







近期,Meta推出了Llama 4系列的首批模型: Llama 4 Scout 和 Llama 4 Maverick。
模型特点:
1、上下文长度支持:
Llama 4 Scout上下文支持达到了1000万。
2、混合专家模型结构:
Llama 4 Scout 和 Llama 4 Maverick均为MoE架构模型,Llama 4 Scout 是一个拥有 16 位专家的 170 亿活跃参数模型,Llama 4 Maverick 是一个拥有 128 位专家的 170 亿活跃参数模型。
3、原生多模态:
模型采用原生多模态设计,结合早期融合,将文本和视觉标记无缝集成到统一的模型主干中, 早期融合能够使用大量未标记的文本、图像和视频数据联合预训练模型。同时改进了 Llama 4 中的视觉编码器。它基于 MetaCLIP,但与冻结的 Llama 模型一起单独训练,以便更好地使编码器适应 LLM。
4、超大模型:
本次Meta还预览了 Llama 4 Behemoth,是Meta迄今为止最强大的新模型,也是 Llama 4 Scout 和 Llama 4 Maverick的老师。
这只是 Llama 4 系列的开始。Meta将继续研究和制作模型和产品的原型,并将在 4 月 29 日的 LlamaCon 上分享更多内容。
最近春招和实习已开启了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

01 预训练
Llama 4代表了 Llama 的最佳性能,以极具吸引力的价格提供多模态智能,同时性能优于明显更大的模型。在 MoE 模型中,单个 token 仅激活总参数的一小部分。MoE 架构在训练和推理方面具有更高的计算效率,并且在给定固定训练 FLOP 预算的情况下,与密集模型相比,可提供更高的质量。
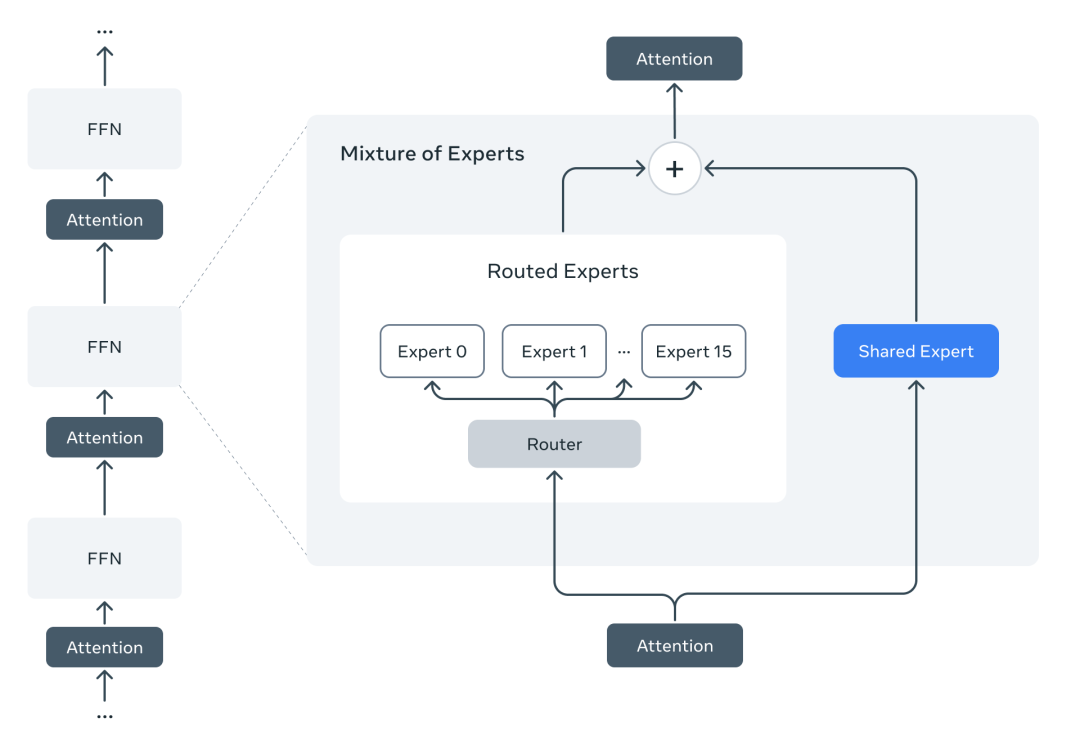
例如,Llama 4 Maverick 模型有 17B 个活动参数和 400B 个总参数。使用交替的密集和混合专家 (MoE) 层来提高推理效率。MoE 层使用 128 位路由专家和一位共享专家。每个令牌都会发送给共享专家以及 128 位路由专家之一。因此,虽然所有参数都存储在内存中,但在为这些模型提供服务时,只有总参数的子集被激活。
02 后训练
对 Llama 4 Maverick 模型进行后期训练时,最大的挑战是在多种输入模式、推理和对话能力之间保持平衡。对于混合模式,研究团队提出了一个精心策划的课程策略,与单个模式专家模型相比,该策略不会牺牲性能。借助 Llama 4,通过采用不同的方法改进了研究团队的后期训练流程:轻量级监督微调 (SFT) > 在线强化学习 (RL) > 轻量级直接偏好优化 (DPO)。一个关键的学习是,SFT 和 DPO 可能会过度约束模型,限制在线强化学习阶段的探索并导致准确性不理想,特别是在推理、编码和数学领域。
为了解决这个问题,使用 Llama 模型作为判断标准,删除了 50% 以上标记为简单的数据,并对剩余的较难数据集进行了轻量级 SFT。在随后的多模式在线强化学习阶段,通过仔细选择更难的提示,研究团队能够实现性能的阶跃变化。此外,研究团队实施了持续在线 RL 策略,交替训练模型,然后使用它来持续过滤并仅保留中等难度到困难难度的提示。
事实证明,这种策略在计算和准确性权衡方面非常有益。然后,研究团队做了一个轻量级 DPO 来处理与模型响应质量相关的极端情况,有效地在模型的智能和对话能力之间实现了良好的平衡。管道架构和具有自适应数据过滤的持续在线 RL 策略最终形成了业界领先的通用聊天模型,具有最先进的智能和图像理解功能
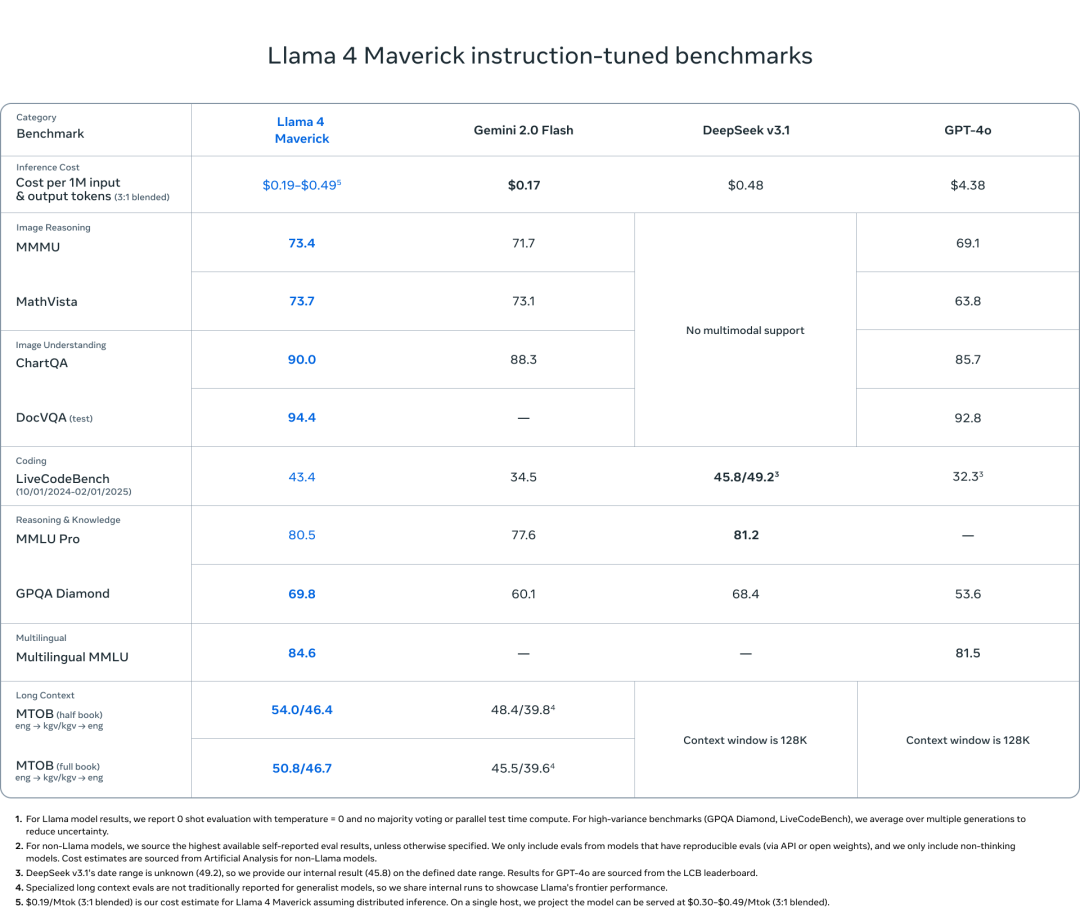
研究团队的小型模型 Llama 4 Scout 是一个通用模型,拥有 170 亿个活动参数、16 位专家和 1090 亿个总参数,可提供同类中一流的性能。Llama 4 Scout 将支持的上下文长度从 Llama 3 中的 128K 大幅增加到行业领先的 1000 万个标记。这开辟了一个无限可能的世界,包括多文档摘要、解析大量用户活动以执行个性化任务以及对庞大的代码库进行推理。
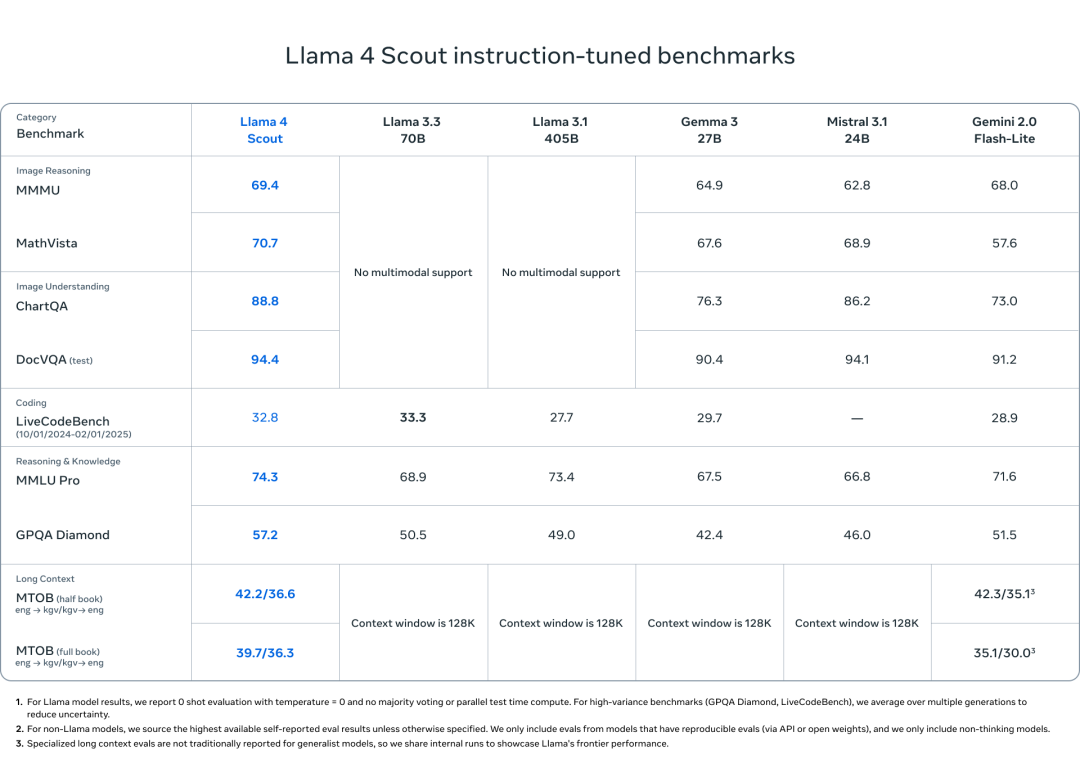
研究团队用各种图像和视频帧静态图像训练了研究团队的两个模型,以便让它们具有广泛的视觉理解能力,包括时间活动和相关图像。这使得多图像输入以及用于视觉推理和理解任务的文本提示能够轻松交互。这些模型在多达 48 张图像上进行了预训练,研究团队在训练后测试了多达 8 张图像,取得了良好的效果。
Llama 4 Scout 在图像基础方面也处于领先地位,能够将用户提示与相关的视觉概念对齐,并将模型响应锚定到图像中的区域。这使得 LLM 能够更精确地回答视觉问题,从而更好地理解用户意图并定位感兴趣的对象。Llama 4 Scout 在编码、推理、长上下文和图像基准方面也超越了同类模型,并且比所有以前的 Llama 模型都具有更强大的性能。
03 模型推理
transformers推理代码
请确保已经安装了 transformers v4.51.0 版本,或者通过运行 pip install -U transformers 来升级。
from modelscope import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "LLM-Research/Llama-4-Scout-17B-16E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
attn_implementation="flex_attention",
device_map="auto",
torch_dtype=torch.bfloat16,
)
url1 = "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/car.jpg"
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": url1},
{"type": "text", "text": "Can you describe the image?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
print(response)
print(outputs[0])
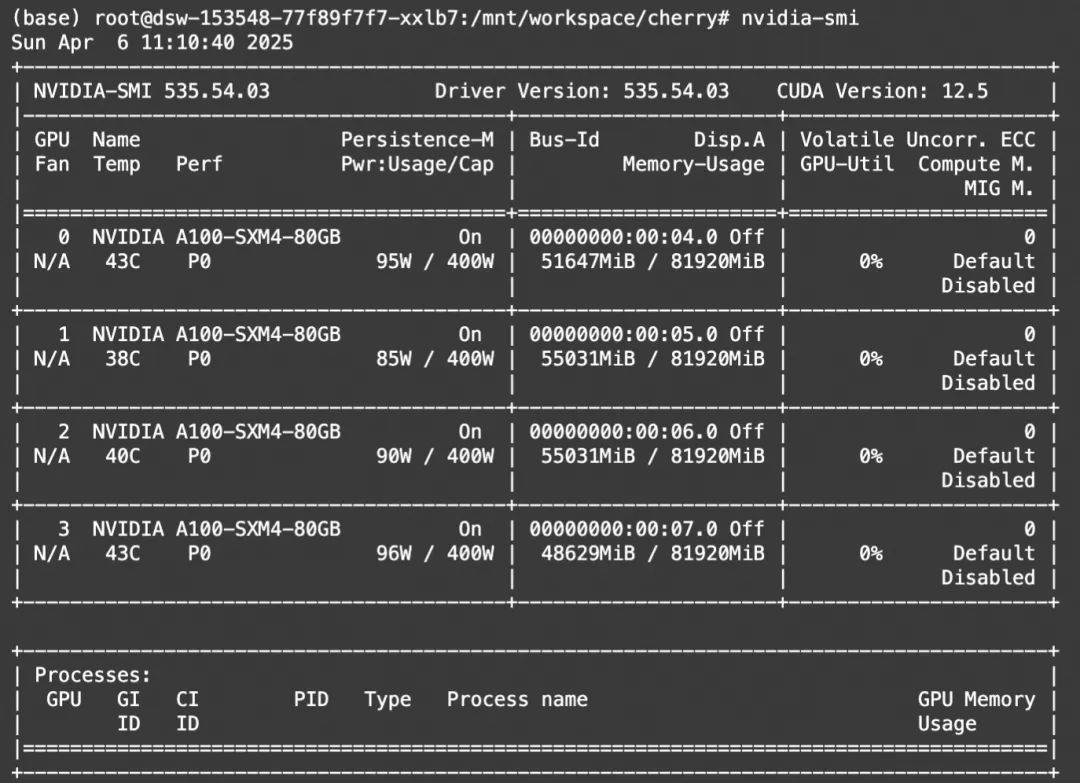
显存占用:
04 模型微调
我们介绍使用ms-swift对LLM-Research/Llama-4-Scout-17B-16E-Instruct进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
图像OCR微调脚本如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model LLM-Research/Llama-4-Scout-17B-16E-Instruct \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite#2000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--gradient_checkpointing false \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
训练显存资源:

自定义数据集格式如下(system字段可选),只需要指定`–dataset <dataset_path>`即可:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}
训练完成后,使用以下命令对训练时的验证集进行推理:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048
推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'
推送模型到ModelScope:
```bash
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









