









🥇个人主页:500佰
#进程 #CPU #服务器 #性能安全
说明:本文介绍cpu使用率高的排查方法 和 进程频繁FullGC的解决方法
案例一
查找CPU使用率高的进程方法
问题
节点报CPU使用率高,需要定位是什么进程占用CPU使用率高。
CPU使用率持续较高
- 在对应节点使用 “top”命令,然后键盘输入“P”,即按照CPU使用率排序进程。
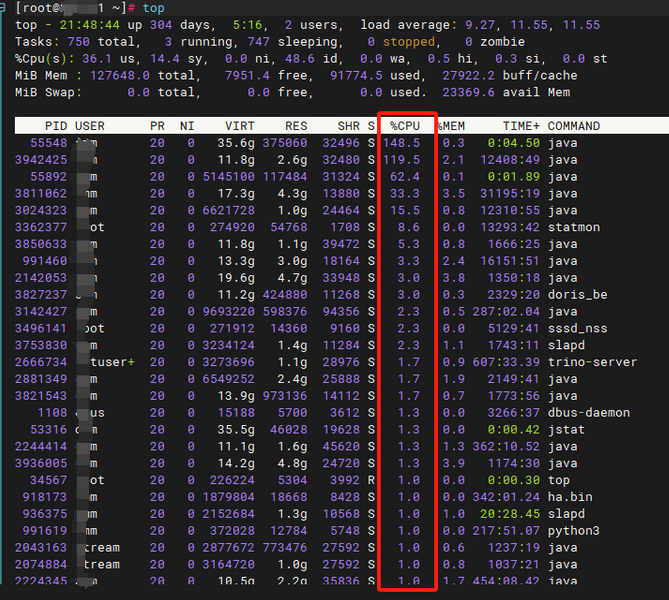
-
执行ps -ef | grep <CPU使用率高的PID>。
-
确认该进程的详细信息,确认该进程的日志。查看该组件日志,占用CPU高是否正常。
-
使用如下命令,可以打印出CPU占用率最高的十个进程的信息。
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head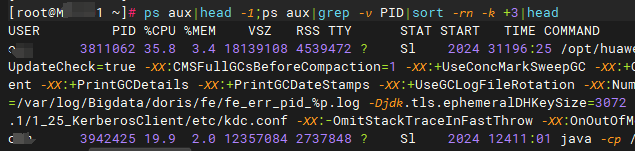
CPU使用率偶现较高
-
在操作系统日志“/var/log/osinfo/statistics/ps.txt”会记录约每分钟执行一次ps命令的结果。该信息只记录了进程的基本信息。
使用如下命令,可以打印出CPU占用率最高的十个进程的信息。
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head -
在对应节点创建如下shell文件。
check.sh ,其中logFile,是日志打印文件,delayTime 是每次执行的间隔,单位秒。
#!/usr/bin/env bash logFile=/var/log/Bigdata/checkCpuUsage.log delayTime=30 #is 30 seconds while( true ) do echo `date` >> $logFile echo "USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND " >> $logFile ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head >> $logFile sleep $delayTime echo " " >> $logFile done -
后台执行脚本。
在节点在后台执行如下shell文件:
chmod 700 /opt/check.sh nohup /opt/check.sh > /dev/null 2>/dev/null & -
查看日志。
查看“/var/log/xxx/checkCpuUsage.log”日志中,是否有打印CPU使用量高的进程的详细信息。
如果查询出的是java进程,常见因为内存配置过小导致频繁垃圾回收,引起CPU使用率高
-
停止检查脚本进程。
在节点执行ps -ef | grep check.sh | grep -v grep,找到该进程的pid,kill 即可。
案例二
存在进程频繁FullGC导致CPU偶现使用率高
案例
Spark集群控制节点CPU突然占用很高,通过top和ps命令在该控制节点进行查看发现是Spark服务的JobHistory进程占用了很高的CPU。查看到“org.apache.spark.deploy.history.HistoryServer” 即说明该进程是Spark服务的JobHistory进程。
/opt/> ps -ef | grep 14261 xxuser 45966 1 0 2016 ? 05:17:00 /opt/xx/Bigdata/jdk1.8.0_51//bin/java -cp /opt/xx/Bigdata/xx-Spark-1.3.0/spark/lib/*:/opt/xx/Bigdata/etc/1_15_JobHistory/:/opt/xx/Bigdata/xx-Spark-1.3.0/spark/lib/spark-assembly-1.3.0-hadoop2.7.1.jar:/opt/xx/Bigdata/xx-Spark-1.3.0/spark/lib/datanucleus-api-jdo-3.2.6.jar:/opt/xx/Bigdata/xx-Spark-1.3.0/spark/lib/datanucleus-rdbms-3.2.9.jar:/opt/xx/Bigdata/xx-Spark-1.3.0/spark/lib/datanucleus-core-3.2.10.jar:/opt/xx/Bigdata/etc/1_15_JobHistory/ -DIgnoreReplayReqDetect -Djava.security.krb5.conf=/opt/xx/Bigdata/etc/1_4_KerberosClient/kdc.conf -Dspark.history.ui.port=23020 -Dlog4j.configuration.watch=false -Dspark.history.kerberos.enabled=true -Dspark.history.kerberos.principal=spark/hadoop.hadoop.com@HADOOP.COM -Dspark.history.kerberos.keytab=/opt/xx/Bigdata/etc/1_15_JobHistory/spark.keytab -Dspark.cas.enabled=true -Dspark.casServer.url.prefix=https://10.xx.xx.xx:20027/cas/ -Dspark.cas.filter.className=com.xx.spark.web.filter.CASFilter -Dspark.session.maxAge=600 -Dspark.connection.maxRequest=5000 -Dspark.session.maxAge=600 -Dspark.history.fs.cleaner.enabled=true -Dspark.history.fs.cleaner.interval=86400 -Dspark.history.fs.cleaner.maxAge=1296000 -Dspark.ui.https.enabled=true -Dspark.ui.ssl.password.decode.enable=true -Dspark.ui.ssl.server.keystore.location=/opt/xx/Bigdata/xx-Spark-1.3.0/spark/child.keystore -Dspark.ui.ssl.server.keystore.type=jks -Djetty.version=x.y.z -Dspark.connection.maxRequest=5000 -Dspark.history.fs.logDirectory=hdfs://hacluster/sparkJobHistory -Xms512M -Xmx512M org.apache.spark.deploy.history.HistoryServer
原因
进程在频繁FullGC,进程GC参数配置的内存过小,需要调整。
原因分析
-
通过jstat命令监控Spark服务的JobHistory进程,发现该进程一直在频繁进行FullGC,且老生带内存占用率一直减不下去,即JVM的Heap内存不足导致频繁进行垃圾回收,照成该进程的JVM垃圾回收线程占用了大量的CPU资源。
说明:使用如下命令可以周期性查看进程的GC情况,如果FGC列在有增加,即说明存在FullGC。
jstat -gcutil 进程编号 间隔时间

-
spark服务的jobhistory进程平时没有任何用处,对Spark作业运行也没有任何影响,其唯一的作用就是提供可视化界面来进行历史任务的人工分析。
之前之所以没有发现内存不足的问题是因为一直没人用,最近几天在进行某些Spark任务的调优才开始使用该服务,所以在累积了很多历史任务信息的情况下,该进程需要消耗较大内存,当前的默认GC参数配置已经无法支撑,需要调整。
解决方法
调整JobHistory的参数spark_daemon_memory,建议调整到2G,然后在进行历史任务分析时使用jstat进行监控观察老生带内存变化。
最后
谢谢大家 欢迎留言 +关注 🥇


















 1640
1640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









