







Scrapy爬虫框架介绍
-
文档
-
什么是scrapy
基于
twisted搭建的异步爬虫框架.scrapy爬虫框架根据组件化设计理念和丰富的中间件, 使其成为了一个兼具高性能和高扩展的框架
-
scrapy提供的主要功能
- 具有优先级功能的调度器
- 去重功能
- 失败后的重试机制
- 并发限制
- ip使用次数限制
- …
-
scrapy的使用场景
- 不适合scrapy项目的场景
- 业务非常简单, 对性能要求也没有那么高, 那么我们写多进程, 多线程, 异步脚本即可.
- 业务非常复杂, 请求之间有顺序和失效时间的限制.
- 如果你不遵守框架的主要设计理念, 那就不要使用框架
- 适合使用scrapy项目
- 数据量大, 对性能有一定要求, 又需要用到去重功能和优先级功能的调度器
- 不适合scrapy项目的场景
-
scrapy组件
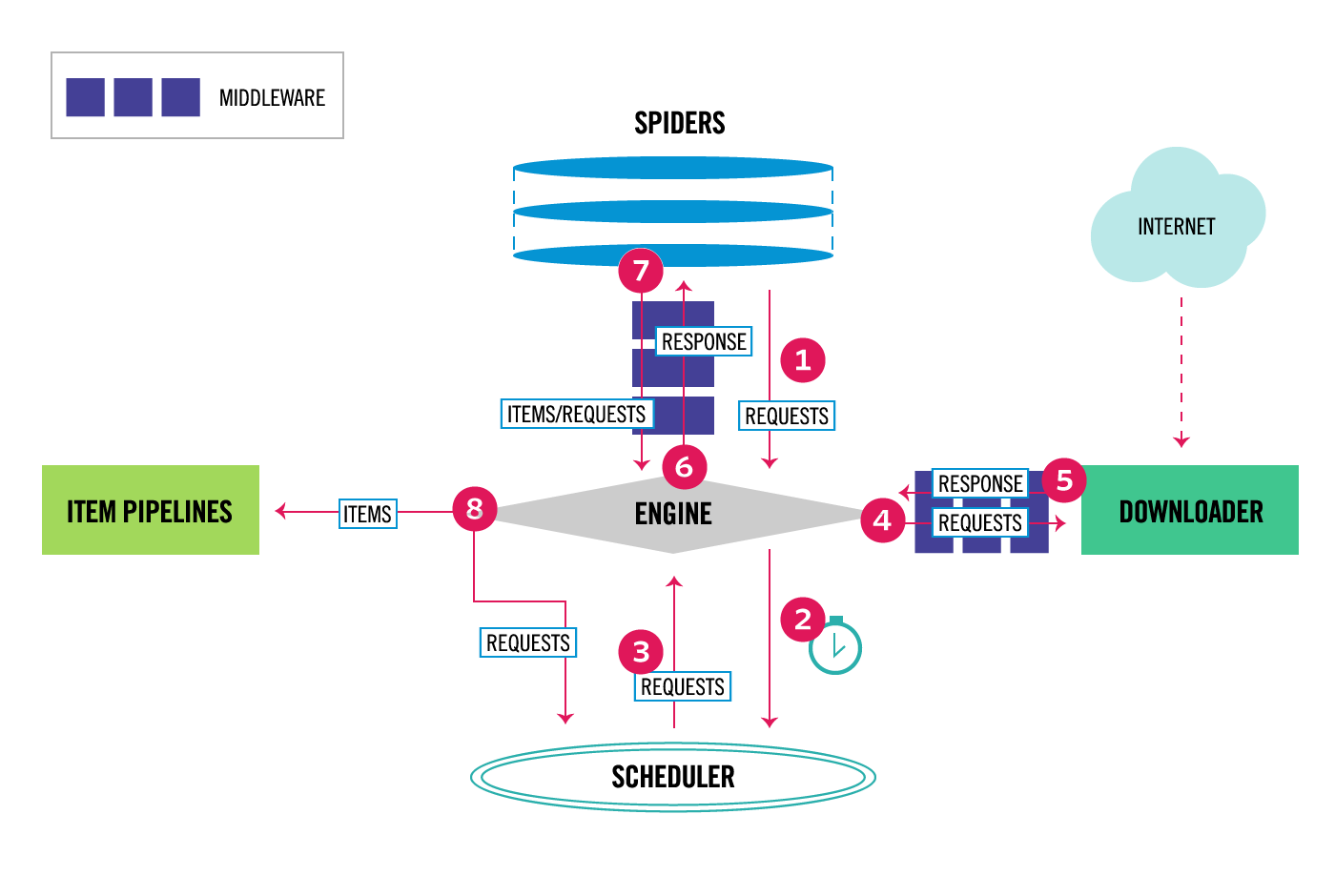
ENGINE从SPIDERS中获取初始请求任务RequestsENGINE得到Requests之后发送给SCHEDULER,SCHEDULER对请求进行调度后产出任务.Scheduler返回下一个请求任务给ENGINEENGINE将请求任务交给DOWNLOADER去完成下载任务, 途径下载器中间件.- 一旦下载器完成请求任务, 将产生一个
Response对象给ENGINE, 途径下载器中间件 ENGINE收到Response对象后, 将该对象发送给SPIDERS去解析和处理, 途径爬虫中间件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5446
5446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









