






习题3-2
在线性空间中,证明一个点𝒙到平面𝑓(𝒙; 𝒘) = = 0的距离为|𝑓(𝒙; 𝒘)|/‖𝒘‖。
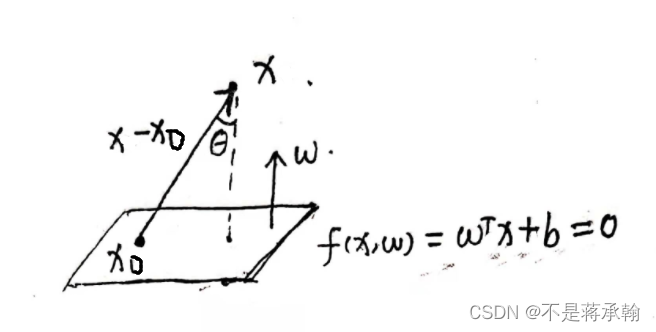
取平面𝑓(𝒙; 𝒘) = 0中任意一点,得到向量
(即
),其中点x到平面的距离d为向量
在平面法向量w上的投影,
,θ为
与法向量w的夹角。
因为点在平面
内,所以有
带入d中得:
习题3-5
在Logistic回归中,是否可以用去逼近正确的标签𝑦,并用平方损失
最小化来优化参数𝒘?
不可以。
logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。
sigmoid:使大的值更大、小的值更小(数值被归整到0-1之间);多用于二分类问题。
线性回归的输出使用sigmoid激活后成为logistic回归,logistic 回归能实现非线性特征变换,这也就是加深网络的意义。
softmax:使所有的值之和为1(保持数值间的大小关系);可用于多标签分类问题。
sigmoid 处理的是单个输入值,不关注整体输入数据的关系。softmax 处理的是单个与整体的输入值,关注整体输入数据的关系。
logistic回归不能用均方误差,在使用One-Hot编码表示分类问题的真实标签的情况下,我们使用平方损失函数计算模型的预测损失时会计算预测标签中每一个类别的可能性与真实标签之间的差距。
若我们想要得到更小的损失则需要模型预测得到的预测标签整体与One-Hot编码的真实标签相近,这对于模型来说计算精度要求过高,在分类我们上我们往往只关注模型对数据的真实类别的预测概率而不关注对其他类别的预测概率。所以对分类问题来说,平方损失函数不太适用。
习题3-6
在 Softmax 回归的风险函数(公式 (3.39))中,如果加上正则化项会有什么影响?
Softmax回归中使用的𝐶个权重向量是冗余的,即对所有的权重向量都减去一个同样的向量 𝒗,不改变其输出结果。因此,Softmax回归往往需要使用正则化来约束其参数。此外,我们还可以利用这个特性来避免计算Softmax函数时在数值计算上溢出问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









