



Pandas的stack和pivot实现数据透视
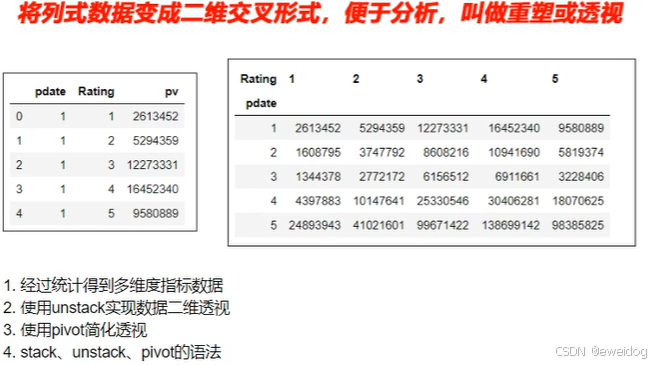
- 经过统计得到多维度指标数据
- 非常常见的统计场景,指定多个维度,计算聚合后的指标
案例:统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份,分数1-5,次数)
import pandas as pd
import numpy as np
# 文件路径
file_path = r'C:\TELCEL_MEXICO_BOT\A\rating.csv'
df = pd.read_csv(file_path, sep=',')
print(df)
UserId MovieId Rating Timestamp
0 张三 104 6 978300760
1 张三 120 7 225689358
2 张三 136 4 689893028
3 张三 152 7 669503982
4 李四 168 5 978323894
5 李四 184 3 795889870
6 李四 208 4 965325698
7 李四 240 0 886669835
8 王五 272 9 668956290
9 王五 304 5 978824291
10 王五 336 4 866679835
11 王五 368 8 598308921
12 赵六 400 9 885986792
13 赵六 432 9 868795863
df['pdata'] = pd.to_datetime(df['Timestamp'],unit='s')
print(df)
UserId MovieId Rating Timestamp pdata
0 张三 104 6 978300760 2000-12-31 22:12:40
1 张三 120 7 225689358 1977-02-25 03:29:18
2 张三 136 4 689893028 1991-11-11 20:57:08
3 张三 152 7 669503982 1991-03-20 21:19:42
4 李四 168 5 978323894 2001-01-01 04:38:14
5 李四 184 3 795889870 1995-03-22 16:31:10
6 李四 208 4 965325698 2000-08-03 18:01:38
7 李四 240 0 886669835 1998-02-05 09:10:35
8 王五 272 9 668956290 1991-03-14 13:11:30
9 王五 304 5 978824291 2001-01-06 23:38:11
10 王五 336 4 866679835 1997-06-19 00:23:55
11 王五 368 8 598308921 1988-12-16 20:55:21
12 赵六 400 9 885986792 1998-01-28 11:26:32
13 赵六 432 9 868795863 1997-07-13 12:11:03
print(df.dtypes)
UserId object
MovieId int64
Rating int64
Timestamp int64
pdata datetime64[ns]
dtype: object
df_group = df.groupby([df['pdata'].dt.month, 'Rating'])['UserId'].agg(pv=np.sum)
print(df_group)
pv
pdata Rating
1 5 李四王五
9 赵六
2 0 李四
7 张三
3 3 李四
7 张三
9 王五
6 4 王五
7 9 赵六
8 4 李四
11 4 张三
12 6 张三
8 王五
对这样格式的数据,要查看按月份,不同评分的次数趋势是没法实现的
需要将数据变换成每个评分是一列才可以实现
2. 使用unstack实现数据二维透视,目的想要画图对比不同月份的不同评分数据趋势
import pandas as pd
import numpy as np
# 文件路径
file_path = r'C:\TELCEL_MEXICO_BOT\A\rating.csv'
df = pd.read_csv(file_path, sep=',')
print(df)
UserId MovieId Rating Timestamp
0 张三 104 6 978300760
1 张三 120 7 225689358
2 张三 136 4 689893028
3 张三 152 7 669503982
4 李四 168 5 978323894
5 李四 184 3 795889870
6 李四 208 4 965325698
7 李四 240 0 886669835
8 王五 272 9 668956290
9 王五 304 5 978824291
10 王五 336 4 866679835
11 王五 368 8 598308921
12 赵六 400 9 885986792
13 赵六 432 9 868795863
df['pdata'] = pd.to_datetime(df['Timestamp'],unit='s') ## 新加一列pdata以Timestamp改变
print(df)
UserId MovieId Rating Timestamp pdata
0 张三 104 6 978300760 2000-12-31 22:12:40
1 张三 120 7 225689358 1977-02-25 03:29:18
2 张三 136 4 689893028 1991-11-11 20:57:08
3 张三 152 7 669503982 1991-03-20 21:19:42
4 李四 168 5 978323894 2001-01-01 04:38:14
5 李四 184 3 795889870 1995-03-22 16:31:10
6 李四 208 4 965325698 2000-08-03 18:01:38
7 李四 240 0 886669835 1998-02-05 09:10:35
8 王五 272 9 668956290 1991-03-14 13:11:30
9 王五 304 5 978824291 2001-01-06 23:38:11
10 王五 336 4 866679835 1997-06-19 00:23:55
11 王五 368 8 598308921 1988-12-16 20:55:21
12 赵六 400 9 885986792 1998-01-28 11:26:32
13 赵六 432 9 868795863 1997-07-13 12:11:03
print(df.dtypes)
serId object
MovieId int64
Rating int64
Timestamp int64
pdata datetime64[ns]
dtype: object
df_group = df.groupby([df['pdata'].dt.month, 'UserId'])['Rating'].agg(pv=np.sum)
print(df_group)
pv
pdata UserId
1 李四 5
王五 5
赵六 9
2 张三 7
李四 0
3 张三 7
李四 3
王五 9
6 王五 4
7 赵六 9
8 李四 4
11 张三 4
12 张三 6
王五 8
df_stack = df_group.unstack() ## unstack这种可以画线
print(df_stack)
pv
UserId 张三 李四 王五 赵六
pdata
1 NaN 5.0 5.0 9.0
2 7.0 0.0 NaN NaN
3 7.0 3.0 9.0 NaN
6 NaN NaN 4.0 NaN
7 NaN NaN NaN 9.0
8 NaN 4.0 NaN NaN
11 4.0 NaN NaN NaN
12 6.0 NaN 8.0 NaN
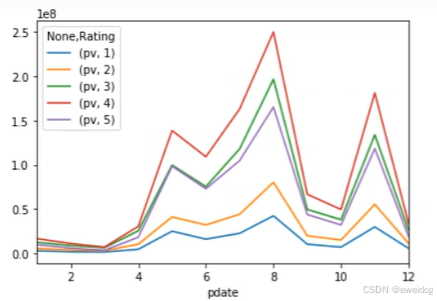
3. 使用pivot简化透视, pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
import pandas as pd
import numpy as np
# 文件路径
file_path = r'C:\TELCEL_MEXICO_BOT\A\rating.csv'
df = pd.read_csv(file_path, sep=',')
print(df)
UserId MovieId Rating Timestamp
0 张三 104 6 978300760
1 张三 120 7 225689358
2 张三 136 4 689893028
3 张三 152 7 669503982
4 李四 168 5 978323894
5 李四 184 3 795889870
6 李四 208 4 965325698
7 李四 240 0 886669835
8 王五 272 9 668956290
9 王五 304 5 978824291
10 王五 336 4 866679835
11 王五 368 8 598308921
12 赵六 400 9 885986792
13 赵六 432 9 868795863
df['pdata'] = pd.to_datetime(df['Timestamp'],unit='s')
print(df)
UserId MovieId Rating Timestamp pdata
0 张三 104 6 978300760 2000-12-31 22:12:40
1 张三 120 7 225689358 1977-02-25 03:29:18
2 张三 136 4 689893028 1991-11-11 20:57:08
3 张三 152 7 669503982 1991-03-20 21:19:42
4 李四 168 5 978323894 2001-01-01 04:38:14
5 李四 184 3 795889870 1995-03-22 16:31:10
6 李四 208 4 965325698 2000-08-03 18:01:38
7 李四 240 0 886669835 1998-02-05 09:10:35
8 王五 272 9 668956290 1991-03-14 13:11:30
9 王五 304 5 978824291 2001-01-06 23:38:11
10 王五 336 4 866679835 1997-06-19 00:23:55
11 王五 368 8 598308921 1988-12-16 20:55:21
12 赵六 400 9 885986792 1998-01-28 11:26:32
13 赵六 432 9 868795863 1997-07-13 12:11:03
df_group = df.groupby([df['pdata'].dt.month, 'UserId'])['Rating'].agg(pv=np.sum)
print(df_group)
pv
pdata UserId
1 李四 5
王五 5
赵六 9
2 张三 7
李四 0
3 张三 7
李四 3
王五 9
6 王五 4
7 赵六 9
8 李四 4
11 张三 4
12 张三 6
王五 8
df_rest = df_group.reset_index()
print(df_rest)
pdata UserId pv
0 1 李四 5
1 1 王五 5
2 1 赵六 9
3 2 张三 7
4 2 李四 0
5 3 张三 7
6 3 李四 3
7 3 王五 9
8 6 王五 4
9 7 赵六 9
10 8 李四 4
11 11 张三 4
12 12 张三 6
13 12 王五 8
df_pivot = df_rest.pivot(index='UserId', columns='pdata', values='pv')
print(df_pivot)
pdata 1 2 3 6 7 8 11 12
UserId
张三 NaN 7.0 7.0 NaN NaN NaN 4.0 6.0
李四 5.0 0.0 3.0 NaN NaN 4.0 NaN NaN
王五 5.0 NaN 9.0 4.0 NaN NaN NaN 8.0
赵六 9.0 NaN NaN NaN 9.0 NaN NaN NaN
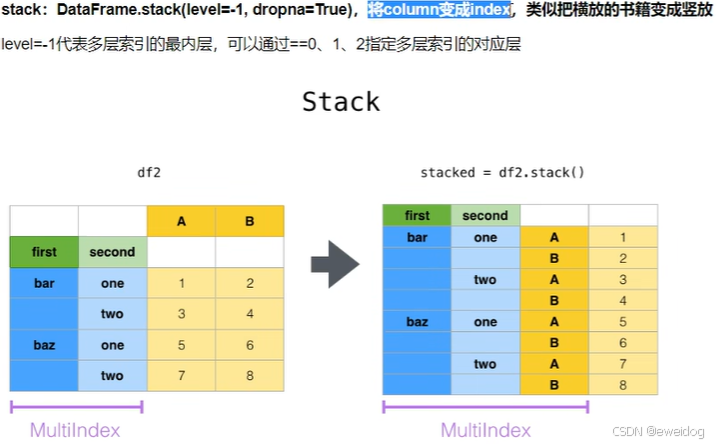
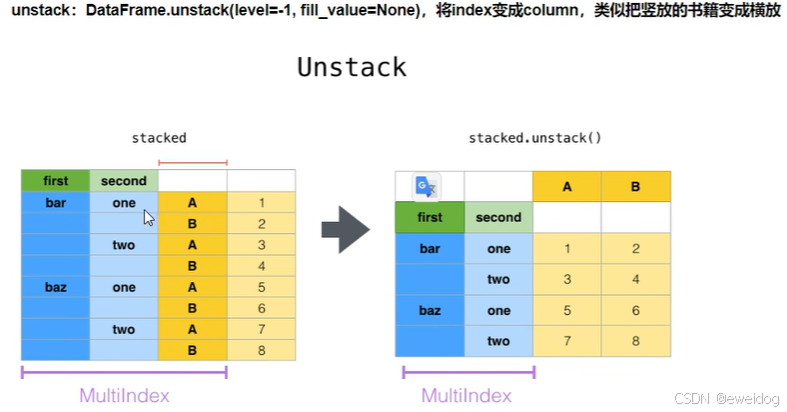
4. stack,unstack,pivot的语法


















 5870
5870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









