






赛题介绍:
新能源发电功率预测是构建新型电力系统的核心技术之一,其价值不仅在于技术层面,更关乎能源安全、经济效率与环境可持续性。本次大赛提供覆盖多个场景的新能源场站历史发电功率数据和对应时段多类别气象预测数据,预测次日零时起到未来24小时逐15分钟新能源场站发电功率。
本赛道与中国南方电网电力调度控制中心(简称南网总调)合作,同时南网总调也于 2023 年启动了覆盖南网区域的新能源功率预测培育计划。该计划旨在提升南方区域新能源预测水平,构建灵活、开放的新能源功率预测新生态。
训练模型代码:
导入库
from netCDF4 import Dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error, mean_absolute_error
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor代码模块分析
netCDF4.Dataset:用于读取和处理 NetCDF 格式的气象数据文件。
numpy:提供高效的数值计算功能,用于处理数组和矩阵运算。
pandas:用于数据处理和分析,如数据读取、清洗、转换和存储等操作。
matplotlib.pyplot:用于数据可视化,可绘制各种图表展示数据特征和模型结果。
sklearn.model_selection.KFold:用于实现 K 折交叉验证,将数据集划分为训练集和验证集,评估模型的泛化能力。
sklearn.metrics:提供多种评估指标,这里使用mean_squared_error和mean_absolute_error来评估模型的预测误差。
lightgbm、xgboost、catboost:都是梯度提升框架,用于构建和训练回归模型,预测发电功率。
数据探索
数据探索是数据分析的起始关键环节。它通过运用描述性统计方法(如计算方差、均值等)与可视化技术(如绘制直方图、散点图等 ),全方位审视原始数据。能直观呈现数据的分布特征,还可挖掘变量间潜在关联,像正相关或负相关关系。这有助于快速洞悉数据全貌,敏锐察觉数据中的异常值、缺失值等状况,为后续精准的数据清洗与特征工程等工作明确方向。
读取所有数据
nc_path = "data/初赛训练集/nwp_data_train/1/NWP_1/20240101.nc"
dataset = Dataset(nc_path, mode='r')
dataset.variables.keys()
channel = dataset.variables["channel"][:]
data = dataset.variables["data"][:]
data.shape
(1, 24, 8, 11, 11)
对日期进行处理
# 获取2024年日期
date_range = pd.date_range(start='2024-01-01', end='2024-12-30')
# 将%Y-%m-%d格式转为%Y%m%d
date = [date.strftime('%Y%m%d') for date in date_range]使用pandas的date_range函数生成从 2024 年 1 月 1 日到 12 月 30 日的日期序列。
通过列表推导式将日期格式从%Y-%m-%d转换为%Y%m%d。
定义读取数据函数
观测上步代码结果可知气象数据中新能源场站每个小时的数据维度为 2 (11x11),但构建模型对于单个时间点的单个特征只需要一个 标量 即可,因此我们把 11x11 个格点的数据取均值,从而将二维数据转为单一的标量值。
且主办方提供的气象数据时间精度为h,而发电功率精度为15min,即给我们一天的数据有24条天气数据与96(24*4)条功率数据,因此将功率数据中每四条数据只保留一条。
# 定义路径模版
train_path_template = "data/初赛训练集/nwp_data_train/1/NWP_1/{}.nc"
# 通过列表推导式获取数据 返回的列表中每个元素都是以天为单位的数据
data = [get_data(train_path_template, i) for i in date]
# 将每天的数据拼接并重设index
train = pd.concat(data, axis=0).reset_index(drop=True)
# 读取目标值
target = pd.read_csv("data/初赛训练集/fact_data/1_normalization_train.csv")
target = target[96:]
# 功率数据中每四条数据去掉三条
target = target[target['时间'].str.endswith('00:00')]
target = target.reset_index(drop=True)
# 将目标值合并到训练集
train["power"] = target["功率(MW)"]
train数据可视化
# 获取24小时的列表
hours = range(24)
# 定义画布
plt.figure(figsize=(20,10))
# 绘制八个特征及目标值
for i in range(9):
# 绘制3*3的图中第i+1子图
plt.subplot(3, 3, i+1)
# 横坐标为小时 纵坐标为特征or目标值
plt.plot(hours, train.iloc[:24, i])
# title为列名
plt.title(train.columns.tolist()[i])
# 展示图片
plt.show()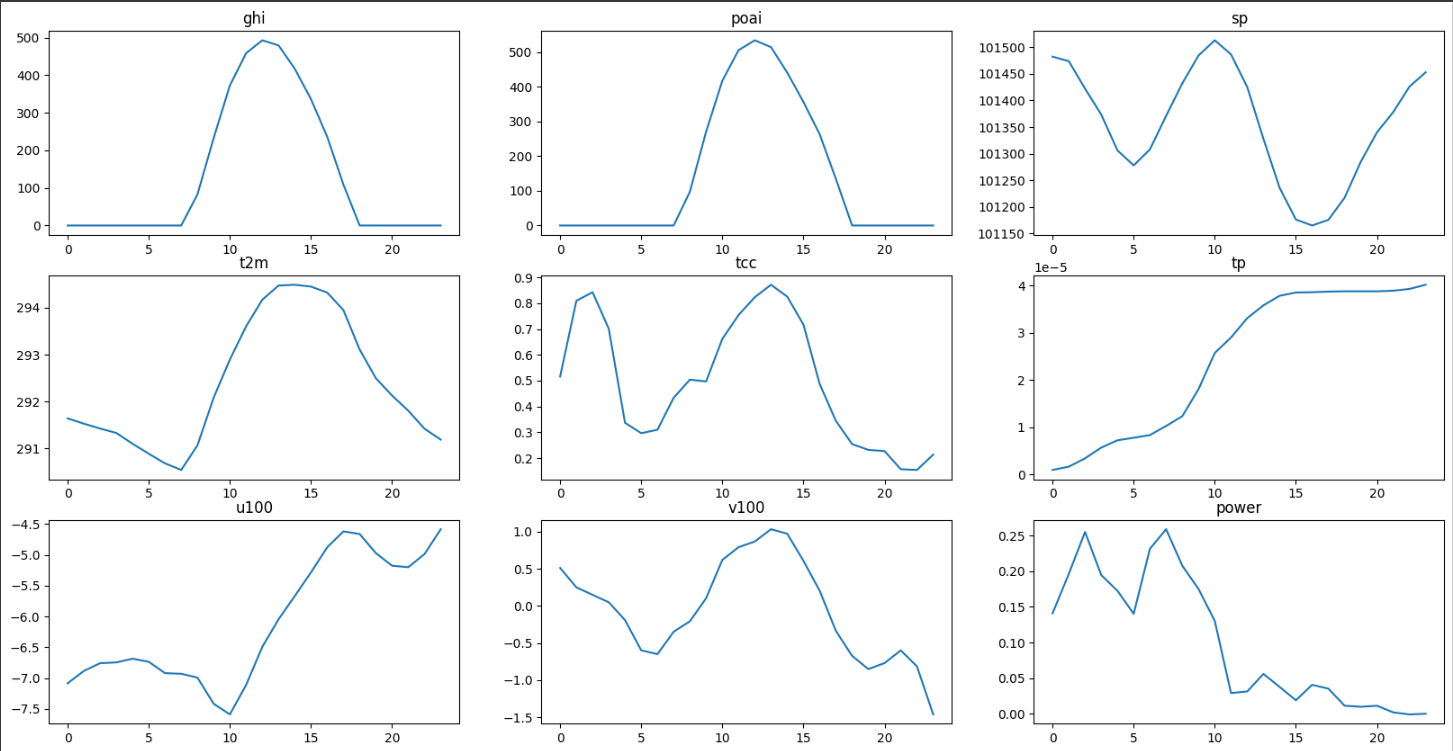
根据上图结果们可以猜测:
ghi与poai基本成正比
sp、t2m、tcc、v100趋势大体一致
power功率高的时段主要在凌晨
power在上午时段急转直下
tp是少有的单调递增的特征 且貌似与power递减区间重复
是否可以根据风在经纬度方向上的速度得到总风速?合并后是否会与power相关?
特征工程与数据清洗
特征工程是机器学习流程中的核心要点。它致力于对原始数据特征进行深度加工。通过特征提取,从复杂数据中提炼关键信息;借助特征选择,剔除冗余、不相关特征,精简数据维度;利用特征变换,如归一化、编码等操作,让特征适配模型需求;还能通过特征构造创造新特征。其目的在于塑造更优质、更具代表性的特征集,大幅提升模型对数据模式的捕捉与学习能力,显著增强模型的预测精准度与泛化性能。数据清洗是保障数据质量的必要步骤。原始数据常存在缺失值、异常值、重复值以及格式错误等诸多问题,会严重干扰模型训练效果。数据清洗就是针对性地处理这些状况,比如采用合适策略填补缺失值,识别并修正或剔除异常值,清理重复记录,规范数据格式。经过清洗,数据得以变得完整、准确、一致,为后续模型训练筑牢根基,确保模型能基于高质量数据学习,提升模型的可靠性与稳定性。
# 构建特征
def feature_combine(df):
df_copy = df.copy()
# 经纬度两个方向的风速进行向量计算 获取实际风速
df_copy["wind_speed"] = np.sqrt(df_copy['u100'] ** 2 + df_copy['v100'] ** 2)
# 添加小时特征 捕捉数据的时间周期性
df_copy["h"] = df_copy.index % 24
# 计算ghi(水平面总辐照度)与poai(光伏面板辐照度)的比值
df_copy["ghi/poai"] = df_copy["ghi"] / (df_copy["poai"] + 0.0000001)
# 计算ghi与poai的差值
df_copy["ghi_poai"] = df_copy["ghi"] - df_copy["poai"]
# 计算总风速与sp(气压)的比值
df_copy["wind_speed/sp"] = df_copy["wind_speed"] / (df_copy["sp"] + 0.0000001)
return df_copy
train = feature_combine(train)
# 数据清洗,删除含有缺失值所在的行
train = train.dropna().reset_index(drop=True)feature_combine函数对输入的DataFrame进行特征工程:
根据u100和v100计算实际风速wind_speed,利用向量计算原理。
添加小时特征h,通过取索引的余数来捕捉数据的时间周期性。
计算ghi与poai的比值ghi/poai和差值ghi_poai,以挖掘两者之间的关系。
计算总风速与sp的比值wind_speed/sp,添加新的特征。
调用feature_combine函数对训练集进行特征处理,并将结果存储回train。使用dropna方法删除训练集中含有缺失值的行,并重置索引,确保数据的完整性。
模型的训练与验证
模型训练与验证是构建有效机器学习模型的核心流程。在训练阶段,依据选定的模型算法(如线性回归、决策树等 ),用处理好的数据对模型进行参数优化,使其学习数据中的内在规律与模式。而验证环节,则借助预留的验证集(或交叉验证方式 ),运用准确率、均方误差等评估指标,客观衡量模型的性能表现。通过不断调整模型超参数等手段,优化模型,防止过拟合或欠拟合,以获取在未知数据上具备良好泛化能力的可靠模型,满足实际应用需求。
定义模型训练与验证函数
# 定义模型训练与验证函数
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=2023):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i + 1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], \
train_y[valid_index]
if clf_name == "lgb":
# 在构建 Dataset 时指定 categorical_feature
train_matrix = clf.Dataset(trn_x, label=trn_y, categorical_feature=[])
valid_matrix = clf.Dataset(val_x, label=val_y, categorical_feature=[])
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread': 16,
'verbose': -1,
'verbose_eval': 200,
'early_stopping_rounds': 100 # 将 early_stopping_rounds 移到 params 字典中
}
model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix])
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'mae',
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.1,
'tree_method': 'hist',
'seed': 520,
'nthread': 16
}
train_matrix = clf.DMatrix(trn_x, label=trn_y)
valid_matrix = clf.DMatrix(val_x, label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'), (valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=2000, evals=watchlist, verbose_eval=200,
early_stopping_rounds=100)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type': 'Bernoulli', 'random_seed': 2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=2000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
return oof, test_predict`cv_model` 函数是一个实现 K 折交叉验证训练与验证的通用函数,适用于 LightGBM、XGBoost 和 CatBoost 三种梯度提升模型进行回归任务。
它接收模型类对象、训练数据特征矩阵、训练数据标签向量、测试数据特征矩阵、模型名称及随机种子作为参数,先将训练数据按 5 折划分,接着在每一折里依据模型名称选择对应模型训练,训练中定义好模型参数并设置早停机制,完成后用模型对验证数据和测试数据预测,将验证集预测结果存于 `oof` 数组,累加测试数据预测结果并取平均,同时计算每折验证集的平均绝对误差存入 `cv_scores` 列表,最后返回训练数据在验证集的预测结果和测试数据的预测结果。
训练与预测
读取测试集的数据并进行预处理。
对测试集的数据同样进行特征工程与数据清洗,使得测试集的数据与训练集的数据一致(只相差功率'power')。
# 获取训练集中除了power的其他列
cols = [f for f in train.columns if f not in ['power']]
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train[cols], train["power"], test, 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train[cols], train["power"], test, 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, train[cols], train["power"], test, 'cat')选择训练集中除power外的所有列作为特征,存储在cols中。
分别调用cv_model函数,使用 LightGBM、XGBoost 和 CatBoost 模型进行训练和预测,得到各自的验证集预测结果和测试集预测结果。
模型融合
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3
len(final_test)
# 将数据重复4次
final_test = [item for item in lgb_test for _ in range(4)]
len(final_test)对三个模型的测试集预测结果取平均,并将数据重复4次,得到融合后的预测结果final_test。
结果输出
读取output文件,将融合后的预测结果添加到power列,重命名列名,设置时间列为索引,删除不需要的列,最后将结果保存到多个CSV文件中。
import os
if not os.path.exists("output"):
os.makedirs("output")
output = pd.read_csv("data/output1.csv").reset_index(drop=True)
output["power"] = final_test
output.rename(columns={'Unnamed: 0': ''}, inplace=True)
output.set_index(output.iloc[:, 0], inplace=True)
output = output.drop(columns=["0", ""])
for i in range(1, 11):
output.to_csv('output/output'+ str(i) + '.csv')
比赛评分

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









