







摘要
这篇博客介绍了CRNN:Rich feature hierarchies for accurate object detection and semantic segmentation这篇文章,CRNN是一种双阶段目标检测算法。RCNN 通过选择性搜索方法生成候选区域,再用CNN网络提取候选区域特征,用SVM分类器对候选区域进行分类,并用线性回归期对边界框进行调整,取得了比传统目标检测算法更高的性能,尤其在小物体检测和精细定位方面优势明显。另外,针对当时目标检测数据集不足的问题,文章利用了迁移学习的方法,先用相对丰富图像分类数据集来训练CNN,再用目标检测数据集对其进行微调。迁移学习的思想至今仍被广泛使用。
Abstract
This blog post introduces the article “CRNN: Rich feature hierarchies for accurate object detection and semantic segmentation,” which discusses the CRNN, a two-stage object detection algorithm. The RCNN generates candidate regions through selective search, then uses a CNN network to extract features from these regions. It classifies the candidate regions with an SVM classifier and adjusts the bounding boxes with a linear regression model, achieving higher performance than traditional object detection algorithms, especially in detecting small objects and precise localization. Additionally, to address the issue of insufficient object detection datasets at the time, the article employs transfer learning, training the CNN with a relatively abundant image classification dataset and then fine-tuning it with an object detection dataset. The concept of transfer learning is still widely used today.
文章简介
Title: Rich feature hierarchies for accurate object detection and semantic segmentation
Author: Girshick, R (Girshick, Ross) ; Donahue, J (Donahue, Jeff) ; Darrell, T (Darrell, Trevor) ; Malik, J (Malik, Jitendra)
WOS:https://arxiv.org/abs/1311.2524
研究背景与动机
在本文作者提出RCNN算法之前,目标检测方法主要基于手工特征,如尺度不变特征变换(SIFT)和方向梯度直方图(HOG)。但是,手工特征的设计依赖于人类的先验知识,对于复杂多变的物体形状和场景,很难提取到足够具有代表性的特征。而且这些方法在处理大规模数据集和复杂场景时,计算效率较低,准确性也难以满足实际需求。
SIFT和HOG是团块、方向的空间像素信息,这类似于灵长类大脑皮层区域的V1细胞(类似卷积神经网络的前几层)。但识别发生在下游的几个阶段,也就是说,对视觉识别来说有分层的、多阶段的过程来计算特征有着更大的潜力。
在规范的PASCAL VOC数据集上测量的目标检测性能已经达到瓶颈。性能最好的方法是复杂方法的集成,其通常将多个低级图像特征与高级上下文相结合。
随着2012年AlexNet的提出及其在图像分类上的突出表现,研究者们开始思考CNN 可以在多大程度上运用到目标检测领域。
RCNN算法流程
为了回答 CNN 可以在多大程度上运用到目标检测领域这一问题,必须先解决两个问题:
- 用深度神经网络来定位目标
- 用少量的标记数据来训练模型

RCNN先在原图上生成包含对象的候选框,本文是采用的selective search 算法来生成候选框。然后将不同大小的各个候选框通过仿射图像扭曲来进行缩放,得到固定大小的“warped region”。再将各“warped region”送入卷积网络中提取特征,将特征送入SVM对每个“warped region”进行分类。同时,CNN提取到的特征会送入用于微调边框的SVM,用于预测目标边框的调整参数,使定位更准确。
对于第一个问题,RCNN先后用selective search算法得到可能包含对象的候选框,然后利用CNN学习所有候选区的特征,再将其送入SVM,得到边框的调整参数,实现目标的准确定位。
对于第二个问题,本文是利用了迁移学习的思想。对于图像分类任务,已经有相对较多的数据集,所以先用ImageNet 预训练一个用于图像分类的CNN网络,文中用的是AlexNet。预训练后的CNN网络已经具有较好的提取图像特征的能力,然后用目标检测数据集PASCAL VOC来对CNN网络进行微调,使得CNN能够更有效的提取PASCAL VOC图像的特征。
模型训练
RCNN需要训练的模型有三个:CNN、SVM分类器、边界框回归SVM。

训练流程:
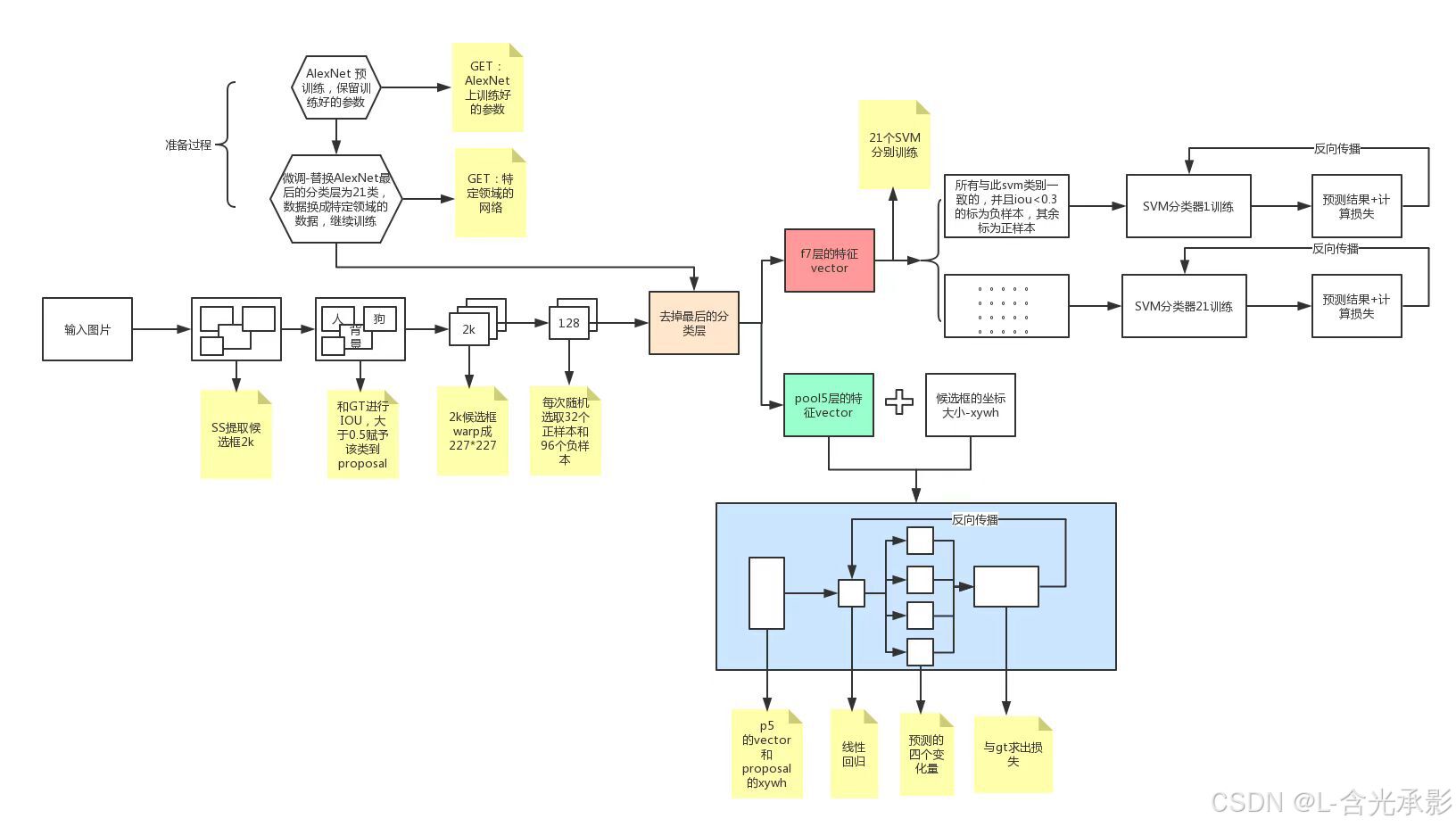
CNN微调
在预训练时,用的CNN是AlexNet,但输出的类别数与ImageNet中的不同,需要根据PASCAL VOC的类别数来更改输出层,改为N+1个神经元,其中N是PASCAL VOC中对象的类别数,还需要判断是否为背景,预训练的CNN网络结构描述如下:

CNN微调时的输入时PASCAL VOC数据集(经过SS算法生成候选框),其中包含了标注的边界框信息和类别信息。
目标检测的正样本(分类对象)比负样本(背景)少得多,为了增加正样本的数量以保证正负样本的相对平衡,训练时以32:96(mini- batch size=128)的要求来对正负样本采样,正样本只有一个,需要扩充正
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









