










目录
题目:
一堆猴子有m个,编号分别是1,2,3 ...m,这m个猴子按照编号1,2,…,m的顺序围坐一圈,然后从第1开始数,每数到第n个,该猴子就要离开此圈,这样依次下来,直到圈中只剩下最后一只猴子,则该猴子就为大王。要求给出一组m和n,输出对应的猴王。
题意是这样的,假设m=9,n=4,由于顺时针或逆时针挑选对结果影响不大,不妨按顺时针排序后挑选,构图如下:
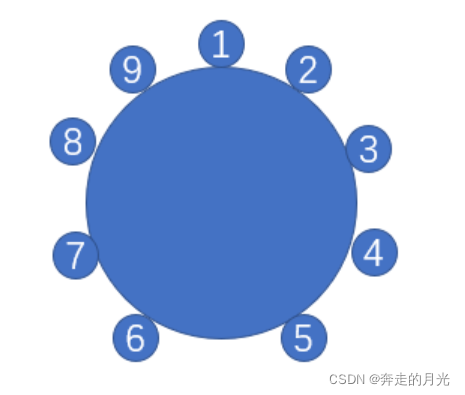
| 次数 | 开始的猴子的号码 | 被挑选离开的猴子的号码 | 剩余猴子的号码 | m |
| 1 | 1 | 4 | 1、2、3、5、6、7、8、9 | 8 |
| 2 | 5 | 8 | 1、2、3、5、6、7、9 | 7 |
| 3 | 9 | 3 | 1、2、5、6、7、9 | 6 |
| 4 | 5 | 9 | 1、2、5、6、7 | 5 |
| 5 | 1 | 6 | 1、2、5、7 | 4 |
| 6 | 7 | 5 | 1、2、7 | 3 |
| 7 | 7 | 7 | 1、2 | 2 |
| 8 | 1 | 2 | 1 | 1 |
这个例子建议大家可以自己用笔操作一番,增加一下理解题意的深度。可以看出,剩余猴子的号码个数是在递减的,当只有一个猴子的号码的时候那么该猴子就是猴子王了。
这也就是说,在这只猴子被挑走后,我们从它的下一只猴子继续按序挑选。题意理解完了以后,我们再来考虑一下m和n的意义,m代表猴子的个数,n代表相邻两次挑选的间隔数目。那么道理就很明显了,m与n是有一个大小的比较的。在探讨m和n大小关系比较对于解答本题的用处时,我得先说明一个概念,以上面那个例子为例:
挑猴子王的过程中一个循环是指从开始点绕一圈回到开始点的过程。在上图第一次挑猴子时,我们走一个循环需要的步数是m+1=9+1=10,过程为1->2->3->4->5->6->7->8->9->1,用了10步。
说明这个概念可能在m>=n时没有什么很大的帮助,但在m<n这种情况下却是很重要的。
因为挑猴子王的过程是一个动态的过程,在挑去一个猴子后,m也需要相应的自减。因此,m>n\m=n\m<n这三种情况中的某一种不可能一直成立,这个问题也可以在上面那个例子看到:在第5次挑选之后,就只剩4个猴子了,这之前大于4只,这之后小于4只,虽然这是在m>n的情况下得到的结果,但他适用于这三种情况。因此我们只需将这3中情况所需的代码分别写明,然后让符合情况的部分运作即可。
现在我们来讨论一下这三种情况:
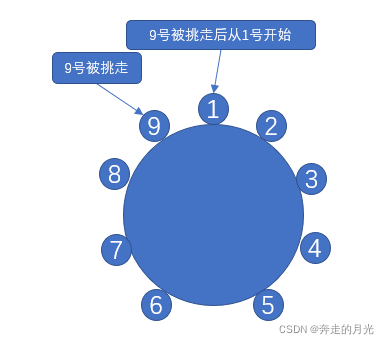
1、m==n:
被挑走的是第m个猴子,在重新标号时第一个猴子刚好是上一轮挑选中的第一个猴子。例如,m=n=9,那么在第一次挑选后,我们仍然是从1号猴子开始挑选的:
2、m>n:
这种情况很常规,不必讨论。
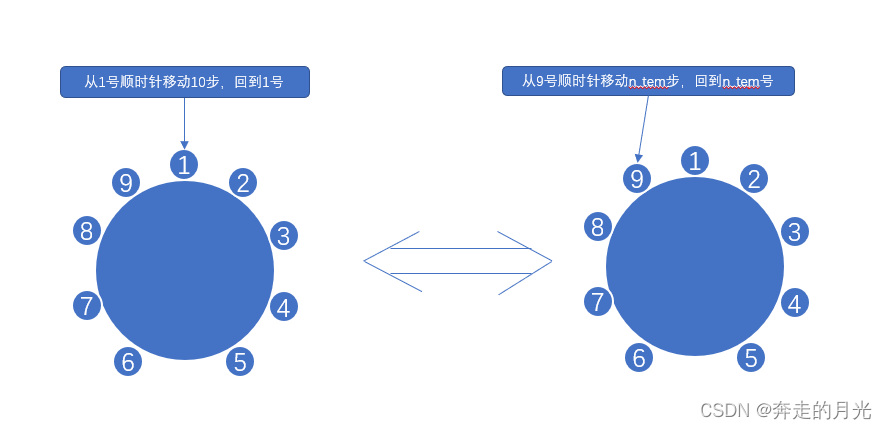
3、m<n:
此种情况类同m>n,只需n有所改变。因为m<n,而循环地遍历一遍猴子需要循环m+1次才能回到起点,因此用一个临时变量n_tem得到n以m为模时取得余数即可。例如,m=9,n=10,那么我实际上回到了1号猴子,但由于n_tem=n%m=1,在此基础上相当于从9号结点顺时针移了一步,故1号猴子被挑走:
现在对于这个题目的大致情况我们已经了解了,那么上代码:
解法一:
#include<stdio.h>
int main()
{
int m, n;
int n_tem;
int a[101];//max=100
int b[101];//我们舍弃了a[0]及b[0],为了操作的简便
scanf("%d%d", &m, &n);//input m&n
for (int i = 1; i <= m; i++)
a[i] = i;
while (m != 1)
{
if (n < m)
{
for (int i = n + 1; i <= m; i++)
{
b[i - n] = a[i];//将第n+1个到m个结点代号存进b[]
}
for (int i = 1; i <= n - 1; i++)
{
b[m - n + i] = a[i];//将第1个到n-1个结点代号存进b[],注意b[]元素下标从m-n开始
}
for (int i = 1; i <= m - 1; i++)
a[i] = b[i];//复制元素
m--;
}
else if (n > m)
{
n_tem = n % m;
if (n_tem == m)//例如m=5,n=11,最终第m个猴子将被挑走,m在原基础上减1,而下面的第一个for循环中i不应该达到m
{
m--;
continue;
}
for (int i = n_tem + 1; i <= m; i++)//将第n_tem+1个到m个结点代号存进b[]
{
b[i - n_tem] = a[i];
}
for (int i = 1; i <= n_tem - 1; i++)//将第1个到n_tem-1个结点代号存进b[],注意b[]元素下标从m-n_tem+1开始
{
b[m - n_tem + i] = a[i];
}
for (int i = 1; i <= m - 1; i++)
a[i] = b[i];
m--;
}
else
{
m--;
}
}
printf("%d", a[1]);
return 0;
}运行结果:
首先,输入m及n的值,结果为最终猴子王的标号,并且为了操作的简便,我们舍弃了a[0]和b[0],从下标1开始存储元素。利用第9、10行代码为每个猴子标号。然后在m与n的大小比较中有3种情况,分情况讨论:
1、m==n:
相应的语句块中只需有m--;语句,这是因为被挑走的是第m个猴子,在重新标号时第一个猴子刚好是上一轮挑选中的第一个猴子,而m自减后表明此时继续在剩下的m-1个猴子中挑选猴子王。
2、m>n:
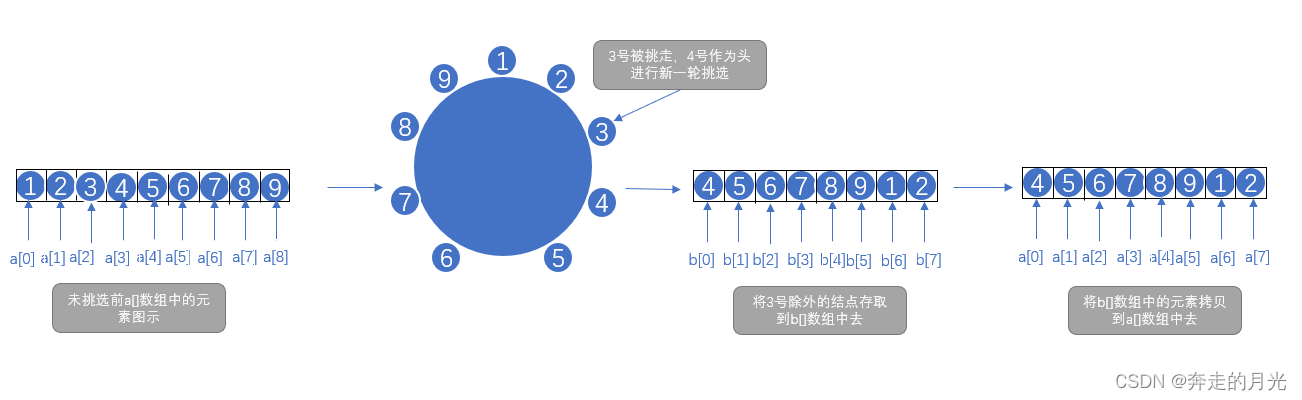
a[]数组是我们用来存储被挑剩下的猴子的,它的元素值是所代表的猴子的号码;b[]数组是用来存储挑选到被淘汰的猴子时按序从该猴子的下一位猴子起将数组a[]中的猴子一个个保存的,之后将b[]中的元素拷贝到a[]中。例如:
若n=3,那么有
b[1]=4; b[2]=5; b[3]=6; b[4]=7; b[5]=8; b[6]=9; b[7]=1; b[8]=2;之后将b[]中的元素拷贝到a[]中,便有
a[1]=4; a[2]=5; a[3]=6; a[4]=7; a[5]=8; a[6]=9; a[7]=1; a[8]=2;然后m--;代表猴子总数目减少一个。图示为:
3、m<n:
此种情况类同m>n,只需n有所改变。因为m<n,而循环地遍历一遍猴子需要循环m+1次才能回到起点,因此用临时变量n_tem存取n以m为模取得的余数,即可得到和m>n类同的情况。
为了更好地表明我所说的,我需要讲一下29、30行代码的意思:
因为我们的数组从下标1开始存储元素,一直是第n个结点被我们挑掉。假如m=3,n=4,那么应当是第1个结点首先被挑走,所以应当是n_tem=n%m=4%3=1,第一个结点被我们挑走,所以第29行代码是n_tem=n%m;;至于第30行的if判断结构,要表示的是一种特殊情况,比如m=5,n=11,最终第m个猴子将被挑走,这与m==n这种情况是一样的,故其语句块里只需要有m--;用来减少猴子数目及continue;结束本次循环即可。
在m=1时表明只剩下一个猴子,同时跳出while循环,而a[1]保存着猴子王的号码,因为a[]始终保存着剩余的猴子数目,当它只有一个元素时,自然就是猴子王的号码了。
贴一种相似的代码:
#include<stdio.h>
int main()
{
int m, n;
int n_tem;
int a[100];//max=100
int b[100];
scanf("%d%d", &m, &n);//input m&n
for (int i = 0; i < m; i++)
a[i] = i + 1;
while (m != 1)
{
if (n < m)
{
for (int i = n; i < m; i++)
{
b[i - n] = a[i];
}
for (int i = 0; i < n - 1; i++)
{
b[m - n + i] = a[i];
}
for (int i = 0; i < m - 1; i++)
a[i] = b[i];
m--;
}
else if (n > m)
{
n_tem = n % m;
if(n_tem==m)
{
m--;
continue;
}
for (int i = n_tem; i < m; i++)
{
b[i - n_tem] = a[i];
}
for (int i = 0; i < n - 1; i++)
{
b[m - n_tem + i] = a[i];
}
for (int i = 0; i < m - 1; i++)
a[i] = b[i];
m--;
}
else
{
m--;
}
}
printf("%d", a[0]);
return 0;
}这段代码和上面那段代码思路上唯一的不同便是a[0]和b[0]是要被用到的。
解法二:
#include<stdio.h>
#include<stdlib.h>
typedef struct node
{
int iId;
struct node* next;
}*node;
int main()
{
int m, n;
node head = NULL;
node new=NULL;
node end=NULL;
node temp = NULL;
scanf("%d%d", &m,&n);
for (int i = 0; i < m; i++)
{
new = (node)malloc(sizeof(struct node));
new->iId = i + 1;
if (head == NULL)
{
head = new;
end = new;
}
else
{
end->next = new;
end = new;
}
}
new->next = head;
temp = head;
node temp_pos=NULL;
while (m > 1)
{
for (int i = 1; i <= n; i++)
{
if (i == n - 1)
{
temp_pos = temp->next;
temp->next = temp->next->next;
free(temp_pos);
m--;
continue;
}
temp = temp->next;
}
}
printf("%d", temp->iId);
return 0;
}这是博主写的第二种解法,接下来我给大家讲一下简单的思路。相比于第一种解法,思路上简单了很多。我们先建立一个循环链表,建立循环链表的操作不难,如果不会可以参考这篇博文:循环链表×双向链表(C语言)。成功建立循环链表后,接着通过计数将挑选到的猴子结点释放掉,在这之前将该节点的前一个结点与其后一个结点连接起来重新组成一个循环链表。
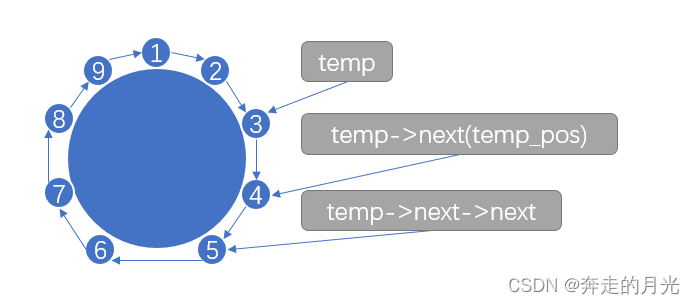
我们在第32行代码中让temp指针指向逻辑上的队首结点,然后在33行定义了一个temp_pos指针用于在38行的if判断结构中指向temp的下一个结点,事实上temp_pos结点就是我们要挑选掉的猴子结点。
在这种解法中,我们要挑走的结点仍然是第n个结点,所以在38行的if判断结构中当i==n-1即temp指针指向我们要挑走的猴子结点的前一个结点时,才执行判断语句块里的内容。
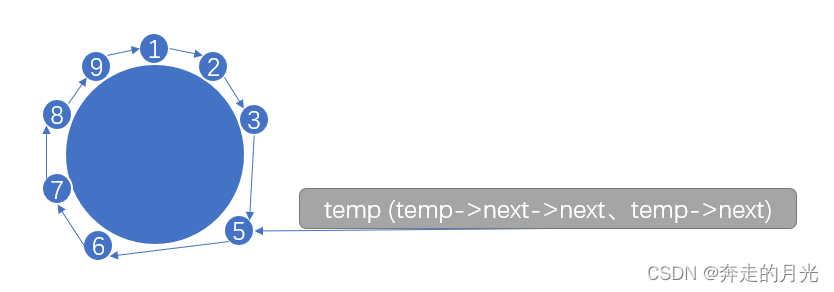
假设第40代码执行后的图示如下:
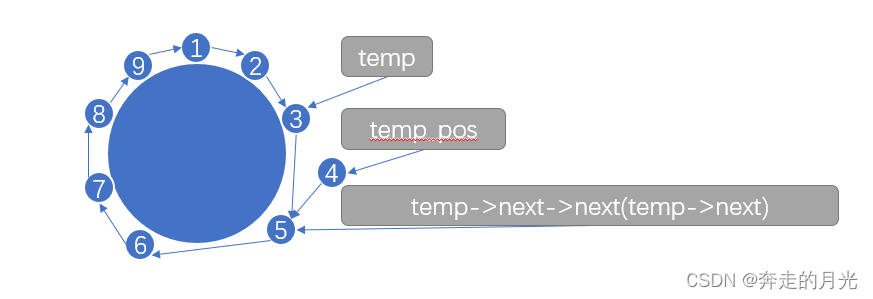
那么第41行代码执行后的图示为:
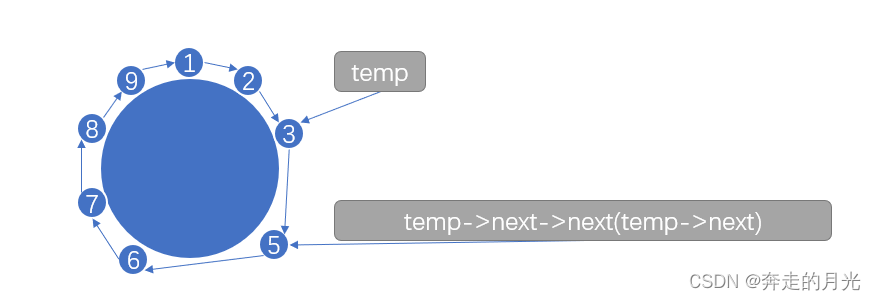
第42行代码执行后的图示为:
第46行代码执行后的图示为:
本篇博文到此为止。
欢迎指正我的上一篇博客:typedef与结构体
我的下一篇博客:递归实现双向链表



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











