



直接赋值,apply,assgin,分条件赋值
- pandas怎样新增数据列?
- 在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析
1. 直接赋值
2. df.apply方法
3. df.assgin方法
4. 按条件选择分组分别赋值
import pandas as pd
0. 读取csv数据到dataframe
file_path = r'C:\TELCEL_MEXICO_BOT\A\Weather.csv' df = pd.read_csv(file_path,encoding='utf-8') print(df.head()) #df.head()先读取数据有前5行 ymd bWendu yWendu tianqi fengxiang fengji aqi aqiInfo aqiLevel 0 1/1/2025 -25°C -6°C 晴~多云 西北风 1-2级 59 优 2 1 1/2/2025 2°C -9°C 阴 东南风 3-4级 48 优 1 2 1/3/2025 -11°C -2°C 晴~多云 西风 4-8级 28 良 1 3 1/4/2025 0°C -4°C 晴~多云 东风 2-5级 30 良 1 4 1/5/2025 3°C -1°C 小雨 东风 3-5级 25 良 1
1. 直接赋值的方法
例子:清理温度列,变成数字类型. 修改列数据
- 替换掉温度的后缀°C
- df.loc[:,'bWendu'] 中的 : 表示选择这个df中所有的行,并同时选择bWendu这一列,让它等于温度bWendu这一列的str形式,然后调用str中的replace方法,把字符串后缀°C替换成空,最后转换下它的类型,变成int32
df.loc[:,'bWendu'] = df['bWendu'].str.replace('°C','').astype('int32')
df.loc[:,'yWendu'] = df['yWendu'].str.replace('°C','').astype('int32')
print(df.head()) bWendu yWendu tianqi fengxiang fengji aqi aqiInfo aqiLevel ymd 1/1/2025 -25 -6 晴~多云 西北风 1-2级 59 优 2 1/2/2025 2 -9 阴 东南风 3-4级 48 优 1 1/3/2025 -11 -2 晴~多云 西风 4-8级 28 良 1 1/4/2025 0 -4 晴~多云 东风 2-5级 30 良 1 1/5/2025 3 -1 小雨 东风 3-5级 25 良 1
- 计算温差
- 注意:df['bWendu']其实是一个Series,后面的减法返回的是Series
例子:新增列wencha 等于bWendu减去yWendu
df.loc[:,'wencha'] = df['bWendu'] - df['yWendu']
print(df.head()) bWendu yWendu tianqi fengxiang fengji aqi aqiInfo aqiLevel wencha ymd 1/1/2025 -25 -6 晴~多云 西北风 1-2级 59 优 2 -19 1/2/2025 2 -9 阴 东南风 3-4级 48 优 1 11 1/3/2025 -11 -2 晴~多云 西风 4-8级 28 良 1 -9 1/4/2025 0 -4 晴~多云 东风 2-5级 30 良 1 4 1/5/2025 3 -1 小雨 东风 3-5级 25 良 1 4
2. df.apply方法
例子:添加一列温度类型:
1.如果最高温度大于33度就是高温
2.低于-10度就是低温
3.否则是常温
def get_wendu_type(x):
if x['bWendu'] > 33:
return '高温'
if x['bWendu'] < -10:
return '低温'
return '常温'
#注意需要设置axis==1,这是series的index是columns
df.loc[:,'wendu_type'] = df.apply(get_wendu_type,axis=1)
#查看温度类型的计数
print(df['wendu_type'].value_counts())
常温 14
低温 5
Name: wendu_type, dtype: int64
3. df.assgin方法
例子:将温度从摄氏度变成华氏度
#可以同时添加多个新的列
huashi = df.assign(
yWendu_huashi = lambda x : x['yWendu'] * 9 / 5 + 32,
bWendu_huashi = lambda x : x['bWendu'] * 9 / 5 + 32
)
print(huashi)
bWendu yWendu tianqi ... wendu_type yWendu_huashi bWendu_huashi
ymd ...
1/1/2025 -25 -6 晴~多云 ... 低温 21.2 -13.0
1/2/2025 2 -9 阴 ... 常温 15.8 35.6
1/3/2025 -11 -2 晴~多云 ... 低温 28.4 12.2
1/4/2025 0 -4 晴~多云 ... 常温 24.8 32.0
1/5/2025 3 -1 小雨 ... 常温 30.2 37.4
1/6/2025 10 3 阴 ... 常温 37.4 50.0
1/7/2025 7 -10 阴 ... 常温 14.0 44.6
1/8/2025 -13 -6 小雨 ... 低温 21.2 8.6
1/9/2025 8 -9 晴~多云 ... 常温 15.8 46.4
1/10/2025 3 -2 阵雨 ... 常温 28.4 37.4
1/11/2025 5 -4 阵雨 ... 常温 24.8 41.0
1/12/2025 7 -1 冰 ... 常温 30.2 44.6
1/13/2025 2 -4 冰 ... 常温 24.8 35.6
1/14/2025 -14 -1 霜 ... 低温 30.2 6.8
1/15/2025 7 -9 霜 ... 常温 15.8 44.6
1/16/2025 5 -10 冰 ... 常温 14.0 41.0
1/17/2025 -19 -6 雾 ... 低温 21.2 -2.2
1/18/2025 3 -9 雾 ... 常温 15.8 37.4
1/19/2025 1 -2 雾 ... 常温 28.4 33.8
[19 rows x 12 columns]
4. 按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
例子:高低温度差大于10度,则认为温差大
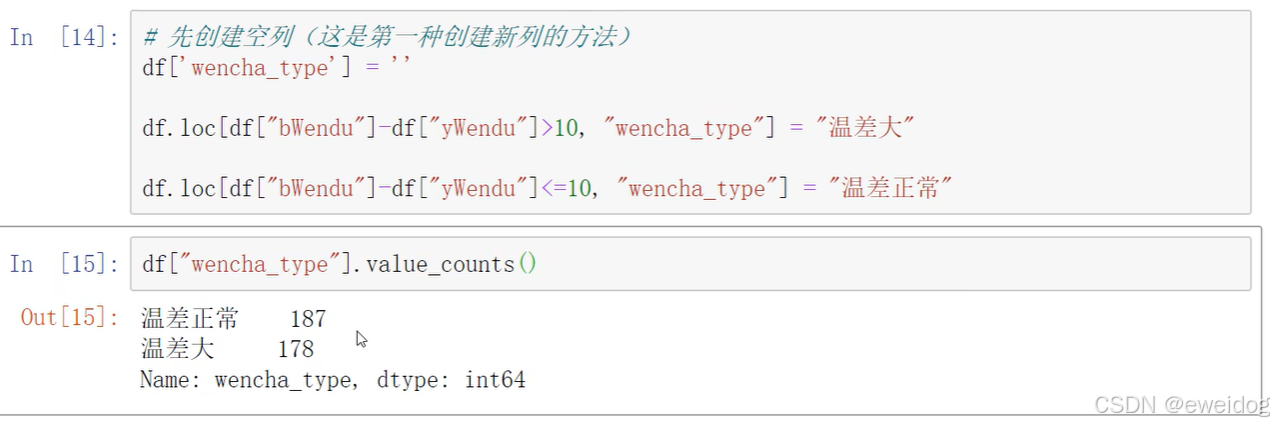

















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









