







 本文介绍了使用PyTorch构建RNN分类器来根据姓名预测其可能的语言来源。通过处理字符的ASCII值,进行序列填充以统一长度,训练模型并观察随着训练进程损失函数的降低,最终在测试集上达到约84%的准确率。
本文介绍了使用PyTorch构建RNN分类器来根据姓名预测其可能的语言来源。通过处理字符的ASCII值,进行序列填充以统一长度,训练模型并观察随着训练进程损失函数的降低,最终在测试集上达到约84%的准确率。
用RNN做一个分类器~
- 根据名字来判断国家18个语言地区,几千个名字,训练模型,输入新名字,然后告诉我们是使用哪种语言的人
- 复习:onehot通过嵌入层,然后RNN层,隐状态~做线性层,把输出映射成我们要的维度
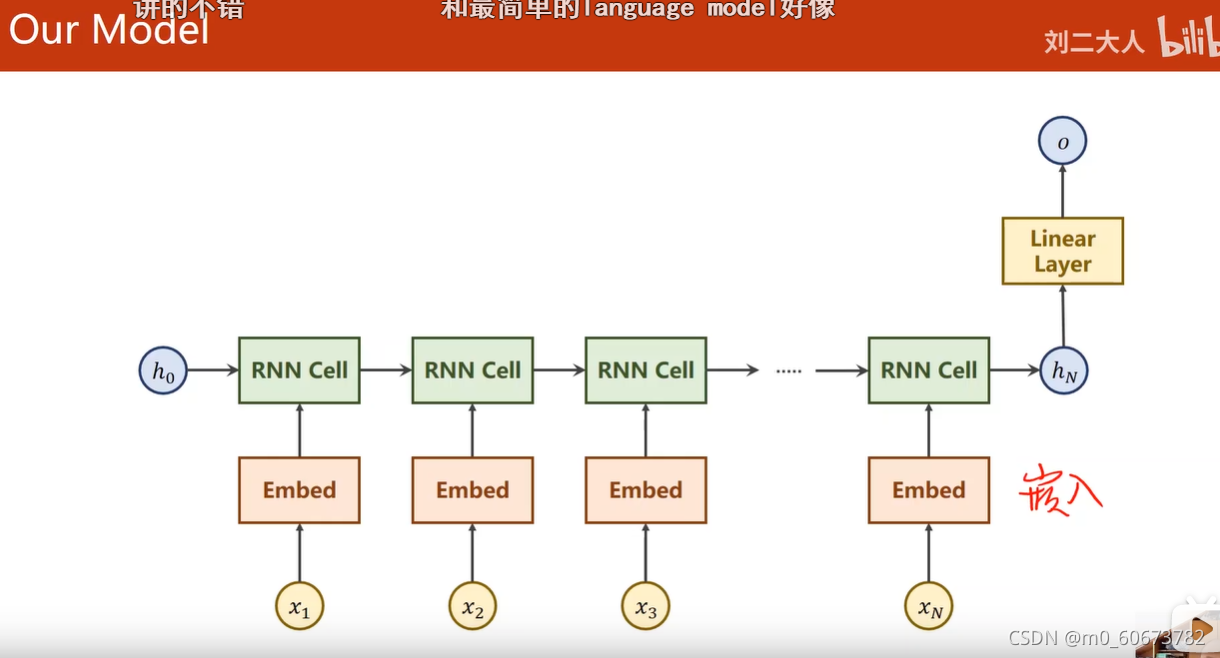
-
hN是最后一个隐层
-
输入名字M c l e a n是一个序列,而且序列长短不一样
-
我们把嵌入层RNN 线性层 定义名叫RNNClassifier
-
主循环:
-
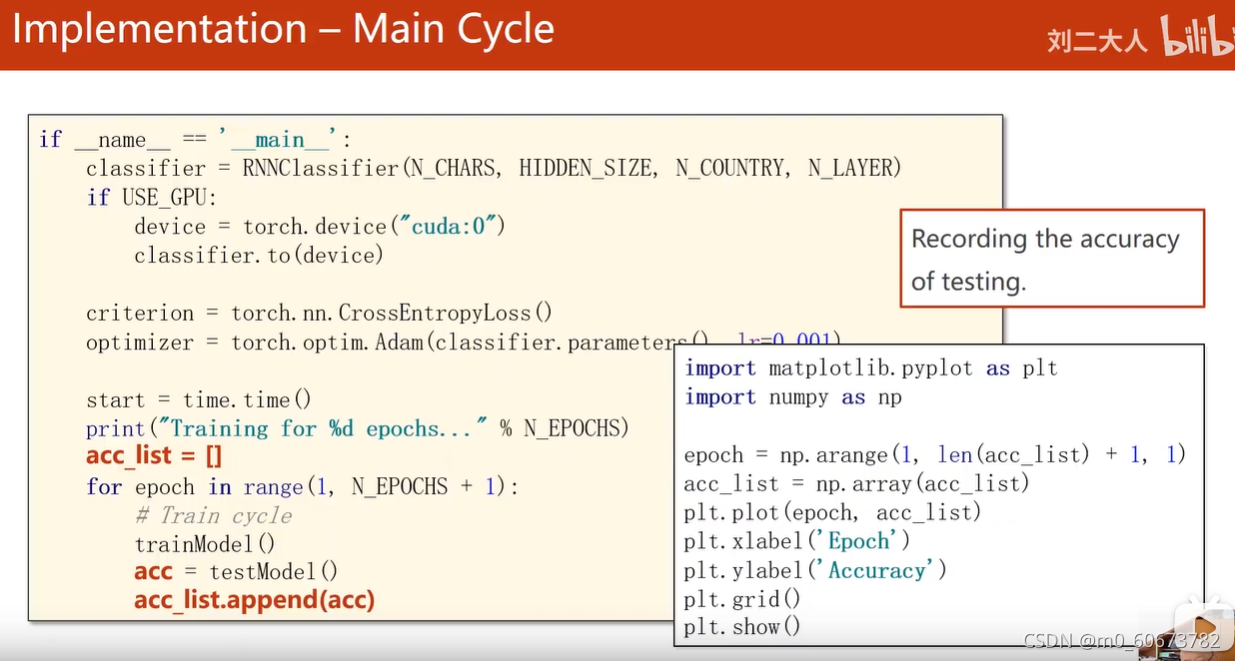
-
if __name__ == '__main__': #N_CHARS字符数量输入英文字母转换成onehot向量、隐层数量、country分类一共多少、layerGRU几层 classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER) if USE_GPU: device = torch.device("cuda:0") classifier.to(device) #损失函数、优化器 criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001) #打印训练时间的长度 start = time.time() print("Training for %d epochs..." % N_EPOCHS) #recording the accuracy of testing acc_list = [] for epoch in range(1, N_EPOCHS + 1): # Train cycle 把训练和测试封装在两个函数里 trainModel() acc = testModel() acc_list.append(acc)还有一个函数:
-
#距离训练开始的时间,python中以秒为单位,除60变成分 def time_since(since): s = time.time() - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s)1准备数据
- 名字的处理:
-
每个字符对应一个ASCII值0-127
-
序列长度不一样,做padding让他们变成一样长度
-
国家处理:
-
把国家名变成分类索引,从0开始索引标签~做一个对应的词典~
-
代码:
-
# Parameters HIDDEN_SIZE = 100 BATCH_SIZE = 256 N_LAYER = 2 N_EPOCHS = 100 N_CHARS = 128 USE_GPU = False #prepare data class NameDataset(Dataset): def __init__(self, is_train_set=True): #reading data frfom .gz file with package gzip and csv filename = 'data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz' with gzip.open(filename, 'rt') as f: reader = csv.reader(f) rows = list(reader) #save names and countries in list self.names = [row[0] for row in rows] self.len = len(self.names) self.countries = [row[1] for row in rows] #save countries and its index in list and dictionary #sorted 去除重复的国家名
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









