







文献基本信息
- 标题:Grounded Language-Image Pre-training
- 作者:Liunian Harold Li、Pengchuan Zhang、Haotian Zhang、Jianwei Yang、Chunyuan Li、Yiwu Zhong、Lijuan Wang、Lu Yuan、Lei Zhang、Jenq-Neng Hwang、Kai-Wei Chang、Jianfeng Gao
- 单位:UCLA、Microsoft Research、University of Washington、University of Wisconsin-Madison、Microsoft Cloud and AI、International Digital Economy Academy
- 会议/期刊:CVPR
- 发表时间:2022年6月17日
- 代码:https://github.com/microsoft/GLIP
背景与意义
- 目前的视觉识别任务通常是在一个预先定义好的类别范围内进行的,这样限制了其在真实场景中的扩展。
- CLIP的出现打破了这一限制,CLIP利用图像-文本对进行训练,从而使得模型可以根据文本prompt识别任意类别。
- CLIP适用于分类任务,而GLIP尝试将这一技术应用于目标检测等更加复杂的任务中。
- 本文提出了phrase grounding的概念,意思是让模型去学习图像和句子短语之间更加精细的联系,然后提出了GLIP(Grounded Language-Image Pre-training)模型。
研究方法与创新点
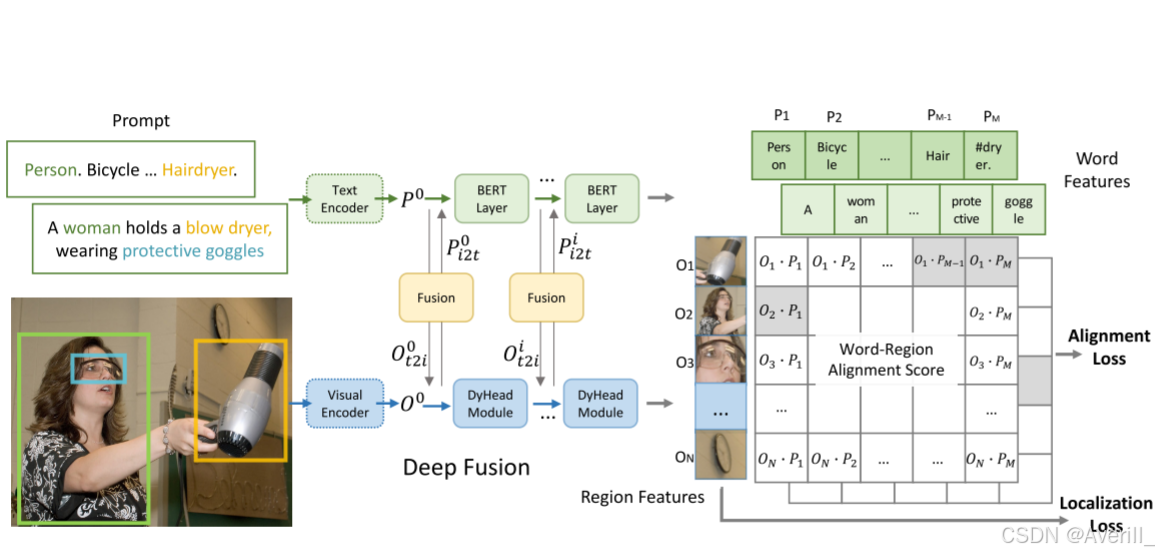
统一目标检测和phrase grounding任务
- 一个典型的目标检测网络的结构如下:
- 将图像输入到视觉编码器
中提取特征
,视觉编码器通常是CNN、Transformer等backbone。
- 将特征
和边界框回归器
中,得到分类结果和边界框回归结果。
- 分别计算分类损失和边界框回归损失,整体损失公式为:
。
- 将图像输入到视觉编码器
- 上述计算分类损失的流程可以用公式表达为:
- 其中,
代表target,即ground truth,
是分类器参数。
- 与上述分类器不同,GLIP将目标检测任务与phrash grounding统一,将目标检测中的每个区域与文本prompt进行匹配以实现分类效果。
- 举例来说,假设有
等类别,可以设计一个这样的prompt,其中每一个类别名字都是一个phrase:
- 可以通过添加更加精确的描述或者加载一些预训练语言模型来提升prompt的质量,例如在使用预训练的BERT模型时,像
这样的prompt表现会更好。
- grounding模型中的分类流程可以用公式表示为:
- 其中,$P$是语言编码器得到的文本特征,
的计算过程如下图所示:
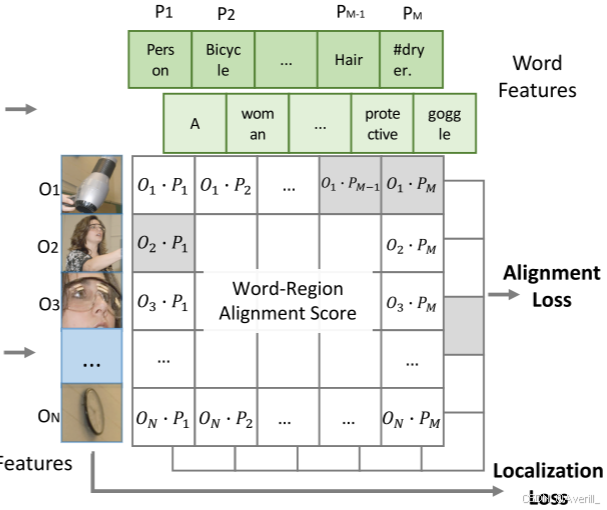
- 在传统的目标检测网络中,每个类别都会分配一个
的标签用于分类器计算损失。
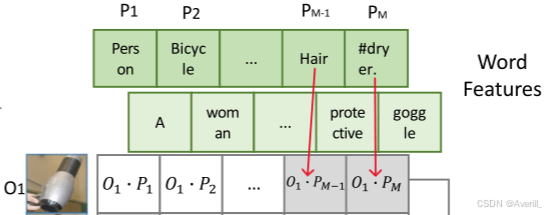
- 然而,在grounding模型中,一个短语(phrase)可能包含多个单词token,这就导致一个类别可能对应多个子单词(sub-word)。
- 针对这个问题,本文是这样做的:当这些子单词的短语与目标区域匹配时,每个正子单词都与目标区域所匹配,例如,吹风机的短语是“Hair dryer”,那么吹风机的区域就会与“Hair”和“dryer”这两个词都匹配,如下图所示:
图像-文本特征的深度融合
- 在CLIP等算法中,图像和文本特征通常只在最后用于计算对比学习的损失,即晚期融合模型。
- 本文在图像和文本特征之间引入了更深层次的融合(深度融合),在最后几个编码器层中进行了图像和文本的信息融合,如下图所示。
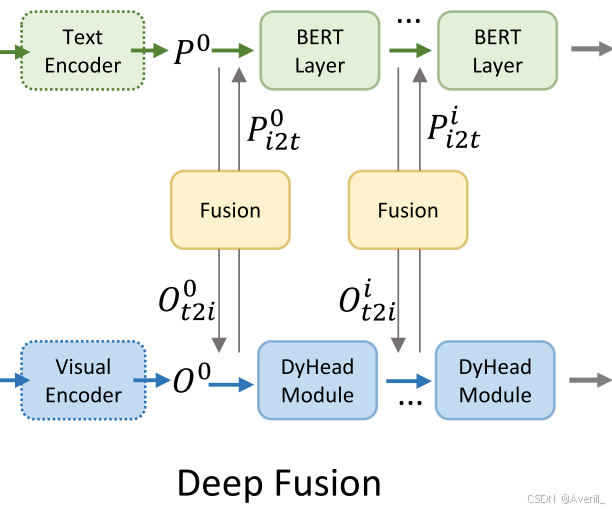
- 具体来说,GLIP采用DyHead作为图像编码器,BERT作为文本编码器。
- DyHead本质上是对于“尺度(scale)、空间(space)、任务(task)”三个维度分别进行自注意力机制运算。
- 深度融合编码器可以用以下公式来表示:
- 其中,X-MHA代表跨模态多头注意力模块(Multi-Head Attention Module),
代表DyHead中DyHeadModule的个数,BERTLayer是额外添加在预训练BERT模型之上的层,
是视觉backbone提取的图像特征,
是语言backbone提取的文本特征。
- X-MHA是用于跨模态信息融合的关键模块,它的公式如下所示:
- 深度融合有两个优点:
- 提升了phrase grounding的性能。
- 使得图像特征的学习与文本特征产生关联,从而让文本prompt可以影响到检测模型的预测。
通过大量语义丰富数据训练的预训练模型
- GLIP训练采用的数据包含了超过2000个类别,并且是边界框+phrase grounding的标注。
- 本文通过实验证明,GLIP可以轻松地扩展到非常稀有的类别上,使用80万gold grounding数据训练的模型,就可以在另外200万稀有类别数据测试上获得很大的提升。
- GLIP提供了一种快速丰富训练数据集的方式:
- 用gold grounding训练一个teacher模型。
- 用teacher模型在新数据上进行预测,获取到检测框和对应的名词,也就是伪标注。
- 用一个student模型同时在gold grounding数据集和伪标注数据集上训练。

- 为什么student模型可能会优于teacher模型:起初teacher模型可能并不知道类似于上图中疫苗(vaccine)和绿宝石(turquoise)的具体概念,但是可以根据文字的上下文去猜测,例如根据“a small vial(一小瓶)”,GLIP定位到了这个小瓶子,然后vaccine就可以跟这个小瓶子关联起来了,这种情况被称为“训练猜测(educated guess)”;而在训练sutdent模型时,这些“educated guess”就变成了一个强监督信息,从而让模型真正认识疫苗(vaccine)。
研究结论
- 本文设计了多个版本的GLIP用于对比试验:
- GLIP-T(A):基于SoTA模型Dynamic Head,将其中的分类损失替换为GLIP的对齐损失,预训练数据为Objects365(66万人工标注数据)。
- GLIP-T(B):在GLIP-T(A)的基础上加入深度融合。
- GLIP-T(C):在预训练数据中加入GoldG(80万人工标注数据)。
- GLIP-T:加入更多数据:Cap4M(400万网上爬取的数据)。
- GLIP-L:基于Swin-Large,并采用更大量的数据集,包含:FourODs(266万)、Objects365、OpenImages、Visual Genome、ImageNetBoxes、GoldG、CC12M+SBU。
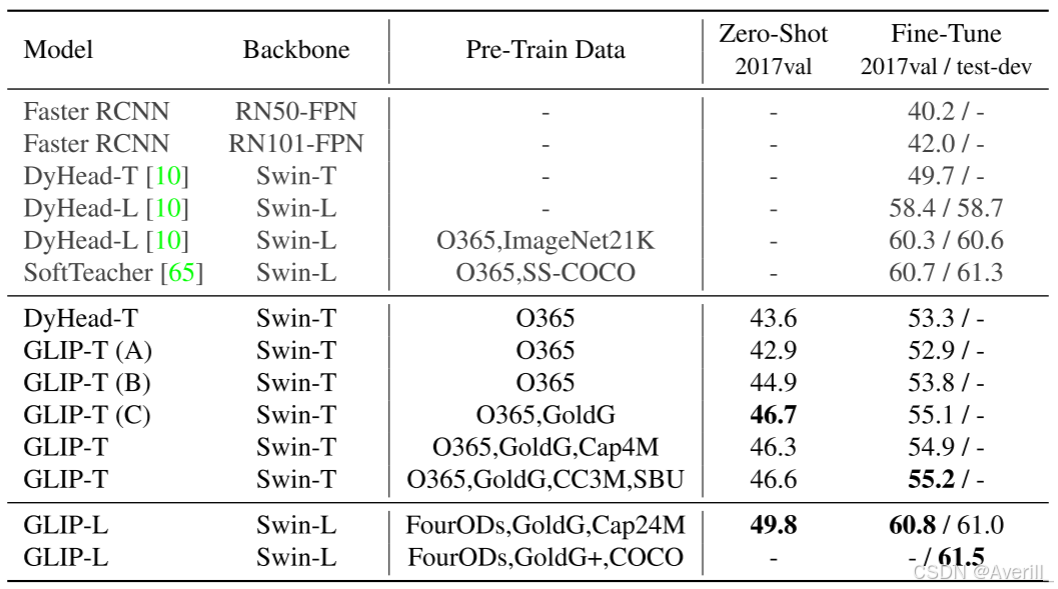
- 在COCO数据集上的表现如下图所示,可以看到zero-shot的GLIP模型就已经超越了Faster RCNN的表现了,而在经过微调之后,GLIP-L的mAP达到了略超过DyHead的水平。
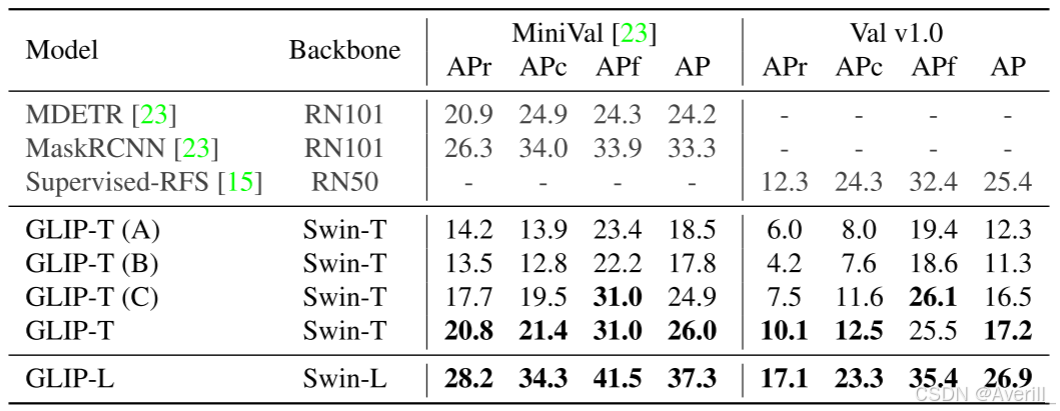
- 在LVIS数据集上的表现(下图):GLIP zero-shot的表现超过了监督训练的MDETR模型。
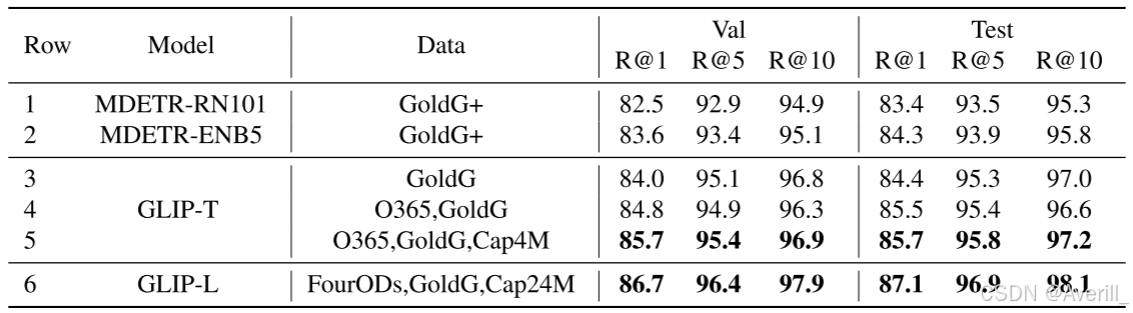
- 在Flickr30K数据集上的表现达到了SoTA水平(下图)。
启发与思考
- 本章介绍的CLIP、ViLT和ViLD都仅使用了晚期融合,而GLIP使用了深度融合,即基于自注意力机制的融合+晚期融合,这是一种加强融合端的方法。
- 伪标签是一种实用的扩大数据集的方法。
- 对现有模型改进的方向不仅有提高准确度和模型轻量化,还有拓展下游任务等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









