







 本文详细介绍了web自动化测试的重要性和选择selenium的原因,包括环境部署、驱动原理,并深入讲解了selenium的基础语法、操作、等待技术以及Junit的注解、断言和测试套件的使用。通过实例演示了如何进行自动化测试,包括元素定位、操作、窗口切换、导航、弹窗处理、文件上传等,并探讨了测试用例的执行顺序和参数化测试的方法。
本文详细介绍了web自动化测试的重要性和选择selenium的原因,包括环境部署、驱动原理,并深入讲解了selenium的基础语法、操作、等待技术以及Junit的注解、断言和测试套件的使用。通过实例演示了如何进行自动化测试,包括元素定位、操作、窗口切换、导航、弹窗处理、文件上传等,并探讨了测试用例的执行顺序和参数化测试的方法。
目录
(1)assertEquals(expect,actual)和assertNotEquals(expect,actual)
(2)assertTrue(expect和actual比较相等)和assertFalse(expect和actual比较不相等)
(3)assertNull()和assertNotNull()
1.单参数:@ValueSource(类型={参数1,参数2})
1.什么是自动化以及为什么要进行自动化
自动化测试能代替一部分的手工测试
自动化测试能够提高测试效率----->随着功能的增加、版本越来越多,版本回归的压力也就越来越大。所以仅通过人工测试来回归所有的版本是不现实的,因此需要借助自动化来进行回归。
2.为什么选择selenium作为web自动化工具
(1)开源免费(学生党友好)
(2)支持多浏览器(如Chrome、Firefox、IE、edge、Safari...)
(3)支持多系统(如Linux、Windows、MacOS)
(4)支持多语言(如java、python)
(5)selenium包底层有很多可使用的API
3.selenium环境部署
java版本最低要求8+Chrome浏览器+Chromedriver(谷歌浏览器驱动)+selenium工具包
具体操作看这篇: java+selenium环境搭建_在上山的mei的博客-优快云博客
4.什么是驱动以及驱动的原理
为什么要说驱动的事,因为你看上面selenium环境搭建的时候是不是有一个谷歌浏览器驱动,因此我这里就来细说一下这个驱动他是干嘛的。
- 什么是驱动?
生活当中我们开车,汽车有驱动(两轮驱动、四轮驱动),它可以让汽车跑起来。
我们使用的计算机里也有驱动程序,它可以驱动计算机和设备工作起来。我们打开浏览器也需要驱动,平常我们手动的打开浏览器,这种就是人工手动的驱动打开浏览器;而如果我们不选择人工手动的驱动打开浏览器,而是使用自动化,由于代码不能直接打开浏览器,因此就需要借助驱动程序来协助打开浏览器。(这也就是为什么我们在进行自动化的时候需要浏览器驱动,而我这里选择的是在谷歌浏览器上操作,所以需要使用谷歌浏览器驱动)
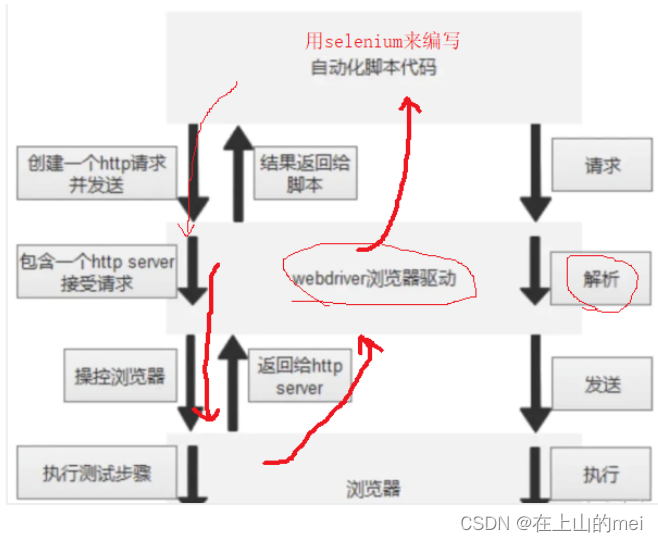
- 驱动的原理——selenium、驱动、浏览器三者之间的关系
第一步:用selenium来编写自动化脚本代码,然后代码创建一个http请求并发送这个请求给webdriver浏览器驱动(webdriver浏览器驱动就是一个服务器)。
第二步:webdriver浏览器驱动接受这个请求,解析这个请求。第三步:webdriver浏览器驱动发送指令操控浏览器,浏览器执行测试步骤。
第四步:浏览器把结果返回给webdriver浏览器驱动,webdriver浏览器驱动再把结果返回给脚本。
上面四步就是一次自动化测试中selenium、驱动、浏览器三者之间的一个运作原理
用一句话总结上面自动化测试的原理就是:代码可以驱使驱动来打开浏览器
5.selenium的基础语法和操作
- 写在前面的话
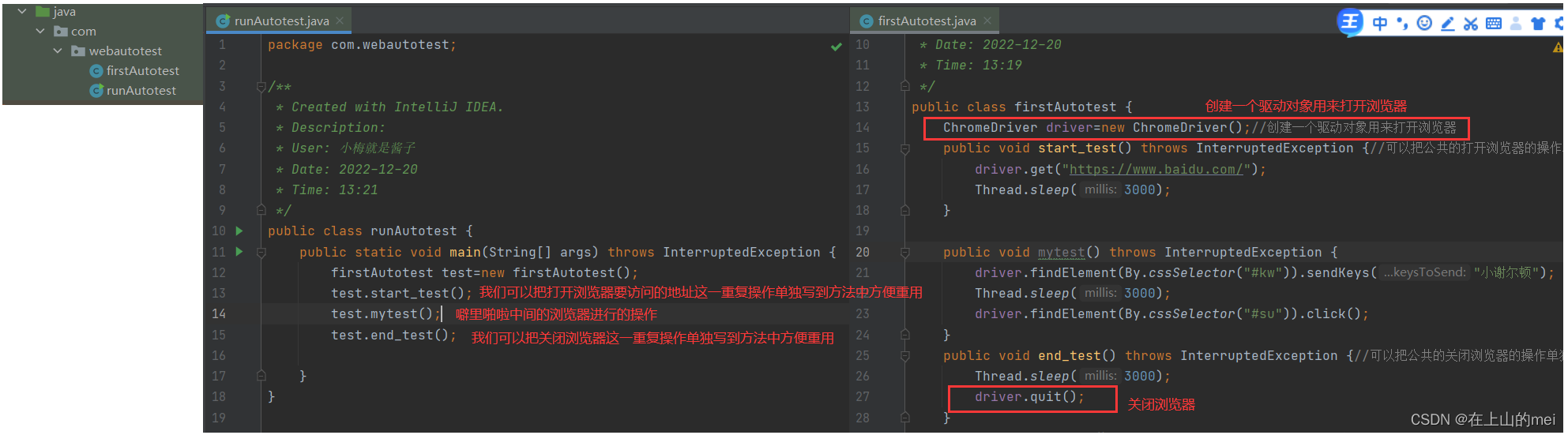
需要知道的是,一次自动化测试的周期是这样的:
创建驱动对象打开浏览器---->噼里啪啦进行浏览器中的操作--->关闭浏览器
(下面写一个简单的例子用来说明最基本但是必要的这三部分代码格式)
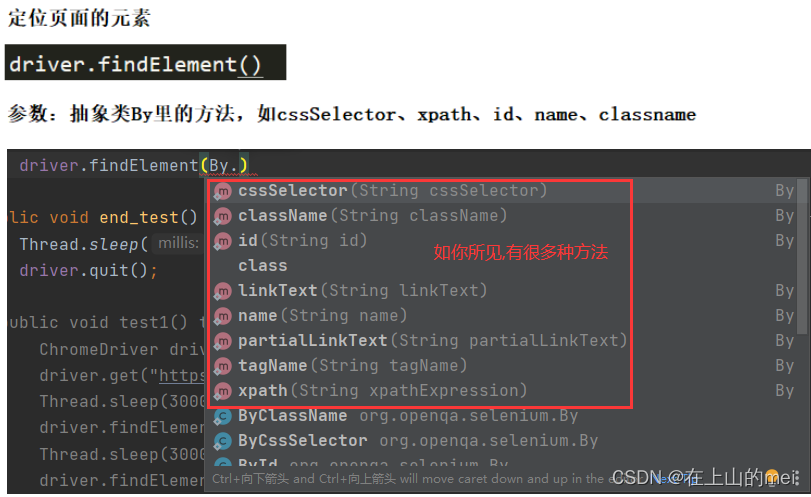
5.1定位元素
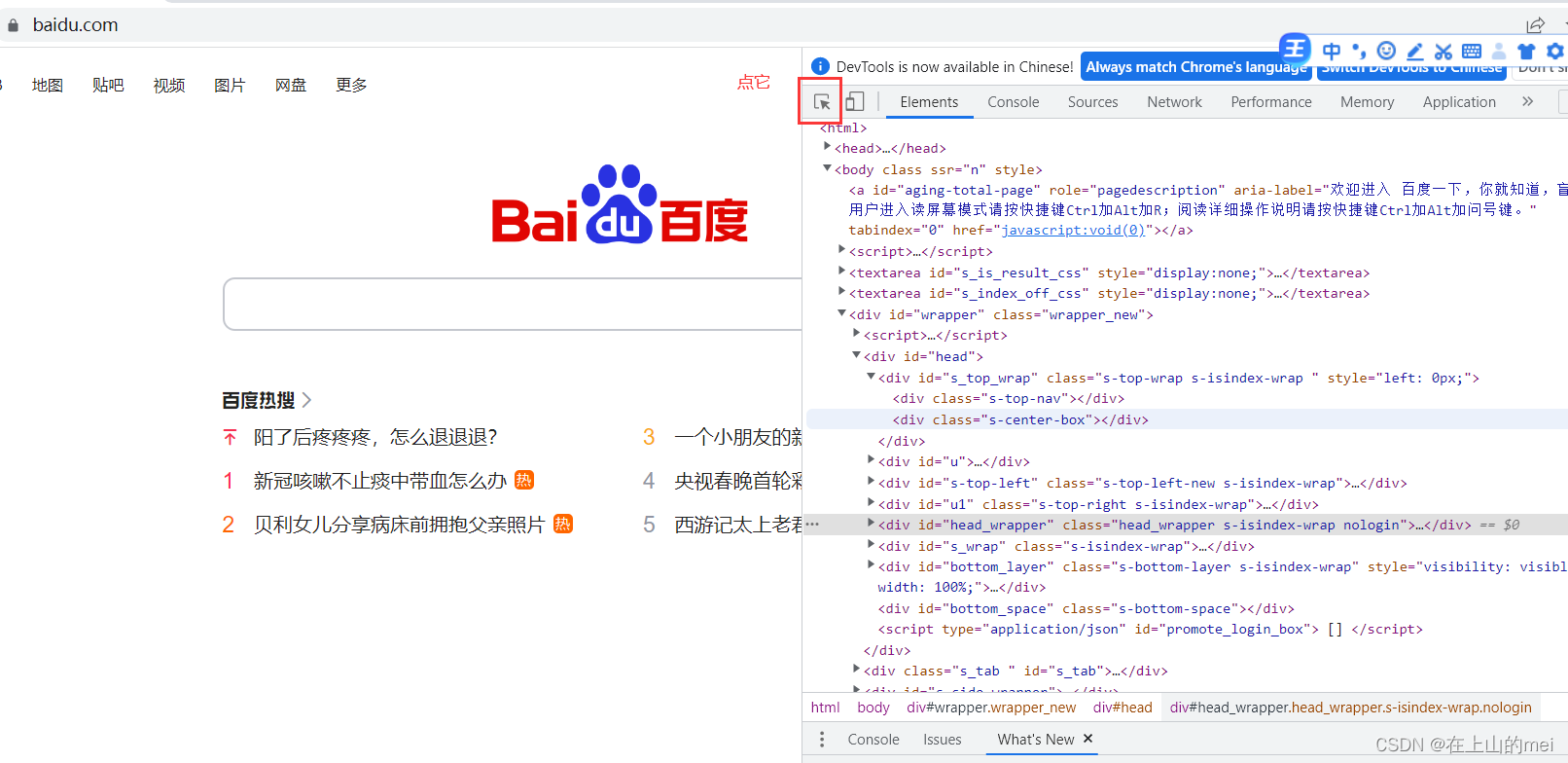
怎么得知页面元素的这些信息呢?---使用开发者工具(检查)
打开浏览器--->检查--->点下图这个按钮,然后点页面中的想要了解的位置,就能在右侧这个检查中看到它对应的信息了(比如上面方法中的id、className、tagName...)
这里关于定位元素我就介绍两个比较常用的方法吧,一个是cssSelector,另一个是xpath
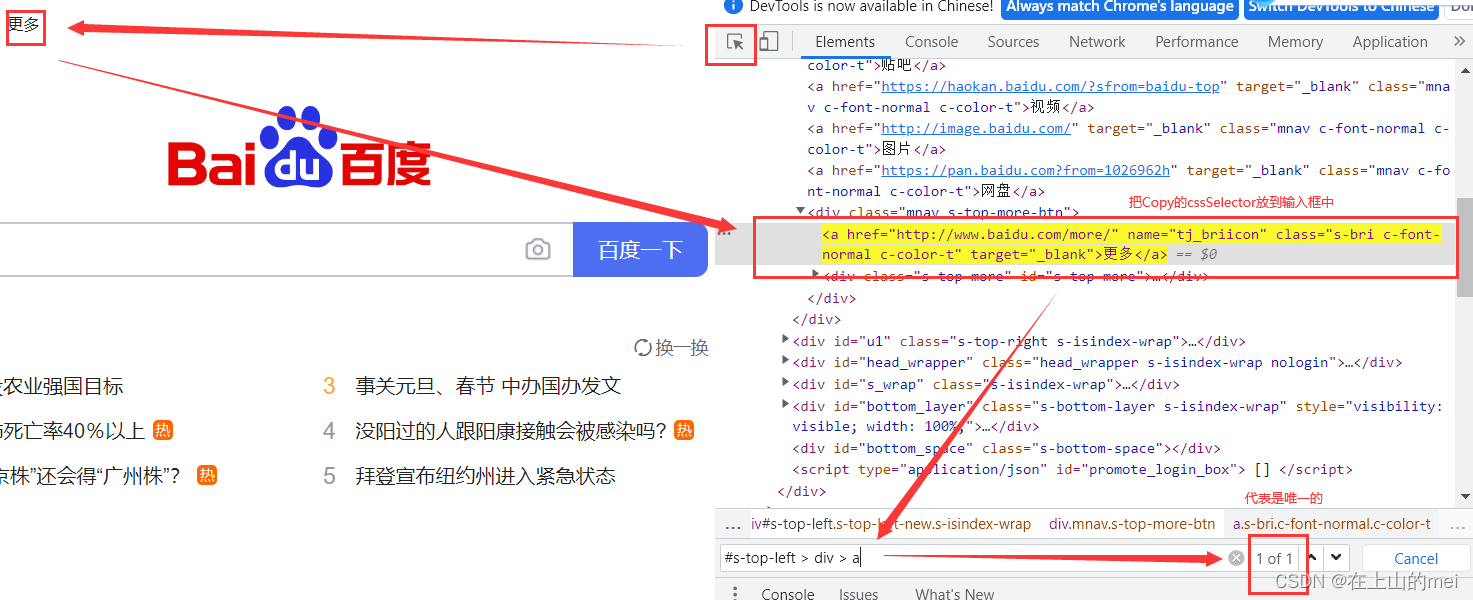
比如我想要定位百度一下这个网址中的输入框:
注意:元素的定位一定要唯一!!!!
怎么确定其唯一呢?----->右键检查,然后Ctrl+F会出现一个输入框
复制要检查的元素到输入框,如果显示 1 of 1,则表示属性在当前界面是唯一的,否则不是唯一的
5.2元素的操作
定位到元素之后,当然就要进一步对元素进行操作啦~

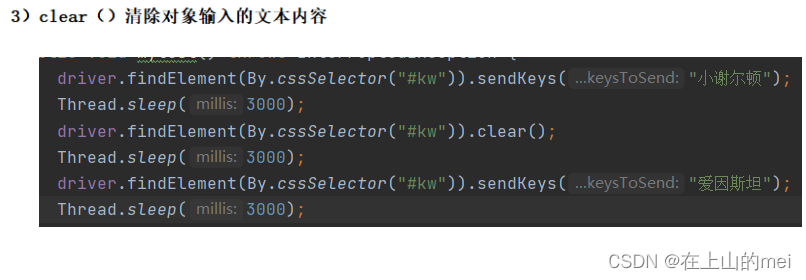
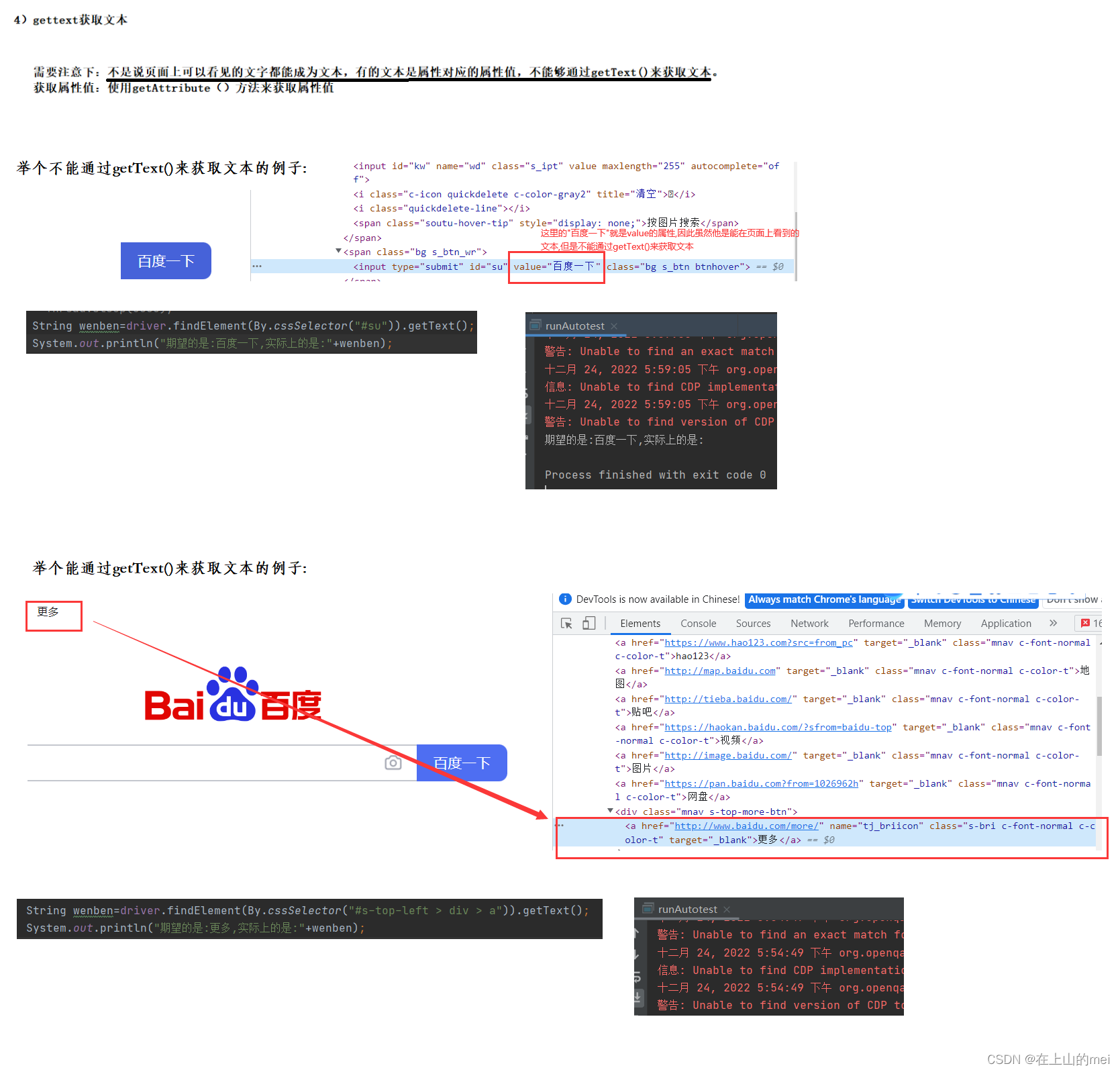
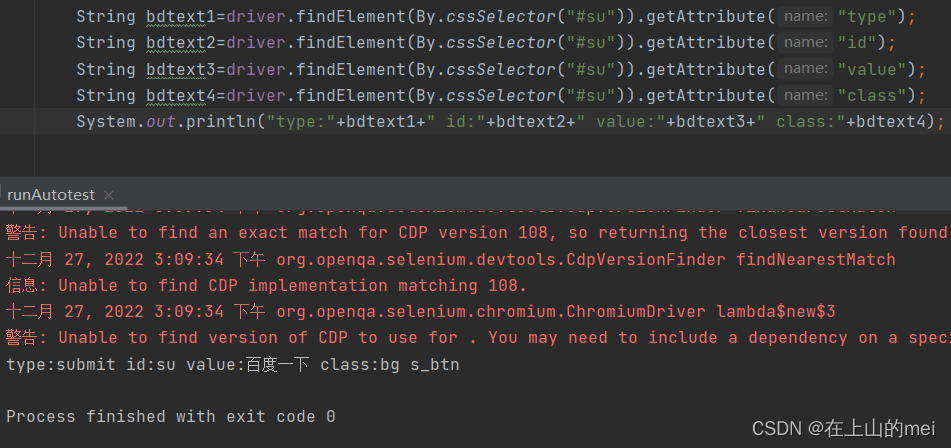
这里拓展说明一下:虽然像上面“不能通过getText()获取文本”的例子中的按钮里的“百度一下”不能通过getText()来获取,但是如果我们要获取到他,我们需要用到getAttribute("value")。原因是这个“百度一下”是value这个属性中的值。
5.3等待
- 为什么会有等待?
因为代码的执行速度比较快,而前端页面渲染的速度相对较慢一点,这就可能导致——代码已经执行到下一步了,页面还没有渲染出来,因此就找不到页面上本来有但是因为没有渲染出来而定位不到的元素。
- 等待分类
等待分为:强制等待、隐式等待、显示等待
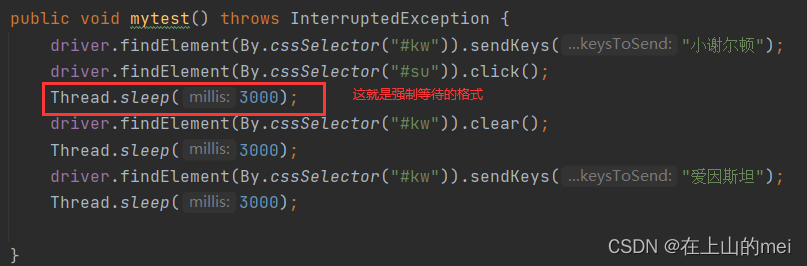
(1)强制等待:让程序暂停一会儿,等待指定的时间之后继续执行下一步
优点:语法简单,适合调试的时候用
缺点:需要等待固定的时间,造成测试时间的大量消耗,大大降低了自动化的测试效率
关于这个缺点的说明我举一个例子你就知道了——1个测试用例使用强制等待,平均时间是3-5s,以5s为例,加入web自动化有100个,那么强制等待的时间就是100*5=500s=8min20s,这还是没加自动化执行的时间呢,如果加上可能就超过15min甚至更久!
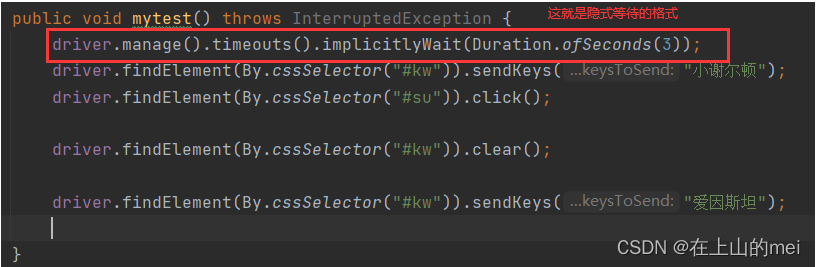
(2)隐式等待:在规定的时间范围内,轮询等待元素出现之后就立即结束,如果在规定的时间内元素仍然没有出现,则会抛出一个NoSuchElementException异常
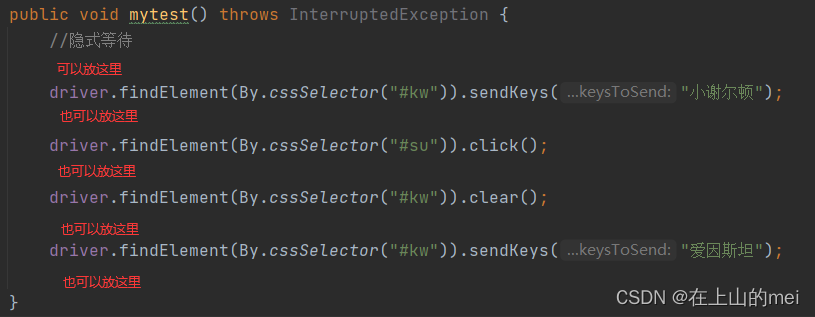
隐式等待特点:作用在webdriver整个生命周期,即只要没有走到driver.quit,隐式等待就一直存在。所以像上面那个例子,你把隐式等待放在哪里都可以,如下图所示。
优点:节省了大量的等待时间,元素展示之后就可以直接执行下一步,执行效率高
缺点:需要等待所有的元素都展现完才会执行下一步,仍然有额外的时间上的浪费
(3)显示等待:可以针对某一个元素进行测试
首先创建一个显示等待的对象(我这里举例为res),这个对象初始化的时候要传入两个参数,第一个是驱动对象(我这里为driver),第二个是强制等待的时间(我这里设为10),在这个时间之内会轮询的查找元素是否存在。等待什么时候为止呢?等待括号里的条件满足为止,如果条件在指定时间内没有满足,就抛出异常。括号里的内容:ExpectedConditions类中的presenceOfElementLocated方法(查看页面是否存在对应的元素),通过定位元素来查看当前要查找的元素是都在页面存在,如果存在就结束.如果不存在就会报异常。
下面这个例子我是针对页面中这一元素进行的等待:
或者用ExpectedConditions类中的textToBe方法(检查元素对应的文本是否符合预期)也可以
注意哈,你有可能照着我这个例子打,然后运行之后发现报错,莫慌莫慌,一般你再重新运行一两遍就好了。原因就是我选的这个元素啊它有时候会小小的变一下他的cssSelector,比如从#32变到#31,所以你代码里cssSelector复制的是#32的,但是可能某次运行的时候,这个元素它变成了在页面上的#31位置,所以找不到是正常滴。之所以说让你再运行一遍,是因为下次这个元素可能就又回到#32位置了哈哈哈哈,你懂我意思么~
对于这个格式中的内容再补充一点解释:
1. ExpectedConditions 是selenium里的一个类,类里提供了很多方法用来测试。presenceOfElementLocated就是这个类中的一个方法,用来查看页面是否存在对应的元素。
textToBe方法也是这个类中的方法,用来检查元素对应的文本是否符合预期,第一个参数是实际上的,第二个参数是期待的
优点:针对某一个元素进行等待,极大降低了自动化整体的等待时间
缺点:写法更为复杂
- 代码里面可以同时使用显性等






 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









