




在⾃然语⾔处理(NLP)领域,Tokenizer(分词器)是将原始⽂本转换为模型可处理的基本
单位(即词元或Token)的⼯具。Tokenizer的训练对于模型的性能和效率⾄关重要。
1、为什么需要Tokenizer

2、基本概念

3、传统的分词方式及其缺陷
(1)基于词的分词
缺陷:将⽂本按空格或标点分割,但⽆法处理新词、拼写错误或形态变化,导致⼤量的未登录词 (OOV)。
(2)基于字符的分词
缺陷:将每个字符作为⼀个Token,词汇表小,但序列⻓度过长,模型难以捕获长距离依赖。
4、常见的分词方式
什么子词分词:⼦词分词在字符级和词级之间找到平衡,通过将词拆分为更小的子词单位,解决新词和低频词的问题。
BPE合并频繁字节对,WordPiece基于概率合并
-
Dropout应用在注意力分数、FFN输出、嵌入层等位置。
-
测试时需要关闭Dropout(使用eval模式),但需缩放权重(如乘以Dropout概率)或直接使用推理模式。
4.1 子词分词方法——Byte Pair Encoding(BPE)
BPE最初⽤于数据压缩,其在NLP中的应⽤是:从字符开始,迭代地合并频率最高的相邻符号对,构建子词词汇表。
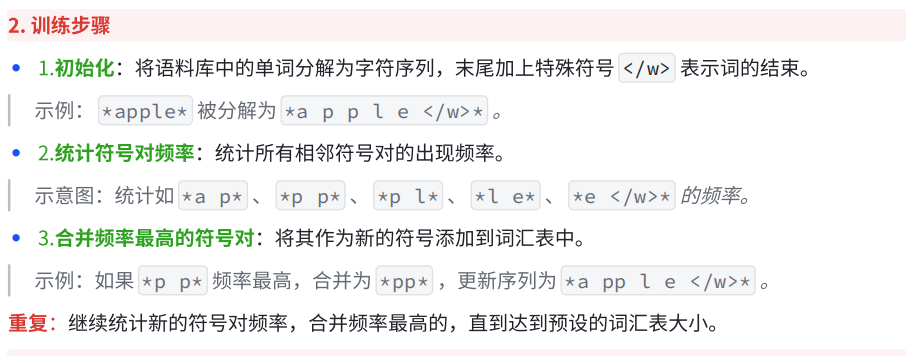

持续合并,构建更⼤的⼦词。
BPE的缺点:无法获取语义信息。
BPE的优点:简单高效、适用于多种语言、易于实现。
4.2 子词分词方法——WordPiece算法
与BPE类似,但在合并时考虑了语⾔模型的概率。
步骤
Step1 初始化:同样将词分解为字符序列。
Step2 迭代合并:
◦ 计算得分:对每个可能的合并,计算语⾔模型概率的增益。
◦ 选择合并:选择使模型概率增益最⼤的符号对进⾏合并。
Step3 更新词汇表:将新的合并符号加⼊词汇表。
WordPiece优缺点:
•
优点:考虑了语⾔模型的概率,提⾼了分词的合理性。
•
缺点:计算复杂度⾼,训练时间较长。
4.3 Unigram语⾔模型
基于Unigram(⼀元)语⾔模型,将分词视为对词汇表概率分布的估计。
训练步骤


5、实践中的考虑
1. 词汇表大小的选择:需要在模型性能和计算资源之间权衡。
2. 特殊符号处理:如数字、标点、表情符号,需要特殊处理。
3. 多语⾔⽀持:对于多语⾔模型,需要确保Tokenizer对不同语⾔的适⽤性。
6、BPE&BBPE这两种Tokenization方法
BPE(Byte Pair Encoding)和 BBPE(Byte-Level BPE)是⾃然语⾔处理中的两种常⽤的子词分割算法。它们旨在解决词汇表规模和模型泛化能⼒之间的平衡问题,通过将单词分割为较⼩的⼦词单元来降低词汇表的⼤⼩,同时保持良好的语⾔表⽰能⼒。
6.1 BPE(Byte Pair Encoding)
BPE是⼀种基于频率的贪⼼算法,最初⽤于数据压缩。它的核⼼思想是通过反复合并出现频率最⾼的字符对(或⼦词对),从⽽⽣成⼀组⼦词单元。BPE特别适合处理低频词汇的问题,因为它可以有效减少词汇表中的稀有词。


6.2 BBPE(Byte-Level BPE)
BBPE是BPE的字节级扩展版本,主要应⽤于多语⾔模型(如GPT等)和处理Unicode字符的场景。与标准BPE不同,BBPE操作在字节层⾯,⽽不是字符层⾯,这允许它以更加通⽤的⽅式处理任意编码的⽂本(包括⾮拉丁字⺟)。

6.3 BPE和BBPE的应用
• BPE在各种⾃然语⾔处理任务中都有⼴泛应用,如机器翻译(如Google的神经机器翻译系统)。
• BBPE在多语⾔模型中使用频繁,特别是在跨语⾔预训练模型中(如GPT、BERT等)。
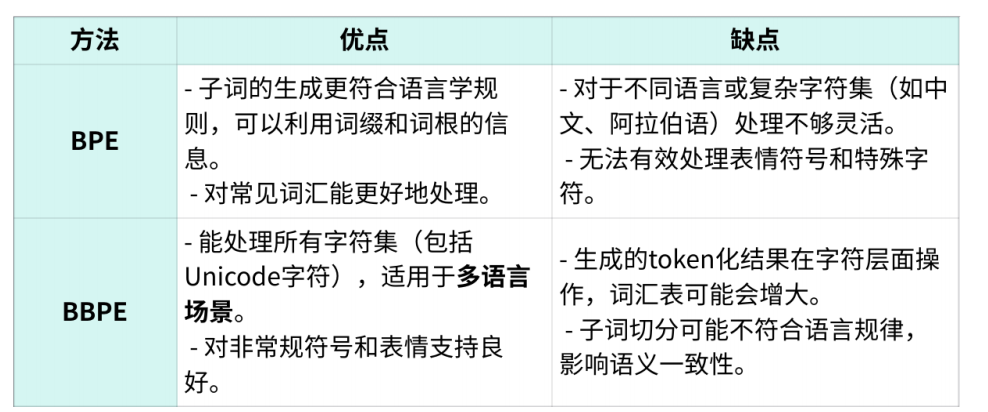
6.4 优缺点
7、主流大模型采用的分词方法为什么选择BBPE而不是BPE
⽬前,主流的⼤模型(如GPT系列、BERT、T5等)⼤多数采⽤的是BBPE(Byte-Level BPE)或类似的字节级tokenization⽅法。BBPE⼴泛应⽤的原因包括:
处理多语言文文本的能⼒ : ⼤模型通常需要处理⼤量不同语⾔的⽂本,⽽BBPE在字节级别操作,能够处理所有Unicode字符,特别是对于包含复杂字符集的语⾔(如中⽂、韩语、阿拉伯语)表现良好。
统⼀的tokenization : BBPE⽅法不依赖于语⾔特定的字符结构,因此可以在不增加额外复杂性的情况下,统⼀应⽤于多语⾔任务,简化了预训练和下游任务中的tokenization流程。
兼容表情符号和特殊字符 : 现代⼤语⾔模型需要处理⼤量互联⽹数据,这些数据中包含许多表情符号、特殊字符以及⾮标准符号,⽽BBPE可以更好地⽀持这类符号。
为什么不选择BPE:
多语⾔与统⼀性 : 随着模型规模的扩大,⽀持多种语⾔和字符集成为必然需求。BBPE通过在字节层⾯的操作,能够避免各语⾔tokenization不⼀致的问题。
处理多种字符 : 由于BBPE可以处理所有Unicode字符,能够无缝处理非拉丁字符和特殊符号,具备更好的通⽤性。
8、总结
BPE 和 BBPE 通过将词分割成⼦词的⽅式来平衡词汇表的⼤⼩与语⾔建模的泛化能⼒。BPE适合处理较为常规的语⾔任务,⽽BBPE适合多语⾔和字符集复杂的场景。

















 2729
2729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









