







一.特点
1.存取无序
2.键和值都可以是null,但是键只能有一个null
3.键位置是唯一的,底层的数据结构控制键
4.jdk1.8之前的数据结构是:链表+数组 ,jdk1.8之后又加上了红黑树来加速查询
5.使用红黑树的阈值是:1.数组的长度大于64. 2链表的长度大于8.
二.HashMap集合底层数据结构
jdk1.8之前的数据结构是:链表+数组 ,jdk1.8之后又加上了红黑树来加速查询。
当创建HashMap集合对象的时候,在jdk8之前,构造方法中创建一个长度为16的Entry[] table 用来存储键值对数据。在jdk8以后不是在HashMap的构造方法底层创建数组,是在第一次调用put方法时创建的数组,Node[] table用来存储键值对数据,类似Entry[] table。
计算流程
HashMap<String, Integer> HM = new HashMap<>();
HM.put("张三", 10);
HM.put("李四", 20);
HM.put("王五", 30);当向HashMap中添加数据时,会使用String类重写的HashCode()方法计算出哈希值,然后结合数组长度采用某种算法计算出向Node数组中存储数据的空间的索引值。如果计算出的索引空间没有数据(没有哈希冲突),则直接将键值对存储在数组中。
HashMap底层计算哈希值的算法:
1.调用Key对象的hashCode方法计算出key的hashcode
2.hashcode无符号右移16位(>>>,左边补16个0)与原hashcode进行异或操作。(具体原因文章最后有解释)
3.第二步中得到的异或结果与数组长度-1进行按位与运算(&),得到最终的索引位置
其他的可以采用的计算哈希值的方法:平方取中法,伪随机数法,取余法。(方法效率低没有被采用,取余数计算在底层是通过不断减实现,计算比较慢被淘汰。位运算对于计算机来说计算效率高)
HashCode():当两对象是相等的,那么在两个对象中的每个对象调用HashCode方法的返回值都是相同的整数结果。当equals方法被重写时,通常有必要重写hashCode方法,以维护hashCode方法的常规协定(相等的对象必须有相等的哈希值).
HashMap存储过程:
两个键对应的Node索引位置相同(当一个键值对已经存入HashMap),这时比较两键通过hashCode方法得到的hashcode是否相等(在重写了equals和hashCode两方法后,hashcode不相等等同于equals为false),不等则会在Node存储空间位置开辟出一个节点位置存储新来的键值对,并用单向链表形式存储,当链表长度大于8且数组长度大于64时,采用红黑树存储结构优化查询效率。

HM.put("张三", 20);当重新插入一个"张三"时,则必然会发生哈希冲突,由于String对象值相等则对应的hashcode也相等,此时需要调用String类的equals方法比较两个值是否相等,相等则将后添加的"张三"对应的value覆盖前面的value,体现到例子中为 10->20。不相等的情况下则可判定为新数据,则创建新节点存储即可。(值不同的对象hashcode值是有冲突的可能的,由于hashCode是将地址映射到一个int类型的值,即64位映射到32位,虽然概率比较小但有可能发生碰撞,所以当hashcode发生冲突时继续使用equals方法判断键是否相同是有必要的)

关于String类hashCode和equals方法,可类比到其他类:
1.不同值的对象hashcode不一定不相等,equals一定为false
2.相同值的对象hashcode一定相等,equals一定为true
3.hashcode不相等的两对象值一定不相等,equals一定为false
4.hashcode相等两对象值不一定相等,需要equals进一步判断
HashMap底层源码的一些知识:
1.为什么初始化数组长度以及扩容时数组长度均为2的n次幂?
在分配数组的长度length为2的n次幂的情况下,hash%length=hash&(length-1) ,可以实验一下,由于(2的n次幂-1)低位全是1,&运算可以将地位提出来即为余数,高位全为0,最后的结果即为余数。如果不为2的n次幂,&运算计算出的结果非常容易发生冲突,所以数组通常采用2的n次幂(初始化数组长度为16),结合了取余和位运算的优点,效率和减少冲突兼得,源码如下:

2.初始化HashMap时直接传入初始化的容量不为2的n次幂会发生什么?
会创建一个大于初始化参数的最小的2的n次幂的容量大小的数组
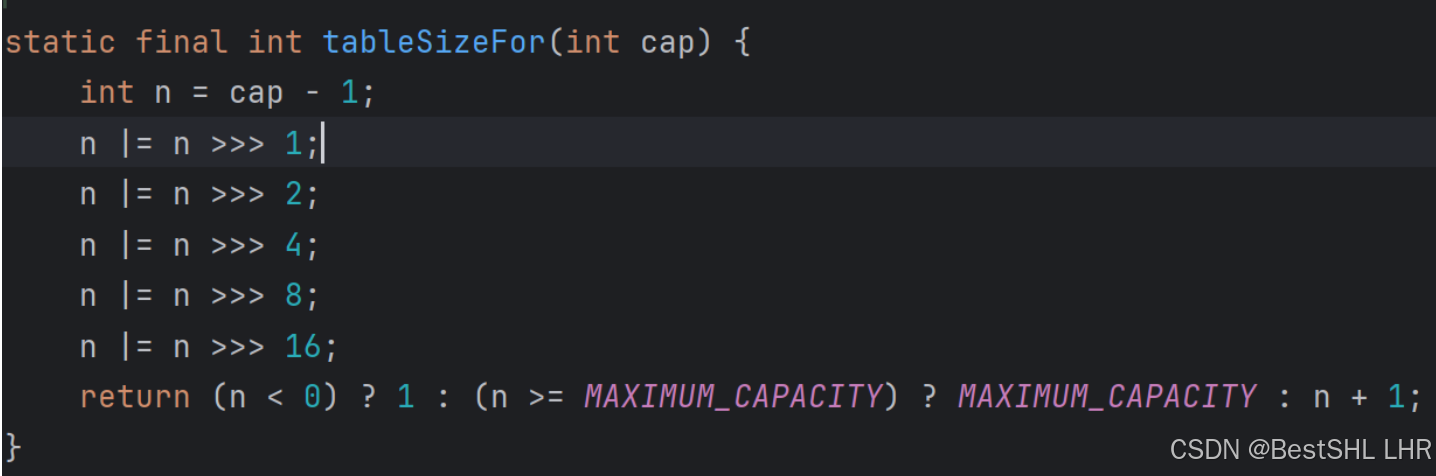
经过上面的操作可以得到一个从给出的初始值的最高位1开始一直到最低为都是1的值,最后返回的时候再+1即得到大于初始值的最小的2的n次幂。

3.Node 数组的结构?
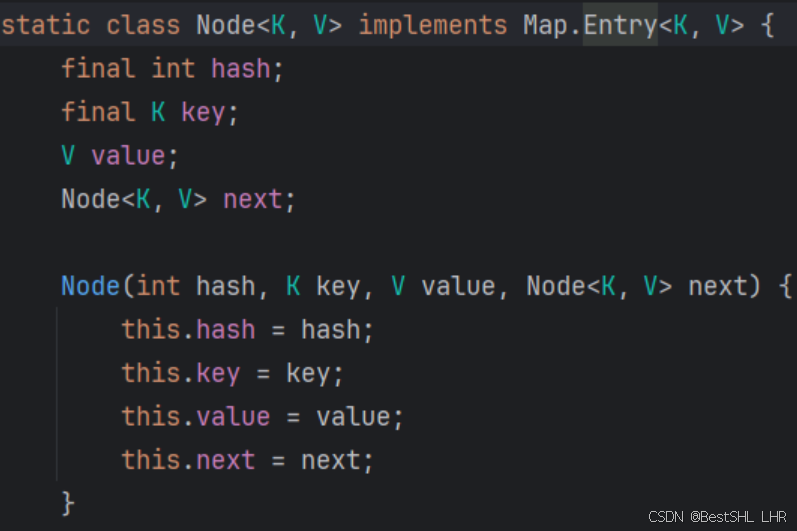
implements了Map.Entry<K, V>,Node就是HashMap数组的组织结构。
4.为什么在哈希映射到数组中时,要先无符号右移16位再异或,最后进行&(数组length-1)(即取余)操作?
以下是我在网上找的一些答案,有大神可以在评论区补充:
由于数组的长度通常小于等于2^16,hashcode是一个int类型32位,故若直接用hashcode进行&(数组length-1)(即取余)操作,只会将低16位hashcode的区别引入到余数中,容易造成数据分布不均衡,无符号右移16位异或后能将高16位的不同和低16位的不同均引入低16位中,增加了低16位的多样性,再映射到数组中的时候数据分布更均衡。
5.为什么在putMapEntries方法中”float ft = ((float)s / loadFactor) + 1.0F“要+1?
putMapEntries方法是将一个HashMap直接赋值给新建的HashMap调用的初始化方法,问题中这行代码+1的主要作用是避免因初始化数组长度过短,造成多次扩容,扩容是比较费时的操作。

















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









