







目录
摘要
本文探讨了标准梯度下降法在参数更新方面的局限性,并介绍了自适应学习率算法,特别是Adagrad和RMSProp。这两种算法通过考虑历史梯度来动态调整学习率,但它们在处理梯度权重方面有所不同。文章还讨论了“梯度爆炸”问题,并分析了学习率衰减(Learning Rate Decay)和预热(Warm Up)策略的效果及其计算方法,这两种策略都将时间因素纳入学习率的调整中。此外,本文还对卷积神经网络(CNN)进行了基础介绍,解释了卷积操作提取特征的原理和步骤,并阐述了池化操作的作用及其实施步骤。
Abstract
This article explores the limitations of the standard gradient descent method for parameter updates and introduces algorithms for automatically adjusting the learning rate, with a focus on Adagrad and RMSProp. These algorithms dynamically adjust the learning rate by taking into account historical gradients, but they differ in how they handle gradient weights. The paper also discusses the issue of "gradient explosion" and analyzes the effects of learning rate decay and warm-up strategies, both of which incorporate temporal factors into the calculation of the learning rate. Additionally, the paper provides a preliminary introduction to convolutional neural networks (CNNs), explaining the principle and steps of using convolution to extract features, and discusses the role and procedure of pooling operations.
1. 自动调整学习率
在训练模型的时候,如果损失不再下降,这并不意味着梯度为 0 ,可能梯度也比较大,只是参数更新不再能使损失变得更小。如下图中,参数更新情况为图中绿线表示,这时梯度不为0,但是由于参数更新的问题,损失不再下降。
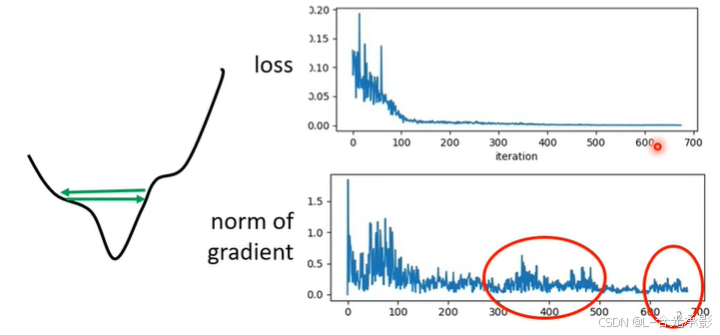
下面为一组简单的模型训练的情况:
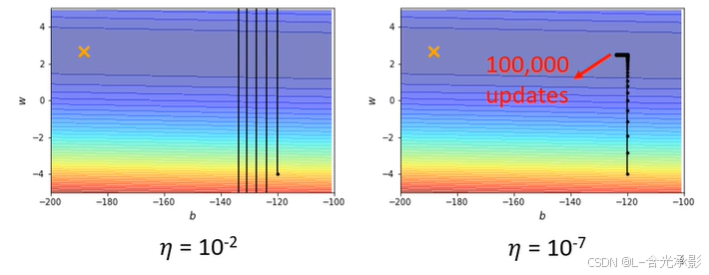
从图中右下角黑色点所表示的参数开始左图中开始更新,左上角为损失最小时对应的参数。很明显左图是学习率过大,导致参数更新的步长太大,有图中学习率足够小,但是也不能是参数更新到理想状态,更新到W值接近理想参数的w时,b方向上的梯度很小,导致更新参数更新到 w=120后参数b基本不更新了。所以需要更灵活的学习率来支持梯度下降。
上图中,横轴方向上的梯度较小,而纵轴上的梯度较大。针对不同的参数,梯度是不一样的,所以需要不同的学习率来更好地更新参数。以下以一个参数的学习率为例进行说明。
1.1 Adagrad 算法

Adagrad 算法在学习率的计算中考虑到了前面所有位置的梯度。若梯度较大,则 较大,
较小,新的学习率就较小,步长也较小;若梯度较小,则相反,达到了梯度大时步长小、梯度小时步长大的效果,更适合参数更新。但此算法对于同一个参数来说,其学习率相差不大。但对于一个参数,也可能有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









