







一、介绍
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库1进行数据存储,存在以下性能瓶颈:
1.IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率降低,请求数据太多,带宽不够,网络IO瓶颈;
2.CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU会出现瓶颈;
分库分表的中心思想就是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的;
拆分策略
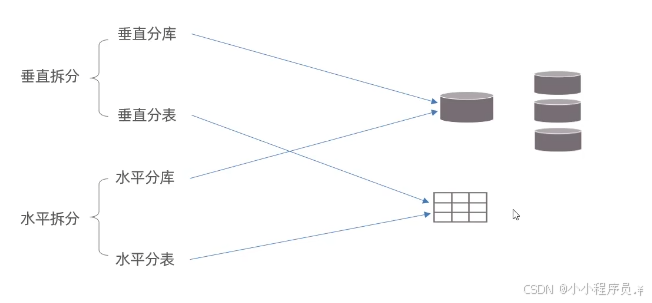
二、垂直拆分
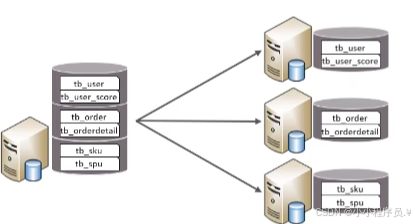
(1)垂直分库:以表为依据,根据业务将不同的表拆分到不同库中。
特点:每个库的表结构不一样;每个库的数据也不一样;所有库的并集是全量数据;
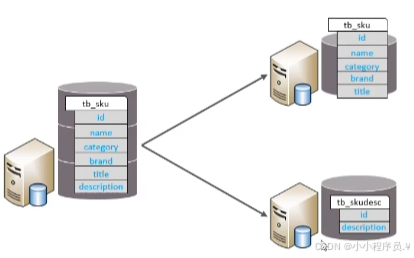
(2)垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中;
特点:每个表的结构不一样;每个表的数据也不一样,一般通过一列(主键/外键)关联;所有表的并集是全量数据;
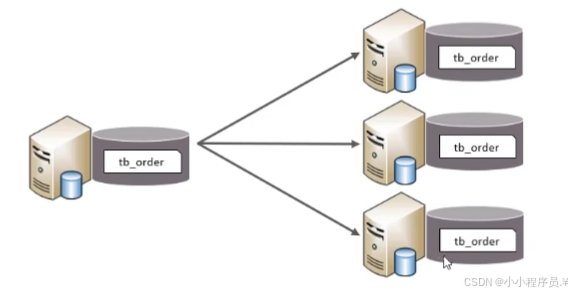
2.水平拆分
(1)水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中;
特点:每个库的表结构都一样,每个库的数据都不一样;所有库的并集是全量数据;
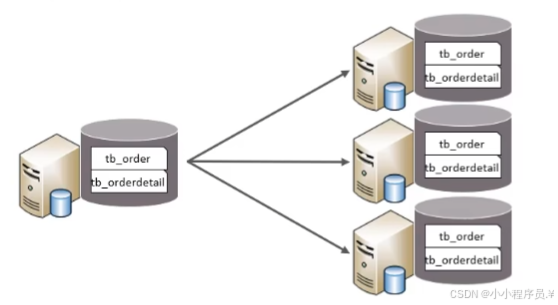
(2)水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中;
特点:每个库的表结构都一样,每个库的数据都不一样;所有库的并集是全量数据;
三、实现技术
1.shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截、解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高;
2.mycat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者;


















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











