






lambda在开发中常用的一些方法
@Data
public class Student {
private String name;
private Integer age;
private Integer className;
public static List<Student> getStudents(){
List<Student> students = new ArrayList<>();
Student student1 = new Student();
student1.setName("张三");
student1.setAge(20);
student1.setClassName(119);
Student student2 = new Student();
student2.setName("李四");
student2.setAge(18);
student2.setClassName(120);
Student student3 = new Student();
student3.setName("王五");
student3.setAge(22);
student3.setClassName(119);
Student student4 = new Student();
student4.setName("赵六");
student4.setAge(19);
student4.setClassName(163);
students.add(student1);
students.add(student2);
students.add(student3);
students.add(student4);
return students;
}
public static void main(String[] args) {
// 初始化学生数据
List<Student> students = Student.getStudents();
}
}
1.通过指定条件过滤集合
业务场景:
比如我们在从数据库中查出一个集合数据,然后通过某个条件,筛选出符合逻辑的。
哈哈,这个其实在数据库中查不出不是更香香吗!简单的介绍一下
List<Student> students = Student.getStudents();
// 获取学生年龄大于20岁的
List<Student> collect = students.stream()
.filter(item -> item.getAge() > 20).collect(Collectors.toList());
collect 结果
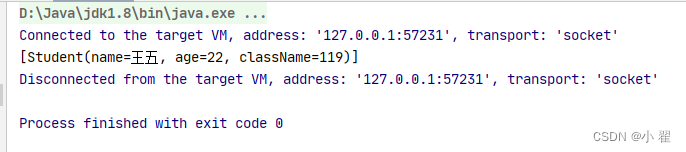
这个方法在一般场景中是用不到的,在数据库中查找也是可以的。
如果我想过滤年龄大于20并且班级不是119的学生,应该如何操作?
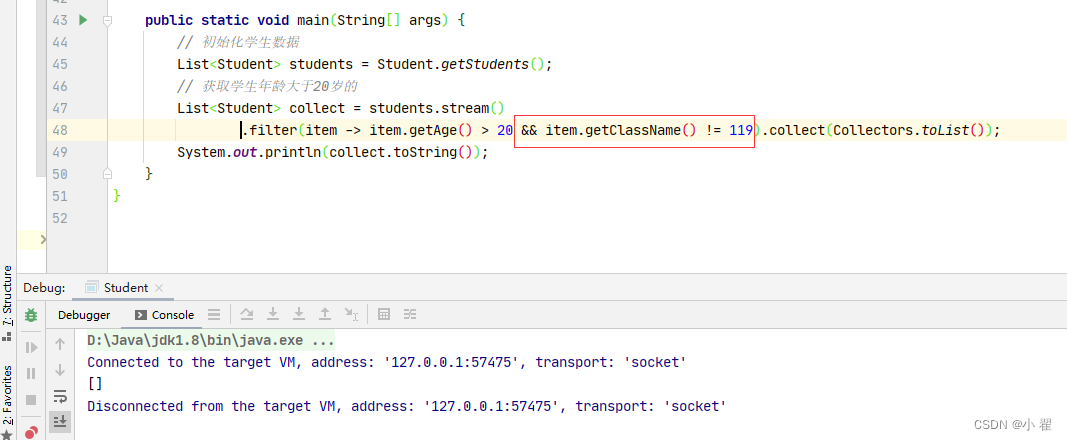
看这也是不是可以了,但是这里面还是有问题的,我上面声明的className是int 的包装类型。… 不多说了,不然说不完了。想一想会出那种问题。
2.将学生数组转换成map
// 初始化学生数据
List<Student> students = Student.getStudents();
// 将学生集合转换成map对象
Map<String, Student> collect = students.stream()
.collect(Collectors.toMap(Student::getName, item -> item));
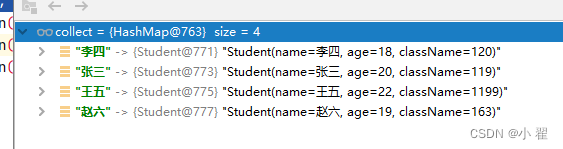
这个在真实的开发中比较长用,我给大家介绍一个场景,比如在导入数据的时候,
做数据校验,文档导入的文档中是汉字你要转换成对应的编码,去保存到数据库
中。如果你把数据这个字典的数据转换成一个map集合。是不是不用多次查询了。
前提是这个字典表数据量不能太大。这种方法也就是用空间换时间。这个使用换
有几种情况,当你的map value中只想手机某一个字段。或者map 的key重复如何
处理。这里我就不给大家详细介绍了,代码如下。
// key 学生姓名 value 为学生年龄
Map<String, Integer> collect1 = students.stream()
.collect(Collectors.toMap(Student::getName, item -> item.getAge()));
// key 重复的处理策略
Map<String, Student> collect2 = students.stream()
.collect(Collectors.toMap(Student::getName, Function.identity(), (key1, key2) -> key1));
3.通过指定的条件对数据进行分组
这个方法在开发中遇到一些场景是比较好用的,大家可以灵活使用
// 初始化学生数据
List<Student> students = Student.getStudents();
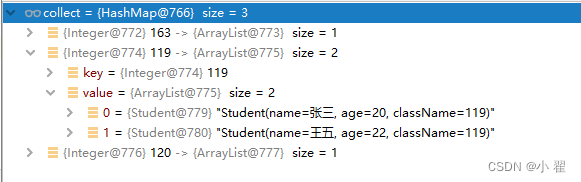
// 通过班级对数据分组
Map<Integer, List<Student>> collect = students.stream()
.collect(Collectors.groupingBy(Student::getClassName));
4.再给大家说一下,关于集合排序的一个方法
// 初始化学生数据
List<Student> students = Student.getStudents();
// 通过年龄对学生从小到大排序
Collections.sort(students, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
});
// 简写方式
Collections.sort(students, (o1,o2) -> o1.age - o2.age);

关于对集合的操作还有很多,大家可以去了解更多。我只是举例几个,我再真实开发中常用的例子。希望能对大家有帮助。

















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









