




本文是通过学习倪朋飞老师的专栏《Linux性能优化实战》--整理得出
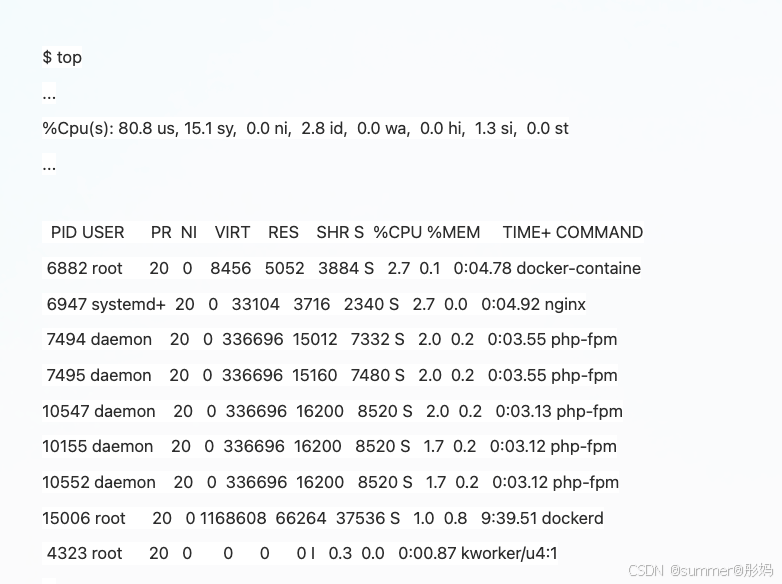
系统的整体 CPU 使用率是比较高的:用户 CPU 使用率(us)已经到了 80%,系统 CPU 为 15.1%,而空闲 CPU (id)则只有 2.8%。
排查过程
1、top 查看系统的整体使用情况,发现CPU的使用率:%Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
但是下面展示的数据,显示cpu使用率不高
2、$ pidstat 1 间隔1秒输出一组数据(按Ctrl+C结束),检测发现所有的cpu使用率也不高
3、再去检测top的每行输出,咦?Tasks 这一行看起来有点奇怪,就绪队列中居然有 6 个 Running 状态的进程(6 running),是不是有点多
这次主要看 Running(R) 状态的进程。你有没有发现, Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个 stress 进程。这几个 stress 进程就比较奇怪了
4、 pidstat -p 24344 -----pidstat 来分析这几个进程,并且使用 -p 选项指定进程的 PID
没有输出,使用其它工具交叉确认
5、$ ps aux | grep 24344 # 从所有进程中查找PID是24344的进程
还是没有输出。现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出。既然进程都没了,那性能问题应该也跟着没了吧。我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









