



一、不相交集合的操作
1、基本操作
:建立一个新的集合,它的唯一成员是
。
:将包含x和y的两个动态集合(
和
)合并成一个新的集合。
:返回一个指针,这个指针指向包含
的唯一的集合代表。
我们使用如下两个参数衡量时间复杂度:
:MAKE-SET操作次数。
:MAKE-SET、UNION、FIND-SET操作总次数。
2、Disjoint Sets的一个应用:无向图的连通分量
不相交集合数据结构的应用之一是确定无向图的连通分量。CONNECTED-COMPONENTS使用不相交集合数据结构来计算无向图的连通分量,SAME-COMPONENT回答两个顶点是否在同一个连通分量。

举例:
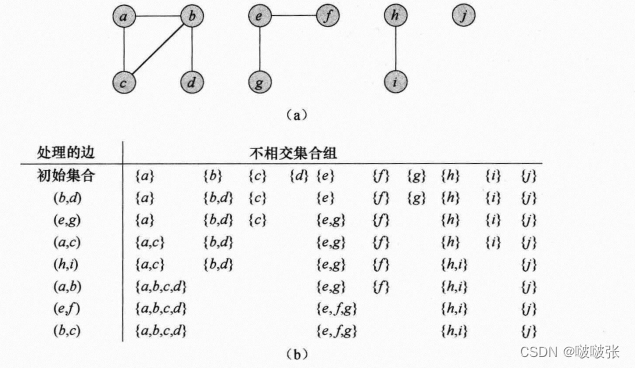
二、不相交集合的链表表示
1、用链表实现的Disjoint Sets
每个集合用一个自己的链表来表示。每个集合对象包含head和tail属性,head指向表的第一个对象,tail指向表的最后一个对象。链表中的每个对象都包含一个集合成员、一个指向链表中下一个对象的指针和一个指回到集合对象的指针。
例如:
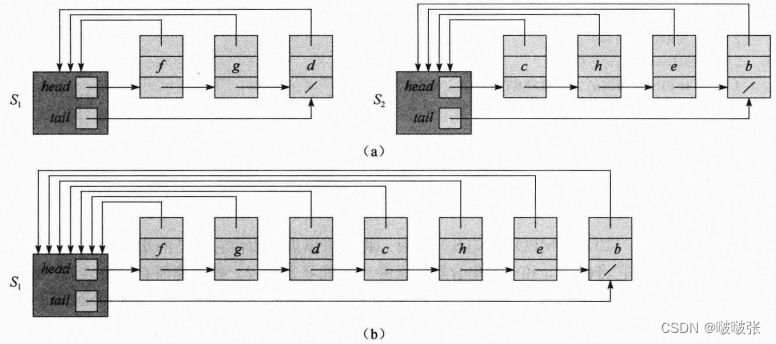
时间复杂度:平均情况下,MAKE-SET:;FIND-SET:
;UNION:
。
特点:FIND-SET快,UNION慢。
2、一种加权合并的启发式策略
加权合并启发式策略:总是将较短的表拼接到较长的表中。
定理:使用不相交集合的链表表示和加权合并启发式策略,一个具有
个MAKE-SET、UNION、FIND-SET操作的序列(其中
个是MAKE-SET操作)需要的时间为
。
时间复杂度:平均情况下,MAKE-SET:;FIND-SET:
;UNION:
。
三、不相交集合森林
1、用森林实现的Disjoint Sets
在一个不相交集合森林中,每个成员仅指向它的父结点,根结点是代表,且是自己的父结点。
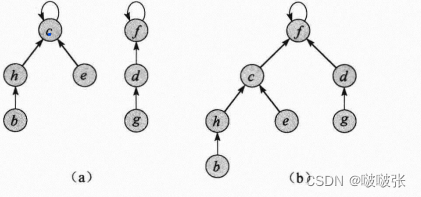
特点:FIND-SET慢,UNION快。
2、改进运行时间的启发式策略
通过使用如下两种启发式策略,我们能获得一个几乎与总的操作数呈线性关系的运行时间。
策略一按秩合并(union by rank):让具有较小秩的根指向具有较大秩的根。对于每个结点维护一个秩,它表示该结点高度的一个上界。
时间复杂度:当仅使用按秩合并策略时,平均情况下,MAKE-SET:;FIND-SET:
;UNION:
。
策略二路径压缩(path compression):在FIND-SET操作中,该策略可以使查找路径中的每个结点直接指向根。路径压缩并不改变任何结点的秩(因为如果每次路径压缩都更新结点的秩这将非常耗时,且没有必要)。
路径压缩:
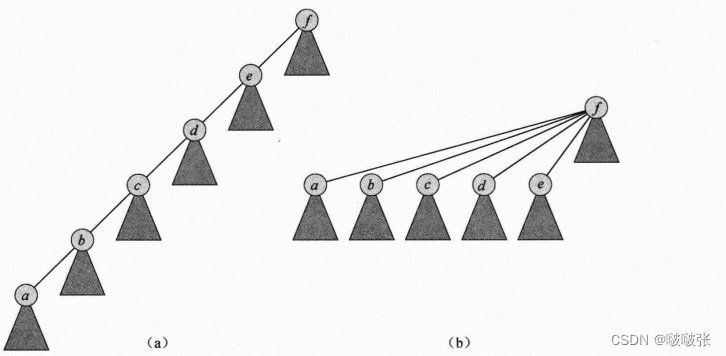
伪代码(代表高度的一个上界,每个FIND-SET操作不改变任何秩。UNION操作有两种情况:如果根没有相同的秩,则让较大秩的根成为较小秩的根的父结点,但秩本身保持不变;如果两个根有相同的秩,任选其中一个根为另一个根的父结点,并使其秩加1.):


解释:FIND-SET过程是一种两趟方法:当它递归时,第一趟沿着查找路径向上直到找到根,当递归回溯时,第二趟沿着搜索树向下更新查找路径上每个结点,使其直接指向根。
时间复杂度:当同时使用按秩合并和路径压缩时,平均情况下,MAKE-SET:;FIND-SET:
;UNION:
(函数
取值如下表)。最坏情况的总运行时间为
,其中
是增长非常缓慢的函数,在实际应用中我们可以认为
。因此可以认为运行时间是
的线性函数。
| x | lg* x |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |


















 195
195




 到【灌水乐园】发言
到【灌水乐园】发言







