







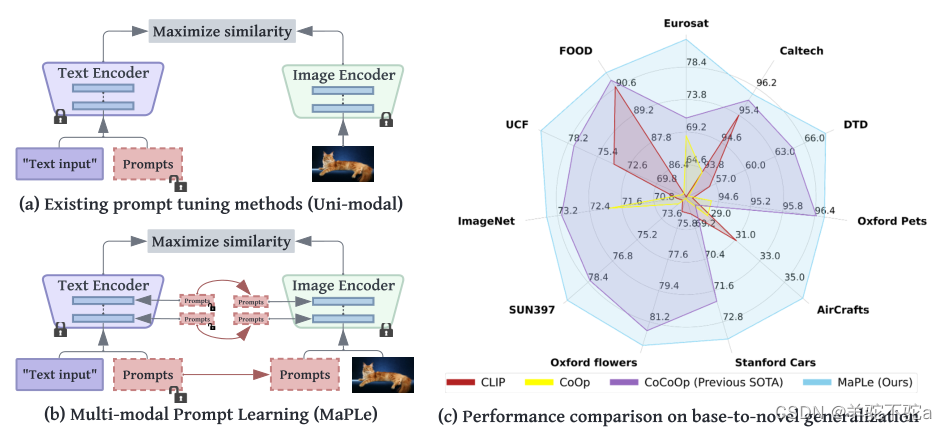
 MaPLe是一种多模态提示学习方法,旨在改善CLIP模型中视觉和语言表征的一致性。通过学习深度语言和视觉提示,MaPLe在多个转换块中逐步建模两种模态的协同行为,增强上下文学习,提高CLIP在下游任务上的对齐效果。相比仅微调单一模态,MaPLe通过耦合函数促进两种模态之间的交互,实现更好的多模态适应。
MaPLe是一种多模态提示学习方法,旨在改善CLIP模型中视觉和语言表征的一致性。通过学习深度语言和视觉提示,MaPLe在多个转换块中逐步建模两种模态的协同行为,增强上下文学习,提高CLIP在下游任务上的对齐效果。相比仅微调单一模态,MaPLe通过耦合函数促进两种模态之间的交互,实现更好的多模态适应。
1.motivation
最近的CLIP适应方法学习提示作为文本输入,以微调下游任务的CLIP。使用提示来适应CLIP(语言或视觉)的单个分支中的表示是次优的,因为它不允许在下游任务上动态调整两个表示空间的灵活性。在这项工作中,我们提出了针对视觉和语言分支的多模态提示学习(MaPLe),以改善视觉和语言表征之间的一致性。促进了视觉语言提示之间的强耦合,以确保相互协同,并阻止学习独立的单模态解决方案。此外,在不同的早期阶段学习单独的提示,逐步对阶段特征关系建模,以允许丰富的上下文学习。
本文动机源于CLIP的多模态特性,其中文本和图像编码器共存,并且都有助于正确对齐V -L模态。
作者认为任何提示技术都应该完全适应模型,因此,仅为CLIP中的文本编码器学习提示不足以模拟图像编码器所需的适应。为此,着手实现提示方法的完整性,并提出了多模态提示学习(MaPLe),以充分微调文本和图像编码器表示,以便在下游任务中实现最佳对齐(图1:b)。
工作的主要贡献包括:
•在CLIP中进行多模态提示学习,以更好地调整其视觉语言表征。据我们所知,这是第一个用于微调CLIP的多模式提示方法。
•为了将文本和图像编码器中学习到的提示联系起来,我们提出了一个耦合函数来明确地对其语言对应的视觉提示进行条件设置。它作为两种模式之间的桥梁,允许梯度的相互传播,以促进协同作用。
•我们的多模态提示是在视觉和语言分支的多个转换块中学习的,以逐步学习两种模态的协同行为。这种深度提示策略允许独立地对上下文关系进行建模,从而为对齐视觉语言表示提供更大的灵活性。
2. 方法
我们的方法涉及微调预训练的多模态CLIP,以便通过提示进行上下文优化,更好地泛化到下游任务。图2显示了我们提出的MaPLe(多模式提示学习)框架的整体架构。与之前的方法[48,49]不同,MaPLe提出了一种联合提示方法,其中上下文提示在视觉和语言分支中都被学习。具体而言,我们在语言分支中附加可学习的上下文标记,并通过耦合函数显式地将视觉提示条件置于语言提示上,以建立它们之间的交互。为了学习分层上下文表示,我们在两个分支中通过跨不同转换块的单独可学习上下文提示引入深度提示。在微调期间,只学习上下文提示及其耦合函数,而模型的其余部分被冻结。下面,我们首先概述预训练的CLIP架构,然后介绍我们提出的微调方法。
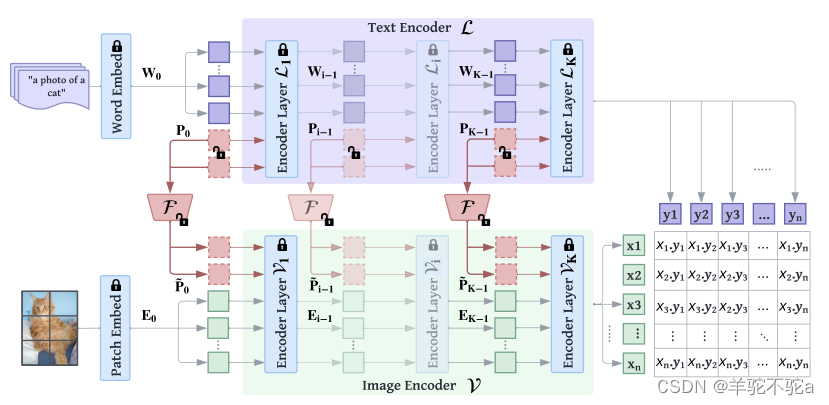
图2。概述我们提出的用于V-L模型中提示学习的MaPLe(多模态提示学习)框架。MaPLe调节视觉和语言分支,其中只有上下文提示被学习,而模型的其余部分被冻结。MaPLe通过V-L耦合函数F将视觉提示置于语言提示上,以诱导两种模式之间的相互协同作用。我们的框架使用深度上下文提示,其中跨多个转换器块学习单独的上下文提示
2.1 回顾Clip
我们在预先训练的视觉语言模型CLIP上构建我们的方
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









