







一、内核内存管理框架
内核将物理内存等分成N块4KB,称之为一页,每页都用一个struct page来表示,采用伙伴关系算法维护
 补充:
补充:
Linux内存管理采用了虚拟内存机制,这个机制可以在内存有限的情况下提供更多可用的内存空间。每个进程都有自己独立的虚拟地址空间,应用程序只能访问自己的地址空间,而不能直接访问其他进程的地址空间或内核空间。
当应用程序需要访问某些数据时,它会使用虚拟地址来引用这些数据。实际上,这些虚拟地址并不是直接映射到物理内存,而是由操作系统进行转换。操作系统将虚拟地址映射到物理内存中的一些页框(Page Frame),这个过程称为页表映射(Page Table Mapping)。
因此,每个应用程序都有自己的页表,它们被存储在内存中,这些页表以及对应的物理页框在不同的时间可能会被交换到硬盘上,从而释放内存空间。当应用程序访问虚拟地址时,操作系统会根据页表映射的结果找到相应的物理页框,然后将数据从物理内存中读取出来。
由于每个应用程序都有自己独立的虚拟地址空间和页表,所以应用程序之间的内存访问是相互隔离的。这种隔离机制可以保证每个应用程序只能访问自己的内存空间,而不能对其他应用程序或操作系统造成干扰。这也是为什么应用程序内存不会影响到其他内存的原因。
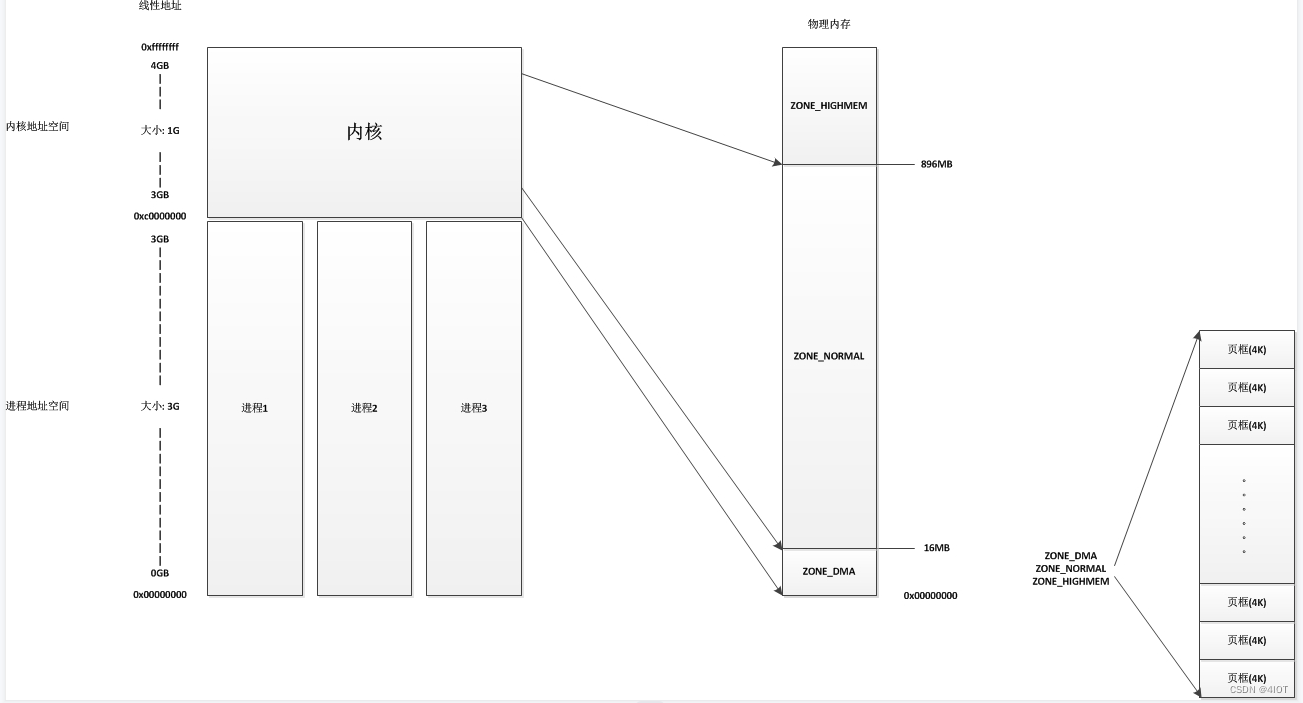
0~1G虚拟地址给内核用
1~4G虚拟地址给应用程序用(我们这次研究这块)
内核地址空间划分图:

3G~3G+896M:低端内存,直接映射 虚拟地址 = 3G + 物理地址(虚拟地址连续,物理地址也连续)
细分为:ZONE_DMA、ZONE_NORMAL
分配方式:
1. kmalloc:小内存分配,slab算法
2. get_free_page:整页分配,2的n次方页,n最大为10大于3G+896M:高端内存
细分为:vmalloc区、持久映射区、固定映射区
分配方式:
vmalloc:虚拟地址连续,物理地址不连续二、内核中常用动态分配
2.1 kmalloc
函数原型:
void *kmalloc(size_t size, gfp_t flags);kmalloc() 申请的内存位于直接映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因为存在较简单的转换关系,所以对申请的内存大小有限制,不能超过128KB。
较常用的 flags(分配内存的方法):
-
GFP_ATOMIC —— 分配内存的过程是一个原子过程,分配内存的过程不会被(高优先级进程或中断)打断;
-
GFP_KERNEL —— 正常分配内存;
-
GFP_DMA —— 给 DMA 控制器分配内存,需要使用该标志(DMA要求分配虚拟地址和物理地址连续)。
flags 的参考用法:
|– 进程上下文,可以睡眠 GFP_KERNEL
|– 异常上下文,不可以睡眠 GFP_ATOMIC
| |– 中断处理程序 GFP_ATOMIC
| |– 软中断 GFP_ATOMIC
| |– Tasklet GFP_ATOMIC
|– 用于DMA的内存,可以睡眠 GFP_DMA | GFP_KERNEL
|– 用于DMA的内存,不可以睡眠 GFP_DMA |GFP_ATOMIC
对应的内存释放函数为:
void kfree(const void *objp);
void *kzalloc(size_t size, gfp_t flags) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











