




 本文介绍了如何使用Pandas的stack、unstack和pivot方法进行数据透视和可视化。首先展示了如何通过统计计算得到多维度指标数据,接着利用unstack将数据转换为便于分析的二维透视表,最后通过pivot简化透视过程。通过实例详细解释了这三个方法的用法,便于理解数据透视和绘制数量趋势图。
本文介绍了如何使用Pandas的stack、unstack和pivot方法进行数据透视和可视化。首先展示了如何通过统计计算得到多维度指标数据,接着利用unstack将数据转换为便于分析的二维透视表,最后通过pivot简化透视过程。通过实例详细解释了这三个方法的用法,便于理解数据透视和绘制数量趋势图。
Pandas 二十:stack和pivot实现数据透视
1.经过统计得到多维度指标数据
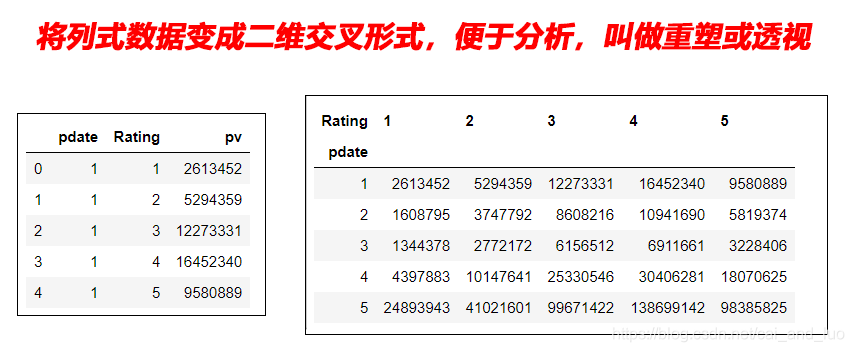
2.使用unstack实现数据二维透视
3.使用pivot简化透视
4.stack、unstack、pivot的语法
1. 经过统计得到多维度指标数据
非常常见的统计场景,指定多个维度,计算聚合后的指标
实例:统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份、分数1~5、次数)
1
import pandas as pd
import numpy as np
%matplotlib inline
No output
2
df = pd.read_csv(
"./datas/movielens-1m/ratings.dat",
header=None,
names="UserID::MovieID::Rating::Timestamp".split("::"),
sep="::",
engine="python"
)
No output
3
df.head()
3
UserID MovieID Rating Timestamp
0 1 1193 5 978300760
1 1 661 3 978302109
2 1 914 3 978301968
3 1 3408 4 978300275
4 1  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5868
5868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









