







Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置
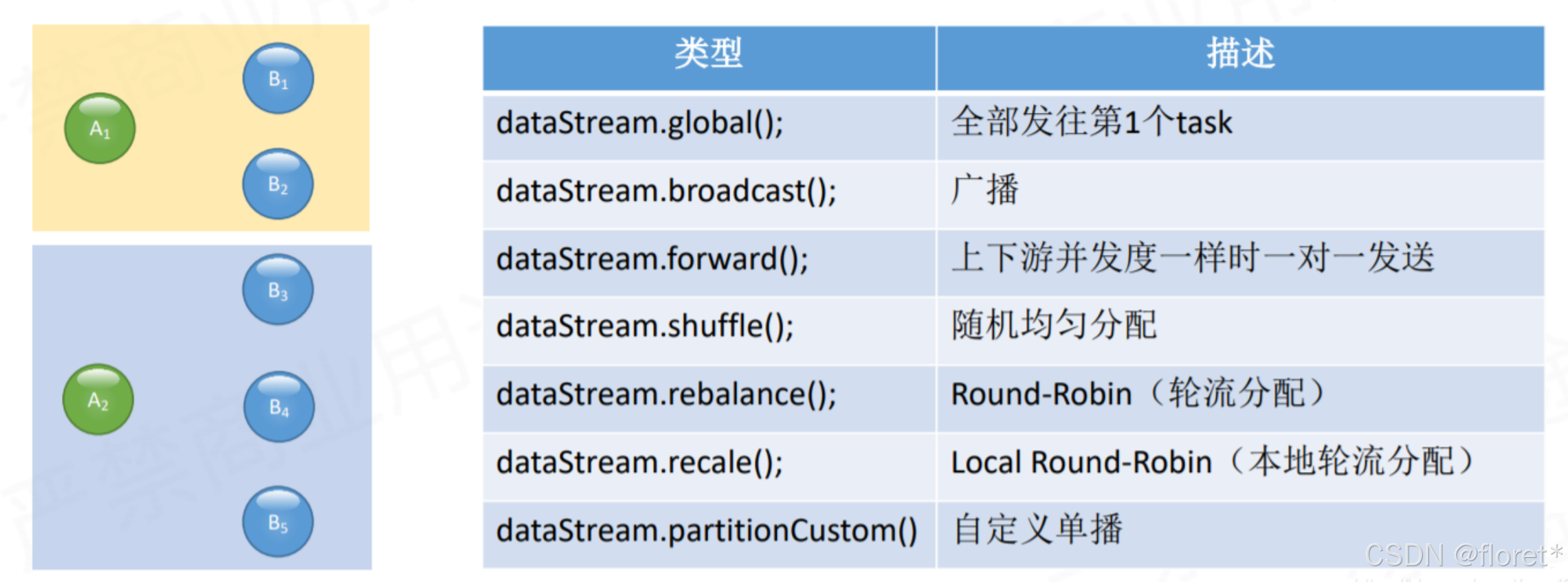
1) Global Partitioner
该分区器会将所有的数据都发送到下游的某个算子实例(subtask id = 0)
2)Shuffle Partitioner
根据均匀分布随机划分元素
3) Broadcast Partitioner
发送到下游所有的算子实例,是将上游的所有数据,都给下游的每一个分区一份。
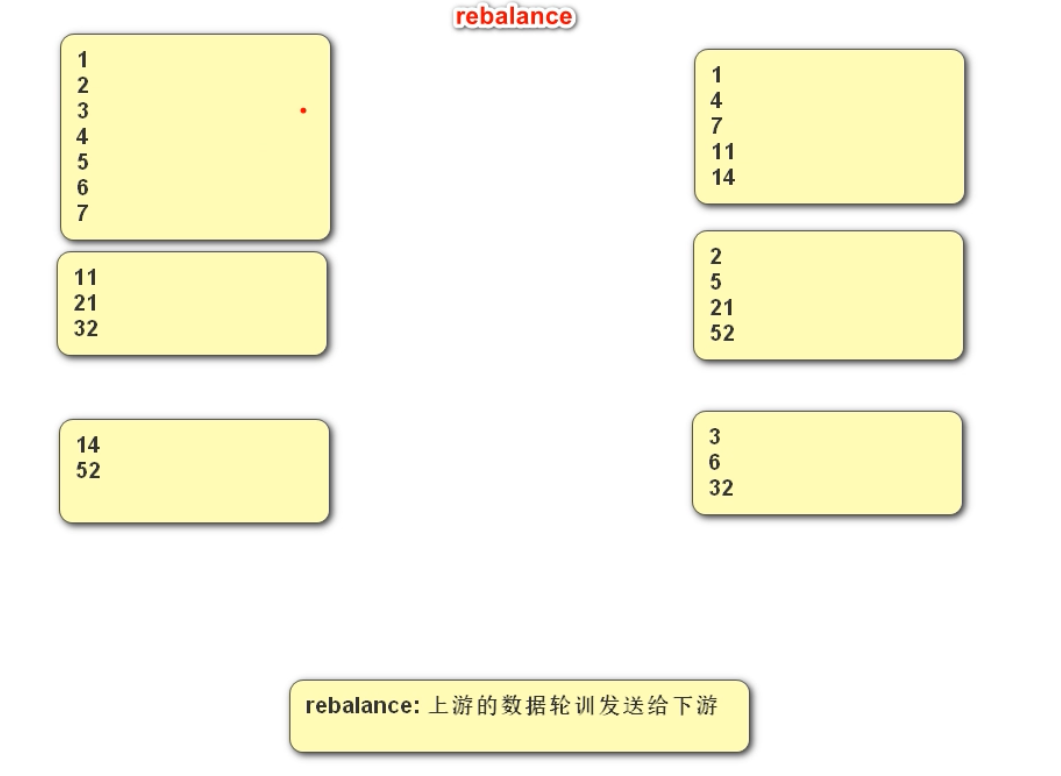
4)Rebalance Partitioner --重分区 【重点】
通过循环的方式依次发送到下游的task
数据倾斜: 某一个分区数据量过大。
解决方案:可以对分区数据进行重分区rebalance。
通过人为制造数据不平衡,然后通过方法让其平衡,可以通过观察每一个分区的总数来观察。
随堂代码,熟悉各个分区器的使用方法:
package com.bigdata.day03;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @基本功能:
* @program:FlinkDemo
* @author: zxx
* @create:2023-11-21 14:11:59
**/
public class PartitionerDemo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 手动设置五个分区
env.setParallelism(5);
//2. source-加载数据
DataStreamSource<Long> dataStream = env.fromSequence(0, 100);
// 认为制造数据不均衡的情况
/**
* // [1,20],[21,40],[41,60],[61,80],[81,100]
* // -->[11,20],[21,40],[41,60],[61,80],[81,100]
* // 这个是由数据源所决定的,假如是一个socket ,就不会出现这个情况了。
*/
SingleOutputStreamOperator<Long> filterStream = dataStream.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return aLong > 10;
}
});
filterStream.print("前");
// 在一个流对象后面,调用rebalance ,会将流中的数据进行再平衡,得到一个新的流
// DataStream<Long> rebalanceStream = filterStream.rebalance();
// global 是将数据全部发送给一个分区
// DataStream<Long> rebalanceStream = filterStream.global();
// 将上游数据,随机发送给下游的分区
// DataStream<Long> rebalanceStream = filterStream.shuffle();
// 前面一个分区的数据,发送给后面一个分区
//DataStream<Long> rebalanceStream = filterStream.forward();
// 将前面分区的数据发送给后面的所有分区
DataStream<Long> rebalanceStream = filterStream.broadcast();
rebalanceStream.print("后");
//3. transformation-数据处理转换
//4. sink-数据输出
//5. execute-执行
env.execute();
}
}如何查看每一个分区的数据量呢?
package com.bigdata.transforma;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @基本功能:
* @program:FlinkDemo
* @author: zxx
* @create:2024-11-22 11:52:43
**/
public class _10_物理分区策略 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(5);
DataStreamSource<Long> streamSource = env.fromSequence(1, 100000);
//DataStream<Long> ds = streamSource.global();
// 此时打印,数据都在1 分区
//ds.print();
// shuffle 将数据随机均匀分布在不同的 分区上,或者任务上。
//DataStream<Long> shuffle = streamSource.shuffle();
// broadcast 将上游的每一个分区的数据发送给下有的所有分区
//DataStream<Long> broadcast = streamSource.broadcast();
// 将数据均匀的分发给下游的分区,如果遇到数据倾斜,直接就解决了
//DataStream<Long> rebalance = streamSource.rebalance();
// 上有的数据对应下游的数据,分区数必须是 1:1才行
DataStream<Long> forward = streamSource.forward();
// streamSource.rescale();
//shuffle.print();
// 虽然打印了,但是我不知道某个分区具体有多少数据,所以我想看到某个分区,以及这个分区的数据量
forward.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {
@Override
public Tuple2<Long, Integer> map(Long value) throws Exception {
long partition = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(partition,1);
}
}).keyBy(0).sum(1).print();
//5. execute-执行
env.execute();
}
}Rebalance底层逻辑:
5) Forward Partitioner
发送到下游对应的第一个task,保证上下游算子并行度一致,即上有算子与下游算子是1:1的关系
在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用RebalancePartitioner,对于ForwardPartitioner,必须保证上下游算子并行度一致,否则会抛出异常。
6)Custom(自定义) Partitioning
关于分区,很多技术都有分区:
1、hadoop 有分区
2、kafka 有分区
3、spark 有分区
4、hive 有分区
使用用户定义的Partitioner 为每个元素选择目标任务
以下代码是这几种情况的代码演示:
package com.bigdata.transforma;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @基本功能:
* @program:FlinkDemo
* @author: zxx
* @create:2024-11-22 14:15:50
**/
class CustomPartitioner implements Partitioner<Long>{
@Override
public int partition(Long key, int numPartitions) {
System.out.println(numPartitions);
if(key <10000){
return 0;
}
return 1;
}
}
public class _11_自定义分区规则 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(2);
DataStreamSource<Long> streamSource = env.fromSequence(1, 15000);
DataStream<Long> dataStream = streamSource.partitionCustom(new CustomPartitioner(), new KeySelector<Long, Long>() {
@Override
public Long getKey(Long value) throws Exception {
return value;
}
});
//dataStream.print();
// 每一个分区的数据量有多少
dataStream.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {
@Override
public Tuple2<Long, Integer> map(Long value) throws Exception {
long partition = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(partition,1);
}
}).keyBy(0).sum(1).print("前:");
DataStream<Long> rebalance = dataStream.rebalance();
rebalance.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {
@Override
public Tuple2<Long, Integer> map(Long value) throws Exception {
long partition = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(partition,1);
}
}).keyBy(0).sum(1).print("后:");
//5. execute-执行
env.execute();
}
}


















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









