




一、引言
近年来,人工智能技术经历了爆发式的发展,深度神经网络在自然语言处理、计算机视觉及目标检测等诸多领域展现出了超越人类的准确度。然而,随着模型性能的提升,网络层数与参数量呈指数级增长,带来了巨大的计算开销与存储压力。为了解决这一瓶颈,基于忆阻器(Memristor)的神经网络加速器应运而生。忆阻器凭借其非易失性和“存算一体”的特性,利用忆阻交叉阵列在O(1)时间复杂度内完成矩阵乘法,被视为突破冯·诺依曼瓶颈的理想硬件架构。
尽管如此,在资源受限的边缘计算场景中,直接部署庞大的网络模型仍极具挑战。因此,“模型剪枝”成为了降低硬件开销的必要手段。它通过去除网络中的冗余权重,减少无效计算。针对传统剪枝方法在忆阻器硬件上“水土不服”的问题,周博等人提出一种混合粒度剪枝方法。该方法旨在在大幅压缩模型体积、降低能耗的同时,最大程度地保持神经网络的推理精度,实现软硬件协同优化的最佳平衡。
二、当下问题
在将深度学习模型轻量化并部署至忆阻器硬件的过程中,现有的主流剪枝技术普遍面临着“硬件效率”与“模型精度”难以兼得的结构性难题。
- 非结构化剪枝:硬件利用率的痛点
首先,传统的非结构化剪枝虽然在软件层面应用广泛,但在忆阻器硬件上却遭遇了严重的“水土不服”。非结构化剪枝以单个权重为最小操作粒度,通过随机剔除数值较小的连接来压缩模型。这种做法虽然能大幅减少参数数量,却会导致权重矩阵变得极度稀疏且分布无序。然而,忆阻器加速器的核心——交叉阵列(Crossbar)是一种紧密耦合的物理结构,同一行或同一列的忆阻单元在电气上是共享字线与位线的。这意味着,即便某个单独的权重被剪除,只要该行或该列中仍存在其他有效权重,整行或整列的电路单元就必须被激活以参与计算。因此,非结构化剪枝后的稀疏矩阵不仅无法在物理上减少Crossbar的占用面积,反而因为保留了大量无效的电路激活而无法真正降低能耗,导致理论上的压缩无法转化为实际的硬件收益。
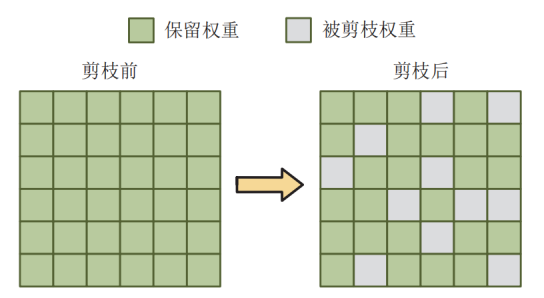
图1 非结构化剪枝示意图
- 结构化剪枝:精度损失的瓶颈
为了解决上述硬件适配问题,研究界提出了结构化剪枝方案。该方案采用更粗犷的策略,直接以过滤器、通道或权重矩阵的整行、整列为粒度进行删除。这种策略与Crossbar的物理结构高度契合:一旦剪除一整列权重,对应的Crossbar列即可被物理移除或完全断电,从而实打实地节省芯片面积并降低静态功耗。但是,这种“一刀切”的方式存在明显的弊端。由于剪枝粒度过粗,一个被判定为冗余的权重列中,往往混杂着对特征提取至关重要的“关键权重”。若为了迎合硬件结构而强行删除整列,势必会误删这些重要信息,从而导致神经网络的推理精度出现不可逆的严重下降。
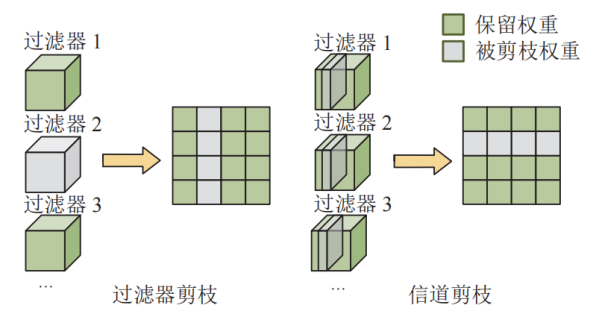
图2 结构化剪枝示意图
- 搜索难题:寻找平衡点的挑战
综上所述,当前的困境在于:非结构化剪枝保住了精度却浪费了硬件资源,而结构化剪枝节省了硬件却牺牲了精度。如何在数以百万计的参数中,精准地识别出哪些区域可以“大刀阔斧”地整列删除,哪些区域需要“精雕细琢”地保留,本质上是一个极其复杂的NP难(Non-deterministic Polynomial-time hard)问题。这不仅需要对权重的重要性进行精准评估,更需要构建一种能够将硬件拓扑约束纳入考量的智能搜索框架,以便在庞大的搜索空间中找到压缩率与准确率的最佳平衡点。这正是本文引入ADMM优化算法和混合粒度策略所要攻克的核心难点。
三、创新点
1. 细粒度剪枝方法
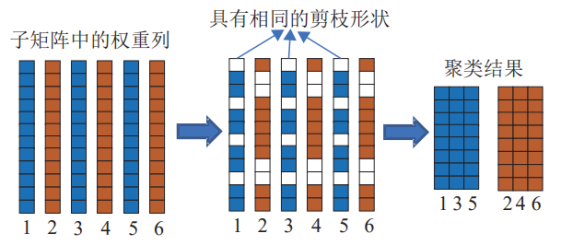
图3 细粒度剪枝
细粒度剪枝旨在处理那些冗余程度较低的权重列。这些权重列中既包含大量冗余权重,也混杂着对模型精度至关重要的权重。如果直接采用结构化剪枝删除整列,将不可避免地移除这些重要权重,导致CNN性能显著下降。为此,本论文引入细粒度剪枝机制,以单个权重为基本单位进行选择性删除。具体而言,对于每个权重列,按照权重绝对值的大小,从小到大排序,并固定剪去数量最少的np个权重。例如,在示例中设置np=4,即每列仅删除4个绝对值最小的权重,如图3所示。这确保了冗余权重被优先移除,而重要权重得以保留。
剪枝后的权重矩阵会变得稀疏,但为了适应MCA的紧密耦合结构,需要进一步优化布局。方法的关键创新在于对剪枝后的权重列进行聚类:那些具有相同剪枝的列会被聚合在一起,并映射到Crossbar阵列的相邻位置。这样,这些列仍能共享相同的输入信号,在单个时钟周期内完成矩阵-向量乘法运算,而不会引入额外的计算延迟或硬件冲突。聚类过程考虑了权重分布的随机性,确保剪枝后阵列的完整性和计算效率。通过这种方式,细粒度剪枝不仅降低了计算开销,还维持了MCA的并行计算优势,避免了非结构化剪枝带来的稀疏性问题。同时,它在保留精度的前提下,实现了更精细的压缩,适用于冗余度不高的权重区域。
- 混合粒度剪枝策略设计
单纯的细粒度或结构化剪枝各有局限:前者虽精度友好,但压缩效果有限;后者压缩高效,却易损精度。混合粒度剪枝通过智能分类解决了这一矛盾。首先,需要量化权重列的冗余程度。为此,将权重分为小值权重和非小值权重,小值权重的阈值设为tw。然后,根据权重列中小值权重的占比tp,对列进行二分类:如果占比大于阈值tp,则判定为高冗余权重列;否则为低冗余权重列。阈值tp的设置决定了分类的严格性,例如tp=0.5意味着超过50%的小值权重占比即为高冗余。
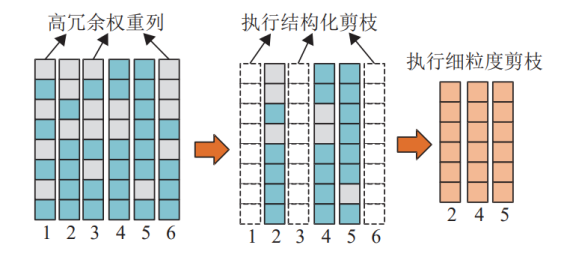
图4 混合粒度剪枝
对于高冗余权重列,由于其绝大部分权重对精度影响微弱,直接执行结构化剪枝:删除整列权重。这相当于移除Crossbar中整列忆阻器单元,显著减少硬件面积和能耗,而不会造成明显精度损失。对于低冗余权重列,则应用细粒度剪枝,仅删除部分冗余权重,避免误伤重要参数。以图4为例,假设tp=0.5,第1、3、6列的小值权重占比超过50%,执行结构化剪枝,直接移除;第2、4、5列占比低于50%,则仅剪去np个小值权重。这种分类策略充分利用了CNN权重分布的异质性:不同层或不同区域的冗余度差异大,高冗余区大胆压缩,低冗余区谨慎操作。结果是整体模型体积大幅缩小,同时精度保持稳定。该方法在迭代训练中动态调整,确保剪枝过程与网络优化同步进行。
- 算法设计
本篇论文引入交替方向乘子法(ADMM),这是一种处理非凸优化的有效工具。它将原始问题分解为更易处理的子问题,并结合随机梯度下降在CNN的迭代训练中逐步收敛,确保在压缩模型的同时保持精度。
算法的核心是同时最小化CNN的损失函数并施加剪枝约束。损失函数衡量模型的预测准确性,而剪枝约束确保每个权重列都执行合适的剪枝操作:高冗余列进行结构化剪枝,低冗余列进行细粒度剪枝。通过增广拉格朗日方法,算法迭代更新权重、剪枝变量和辅助乘子。在每次迭代中,权重更新类似于标准训练,剪枝更新则根据参数强制稀疏化权重矩阵。这种框架特别适应忆阻加速器,能模拟Crossbar布局,确保剪枝后权重高效聚类,避免额外计算开销。
算法采用逐层搜索策略,从网络深层开始(深层冗余更高)。针对每一层,遍历参数搜索空间,对临时模型执行剪枝,计算精度和剪枝率,然后用适应度函数选出最佳参数组合。所有层参数收集后,进行全局剪枝,最后再训练模型恢复精度。如图5所示,伪代码清晰描述这一流程:输入原始CNN模型,逐层搜索优化参数,输出剪枝后的高效模型。

图5 算法伪代码
四、实验数据
为了验证混合粒度剪枝方法在忆阻神经网络加速器上的效果,本研究从压缩率、精度保持能力、硬件开销等多个维度进行了量化评估。文章选用了行为级仿真平台MNSIM能够模拟基于忆阻器的神经形态计算系统的行为特性,以及忆阻器参数准确的TaOx材料器件模型,确保仿真结果更真实。
采用CACTI 6.5工具在32nm工艺节点下对忆阻交叉阵列(MCA)的外围电路进行建模,MCA的规格设定为128*128,每个忆阻器单元存储1位数据,权重量化精度设为8位。实验选取了MNIST和CIFAR10两个经典数据集,并分别在AlexNet、VGG16和Plain20三种不同规模深度的CNN模型上进行了测试。以未剪枝的Baseline作为基准,实验将其与Pim-prune、Pattern-Prune、Auto-Prune及PRAP-PIM等四种主流剪枝方案进行了横向对比。
实验结果表明,混合粒度剪枝方法在压缩率与精度保持优于现有方案。新方法展现了更高的权重缩减能力,在AlexNet模型实现了23.7倍的压缩率;VGG16模型的压缩率也有21.7倍,数据显著高于Pattern-Prune等结构化剪枝方法。这可以证明通过区分高冗余与低冗余权重列并实施差异化剪枝策略能够挖掘出网络中深层次的稀疏性。
此外,高倍率的压缩往往伴随着精度的剧烈下降。但在本研究中CIFAR10数据集上的VGG16模型在压缩15.3倍的情况下,精度损失仅为0.16%;AlexNet的精度损失也控制在0.41%以内,几乎实现了“无损”压缩。这一结果主要得益于ADMM算法保留了对网络推断至关重要的特征权重。
由于新方法的剪枝减少了映射到MCA上的权重数量,进而降低了CIM所需的交叉阵列数量及其带来的静态和动态功耗。在CIFAR10数据集AlexNet实现了94.9%的面积和93.6%的能耗缩减。在MNIST数据集上的面积与能耗缩减分别达到95.8%和96.0%。相比于Pattern-Prune等方法仅能提供约9.1%的面积节省,混合粒度剪枝在硬件资源受限的边缘计算场景中具有决定性的应用价值。
五、总结改进
本研究针对忆阻神经网络加速器设计中面临的“剪枝粒度与硬件结构不匹配”问题,提出了一种新的混合粒度剪枝方法。传统的非结构化剪破坏了MCA的规则结构,而结构化剪枝虽然硬件友好但精度损失严重。本文通过动态评估权重列的冗余度,结合细粒度剪枝与结构化剪枝的优势,成功解决了上述两难问题。研究证明,该方法不但大幅度降低了模型的参数量,还将算法层面的稀疏转化为面积与能耗收益。在保证神经网络推断精度的前提下,实现了压缩率、能量效率与计算精度的提高。对于AlexNet和VGG16这类具有较高冗余度的经典网络,该方法展现出了很强的压缩潜力,为基于RRAM的存算一体化芯片设计提供了极具价值的理论支撑与技术路径。
未来可进一步探索以“权重位(Bit-level)”为粒度的更精细剪枝方案。或进一步优化权重映射策略与稀疏索引机制,以降低在处理Transformer时的额外内存开销,使该剪枝框架能通用地适配今年热度较高的深度学习模型。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









