







 本文详细解析switch语句的语法,展示其分支功能的工作原理,并探讨case和default的代码排列策略。学习如何正确使用break、default的位置对代码健壮性的影响,以及最佳实践技巧。
本文详细解析switch语句的语法,展示其分支功能的工作原理,并探讨case和default的代码排列策略。学习如何正确使用break、default的位置对代码健壮性的影响,以及最佳实践技巧。
提到switch,这是一个我们十分熟悉的关键字,而且我们经常在做一些项目菜单的时候去使用它,今天想带大家去真正了解这个关键字。
目录
1、switch关键字的语法规则
switch格式为
switch(整形表达式/整型变量/整型常量)
{
case 常量:
执行的语句;
...........(此处代表多个case语句)
default:
执行的语句;
}
这样讲太过于抽象了,给大家上代码演示一下!
#include<stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一!");
break;
case 2:
printf("星期二!");
break;
case 3:
printf("星期三!");
break;
case 4:
printf("星期四!");
break;
case 5:
printf("星期五!");
break;
case 6:
printf("星期六!");
break;
case 7:
printf("星期天!");
break;
default:
printf("您输入的数据有误!");
break;
}
return 0;
}相信看了代码,大家对switch语句的格式和使用有了一个清晰的认知,接下来进入下一模块!
2、switch语句是如何具有分支功能的
首先给大家强调一件事,switch本身并不具有分支功能,因为switch只是执行后面()中的内容,然后得出相应的整型数据或者字符型数据,当然,字符型本质上也是整型数据,
在switch()中的表达式执行完后,将执行{}中的内容,执行顺序是顺序执行的(对于case语句来说),当switch语句执行得到的数据与case 后面的常量匹配一致后,将开始执行case后面的语句,无论后面再遇到的case语句是否匹配,程序将一直执行,直到遇到break语句或者{}语句块执行结束,接下来将给大家代码展示这一点:
#include<stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一!\n");
case 2:
printf("星期二!\n");
case 3:
printf("星期三!\n");
case 4:
printf("星期四!\n");
case 5:
printf("星期五!\n");
case 6:
printf("星期六!\n");
case 7:
printf("星期天!\n");
default:
printf("您输入的数据有误!\n");
}
return 0;
}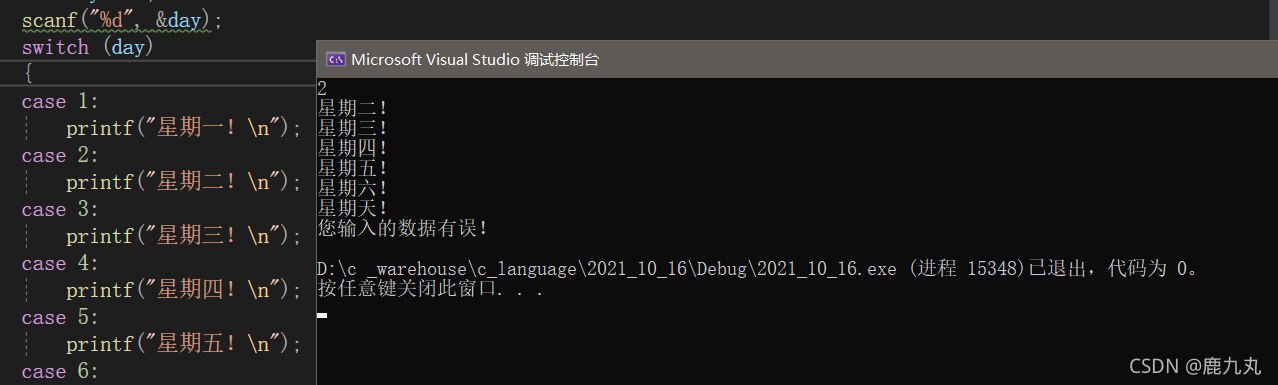
程序的运行结果很明显,因为我输出的是2,所以switch语句()里的内容是2,在程序执行{}中的内容时,将拿着2去匹配,首先顺序执行case语句,第一个是case 1,并不匹配,然后是case 2,刚好匹配了,然后执行输出语句printf("星期二"),执行完成后,case 3以及后面的case 4等等语句,虽然不匹配,但仍旧进行执行,接下来,我们看一下有break关键字的代码块正常执行应给是什么样的:
代码块正常进行分支,前面我们已经了解了,switch并不能完成分支功能,而只有case也不能完成分支功能,case完成的是匹配或者判定功能,最后加上了break才完成了真正意义上的分支功能, 总结而言,switch语句中,switch()只负责执行表达式,得到整型数值,case完成匹配或者说是判定功能,break完成的是分支功能,或者说case和break共同完成分支功能,而不是switch,这是一个需要我们去理解的点。
3、有关于case和default的代码排放顺序
其实一般情况下我们是不需要讨论这个排放顺序的,因为我们在使用时通常会对每一个接口使用break退出switch语句,在这种情况下case和default无论放在任何位置都没有关系,但出于逻辑和维护考虑,我们通常按照从大到小顺序对case进行排放,把default放在最后,同时把最容易匹配或者说是匹配频率最高的放在最前面,这样在一定程度上能够提高代码的运行效率,
#include<stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
default:
printf("您输入的数据有误!");
break;
case 1:
printf("星期一!");
break;
case 2:
printf("星期二!");
break;
case 3:
printf("星期三!");
break;
case 4:
printf("星期四!");
break;
case 5:
printf("星期五!");
break;
case 6:
printf("星期六!");
break;
case 7:
printf("星期天!");
break;
}
return 0;
}

大家很容易看到,此此时我们虽然把 default放在了最前面,但并不影响程序的正常执行,通过逐步运行后我们可以看出,当我们在输入8时,程序直接执行了default,而并没有对case进行匹配,当然,匹配了也无法完成匹配,这是一个有趣的现象,限于作者当前的水平有限,无法给出相应的解释,如果大家有相应的解释,希望可以在评论区给出。
为了我们的理解,我们通常这样理解,我们输入的数字,在跟default进行匹配的时候,先跟所有的case进行了匹配,匹配并未通过,所以执行default后面的内容,当然,程序在执行的时候并不是这样的这样的,但有助于我们从表面上去理解程序,当然,如果default中没有相应的break语句,程序将继续执行后面的case语句,同样的,下面给出相应的代码展示:
#include<stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
default:
printf("您输入的数据有误!");
case 1:
printf("星期一!");
break;
case 2:
printf("星期二!");
break;
case 3:
printf("星期三!");
break;
case 4:
printf("星期四!");
break;
case 5:
printf("星期五!");
break;
case 6:
printf("星期六!");
break;
case 7:
printf("星期天!");
break;
}
return 0;
}
大家看到这之后就疑惑了,为什么会这样呢?这样不就跟你前面给出的解释混淆了吗?所以就可以得出我前面的解释并不是正确的,起码编译器就不是这么运行的(有兴趣的可以自己调试来看),在编译器中,switch后面的{}永远都是顺序执行的,而对于其匹配,则由其最根本的意义来进行匹配,default就是执行与所有的case不相匹配的情况,而casse语句就是进行相应的匹配,从其最本质理解即可!
这一段总结来说,就是:
1、case和default在每一个语句块中如果都放置了break退出语句的话,他们的排放顺序是没有任何关系的,也对程序最后的运行结果没有任何的影响
2、switch后面的{}中的内容永远都是顺序执行的!
4、有关于switch的小点总结(强烈推荐,一定要看!!)
(1)switch后面跟整型变量、常量、整型表达式(只能为整型或者字符型)
(2)switch语句中,switch语句本身没有判定和分支功能,case完成的是判定功能,而break完成的则是分支功能。一定不要忘记加上default!必须要带!(代码具有更好的健壮性)。这是作为一个优秀程序员的自我修养!
(3)case后面如果想要定义变量(注意是定义而不是赋值),需要加{},可以在代码块内进行定义,当然,在case语句中变量也只能在代码块内进行定义。在case之后可以执行多条语句,不用{}也可以,但最好加上,或者直接封装为函数。
(4)default可以放在任意位置,可以放在case前,case中间,case最后都没有任何的影响,但习惯上将default放在最后。
(5)case后面不要用return。虽然说编译器不会报错,但我们要搞清楚return 的作用,return的作用是直接退出程序,返回值为0,而break的作用是退出循环或者switch语句,我们要搞清楚这一点,如果你用了return并且成功匹配,那么程序就不会执行switch后面的语句,有兴趣自己试一下。
(6)不要在switch后面的括号内出现bool值。虽然说程序也不会报错,但我们并不推荐这样,因为()里面我们通常得出的是整型数值,bool类型可以正常运行的原因是c99和c90标准下的vs 2019把true默认为是1,把false默认为是0,这些同样是作为一个优秀程序员的自我修养!
(7)case后面要跟真的常量,const修饰的常变量是无法编译通过的。
(8)建议case后面要有好的布局方式,从小到大,以及把最容易匹配到的放在最前面。
(9)switch后面{}内的语句位于case和default外面的无法进行执行,无论是定义变量的语句还是其它如printf()之类的输出语句。
(10)case语句执行完后,后面的语句无论是否匹配成功,都将执行!除非遇到break退出语句或者switch后面{}中的内容执行完。


















 3337
3337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











