






python代码,jieba分词,中文文本。
其中font_path去电脑系统设置的字体中“字体文件”找。
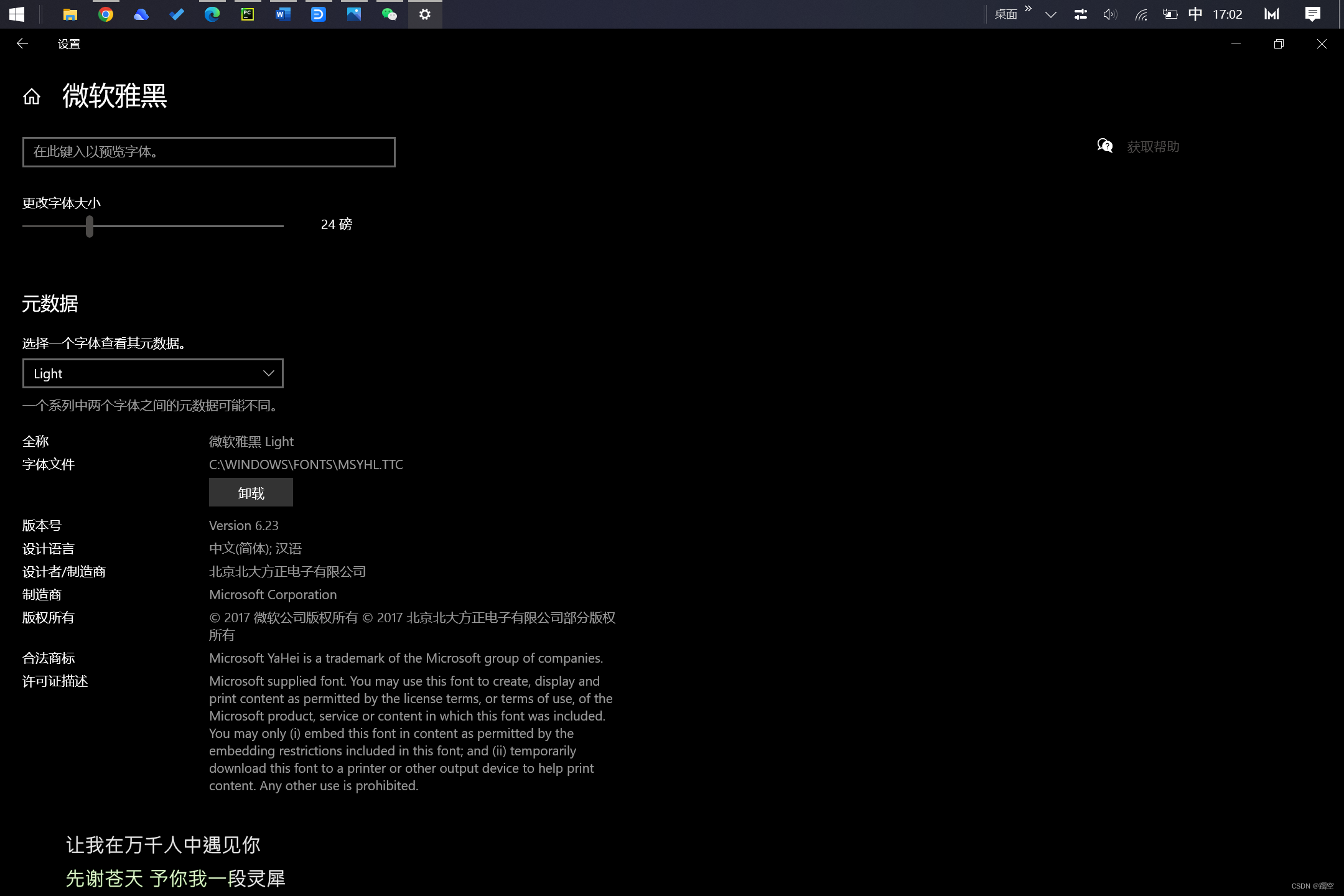
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt', 'r', encoding='utf-8') as file:
text = file.read()
# 分词
seg_list = jieba.cut(text)
tokens = [token for token in seg_list if len(token) > 1]
# 统计词频
word_counts = Counter(tokens)
# 生成词云
wordcloud = WordCloud(font_path='C:\WINDOWS\FONTS\MSYHL.TTC',
width=800,
height=400,
background_color='white',
max_words=100).generate_from_frequencies(word_counts)
# 保存词云图为图片
wordcloud.to_file('wordcloud.png')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









