度学习框架
TensorFlow
TensorFlow是Google开发的一款开源软件库,专为深度学习或人工神经网络而设计。TensorFlow允许你可以使用流程图创建神经网络和计算模型。它是可用于深度学习的最好维护和最为流行的开源库之一。TensorFlow框架可以使用C++也可以使用Python。你可以使用TensorBoard进行简单的可视化并查看计算流水线。其灵活的架构允许你轻松部署在不同类型的设备上。不利的一面是,TensorFlow没有符号循环,不支持分布式学习。此外,它还不支持Windows。
-
出生地:Google
-
特点:计算图、分布式训练效果强、底层C构建速度快,生态强大
-
主要调包语言:Python、C/C++、JS
-
评价:对标Pytorch、学术界没市场了、部署更加的方便
-
入门推荐:建议做工程的小伙伴入门
Pytorch
Pytorch是Meta(前Facebook)的框架,前身是Torch,支持动态图,而且提供了Python接口。是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。Python是现在学术界的霸主,对于想要做学术的同学绝对首推(重点)。
-
出生地:FaceBook
-
特点:生态强大、入门爽歪歪、代码量少(重点)
-
主要调包语言:Python、C/C++
-
评价:入门很快、速度有点慢、部署很垃圾、学术界的霸主
-
入门推荐:想要做学术的同学绝对首选,几乎现在顶会论文的代码都是这个框架写的。
PaddlePaddle
百度推出的深度学习框架,算是国人最火的深度学习框架了。更新了2.0的高级API与动态图后,Paddle更加的强大。百度有很多PaddlePaddle的教程,对于初学者来说还是相当不错的。PaddlePaddle有很多便捷的工具,比如Detection、CV、NLP、GAN的工具包,也有专门的可视化工具(远离Tensorboard的支配)。
-
出生地:百度
-
特点:计算图动态图都支持、有高级API、速度快、部署方便、有专门的平台
-
主要调包语言:Python、C/C++、JS
-
入门推荐:如果没有卡那就非常适合,如果算力不缺,建议先看Pytorch,当然也可以PaddlePaddle。
Keras
Keras可以当成一种高级API,它的后端可以是Theano和tensorFlow(可以想成把TF的很多打包了)。由于是高级API非常的方便,非常适合科研人员上手。
-
作者:Google AI 研究人员 Francois Chollet
-
特点:生态强大、入门爽歪歪、代码量少(重点)
-
主要调包语言:Python、C/C++、JS
-
评价:太适合入门了、速度有点慢、版本得匹配后端框架的版本
-
入门推荐:强推入门首选,但是后续一定要看看算法的底层是怎样工作的。
Caffe/Caffe2
Caffe是顶级高校UCB的贾扬清博士开发的,主要是适用于深度学习在计算机视觉的应用。使用Caffe做算法代码量很少,经常就是修修改改就能用,神经网络模型的管理非常的方便,而且算是比较早的部署在各种落地场景中。Caffe2可以理解为一个新版本的Caffe,但是有很多不同,Caffe2后来并入了Pytorch。该工具支持Ubuntu,Mac OS X和Windows等操作系统。
-
作者:UCB 贾扬清博士
-
特点:计算图、部署方便、训练方便、cuDnn与MKL均支持
-
主要调包语言:Python、Matlab脚本、C++
-
评价:卷积人的大爱、环境不好配置、感觉偏底层、Caffe2还是Pytorch
-
入门推荐:不是很建议,真的想了解可以先入门Pytorch
MXNet
MXNet 是一个社区维护起来的深度学习框架,后来被亚马逊看上了。有类似于 Theano 和 TensorFlow 的计算图,也有灵活的动态图,摒弃有高级接口方便调用。MXNet的底层为C构建,优化的很好,很多推理框架都能直接转换,非常方便。
-
出生地:社区
-
特点:计算图动态图都支持、有高级API、速度快、部署方便
-
主要调包语言:Python、C/C++、JS(js用的相对少)
-
评价:一定意义上是国人的框架、小团体整的社区维护、文档少生态不行
入门推荐:一般。
Theano
Theano是07年左右开发的一个多维数组的计算库,支持GPU计算,当时很多人当成“支持GPU的Numpy”,底层优化的非常好,支持导出C的脚本。
-
出生地:蒙特利尔大学
-
特点:计算图、Python+Numpy、源于学术界
-
主要调包语言:Python
-
评价:很臃肿、不支持分布式、被后面的TensorFlow打击的很大
-
入门推荐:绝对不建议,真的要用的话,先学习别的框架再看Github就行了
Torch
Torch是一款针对ML算法且又简单易用的开源计算框架。该工具提供了高效的GPU支持,N维数组,数值优化例程,线性代数例程以及用于索引、切片和置换的例程。基于Lua的脚本语言,该工具带有大量预先训练好的模型。这款灵活高效的ML研究工具支持诸如Linux,Android,Mac OS X,iOS和Windows等主流平台。
CNTK
Microsoft Cognitive Toolkit是具有C#/C++/Python接口支持的最快的深度学习框架之一。此款开源框架带有强大的C++ API,比TensorFlow更快、更准确。该工具还支持内置数据读取器的分布式学习。它支持诸如前馈,CNN,RNN,LSTM和序列到序列等算法。该工具支持Windows和Linux。
-
出生地:微软
-
特点:非常严谨、语音上有一些优势、难度有点高
-
调包语言:C++、Python
-
评价:适合语音方面的开发工作
-
入门推荐:不建议,看看就好。
ONNX
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。用大白话说就是是一个中间件,比如你Pytorch的模型想转换别的,就得通过ONNX,现在有的框架可以直接转,但是在没有专门支持的时候,ONNX就非常重要了,万物先转ONNX,ONNX再转万物。ONNX本身也有自己的模型库以及很多开源的算子,所以用起来门槛不是那么高。
-
出生地:有点多,很多大厂一起整的
-
特点:万能转换
-
主要调包语言:Python、C/C++
-
入门推荐:不用刻意学习,用到了再看。
深度学习推理框架
TensorRT
TensorRT是NVIDIA公司推出的面向GPU算力的推理框架,在服务端和嵌入式设备上都有非常好的效果,但是底层不开源。TensorRT的合作方非常的多,主流的框架都支持。如果有GPU的话,传统的算子可以用CUDA,深度学习搞成TensorRT。
-
出生地:NVIDIA
-
特点:自产自销NVIDIA不多解释,框架支持很多,生态很棒,稳定性高
-
主要调包语言:Python、C/C++
-
推荐平台:NVIDIA Jetson系列的嵌入式、NVIDIA的GPU(一条龙)
-
支持模型:TensorFlow1.x、TensorFlow2.x、Pytorch、ONNX、PaddlePaddle、MXNet、Caffe、Theano,Torch,Lasagne,Blocks。
-
入门推荐:非常适合入门,直接在自己的GPU上做测试就行。
TF-Lite
TF-Lite是谷歌针对移动端的推理框架,非常的强大。强大的原因在于Keras、TensorFlow的模型都能使用,而且有专门的TPU和安卓平台,这种一条龙的服务让TensorFlow在部署方面还在称霸。TF-Lite如果用Keras、TensorFlow的模型去转换一般来说都是脚本直接开搞,自己重构的部分相对少很多。
-
出生地:Google
-
特点:一条龙的服务专属平台
-
主要调包语言:Python、C/C++、Java
-
支持模型:Keras、TensorFlow、ONNX
-
推荐平台:几乎所有的ARM处理器和微控制器(树莓派,甚至单片机)、TPU专享
-
入门推荐:TFboys(TensorFlow使用者)的必备,毕竟一条龙,还有机会了解TPU,非常贴心。
OpenVINO
OpenVINO是Intel的推理框架,一个超级强的推理部署工具。工具包中提供了很多便利的工具,例如OpenVINO提供了深度学习推理套件(DLDT),该套件可以将各种开源框架训练好的模型进行线上部署,除此之外,还包含了图片处理工具包OpenCV,视频处理工具包Media SDK。如果是针对Intel的加速棒或者工控机上部署真的是非常不错的。
-
出生地:Intel
-
特点:面向Intel设备的加速,便捷使用,安装和SDK很方便
-
主要调包语言:C/C++、Python
-
支持模型:TensorFlow、Pytorch、ONNX、MXNet、PaddlePaddle
-
推荐平台:自己的电脑、Intel神经网络加速棒、Intel的FPGA
-
入门推荐:作为入门还是不错的,只是落地场景有点少,毕竟现在是边缘设备的时代 因为工业上工控机多但是深度学习模型用的还是少,很多都是传统的算法,很多落地场景中上Intel的处理器并不占优势。
CoreML
CoreML是苹果公司推出针对ios以及macOS系统部署的机器学习平台,底层不开源。在苹果设备上,CoreML的速度是最快的,但是也只能用于苹果的设备上。
-
出生地:Apple
-
特点:面向苹果设备,专业设备上速度第一,稳定、入门简单
-
主要调包语言:C/C++、Python、Obj-C、Swift
-
支持模型:TensorFlow、ONNX、Pytorch、ONNX、MXNet、Caffe
-
推荐平台:iMac、MacBook、iPhone、iPad、AppleWatch
-
入门推荐:针对Apple的开发者,业余选手得买个MBP
NCNN
NCNN是腾讯推出的推理框架,一定意义上是之前使用非常广的一个推理框架,社区做的也非常棒。NCNN的速度是超过TFLite的,但是有点麻烦的是之前得经常自己用C去复现一些算子(框架起步都这样),现在因为使用的人数很多,因此算子很多。NCNN对于X86、GPU均有支持,在嵌入式、手机上的表现非常好。
-
出生地:腾讯优图实验室
-
特点:面向移动端的加速、手机处理器的加速单元支持很棒
-
主要调包语言:C/C++、Python
-
支持模型:TensorFlow、ONNX、Pytorch、ONNX、MXNet、DarkNet、Caffe
-
推荐平台:安卓/苹果手机、ARM处理器设备
-
入门推荐:对于嵌入式或者APP开发有经验的同学绝对首推的
MNN
MNN是阿里巴巴推出的移动端框架,现在也支持模型训练,支持OpenCL,OpenGL,Vulkan和Metal等。同样的设备,MNN的部署速度是非常快的,树莓派3B上cpu的加速是NCNN速度的3被以上,而且文档非常的全,代码整洁清晰,非常适合开发者使用。
-
出生地:阿里巴巴多部门合作
-
特点:面向移动端的加速、应该是现在速度之最
-
主要调包语言:C/C++、Python
-
支持模型:TensorFlow、ONNX、Pytorch、MXNet、NCNN、Caffe、TF-Lite
-
推荐平台:安卓/苹果手机、ARM处理器设备
-
入门推荐:首推的部署推理框架,绝对的好用,在苹果设备上的速度也很棒。MNN框架感觉比NCNN稳定一些,而且源码非常整洁,研究底层也是非常方便。
Tenigne
Tenigne-Lite是OpenAILab推出的边缘端推理部署框架,OpenCV官方在嵌入式上的部署首推Tenigne-Lite。现在对于RISC-V、CUDA、TensorRT、NPU的支持非常不错。Tengine是现在来说感觉安装环境中bug最少的框架,几乎安按照文档走不会出问题的。
-
出生地:OpenAILab
-
特点:面向移动端的加速、速度和MNN不相上下、对于嵌入式的支持非常好
-
主要调包语言:C/C++、Python
-
支持模型:TensorFlow、ONNX、DarkNet、MXNet、NCNN、Caffe、TF-Lite、NCNN
-
推荐平台:安卓手机、ARM处理器设备、RISC-V
-
入门推荐:嵌入式开发的小伙伴可以入手 Tengine-Lite是个朝气蓬勃的框架,虽然出的时间并没有其他框架早,但是框架性能、易用性还是非常适合嵌入式玩家的。
NNIE
NNIE 即 Neural Network Inference Engine,是海思 SVP 开发框架中的处理单元之一,主要针对深度学习卷积神经网络加速处理的硬件单元,可用于图片分类、目标检测等 AI 应用场景。
支持现有大部分公开的卷积神经网络模型,如 AlexNet、VGG16、ResNet18、ResNet50、GoogLeNet 等分类网络,Faster R-CNN、YOLO、SSD、RFCN 等检测目标网络,以及 FCN 、SegNet 等分割场景网络。目前 NNIE 配套软件及工具链仅支持以 Caffe 框架,使用其他框架的网络模型需要转化为 Caffe 框架下的模型。
华为海思NNIE非常强大,之前移动端真的快霸主,但是现在受制约芯片停产。
RKNN
Rockchip提供RKNN-Toolkit开发套件进行模型转换、推理运行和性能评估。
模型转换:支持 Caffe、Tensorflow、TensorFlow Lite、ONNX、Darknet 模型,支持RKNN 模型导入导出,后续能够在硬件平台上加载使用。
模型推理:能够在 PC 上模拟运行模型并获取推理结果,也可以在指定硬件平台RK3399Pro Linux上运行模型并获取推理结果。
性能评估:能够在 PC 上模拟运行并获取模型总耗时及每一层的耗时信息,也可以通过联机调试的方式在指定硬件平台 RK3399Pro Linux上运行模型,并获取模型在硬件上运行时的总时间和每一层的耗时信息。
算法
卷积神经网络(CNN)
-
适用于图像识别、视频分析、医学影像等。
-
特别擅长处理带有空间关系的数据。
循环神经网络(RNN)及其变体(如LSTM、GRU)
-
适用于时间序列数据处理,如语音识别、音乐生成、自然语言处理。
-
能够处理序列数据中的时间动态性。
Transformer架构
-
引领自然语言处理的新浪潮,如BERT、GPT系列。
-
适用于复杂的语言理解和生成任务。
自编码器(Autoencoders):
-
用于数据降维、去噪、特征学习等。
-
在异常检测和数据生成中也有应用。
生成对抗网络(GANs):
-
用于图像生成、艺术创作、数据增强等。
-
擅长生成逼真的图像和视频。
每种框架和算法都有其独特的特点和优势,选择哪一个取决于具体的任务需求、数据类型、以及开发者的偏好和经验。随着深度学习领域的不断进步,这些工具也在不断发展和完善,以适应更加多样化和复杂的应用场景。

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









