









目录
各位博友,在学习了前面的链表后,相信各位对于链表的结构与操作有了很好的理解。那么接下来,为了加深这种理解,我们可以试着以递归的形式实现建立链表的操作。为了不让讲解过于简单,我们逐步试着以递归的方式建立一条双向链表。
要建立一条双向链表,我们首先要熟悉普通的单向链表(双向链表与其十分类似)的建立操作,接着我们就可以探讨一下如何递归建立一条双向链表了。建立链表需要结点,我们定义这条链表的结点如下:
typedef struct stu { char id[3]; char name[10]; struct stu *next; struct stu *before; }stu;
然后我们需要一个递归函数,我们不妨给它一个名字叫 creat() ,通过这个函数我们可以递归地建立一条双向链表,然后我们还需要一个可以释放这条双向链表的函数,我们可以将它命名为 disappear() 。
现在,我们基本具备了建立这条链表的条件了,接下来只需讨论这两个函数的类型及各自的形参和具体的操作。其中,creat() 函数显然有着更重要的地位,我们先来讨论如何实现这个函数。
creat()函数
creat()函数的类型
该如何确定creat()函数的类型呢?可以想到,我们是一个个结点建立的,尾结点连接着新结点,然后新结点便成了尾结点,即使是以递归的方式建立链表也是不会违反这个前提的。所以,当我们成功地建立一条链表后,我们希望递归函数可以给我们返回一个什么呢?当然是 stu* 类型的指针。那么,由于这条链表是单向建立的,不可避免地,最好是能够返回指向队首结点或队尾结点的指针。因此,creat()函数的类型明显就是 stu* 类型的啦。
creat()函数的形参
creat,顾名思义,我们是用这个函数来创造链表节点的,不妨认为指向这个新结点的指针的名字叫 new 。方便起见,我们直接认为这个结点的名字叫 new。那么,我们该怎样对待 new 这个节点呢?当然是将它并入已形成的链当中来啊,毕竟我们构造 creat() 这个函数的目的本身就是不断在已有链的基础上添加新的结点,在这条链没有一个结点的时候,我们可以认为这是一条空链,随着我们添加了第一个结点,它就成为了有一个结点的链,而这样的操作显然是有递归的性质的——只要条件合适,我们可以一直用新的结点连接前一个尾结点,并且我们可以很容易地设置一个终止条件,例如一个学生的 id 号是 -1 时,我们便停止调用creat() 函数,并且返回指向队尾结点的指针,因为这个终止条件十分容易设置,不如我们就将它作为递归函数 creat() 的终止条件。这时,我们再把眼光放回来,会发现 creat() 函数的形参在无形中已经被定下来了。就像前面提到的“我们可以一直用新的结点连接前一个尾结点”,在我们已经在 creat() 函数中定义了一个新结点new 的基础上,我们仍然需要的是链表的最后一个结点 end ,如此我们便可以通过一定的操作将 new 纳入到新的一条链当中来。因此,我们需要的形参不妨设置为 stu *end 。
creat()函数内的语句
通过上面的分析,我们大致确定了 creat() 函数的基本形式为:stu *creat(stu *end){}
那么接下来我们只需分析函数体中的语句了:
stu *new = (stu *)malloc(sizeof(stu));用这条语句我们定义了一个指向新结点的指针new,同时利用malloc()函数为它分配了一个stu* 类型、大小为 sizeof(stu) 的地址。
然后,我们需要将 end指向的结点 与 new指向的结点 联系起来。我们在main()函数中不定义一个指向队首结点的指针,我们只是声明一个stu*类型的head变量,将它的值初始化为NULL后用它来实现指向队首结点的功能。那么,在main()函数中调用creat()函数时,我们将head作为creat()函数的实参。
故在调用creat()函数时,end参数又有两种情况了,其中一种是end==NULL的情况,这指的正是前面第一次调用creat()函数时将head作为实参的情况,此时将head的值拷贝到end中,而由于传递的是指针变量,即地址,end指向的内存单元的地址与head指向的内存单元的地址实际上是相同的,那么对end的操作会引起head的相同的变化,例如当我们将new和end两者指向的结点连接起来时,实际上就是head指向的结点与new指向的结点建立了联系。
另外一种自然是end!=NULL的情况,这表明这条链已经不再是空链了,至少包含有一个非空结点了。那么,end确实是现有链的最后一个结点了,我们要做的就是将new指向的结点并入到这条旧链当中来以便构成一条新链了。
那么,问题已经逐步变得清晰明了。我们还需要为各个结点的数据域的赋值语句,并且还需要一个判断结构(前面讲到,以学生的id号是否为-1作为判断的条件),如果学生的id号不为-1,自然是继续建立新的结点,也就是继续调用creat()函数;为-1,那么就需要结束函数,释放为new指向的结点分配的内存空间,并返回指向最后一个结点的指针了。
disappear()函数
disappear()函数的类型
由于disappear()函数被用来释放为整条链开辟的内存空间,那么,我们大可不必设置它的返回值,直接设置为void类型即可。
disappear()函数的形参
我们要将这条链上的结点一个个消除,自然需要结点的指针。至于是队首结点还是队尾结点的都不重要,因为这是条双向链表,不论从哪一头开始都可以遍历整条链。因此,不妨直接设置为stu* head。
disappear()函数内的语句
对于这个,需要根据head指向的是队头还是队尾来决定,因为每个结点有next和before两个方向。假设head是指向队头结点的,那么我们一直往next的方向前进即可。我们可以设置一个temp指针,让它指向head指向结点的下一个结点,通过以temp是否为NULL作为判断条件的while循环结构来实现不断消除结点。
代码
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct stu
{
char id[3];
char name[10];
struct stu *next;
struct stu *before;
}stu;
stu *creat(stu *end)
{
stu *new = (stu *)malloc(sizeof(stu));
if (end == NULL)
{
end = new;
end->before = NULL;//至关重要
}
else
{
end->next = new;
new->before = end;
new->next = NULL;
}
printf("student id(input -1 to stop),then his/her name please:\n");
scanf("%s", new->id);
scanf("%s", new->name);
if (strcmp(new->id, "-1") != 0)
creat(new);
else
{
end->next = NULL;
free(new);
return end;
}
}
void disappear(stu *head)
{
stu *temp = head->next;
while (temp != NULL)
{
free(head);
head = temp;
temp = temp->next;
}
free(head);
printf("Free all nodes successfully.\n");
}
int main()
{
stu *head = NULL;//不能直接使head->before=NULL;
stu *temp = NULL;
head = creat(head);
printf("Output in contrary order:\n");
printf(" %15s%15s\n", "student id", "student name");
while (head != NULL)
{
printf(" %15s%15s\n", head->id, head->name);
if (head->before == NULL)
break;
head = head->before;
}
temp = head;
printf("Output in order:\n");
printf(" %15s%15s\n", "student id", "student name");
while (head != NULL)
{
printf(" %15s%15s\n", head->id, head->name);
if (head->next == NULL)
break;
head = head->next;
}
disappear(temp);
return 0;
}运行一下代码:
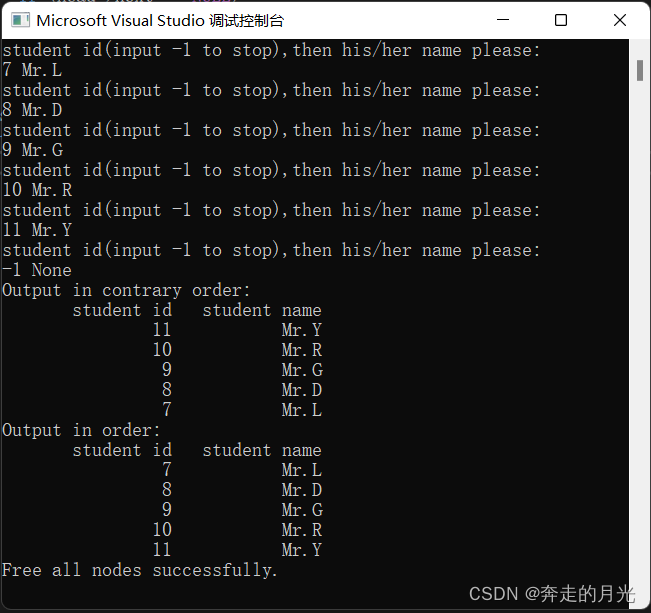
对于以上代码,它的实现过程已经讲得足够清晰了,但还有一点,请看代码第17行和第51行的注释。我解释一下原因,第17行的代码是与第61行的if判断结构密切关系的,如果去掉第17行的代码,我们运行一下程序:
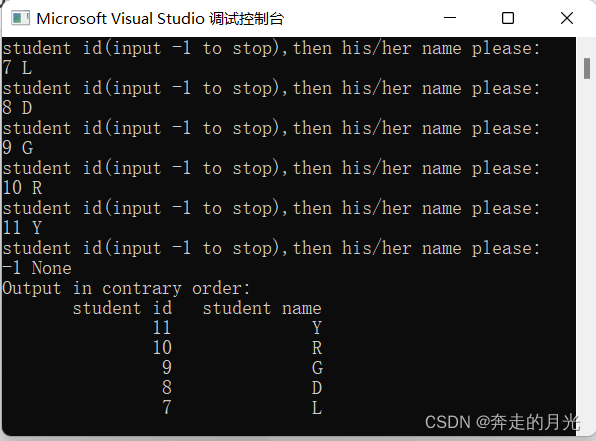
会发现第68行及之后的语句好像并没有执行,同时在调试程序时第60行的代码会抛出以下错误:
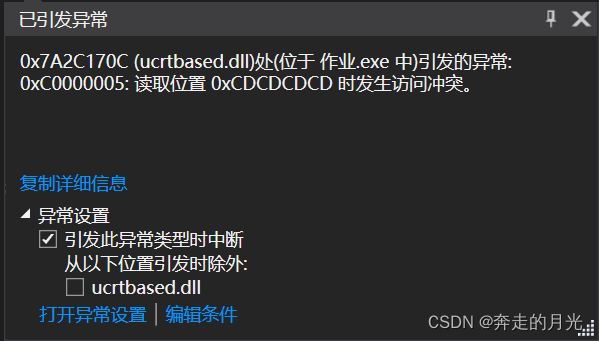

60行的代码本身没有错误,因为我们可以看到逆序确实打印出了完整的信息。关键是61行的if判断结构,我设置这个判断结构的目的是在head指向的正好是队首结点的时候跳出循环,以便利用下一个while()循环顺序打印出链表信息。说到底,还是第61行的if判断结构出了问题,因为当head指向队首结点时,head->before指向的是哪个内存单元呢?而队首结点的前面已经没有节点了,这就导致head->before指向的不确定性。所以,我们需要把队首结点的before域置为NULL,如何做呢?只需在向这条空链中添加第一个结点的时候,将第一个结点也就是队首结点的before域置为NULL即可,这就是第17行代码存在的原因。
至于第51行的代码的注释,更多的是为了尝试另外一种解法,即将第17行代码删去,同时在第51行代码后面添加 head->before=NULL; ,那么这行得通吗?答案是否定的。调试过程中编译器抛出了以下异常:
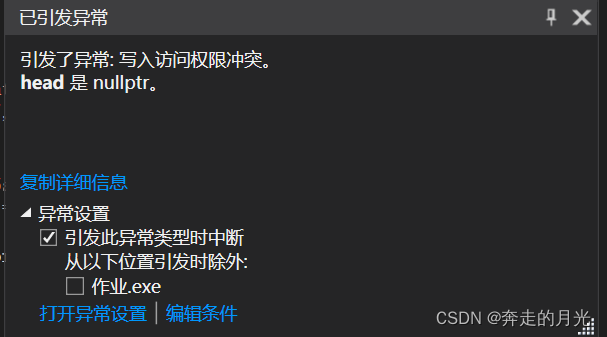

控制台上什么也没有输出。问题在哪里呢?有引发的异常可知,head 是 nullptr。我们在这篇博客——typedef与结构体中提到:
结构体指针在被定义时就需要被赋初值,这个初值可以是 NULL 或是其它同类型的变量的值。若初值为 NULL ,后续被使用时仍然需要被赋予同类型的常量的值。
而我们在main()中声明head的时候,编译器并给它分配了内存空间。我们可以做个小实验:
#include<stdio.h>
typedef struct stu
{
char id[3];
char name[10];
struct stu *next;
struct stu *before;
}stu;
int main()
{
stu *head = NULL;
printf("%p\n", head);
printf("%p", &head);
return 0;
}执行这段代码:
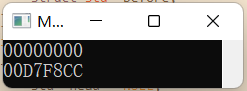
会发现 head 的值为00000000,而 &head 的值为 00D7F8CC,可以看出有为head分配内存空间,因为我们能够得到存储 head 变量的内存单元的首地址即 00D7F8CC。又因为 head 没有存储某个 stu 类型变量的地址,所以在51行代码后面加上head->before=NULL; 明显是有问题的,我们都没为 head 确定指向的内存单元块怎么能够将head的before指针域置为NULL呢,它连指向哪个内存空间都不知道嘛,哪能对before指针域进行操作?这里只是声明了head变量,所以没有为它确定指向的地方。
本篇完。
欢迎指正我的上一篇博客:一题多解×5(数组+循环链表)
我的下一篇博客:地址与值的更改



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











