




1.数据准备
首先对原始数据集进行整理,将标注好的图像和标签分别放在两个文件夹中,同时额外新建两个文件夹,用于存放转换完的标签与划分后的数据集。
1.1将json格式文件转换为txt格式
新建json2txt.py文件,将代码中的文件路径修改为自己的路径。
❗❗❗代码中第43行的classes中存放的是自己数据集的分类标签,记得修改成自己的。
import json
import os
from tqdm import tqdm
def convert_label(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
path = os.path.join(json_dir, json_path)
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
json_dir = 'E:/segmentation_dataset/json'
save_dir = 'E:/segmentation_dataset/txt'
classes = 'material,inner_material,hole'
convert_label(json_dir, save_dir, classes)
1.2划分数据集
新建splitDataset.py,将代码中的文件路径修改为自己的路径。
数据集的划分比例可以按自己的需求修改。
import shutil
import random
import os
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def split(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir)
mkdir(labels_dir)
mkdir(img_train_path)
mkdir(img_test_path)
mkdir(img_val_path)
mkdir(label_train_path)
mkdir(label_test_path)
mkdir(label_val_path)
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
image_dir = 'E:/segmentation_dataset/images'
txt_dir = 'E:/segmentation_dataset/txt'
save_dir = 'E:/segmentation_dataset/dataset'
split(image_dir, txt_dir, save_dir)
运行完后得到如下文件:
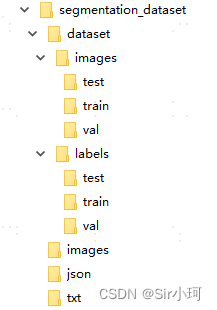
dataset中分别存放有划分好的图片数据和标注数据。
到此,数据集制作完毕!
2.训练设置
2.1新建segmentation.yaml文件
按照如下格式在yolov8工程的datasets文件夹下进行新建,路径修改为自己的路径,对应的分类标签也修改为自己的。
train: E:\segmentation_dataset\dataset\images\train # train images (relative to 'path') 128 images
val: E:\segmentation_dataset\dataset\images\val # val images (relative to 'path') 128 images
test: E:\segmentation_dataset\dataset\images\test # test images (optional)
# Classes
names:
0: material
1: inner_material
2: hole
2.2训练参数设置
配置参数如下图所示:
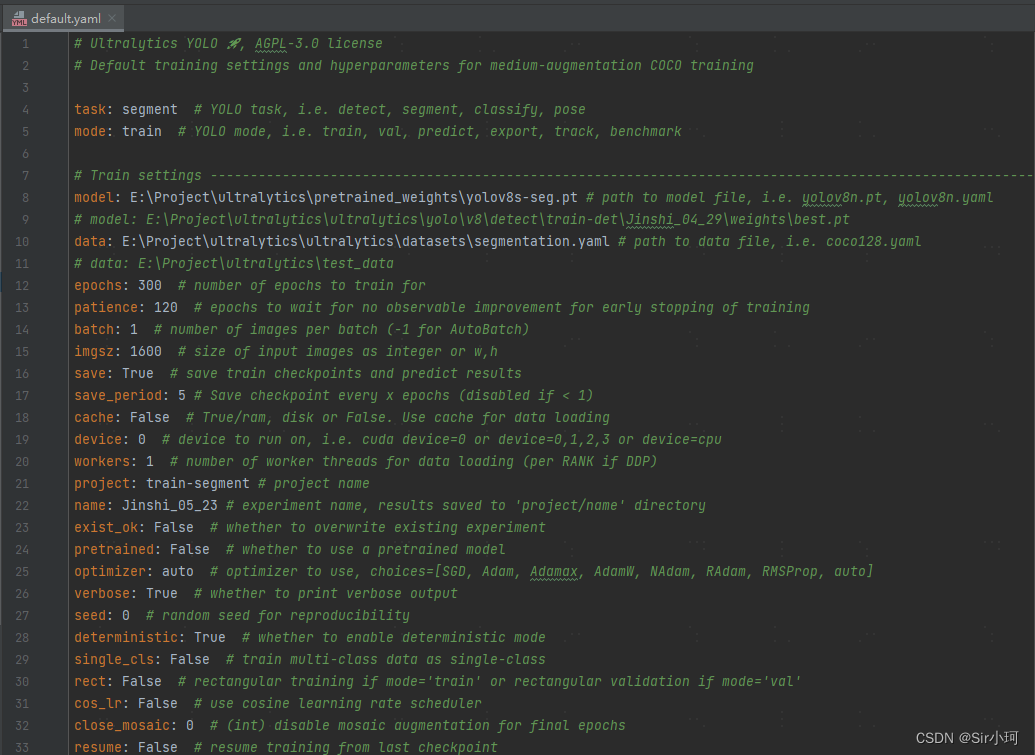
以上常用参数解释如下:
📌task:选择任务类型,可选['detect', 'segment', 'classify', 'pose']。
📌mode: 选择是训练、验证、预测和导出模型等,可选['train', 'val', 'predict', 'export', 'track', 'benchmark']。
📌model: 选择yolov8不同的模型配置文件,可选yolov8s-seg.pt、yolov8m-seg.pt、yolov8x-seg.pt等(提供了n、s、m、l、x版本,随着架构的增大,训练时间也是逐渐增大,需要根据自身设备硬件配置合理选择)。
❗❗❗注意model最好去github上提前下载好,放在如图所示的指定位置,如果没提前下载运行时会自动下载,但是下载速度可能非常非常慢。
yolov8官方权重下载地址:
 https://github.com/ultralytics/ultralytics?tab=readme-ov-file
https://github.com/ultralytics/ultralytics?tab=readme-ov-file📌data: 选择生成的数据集配置文件。
📌epochs:训练过程中整个数据集的迭代次数。
📌batch:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,提示爆显存就需要调小一点。
📌imgsz:输入图片的尺寸大小。
📌workers:用于数据加载的工作线程数。
📌project:训练工程名称。
📌name:保存训练结果的文件夹名称。
📌resume:从最后一个检查点恢复训练,即模型训练的断点接续,可选False或True。
完成配置后,开始进行训练即可!
另外,如果有想了解yolov8目标检测数据集制作以及YOLOv8目标检测 opencv模型部署的小伙伴可以移步我的其他文章



















 8141
8141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











