







#Hive常见故障 #大数据 #生产环境真实案例 #Hive #离线数据库 #整理 #经验总结
说明:此篇总结hive常见故障案例处理方案 结合自身经历 总结不易 +关注 +收藏 欢迎留言
更多Hive案例汇总方案 解决方案:请往下翻
left join右表分区条件写在where后,查询慢
问题
查询慢,右表会进行全表扫描。
原因
例如:
select t1.id
from student_p t1
left join test0617 t2
on t1.id=t2.id
where t1.pt_dt<'2022-02-xx' and t2.pt_dt<'202206xx';副表(即命令中的t2)表,where条件写在join后面,会导致先全表关联再过滤分区。虽然主表(命令中的t1)表分区条件也写在join后面,但是主表会谓词下推,先执行分区过滤再进行join。
打印执行计划可以看到SQL扫描了副表的不在条件内的分区:
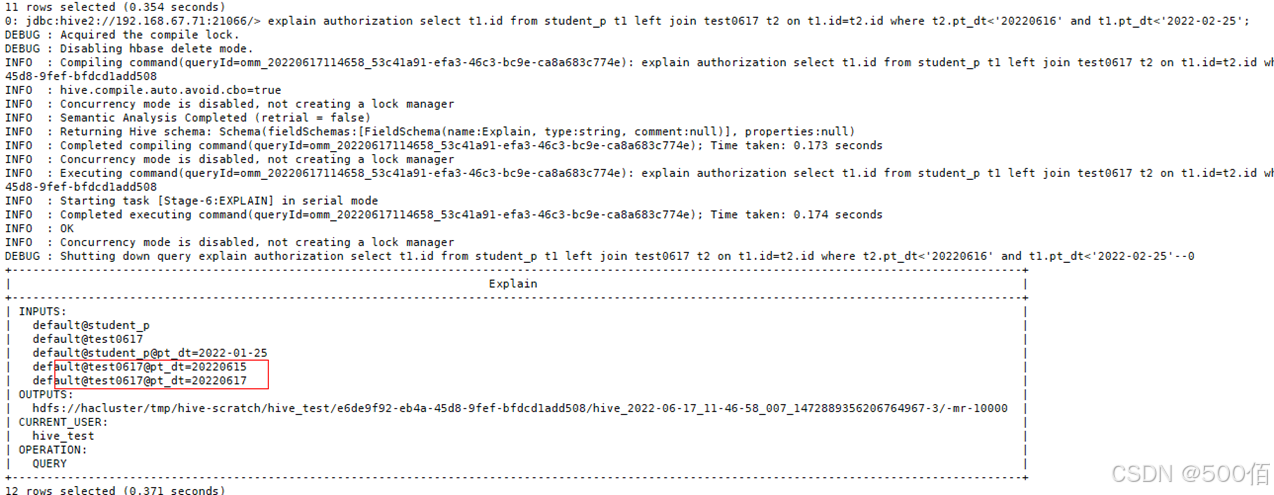
解决方法
将副表的分区过滤条件写在join中,上述例子可修改为:
select t1.id
from student_p t1
left join test0617 t2
on t1.id=t2.id and t2.pt_dt<'202206xx'
where t1.pt_dt<'2022-02-xx';打印执行计划可以看到,06xx分区不再扫描,只扫描指定的分区:
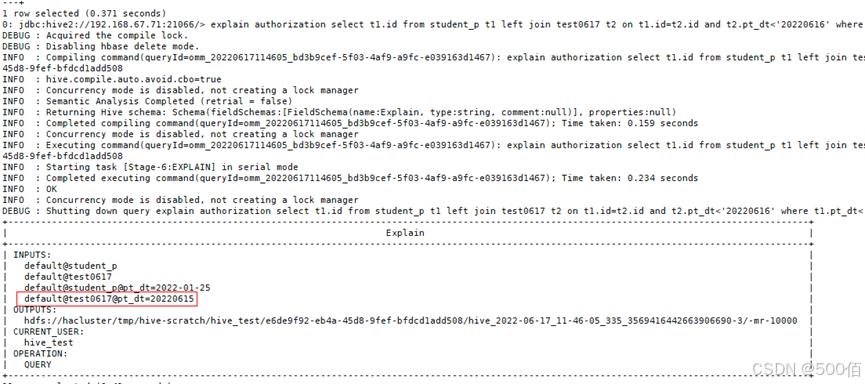
更多Hive案例汇总方案 (点击跳转) :
Hive常见故障多案例维护宝典 --项目总结(宝典一)
Hive常见故障多案例维护宝典 --项目总结(宝典二)
目录内容如下:
架构概述
【1】参数及配置类常见故障
【2】任务运行类常见故障
【3】SQL使用类常见故障
最后
谢谢大家 @500佰


















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









