




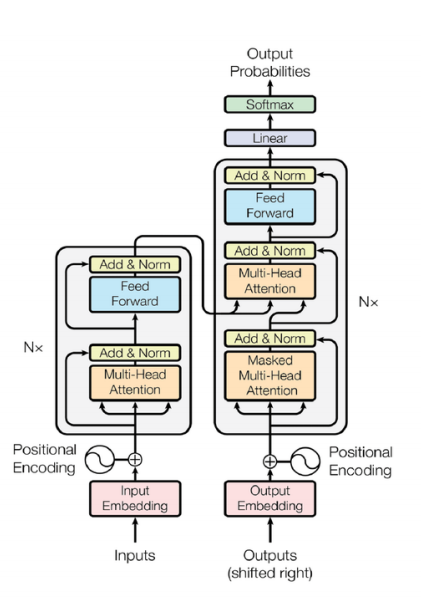
编码器部分
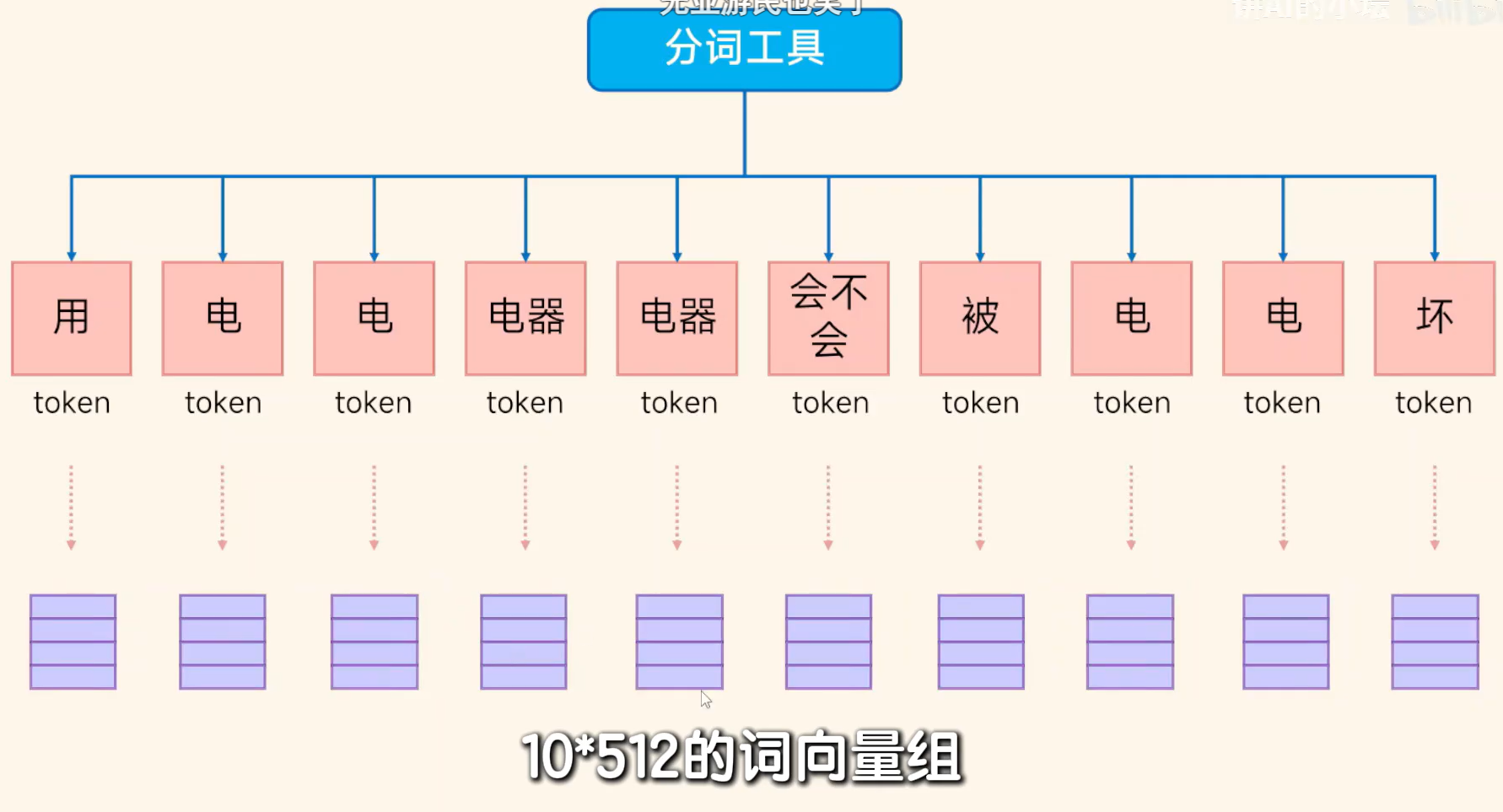
Step1 分词成x个Token
Step2 对每个Token向量化,并进行位置编码。组成10*512的向量。
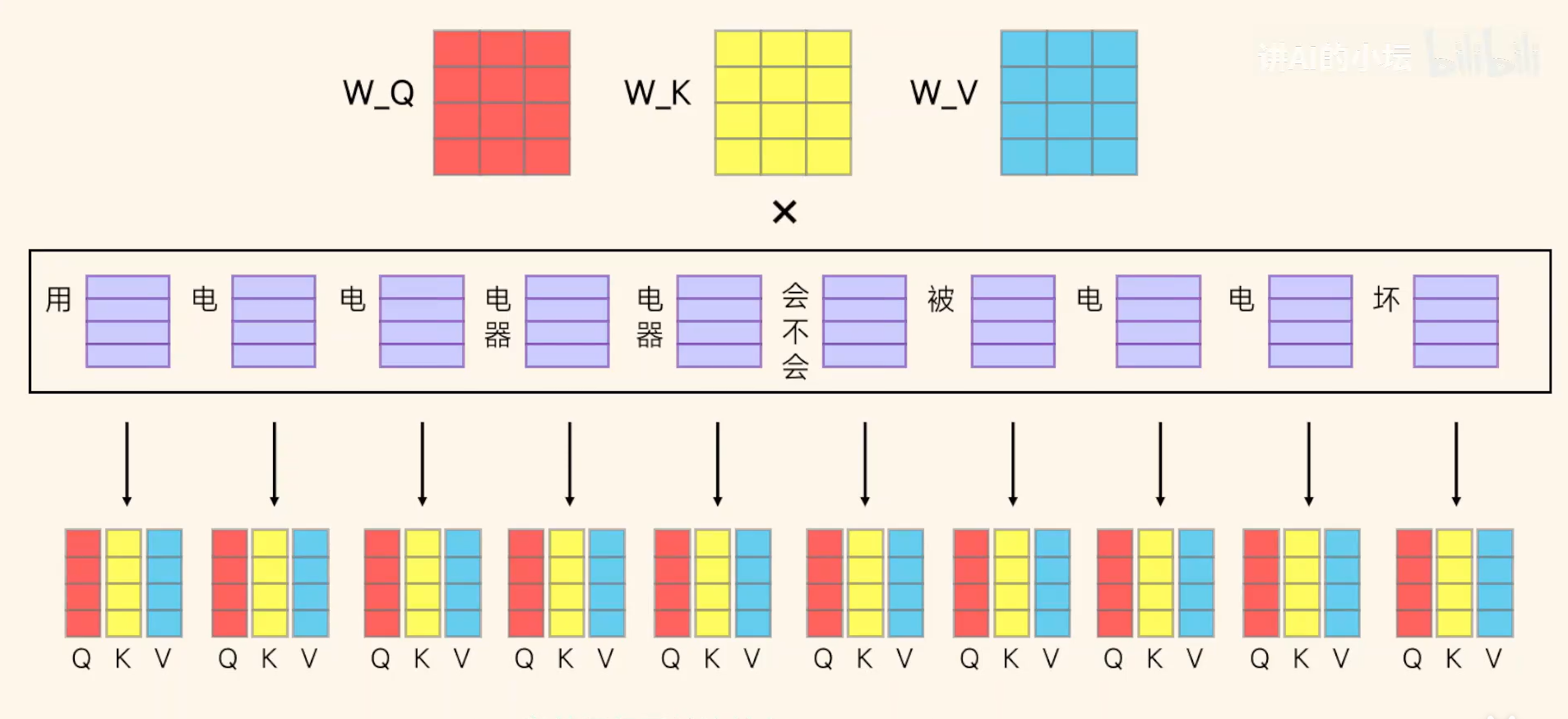
Step3 Token与Token间相互进行相似度计算。计算方式:根据W_Q W_K W_V,让每个词向量与这三个相乘计算各自的Q,K,V。其中Q表示当前词需要关注什么,K表示其他词能提供什么,V表示该词实际包含的结果。

Step4 用每个词的Q向量与每个词的K向量做点乘,算出词与词间的关系。

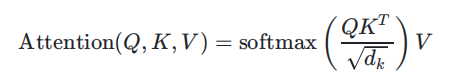
Step5 第四步得到的结果乘上各自的V,再求和获取该词在整个句子中的关系。

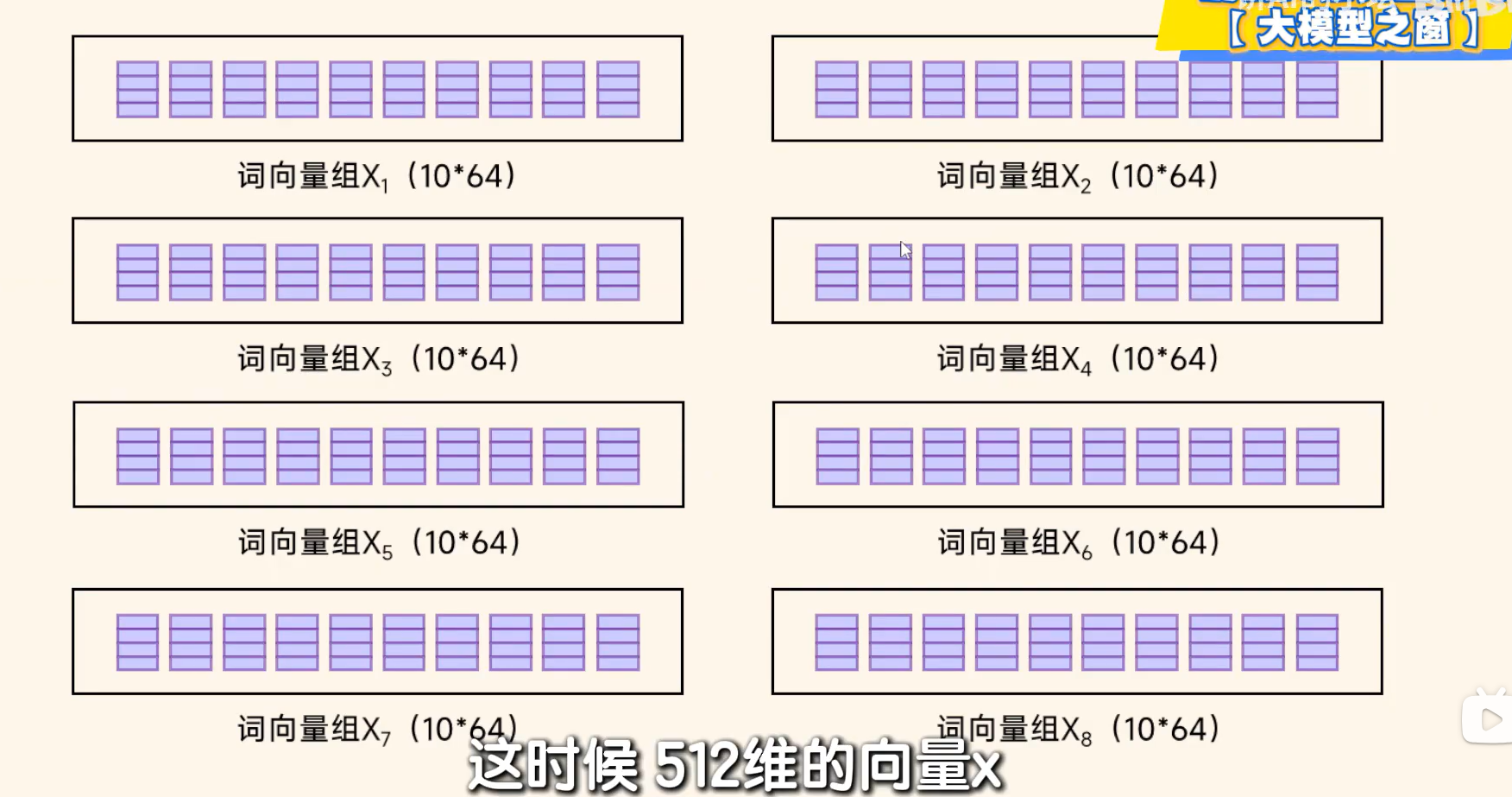
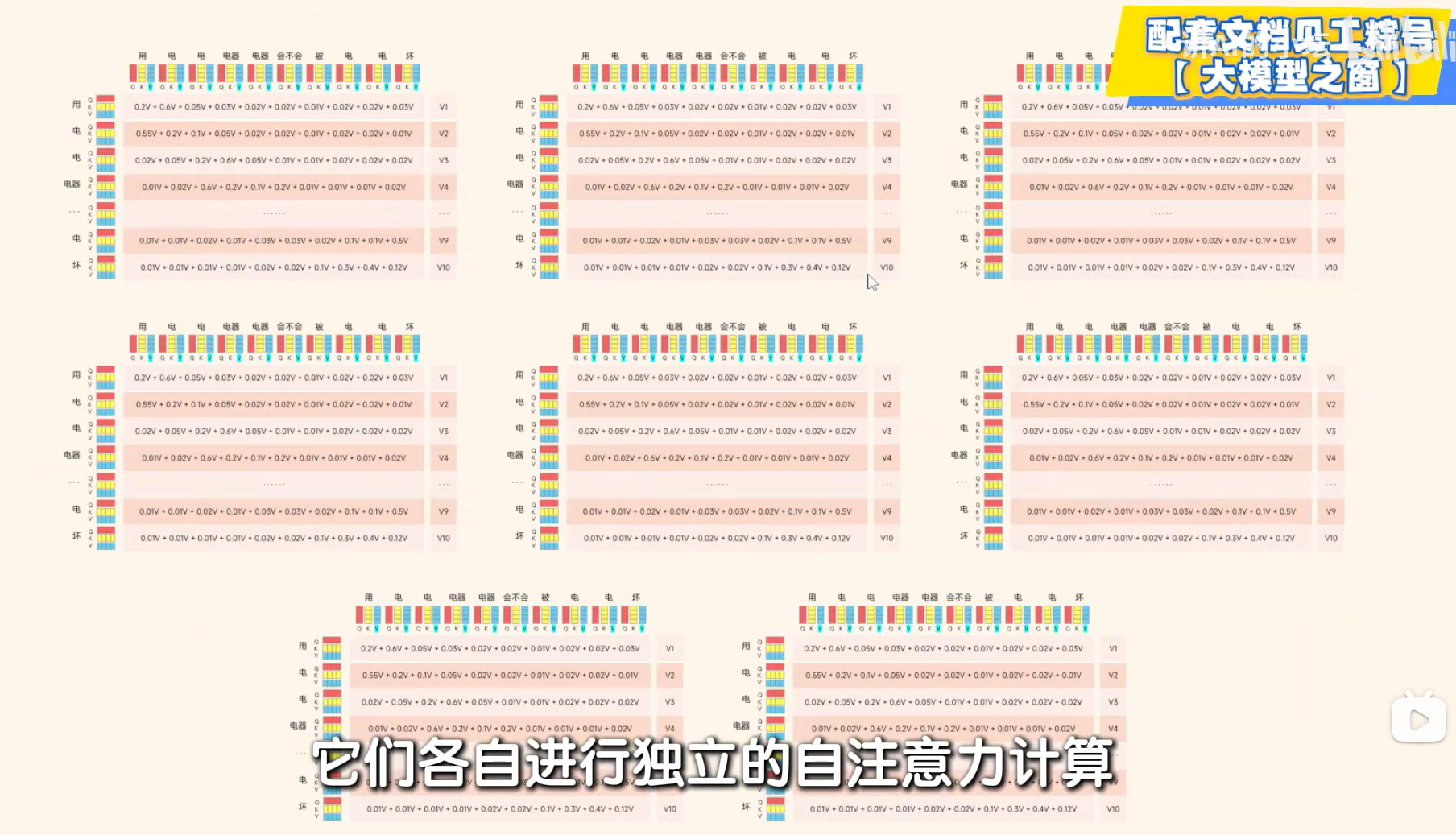
Step6 为进一步让模型理解输入,将一个句子分解成8各部分即,由10*512 变成 10*64 。各自进行各自的自注意力计算。最后再把这8个结果进行拼接回10*512.可以从多个角度整合复杂的语义信息。这个过程就说多头注意力机制。
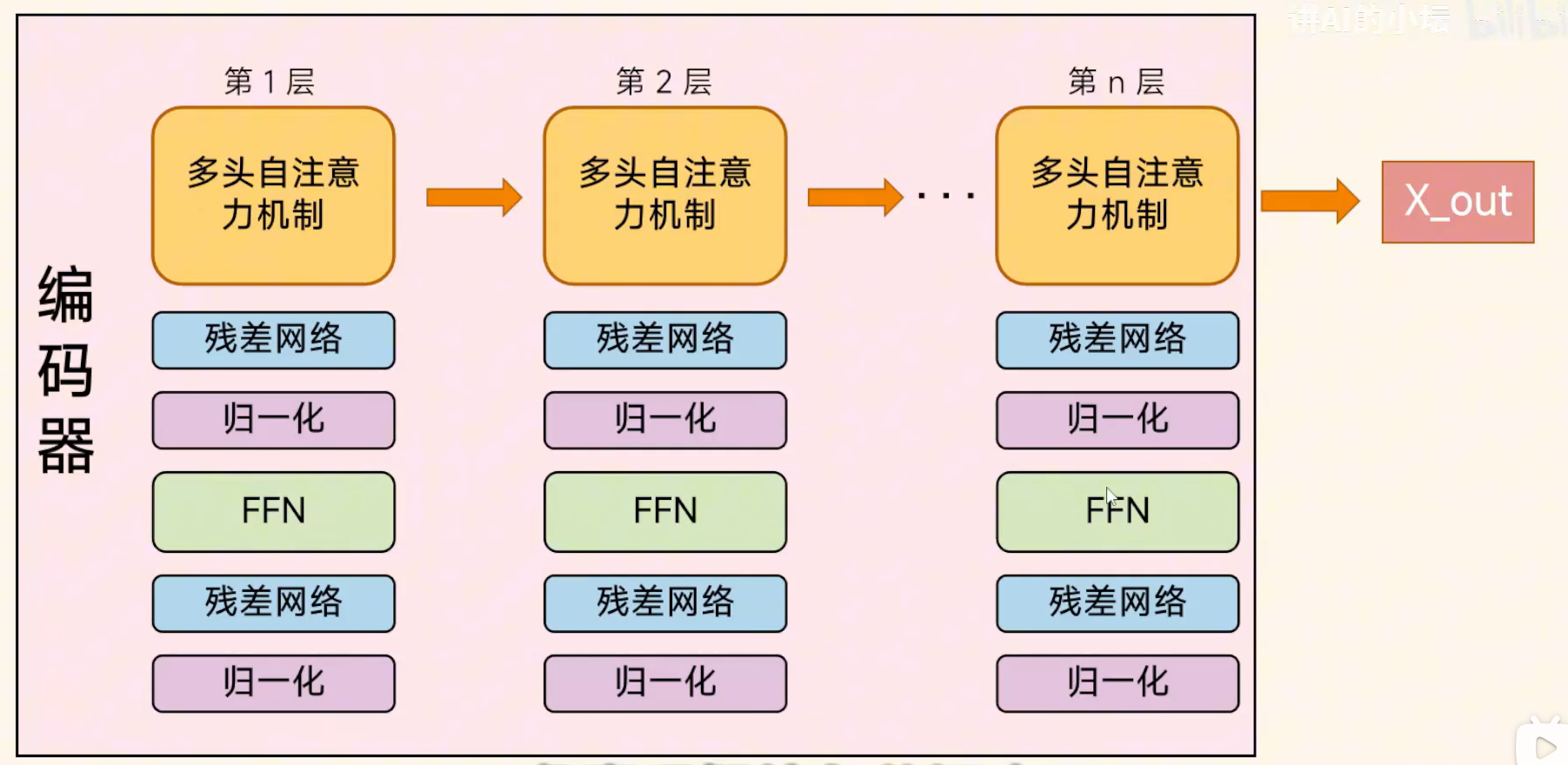
Step7 多层结构学习输入信息。
解码器部分
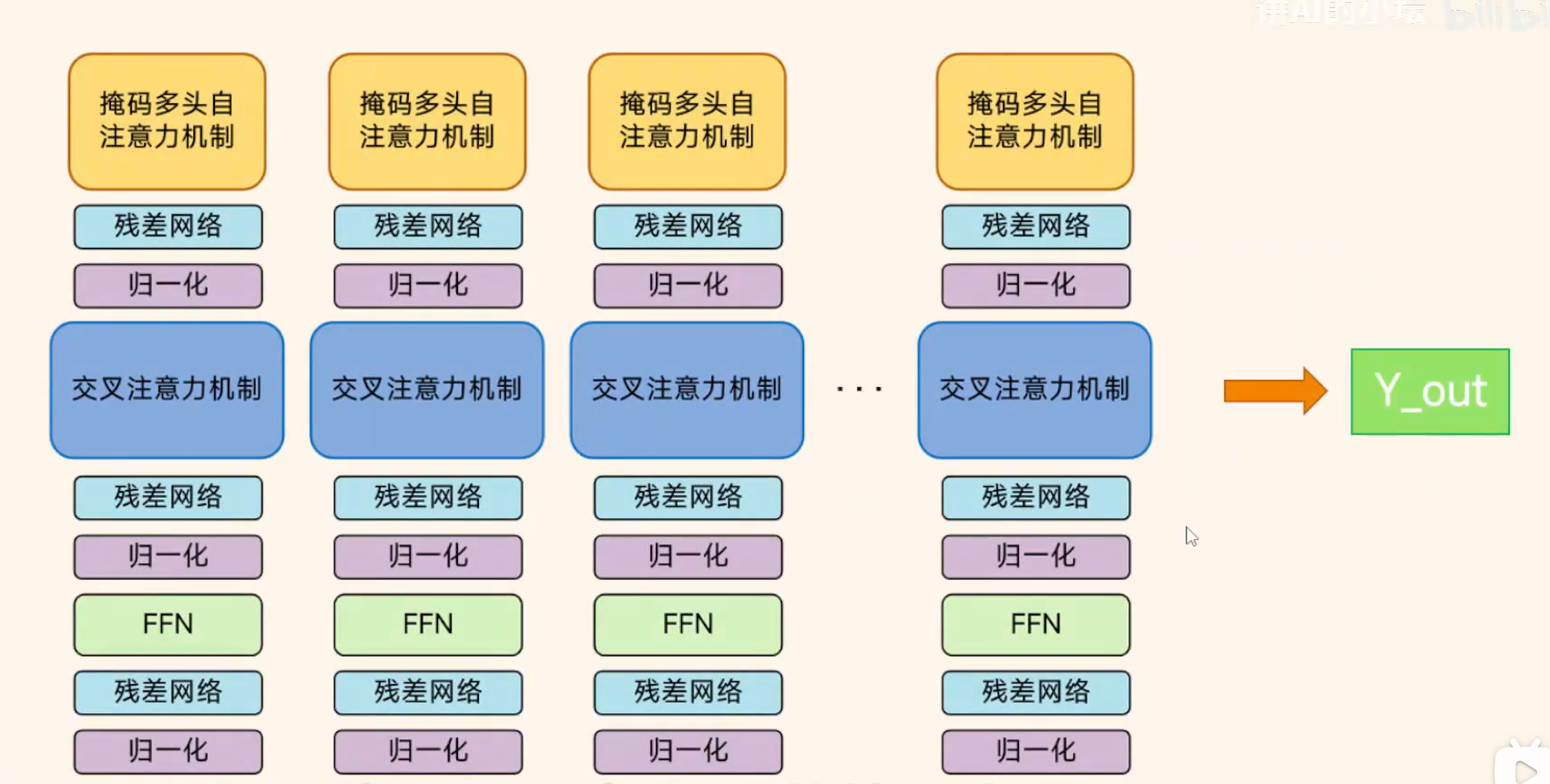
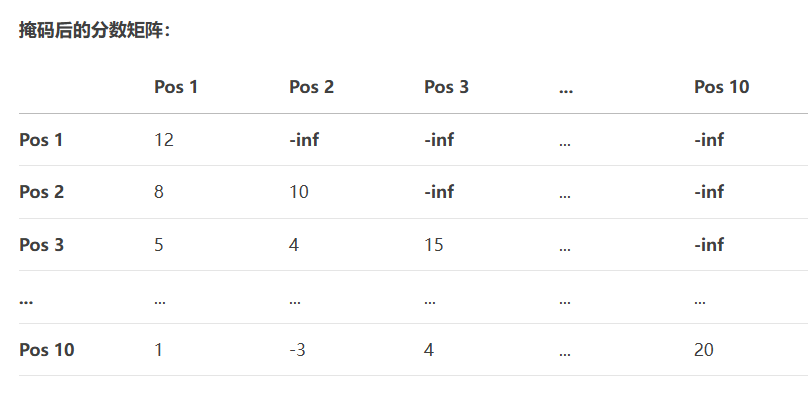
Step2 编码器-解码器注意⼒层(Encoder-Decoder Attention Layer): 该层作⽤是通过编码器输出的上下⽂向量,关注输⼊序列中的相关部分,来帮助解码器⽣成与输⼊相对应的⽬标序列。其中Q是掩码多头自注意力机制的输出,K,V是解码器的输出。
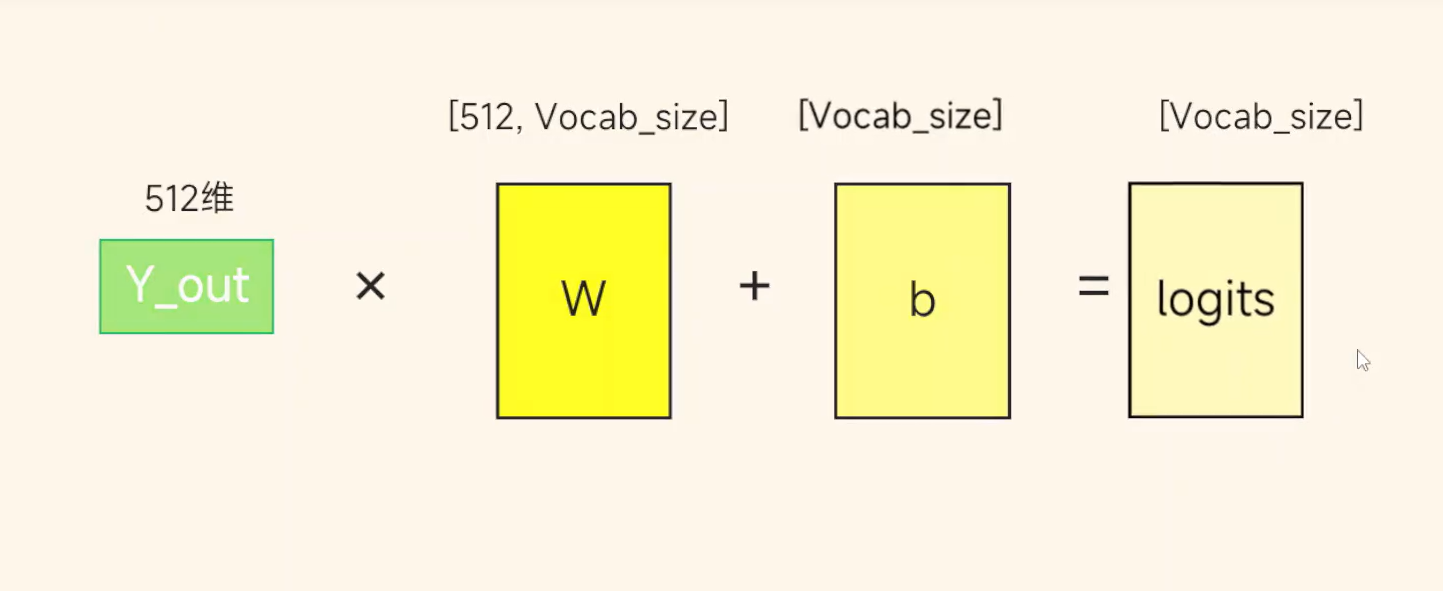
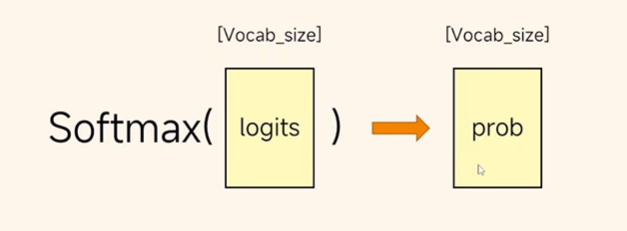
Step3 输出向量映射为一个单词,Y×vocab矩阵,softmax获取每个词的概率,拿出最大的那一个,循环一直到输出截至符为止。
学习来源:B站小坛AI13分钟带你Transformer,从零揭秘Transformer的真面目_哔哩哔哩_bilibili
八股文
1、交叉熵损失函数



2、Positional Encoding原理
Transformer论文中,使用正余弦函数表示绝对位置,通过两者乘积得到相对位置。因为正余弦函数具有周期性,可以很好地表示序列中单词的相对位置。


3、BatchNorm和LayerNorm的区别,为什么不用BatchNorm
BatchNorm
BatchNorm是从某一特征维度,以批次为标准进行归一化,适合CV任务,同时受Batch的大小影响。沿着批次(Batch)维度进行归一化。
BatchNorm核心思想:让一个批次内所有样本的某个特征维度的分布稳定(均值为0,方差为1)。
优点:
非常有效,尤其是在计算机视觉(CV)的卷积网络中,成为标配。
有一定的正则化效果(因为一个样本的激活值依赖于同一批次中的其他样本),可以减少过拟合。
缺点:
对批次大小敏感:如果批次很小(比如1或2),计算的均值和方差噪声会很大,导致性能急剧下降。不适合小批量或在线学习场景。
不适合序列模型:在RNN或Transformer中,序列长度是变化的,不同批次的计算图可能不同,导致均值和方差的估计不稳定
LayerNorm
LayerNorm是对于一个样本整体进行归一化,适合序列样本。对于单个样本,针对该样本的所有特征维度计算均值和方差。
LayerNorm核心思想:让单个样本所有特征维度的分布稳定(均值为0,方差为1)。
优点:
不依赖于批次大小:它的计算完全在单个样本内部进行,因此无论批次大小是1还是1000,其行为都是一致的。这使得它非常适合小批次训练和序列模型(如RNN, Transformer)。
适合变长输入:每个样本独立计算,序列长度不同也没关系。
缺点:
在卷积网络上的效果通常不如BatchNorm。

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









