







 本文介绍了如何通过Python脚本,结合pytest和xToolkit工具,从Excel表格中读取测试数据,进行参数化请求,以及处理跨接口的提取参数。文章详细描述了构建测试用例、数据准备、使用eval转换数据格式和allure生成测试报告的过程。
本文介绍了如何通过Python脚本,结合pytest和xToolkit工具,从Excel表格中读取测试数据,进行参数化请求,以及处理跨接口的提取参数。文章详细描述了构建测试用例、数据准备、使用eval转换数据格式和allure生成测试报告的过程。
一、构建思路
1.1测试用例化为接口数据存于Excel表格,请求的构建与发送用python代码实现,通过xToolkit来读取表格数据,将读取到的数据转化为列表格式(转化为列表),然后循环调用遍历发送请求。由于一般代码执行会遇到出现错误就停止的情况,引入pytest参数化机制,自动循环DDT。


二、构建测试数据
2.1 excel---使用xToolkit
根据请求具体内容,在Excel中构建如下表头数据 。如需使用xToolkit来读取表的数据,注意后缀最好为xls,且要注意使用的办公软件,xToolkit的支持者暂时只提供office2006的维护,所以要么直接一直用office2006,要么用office2006构建之后再用WPS进行修改,或者在WPS新建表格的时候保存格式就选xls,这样可以尽量避免不可读此表的报错。当然request不止这些参数,按需构建就行。如下是部分参数说明。(可以通过pycharm中写一个request方法,然后Ctrl+鼠标左键,查看此函数详细说明)

表中数据需要按图示填写,因为request请求参数要么为None(不是NULL,也不是''),要么有值。

2.2 excel拓展 ---使用openpyxl
由于 xToolkit局限性,一般适用于读取Excel,如果需要修改表格,可以选用openpyxl。这个插件适合后缀xlsx的表格。
由于python版本限制,可以选择合适自己的 openpyxl版本,在此选用openpyxl3.1.3。
目标:
可以用于自动化脚本测试完成后,断言比较预期结果,填入实际结果,实际结果与预期不一致可以填充颜色以示区分。下面只举个简单例子,在实际结果填入对应行数,对偶数的实际结果填充一个颜色。结果如下图:
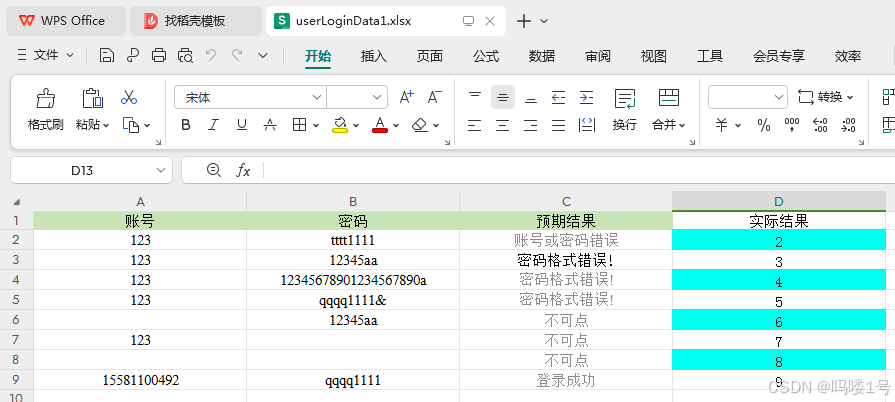
开始前:
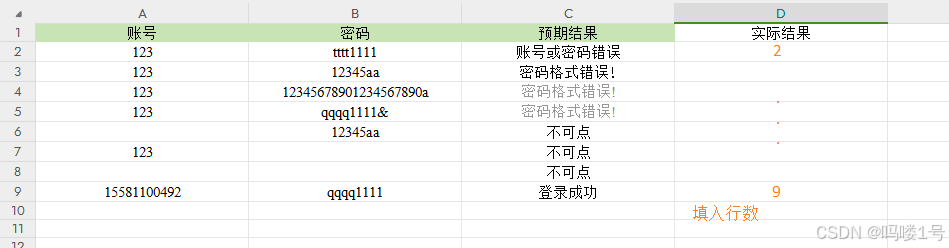
简单使用可以参考博文:
Python处理Excel_python sheet.cell-优快云博客
import openpyxl
from openpyxl import workbook
from openpyxl.styles import *
# 工作簿
wb = openpyxl.load_workbook("D:/test_demo01/userLoginData.xlsx")
# 工作表
# sheet = wb.get_sheet_by_name("Sheet1")
sheet = wb['Sheet1']
# 单元格
# cell_data = sheet.cell(row=1,column=1).value
for rowNum in range(2,sheet.max_row+1):
real = sheet.cell(row=rowNum,column=4)
real.value = rowNum
#单元格对齐方式--居中
real.alignment=Alignment(horizontal='center')
if rowNum % 2 == 0:
#单元格背景填充色
real.fill = PatternFill(patternType='solid', fgColor ='00FFF0')
# 最后保存文件
wb.save("D:/test_demo01/userLoginData1.xlsx")2.2.1工作簿

2.2.2工作表

2.2.3单元格

2.2.4保存修改

我这个版本要求跟原来的表格区分开,不能保存为一模一样的路径和文件名,只能存为不同Excel文件。 后缀也是xlsx结尾。
三、用xToolkit读取excel数据、pytest参数化构建request请求

shurufazifusheet=0我用WPS打开之后就是这样,实际上软件显示这个表是sheet=1,大家要么的 填显示的,要么就跟列表一样下标从0开始。
@pytest.mark.parametrize 后一般接函数方法。
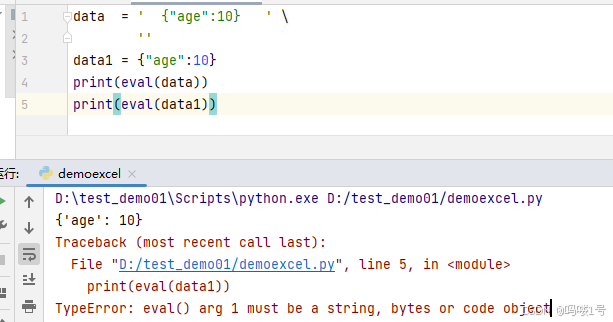
eval函数,会自动按照传参数据格式,格式化掉对应数据,例如:eval('空格空格{“age”:18}换行'),eval会将括号内数据传化为标准JSON格式。因为Excel表格写入JSON等数据时,可能会用到空格或者换行,导致原文识别格式识别不准确,所以用eval。注意:eval无法识别字典对象。
request的常用四个参数都给值,有无参数都传值,实际上没有此参数的,传的是Excel填的none。
加上断言后试试效果: 如下图,断言结果与响应数据的text格式。

此段代码如下:
import requests,pytest
from xToolkit import xfile
#1、读取目标Excel表格,并将其转化为列表
case_list = xfile.read("Book1.xls").excel_to_dict(sheet=0)
#2、eval按照填的数据格式,自动格式化数据,比如填的JSON格式,自动转化为JSON数据
#pytest参数化,自动循环执行
@pytest.mark.parametrize("case_dict",case_list)
#参数化后最好在下面定义一个方法
def test_case_excel(case_dict):
res=requests.request(url= case_dict.get("接口URL"),
method=case_dict.get("请求方式"),
params=eval(case_dict.get("URL参数")), # 字典/字节序列,作为参数增加到URL中
data=eval(case_dict.get("JSON参数"))
)
assert res.status_code ==case_dict.get("预期状态码")
print(res.text)四、如何应对上个请求的响应结果里有这个请求需要的查询参数? (如token又称提取参数)

类似如下情况:
 接口1中响应参数有个token(提取参数),token也是接口2URL中的查询参数(需要参数)
接口1中响应参数有个token(提取参数),token也是接口2URL中的查询参数(需要参数)
构建顺序理解:1、提取全局变量修改部分URL 。2、发起请求。3、对将提取参数存入全局变量。
参数化内按照表格列顺序编写。
4.1新建一个文件用于存放对象,构建一个类,类中定义空字典,定义如下三个方法

#设置一个类,到时候实例化对象用来储存提取参数的值
class g_var(object):
_globar_dict={}
#只能改变key的值,不能改key名
def set_dict(self,key,value):
self._globar_dict[key] = value
# self._globar_dict.get(key) =value,get方法不可用于修改key值,所以会报错
def get_dict_value(self,key):
return self._globar_dict.get(key)
def show_dict(self):
return self._globar_dict4.2完善请求前面的处理
from 放置构建的类的py文件 import g_var(类名)

from string import Template引入Template库,Template用法如下:

4.3完善请求后面的处理


jsonpath语法如下图:$..能读多层嵌套的json,由于使用jsonpath后会读取到很多相似的目标内容组成的数组,所以jsonpath读取要越精确越好,我们只取第0号元素,一般来说最精确。
4.4响应报文很长,如何做断言对比--deepdiff



![]()
结果更好看。
五、全段代码
5.1接口主代码
import pytest
from xToolkit import xfile
import requests
import jsonpath
from script.script.gobal_value import g_var
from string import Template
# python读取Excel库
#1、读取目标Excel表格,并将其转化为列表
case_list = xfile.read("Book1.xls").excel_to_dict(sheet=0)
print(case_list)
print("--------------")
print(case_list[0].get("用例编号"))
#2、eval按照填的数据格式,自动格式化数据,比如填的JSON格式,自动转化为JSON数据
#pytest参数化,自动循环执行
@pytest.mark.parametrize("case_dict",case_list)
def test_excel_case_(case_dict):
#初始化/修改url值,通过存贮对象
url = case_dict.get("接口URL")
dict = g_var().show_dict()
url_ = Template(url).substitute(dict)
res = requests.request(url=url_,
method=case_dict.get("请求方式"),
params=eval(case_dict.get("URL参数")), #字典/字节序列,作为参数增加到URL中
data=eval(case_dict.get("JSON参数")) #字典/字节序列/文件对象,作为request的内容
)
#修改dict/填入dict值,数据来源是提取参数(上个接口返回的token),提取参数来源就是case_dict
if case_dict.get("提取参数") != None or case_dict["提取参数"] != '':
list_ = jsonpath.jsonpath(res.json(), '$..'+case_dict.get("提取参数")) #['token值']
g_var().set_dict(case_dict.get("提取参数"), list_[0])
assert res.status_code ==case_dict.get("预期状态码")
# if __name__ == '__main__':
# pytest.main(['-vs','--capture=sys'])
5.2构建类的主代码
#设置一个类,到时候实例化对象用来储存提取参数的值
class g_var(object):
_globar_dict={}
#只能改变key的值,不能改key名
def set_dict(self,key,value):
self._globar_dict[key] = value
# self._globar_dict.get(key) =value,get方法不可用于修改key值,所以会报错
def get_dict_value(self,key):
return self._globar_dict.get(key)
def show_dict(self):
return self._globar_dict六、接上如下代码利用allure生成测试报告(allure要安装好必备软件包和在线模板):

6.1无法生成报告及生成报告为0和NaN%的解决方案:
如果确认代码没问题,但一直没有新的文件夹(如allure-results)生成:修改python设置中Testing默认的pytest ,改成Unittests ,再次运行__main__,报告即可生成。

6.2找到放置测试报告的目录下的index.html,用浏览器打开即可


if __name__ =='__main__':
pytest.main(['-s','-v','-q','--capture=sys','Test_ExcelCase.py','--clean-alluredir','--alluredir=allure-results'])
os.system(r"allure generate -c -o 测试报告")6.3要想把报告步骤变得更细可以在测试用例中加上allure.step()
参考博文:(二)pytest自动化测试框架之添加测试用例步骤(@allure.step())-优快云博客



















 5884
5884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









