







文献基本信息
- 标题:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
- 作者:Huaishao Luo、Lei Ji、Ming Zhong、Yang Chen、Wen Lei、Nan Duan、Tianrui Li
- 单位:西南交通大学
- 会议/期刊:Neural Computing
- 发表时间:2021年5月8日
- 代码:https://github.com/ArrowLuo/CLIP4Clip
背景与意义
- 随着每天在线上传视频的增加,视频文本检索成为人们高效查找相关视频的一个新兴需求。除了实际的web应用之外,视频文本检索是多模态视觉和语言理解的一项基础研究任务。可以直接通过输入来对以前的工作进行分类:原始视频(像素级)或视频特征(特征级)。
- 预训练的模型是特征级的,因为在一些大规模视频文本数据集上进行过预训练,例如Howto100M,输入是通过现成的冻结视频特征提取器生成的缓存视频特征,如果输入是原始视频,则会使预训练非常缓慢。然而,得益于大规模数据集,预训练模型在视频文本检索方面表现出显著的性能提升。
- 像素级方法直接以原始视频作为输入来训练模型,早期模型几乎都属于这种方法,这种方法结合成对文本学习视频特征提取器。相反,特征级方法高度依赖于合适的特征提取器,它不能将学习的梯度传播回固定的视频编码器。
- 最近的一些工作开始用像素级方法对模型进行预训练,使预训练模型从原始视频中学习,最大的挑战是如何减少密集视频输入的高计算过载。
- ClipBERT采用了稀疏采样策略,使端到端预训练成为可能。具体地说,该模型仅在每个训练步骤中从视频中稀疏地采样一个或几个短片段。实验结果表明,端到端训练有利于低层特征提取,少量的稀疏采样片段就足以解决视频文本检索任务。
- Frozed模型将图像视为单帧视频,并设计了curriculum learning schedule,以在图像和视频数据集上训练模型。结果表明,curriculum learning schedule从图像学习到多帧信息,可以提高学习效率。
- 本文的目标不是预训练一种新的视频文本检索模型,而是主要研究如何将知识从图片文本预训练模型CLIP中迁移到视频本文检索任务中。
- 本文利用预训练好的CLIP,提出了一个名为CLIP4Clip(CLIP For video Clip retrieval)的模型来解决视频文本检索问题。
- 具体而言,CLIP4Clip构建在CLIP之上,并设计了一个相似度计算器来研究三种相似度计算方法:无参数型、顺序型和紧密型。
- 与目前基于CLIP的工作相比,不同之处在于,他们的工作直接利用片段进行zero-shot预测,而没有考虑不同的相似性计算机制。然而,本文设计了一些相似性计算方法来提高性能,并以端到端的方式训练模型。
研究方法与创新点
- 给定一组视频(或视频片段)
和一组文本
,模型的目标是学习函数
来计算视频(或视频片段)
与文本
之间的相似度。
- 根据文本到视频检索中的相似性得分,对给定查询文本的所有视频(或视频片段)进行排序,或者在视频到文本检索任务中对给定查询视频(或视频片段)的所有文本进行排序。
- 其中,视频(或视频片段)
个采样帧组成,使得
。
- 本文的模型是一种端到端方式(E2E),通过将帧作为输入直接对像素进行训练。
- 下图展示了本文的框架,主要包含一个文本编码器、一个视频编码器和一个相似性计算模块。
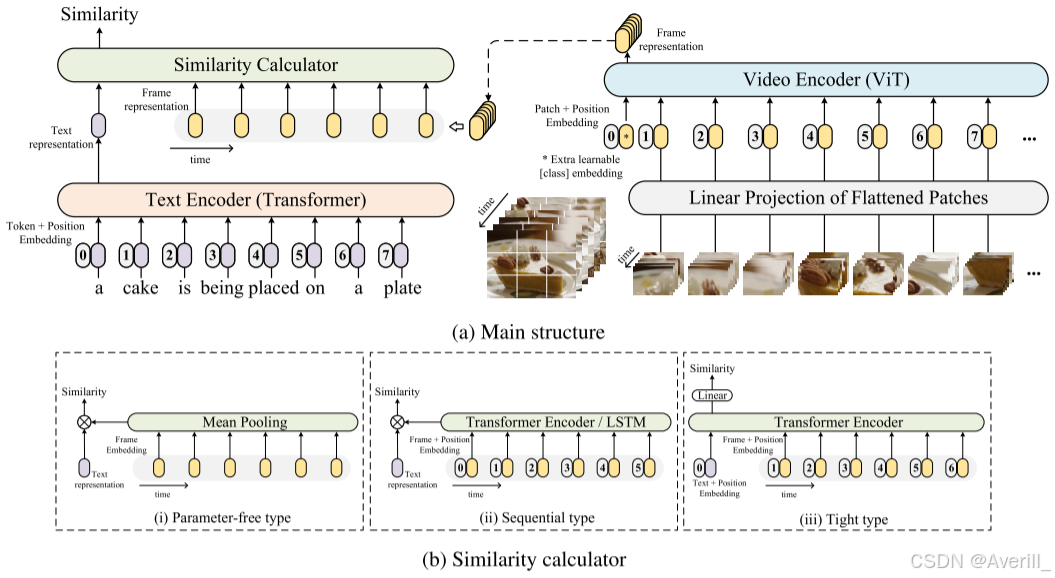
视频编码器
- 为了获得视频表示,首先从视频片段中提取帧,然后通过视频编码器对其进行编码,以获得一系列特征。
- 本文采用ViT-B/32作为视频编码器,具有12层,patch大小为32。
- 具体地,本文使用预训练的CLIP(VIT-B/32)作为主干网络,并且主要考虑将图像表示转移到视频表示。
- ViT首先提取非重叠图像块,然后用线性投影转换为一维的token,并且利用Transformer架构对输入图像的每个patch之间的交互进行建模,以获得最终的表示。
- 在CLIP的ViT之后,使用[class] token的输出作为图像表示。
- 对于视频的输入帧序列
。
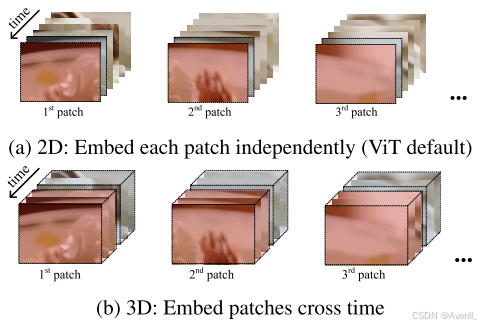
- 上图展示了patch线性投影模块中研究的两种类型的线性投影,分别为2D线性和3D线性。
- 将ViT的patch线性投影视为2D线性投影(上图(a)),独立嵌入每个二维帧patch,这样的二维线性模型忽略了帧之间的时间信息。
- 本文研究了3D线性投影(上图(b)),以增强时间特征提取,三维线性投影会跨时间的patch,具体地说,三维线性使用以
为核的卷积代替二维线性以
为核的卷积,其中
、
和
分别为时间、高度和宽度。
文本编码器
- 本文直接从CLIP中的文本编码器来生成文本表示,它是一种Transformer结构,是一个12层、通道为512的模型,有8个注意力头。
- 在CLIP之后,[EOS] token处Transformer最高层的激活被视为文本的特征表示,对于文本
。
相似性计算器
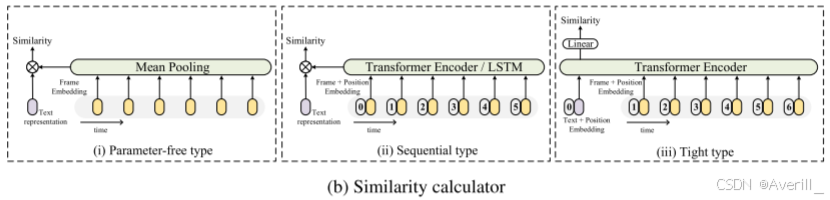
- 在提取视频表示
- 由于本文的模型是基于预训练的图像-文本模型构建的,因此应该在相似度计算模块中小心地添加新的可学习权重,如果没有权重初始化,很难进行学习,并且可能会影响使用反向传播的预训练模型训练的性能。
- 因此,本文根据模块是否引入新参数进行学习,将相似度计算器的机制分为三类(上图):无参数方法,即平均池化,在没有新参数的情况下融合视频表示;另外,还有两种方法引入了新的权值来学习,包括具有不同大小的新权值的序列型方法和紧密型方法。
- 无参数型和序列型的相似度计算器属于松散型,采用两个单独的分支分别用于视频和文本表示来计算余弦相似度。
- 而紧密型相似性计算器使用Transformer模型进行多模态交互,并通过线性投影进一步计算相似性。
- 两者都包含新的权重以供学习。
无参数型
- 通过对图像-文本对的大规模预训练的CLIP,帧表示
和文本表示
- 首先使用平均池化来聚合所有帧的特征,以获得“平均帧”:
- 然后,将相似性函数定义为余弦相似性:
序列型
- 平均池化操作忽略帧之间的顺序信息,因此,本文探索了两种为序列类型相似性计算器建模序列特征的方法:
- LSTM。
- 带位置嵌入的Transformer编码器。
- 这两种模型都是序列特征的有效模型,将其分别表示为
和
。
- 通过编码,嵌入了时间信息。
- 后续操作与无参数型相似性计算器相同。
紧密型
- 与上述无参数型和顺序型不同,紧密型使用Transformer编码器进行视频和文本之间的多模态交互,并通过线性层预测相似性,这引入了未初始化的权重。
- 首先,将文本表示
,然后用Transformer编码器进行建模,其公式如下:
- 其中,
表示concat操作,
是位置嵌入,
是类型嵌入,其包含两种类型的嵌入,一种用于文本,另一种用于视频帧。
- 然后,使用两个线性投影层和一个激活函数来得到
来计算相似度,表示为
- 其中,FC是线性投影,ReLU为激活函数。
训练策略
损失函数
- 给定一个batch,即
个视频-文本或视频片段-文本对,模型需要生成并优化
相似度矩阵,使用这些相似度分数上的对称交叉熵损失来训练模型的参数:
- 其中,损失函数为video-to-text损失和text-to-video损失的和。
帧采样
- 由于本文的模型是通过帧作为输入直接在像素上进行训练的,因此提取帧是一种重要的策略。
- 一个有效的采样策略需要考虑信息丰富度和计算复杂性之间的平衡。
- 为了考虑视频(或视频片段)中的顺序信息,采用了均匀的帧采样策略,而不是随机稀疏采样策略,采样率为每秒1帧。
预训练
- 虽然CLIP对于学习图像的视觉概念是有效的,但从视频中学习时间特征是必不可少的。
- 为了进一步将CLIP的知识迁移到视频,本文用CLIP4Clip模型在Howto100M数据集上进行了后预训练。
- 基于效率考虑,对视频文本数据集进行预训练是非常具有挑战性的,因此,使用“食品和娱乐”类别(约380k个视频)作为后预训练数据集。
研究结论
与SOTA进行比较
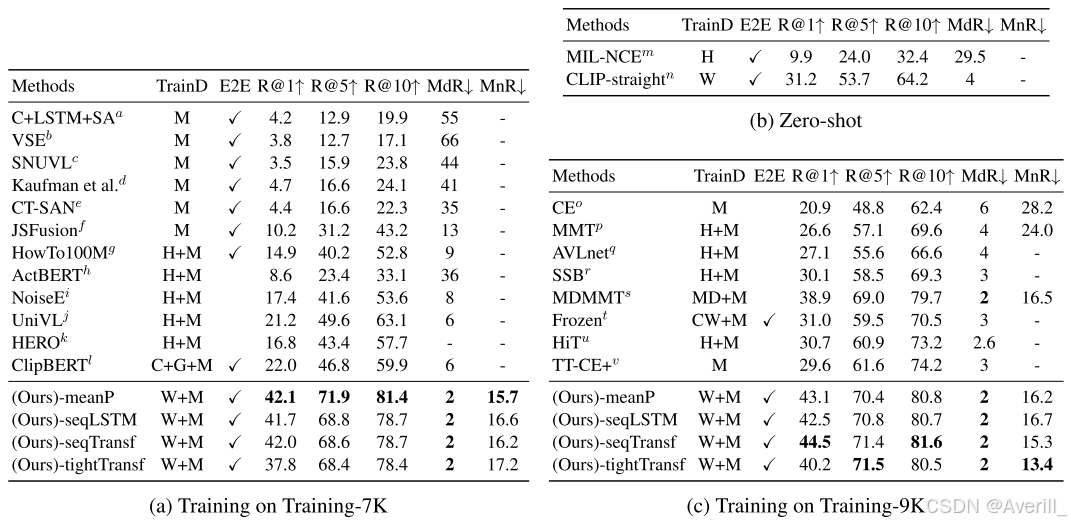
- 上图展示了本文方法和其他SOTA方法在MSR-VTT数据集上的实验结果。
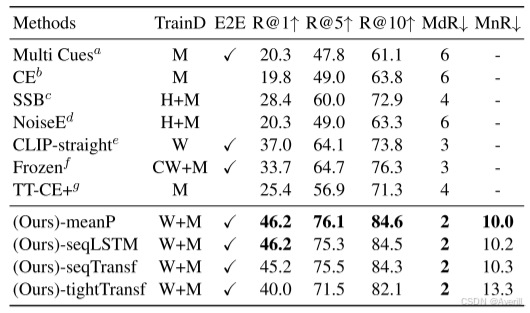
- 上图展示了本文方法和其他SOTA方法在MSVD数据集上的实验结果。
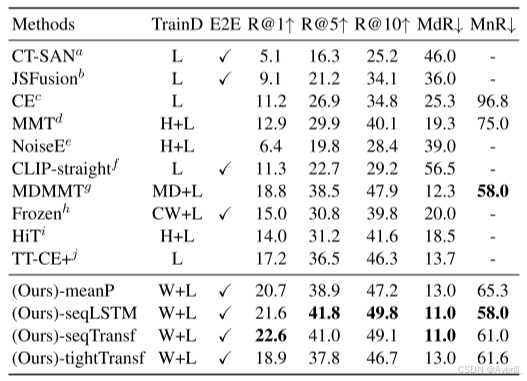
- 上图展示了本文方法和其他SOTA方法在LSMDC数据集上的实验结果。
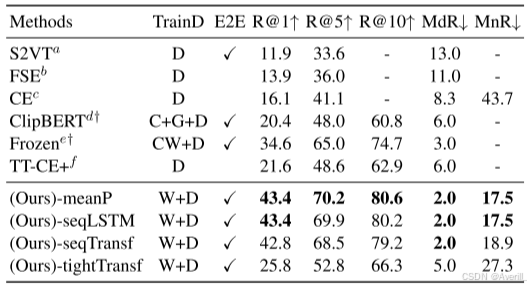
- 上图展示了本文方法和其他SOTA方法在ActivityNet数据集上的实验结果。
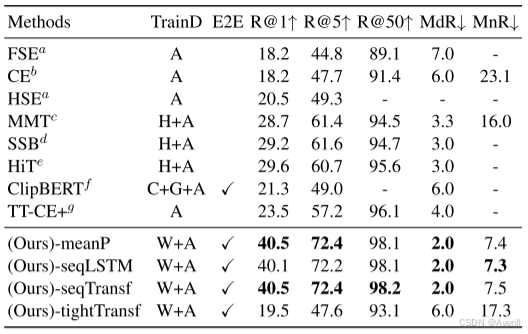
- 上图展示了本文方法和其他SOTA方法在DiDeMo数据集上的实验结果。
- 可以看出,本文方法在多个视频文本检索的数据集上都取得了SOTA的结果。
超参数和学习策略
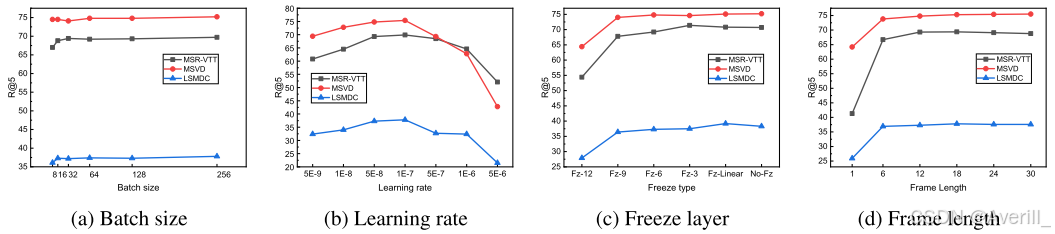
- 上图展示了本文方法在不同超参数和实验设置下的实验结果,可以看出,本文方法对于学习率是非常敏感的。
在视频数据集上进行后预训练
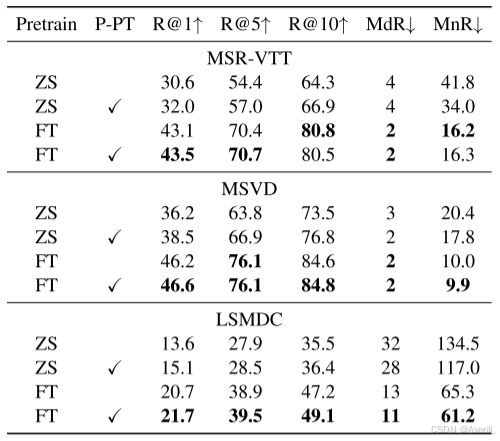
- 上图展示了是否在Howto100M-380k数据集上后预训练的结果,可以看出,后预训练总体来说还是能够进一步的提高性能的。
采样策略
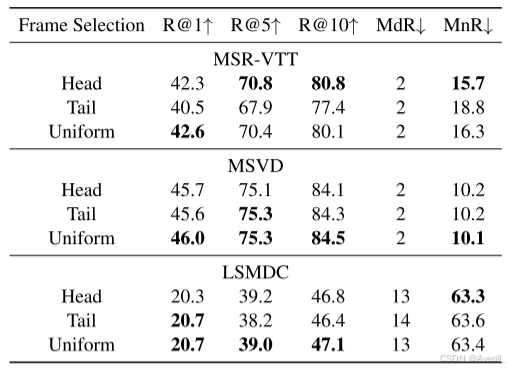
- 上图展示了不同数据集不同帧采样策略的实验结果。
2D/3D patch线性投影
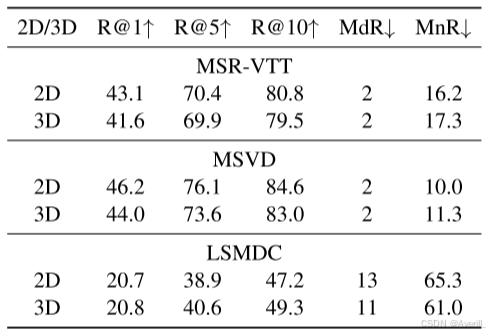
- 从上图可以看出,3D线性在MSR-VTT和MSVD上生成的结果都比2D线性差。
存在的问题
- CLIP4Clip在计算文本和视频的相似度时,只考虑了两个模态的总体表征,缺少细粒度的交互。比如,当文字描述只对应了视频的一部分帧时,如果抽取视频的整体特征,那么模型可能会被其它视频帧的信息干扰与误导。
启发与思考
- 图像特征也可以促进视频文本的检索。
- 对优秀的图像文本预训练CLIP进行后预训练,可以进一步提高视频文本检索的性能。
- 三维patch线性投影和序列类型相似度计算会是一种有前景的检索方法。
- 视频文本检索中使用的CLIP是学习率敏感的。


















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









