




 这篇博客详细记录了使用Python进行网络爬虫的步骤,包括访问Bilibili网站,发送请求,获取响应数据,并进行持久化存储的过程。内容包含1.1部分的代码展示和1.2部分的操作步骤截图,以及2.1部分针对动态地址的具体操作步骤。
这篇博客详细记录了使用Python进行网络爬虫的步骤,包括访问Bilibili网站,发送请求,获取响应数据,并进行持久化存储的过程。内容包含1.1部分的代码展示和1.2部分的操作步骤截图,以及2.1部分针对动态地址的具体操作步骤。
具体步骤:
1.指定url网址
2.发送请求,访问网址
3.获取响应数据
4.持久化存储,保存在数据库或本地
1.下面是访问的bilibili的网址(可以直接复制到python文件)
1.1代码块
#导入requests模块
import requests
if __name__=='__main__':
#step_1:指定url网址
web = 'https://www.bilibili.com/'
#step_2:发送请求,访问网址
#使用requests.get方法,用的url参数,把web传入url。get方法会返回一个响应对象,传入response
response = requests.get(url=web)
#step_3:获取响应数据
page_text =response.text
print(page_text)
#step_4:持久化存储
# 存在本地 编码 存入
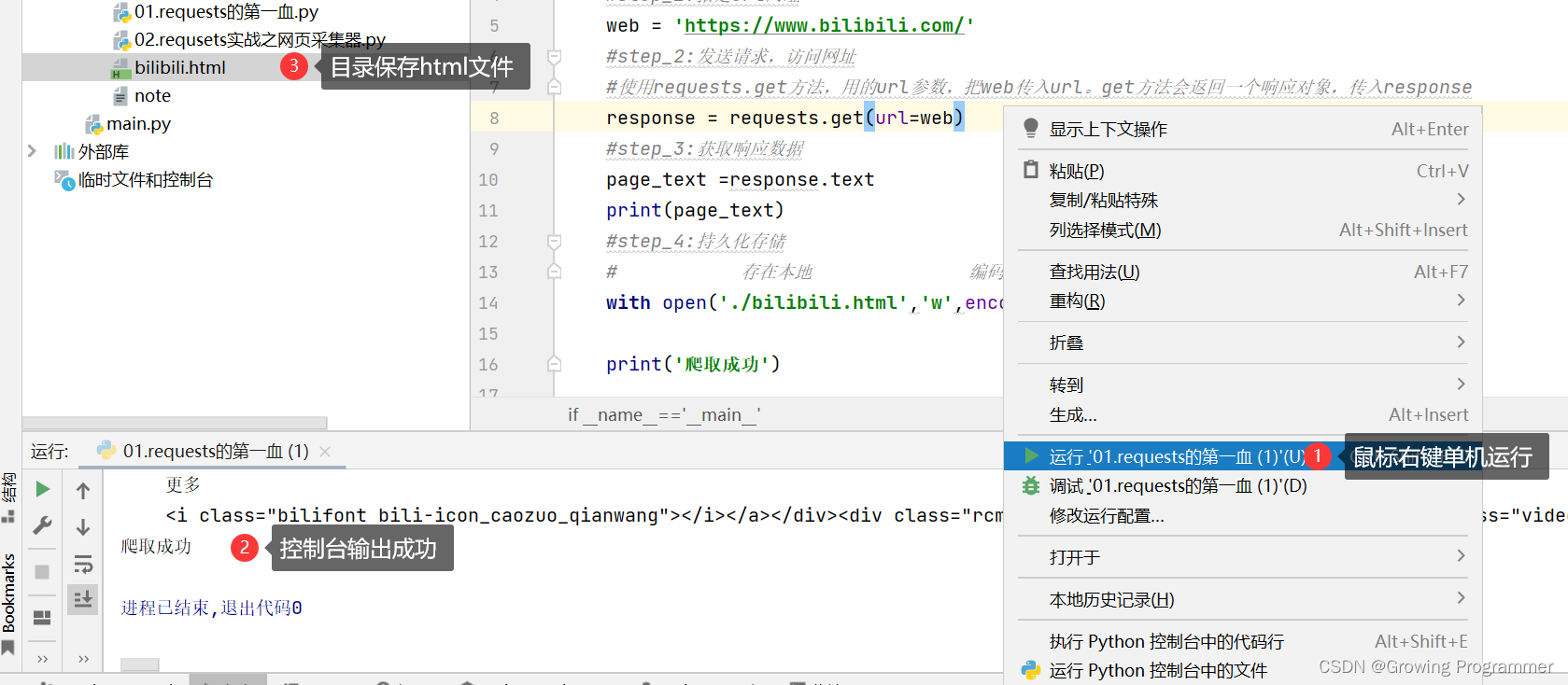
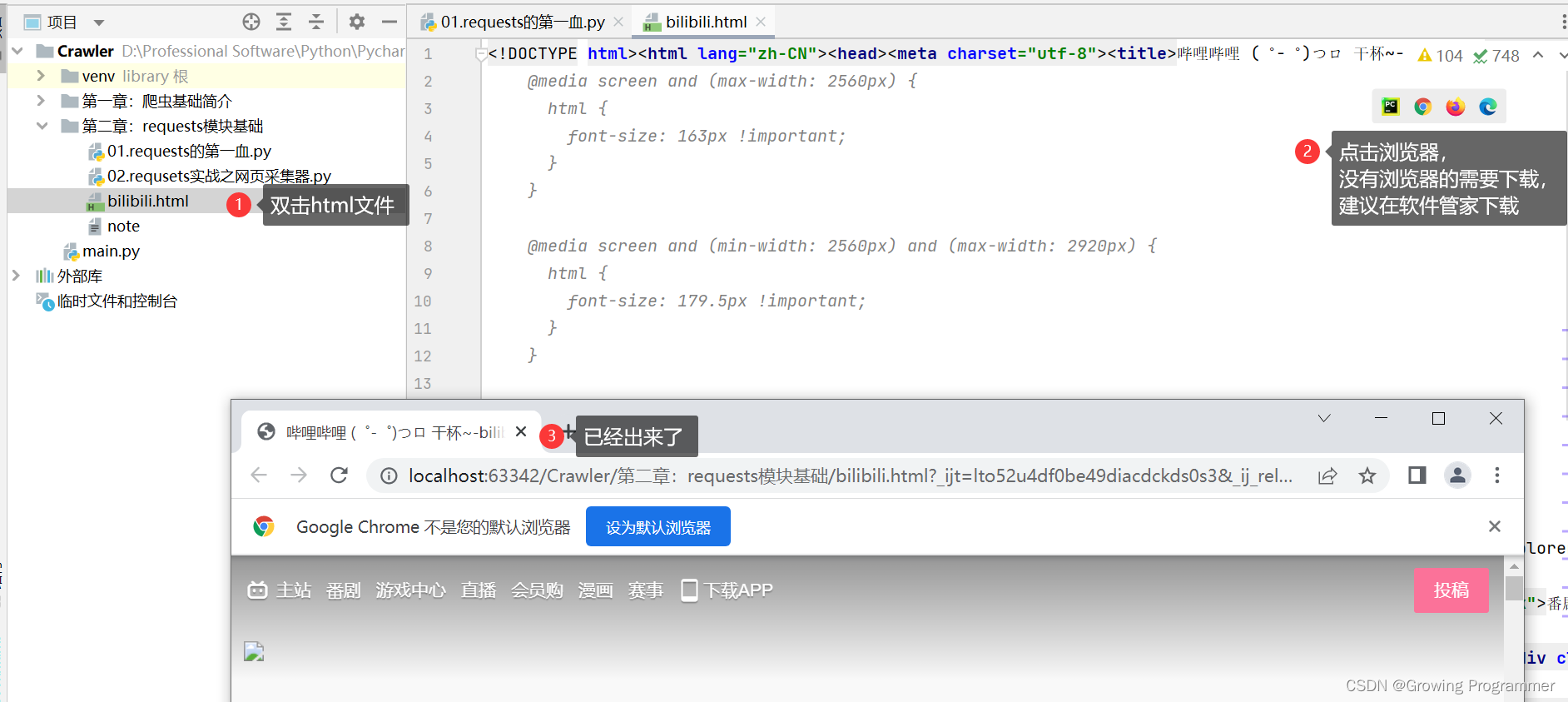
with open('./bilibili.html','w',encoding='utf-8') as fp:fp.write(page_text)
print('爬取成功')
1.2操作步骤截图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 835
835



 到【灌水乐园】发言
到【灌水乐园】发言









