






1.树的前序遍历
规律:访问根节点->访问根节点的子树
使用leetcode的题目来说明。
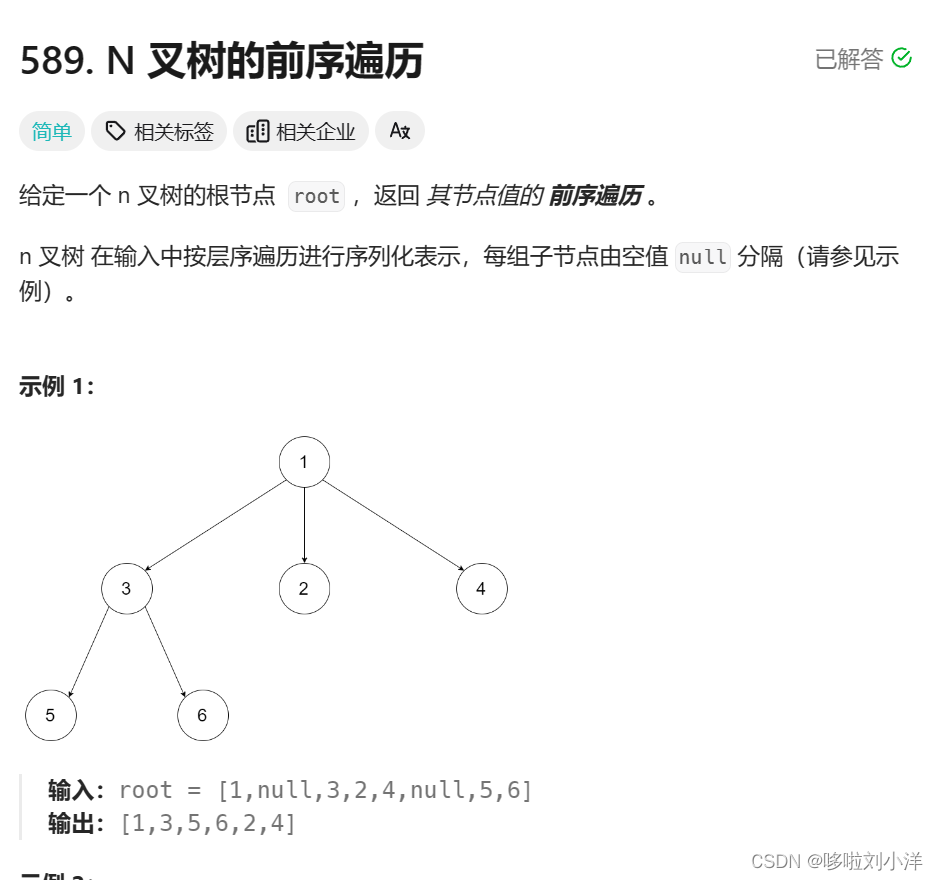
使用递归来做很简单,将问题抽象为:
输出根节点
−
>
处理子树
输出根节点->处理子树
输出根节点−>处理子树
递归的步骤:
递归的目的
−
>
逻辑处理
−
>
递归边界
递归的目的->逻辑处理->递归边界
递归的目的−>逻辑处理−>递归边界
1.递归的目的:输出树的前序遍历
2递归的逻辑处理:输出根节点->处理子树
3.递归的边界:当树为空的时候返回
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution
{
public:
vector<int> preorder(Node* root)
{
vector<int>ans;
function<void(Node *)>dfs=[&](Node *root)->void
{
if(root==NULL)return; //边界处理
ans.push_back(root->val); //输出根节点
for(int i=0;i<root->children.size();i++) //处理子树
dfs(root->children[i]);
return; //可写可不写
};
dfs(root);
return ans;
}
};
难点来了,如果要使用非递归的方法怎么办。实际上,在计算机内存中,递归的过程,就是一个模拟栈的过程,遵从先进后出,后进先出的原理。每层递归的参数都会保存下来,等到递归回溯的时候才会将参数给回收。
比如:
定义一个递归方程:
void dfs(int i,int j)
{
int a=i;
int b=j;
if(a==5&&b==5)return;
dfs(a+1,b+1);
}
dfs(1,1); //调用递归函数
递归进入的时候:
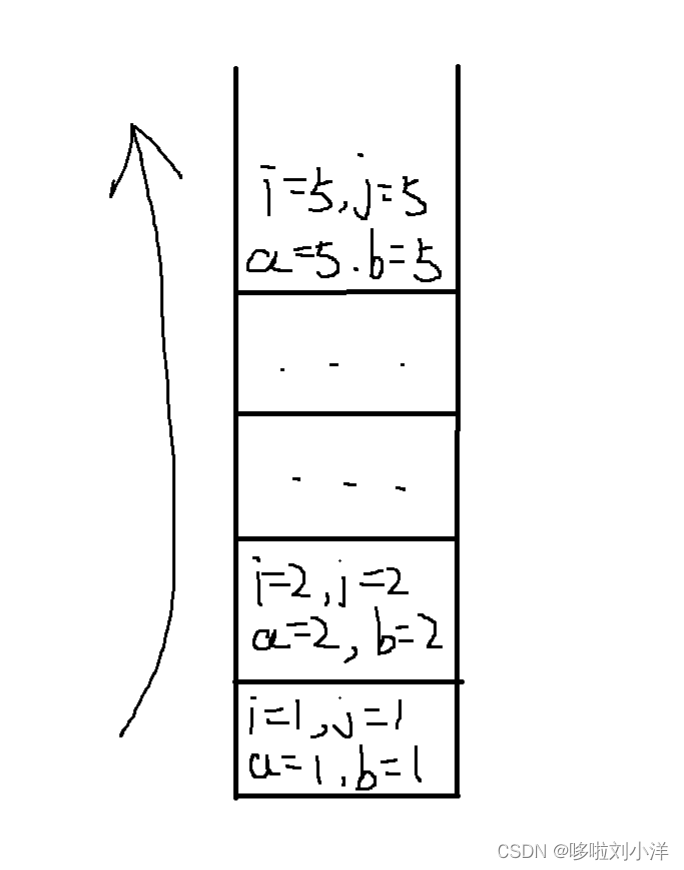
所以如果使用非递归的方法,就要创建一个栈来模拟递归的过程,也就是把递归过程中的栈”显化“出来。
前序遍历的栈调用是:放进第一个子树->放进第一个子树的子树->放进第一个子树的子树的子树。。
然后,出去栈顶的子树,放进出去子树的第二个子树,放进出去子树的第二个子树的第一个子树。。。
以下是模拟递归过程,
关键在于:
进栈的数据,不能只考虑当下,要同时考虑退栈的时候是否符合递归的逻辑,一进一出,有的“隐形”的数据要找到。只有这样才能具体化递归过程
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution
{
public:
vector<int> preorder(Node* root)
{
vector<int>ans;
stack<pair<Node*,int>>st; //{当前节点,当前节点子树的下标(还没有访问)}
if(root==NULL)return ans;
st.push({root,0});
ans.push_back(root->val);
while(st.size())
{
pair<Node*,int>t=st.top();
Node* r=t.first;
if(t.second>=r->children.size()) //当前根节点的所有子树都被遍历过了,退栈。
{
st.pop();
continue;
}
r=r->children[t.second];
while(r!=NULL) // 入栈孩子节点
{
st.top().second++;
st.push({r,0});
ans.push_back(r->val);
if(r->children.size()==0)
break;
else
r=r->children[0];
}
}
return ans;
}
};
看了一下题解,发现一个更舒服的做法,很厉害
class Solution
{
public:
vector<int> preorder(Node* root)
{
vector<int> res;
stack<Node*> st;
if(root == nullptr) return res;
st.push(root);
while(!st.empty())
{
Node* node = st.top();
st.pop();
res.push_back(node->val);
for(int i = node->children.size() - 1; i >= 0; --i)
{
st.push(node->children[i]);
}
}
return res;
}
};
2.后序遍历
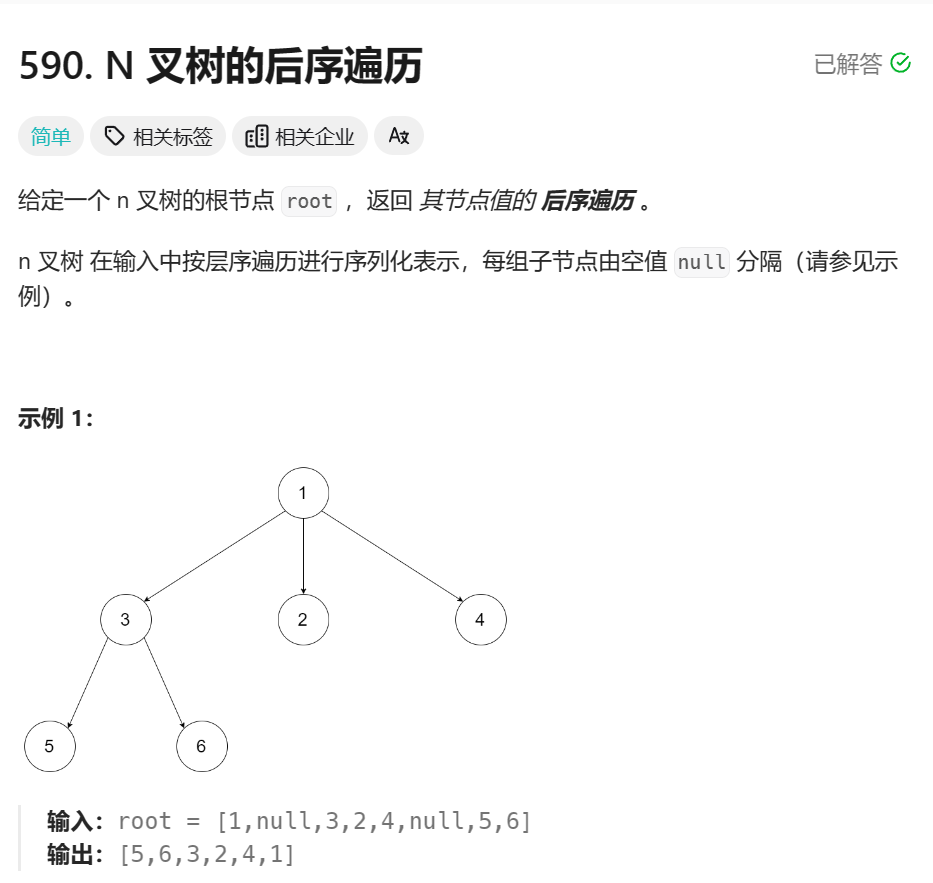
处理根节点的子树 − > 输出根节点 处理根节点的子树->输出根节点 处理根节点的子树−>输出根节点
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution
{
public:
vector<int> postorder(Node* root)
{
vector<int>ans;
function<void(Node*)>dfs=[&](Node*root)->void
{
if(root==NULL)return;
for(int i=0;i<root->children.size();i++) //处理完子树
{
dfs(root->children[i]);
}
ans.push_back(root->val); //输出根节点
};
dfs(root);
return ans;
}
};
模拟递归过程,找葫芦画瓢呗,前序遍历用了两种写法,这个也用两种非递归写法
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution
{
public:
vector<int> postorder(Node* root)
{
vector<int>ans;
stack<pair<Node*,int>>st;
if(root==NULL)
return ans;
st.push({root,0});
while(st.size())
{
pair<Node*,int>t=st.top();
Node *r=t.first;
if(t.second==r->children.size()) //当前的节点的子树都处理完了,退栈,输出当前接节点
{
st.pop();
ans.push_back(r->val);
continue;
}
r=r->children[t.second];
while(r!=NULL)
{
st.top().second++;
st.push({r,0});
if(r->children.size()==0)
break;
else
r=r->children[0];
}
}
return ans;
}
};
vector<int> postorder(Node* root)
{
vector<int> ans;
if(root == nullptr)
{
return ans;
}
stack<Node*> stk;
stk.push(root);
Node *pre = nullptr;
while(!stk.empty())
{
Node *top = stk.top();
if(top->children.size() != 0 && pre != top->children.back())
{
for(auto it = top->children.rbegin(); it != top->children.rend(); ++it)
{
stk.push(*it);
}
continue;
}
// 叶节点,或者上一个访问的节点是这个节点的最后一个字节点,那么访问当前节点
ans.emplace_back(top->val);
pre = top;
stk.pop();
}
return ans;
}
3.中序遍历(二叉树,N叉树没得中序遍历)

处理左子树
−
>
处理根节点
−
>
处理右子树
处理左子树->处理根节点->处理右子树
处理左子树−>处理根节点−>处理右子树
递归:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
vector<int> inorderTraversal(TreeNode* root)
{
vector<int>ans;
if(root==NULL)return ans;
function<void(TreeNode*)>dfs=[&](TreeNode* root)->void
{
if(root==NULL)return;
dfs(root->left);
ans.push_back(root->val);
dfs(root->right);
};
dfs(root);
return ans;
}
};
非递归:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
vector<int> inorderTraversal(TreeNode* root)
{
vector<int>ans;
if(root==NULL)return ans;
//处理左子树--输出根节点--处理右子树
stack<pair<TreeNode*,int>>st;
st.push({root,0});
while(st.size())
{
pair<TreeNode*,int>t=st.top();
TreeNode *r=t.first;
if(t.second==1||r->left==NULL) //左子树为空或者遍历完左子树了
{
ans.push_back(r->val); //加入当前节点
st.pop();
r=r->right;
}
else r=r->left; //否则栈顶节点的左子树还没有访问过
while(r!=NULL) //如果子树不为空
{
if(st.size()) //特殊处理,有可能上面的pop操作导致栈里面没有节点了
st.top().second=1; //当前节点的左子树不为空,标记栈顶节点,下次再遍历栈顶节点就知道它的左子树遍历过了,直接遍历右子树
st.push({r,0});
r=r->left;
}
}
return ans;
}
};

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









