






 文章介绍了如何搭建和使用PaddlePaddle的Senta模型进行情感倾向分析,包括安装PaddlePaddle和PaddleHub的步骤。在过程中遇到了TypeError、UnicodeDecodeError、ModuleNotFoundError和ImportError等错误,分别通过设置文件编码、安装缺失模块和调整安装版本来解决。最终成功安装了PaddlePaddle2.4.2和PaddleHub1.6.2。
文章介绍了如何搭建和使用PaddlePaddle的Senta模型进行情感倾向分析,包括安装PaddlePaddle和PaddleHub的步骤。在过程中遇到了TypeError、UnicodeDecodeError、ModuleNotFoundError和ImportError等错误,分别通过设置文件编码、安装缺失模块和调整安装版本来解决。最终成功安装了PaddlePaddle2.4.2和PaddleHub1.6.2。
模型搭建
参考的链接
开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
PaddleHub/windows_quickstart.md at release/v2.1 · PaddlePaddle/PaddleHub · GitHub
- 情感倾向分析(Sentiment Classification,简称Senta)针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度,能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。该模型基于一个双向LSTM结构,情感类型分为积极、消极。
一、安装
执行安装python -m pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlehub==1.6.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
senta_bilstm 直接在pytorch中下载,下载的为1.1.0版本,(就是运行代码直接在控制台下载了)
with open("test.txt", 'r') as f: 这个里面加上编码的设置 ,encoding=utf-8
二、遇到的问题
1.TypeError: The input data is inconsistent with expectations.
UnicodeDecodeError: ‘gbk‘ codec can‘t decode bytein position
字符编码问题,with open("test.txt", 'r') as f: 这个里面加上编码的设置 ,encoding=utf-8
2.ModuleNotFoundError: No module named 'scipy'
缺少scipy包,直接在cmd里面pip install scipy
3.Could not build wheels for opencv-python
先pip install cmake
pip install opencv-python
可以在后面加上清华源,opencv-python如果下载错的话,会下载很慢
4.ImportError: cannot import name 'get_installed_distributions' from 'pip._internal.utils
是安装paddlepaddle,paddlehub这个的问题,估计是版本安装的不匹配
最后安装的是paddlepaddle最新的,pip install paddlepaddle==2.4.2,pip install paddlehub==1.6.2
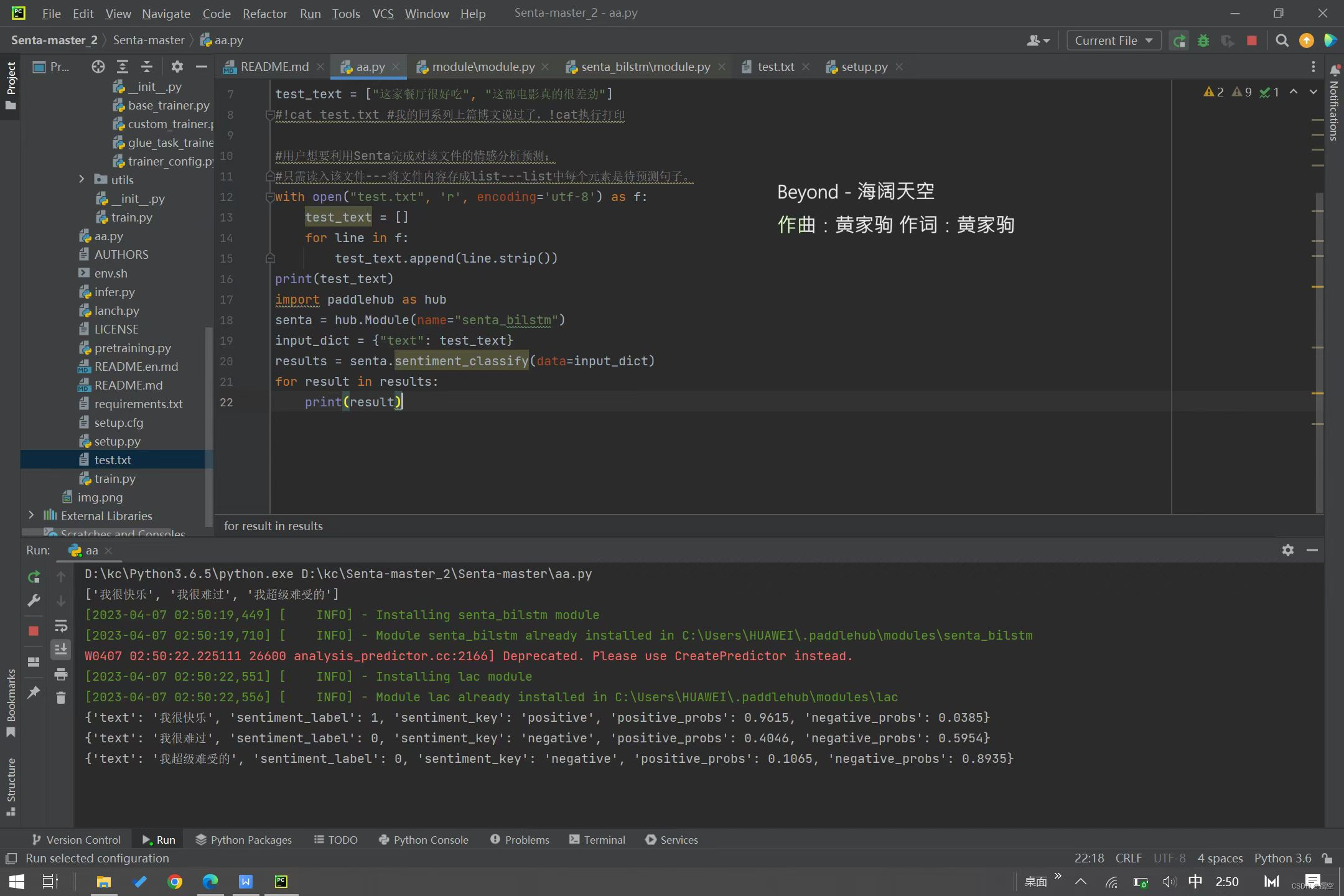
最后的结果,我就是小白一个,python学的稀烂,欢迎大佬指正~

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









