









无类型的转换算子
-
以下算子有@Test的前置条件
// 1. 创建SparkSession val spark = SparkSession.builder() .appName("trans_test") .master("local[6]") .getOrCreate() // 导入隐式转换 import spark.implicits._ // case样例类 case class Person(name: String, age: Int)
选择
- 选择
-
select
select 用来选择某些列出现在结果集中
@Test def select(): Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // select from .. // from ..select .. //在Dataset中,select可以在任何位置调用 // select ds.select('name).show() }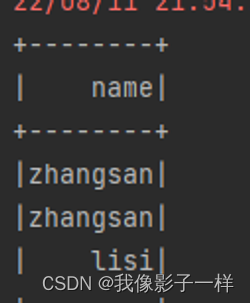
-
selectExpr
在 SQL 语句中, 经常可以在 select 子句中使用 count(age), rand() 等函数, 在 selectExpr 中就可以使用这样的 SQL 表达式, 同时使用 select 配合 expr 函数也可以做到类似的效果
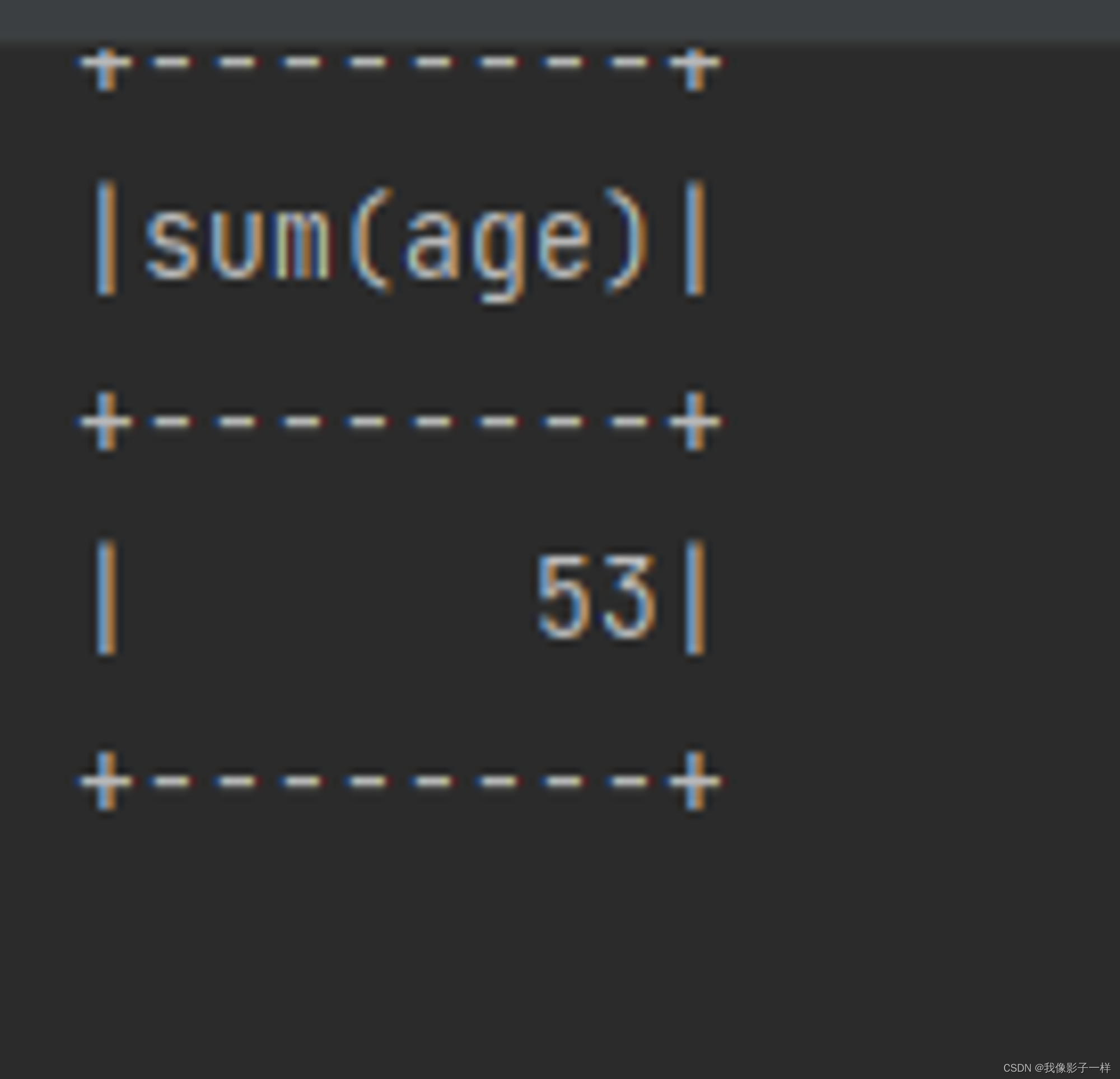
@Test def select(): Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // **selectExpr** ds.selectExpr("sum(age)").show() println("----------------") // select count(*) import org.apache.spark.sql.functions._ ds.select(expr("sum(age)")).show() }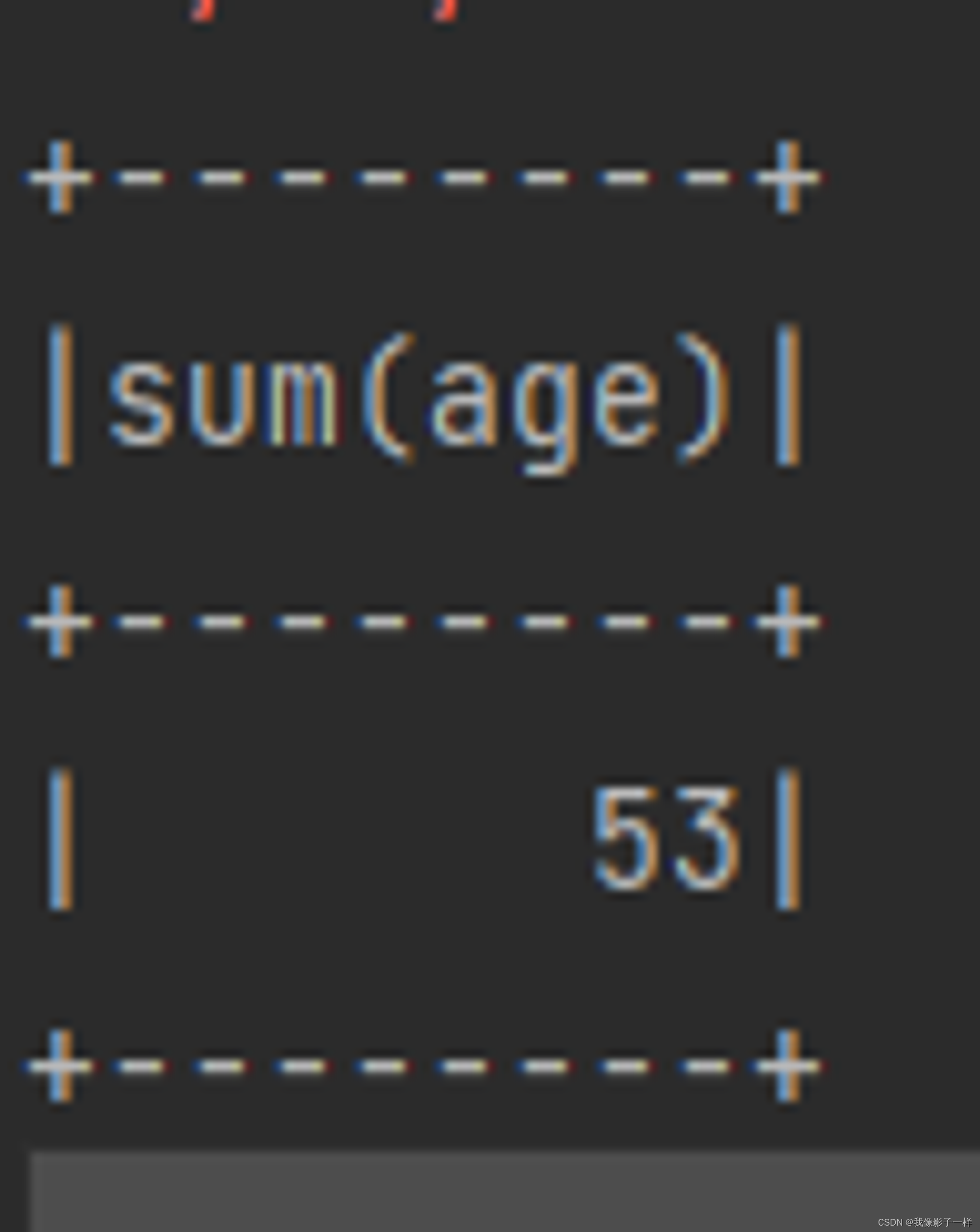
-
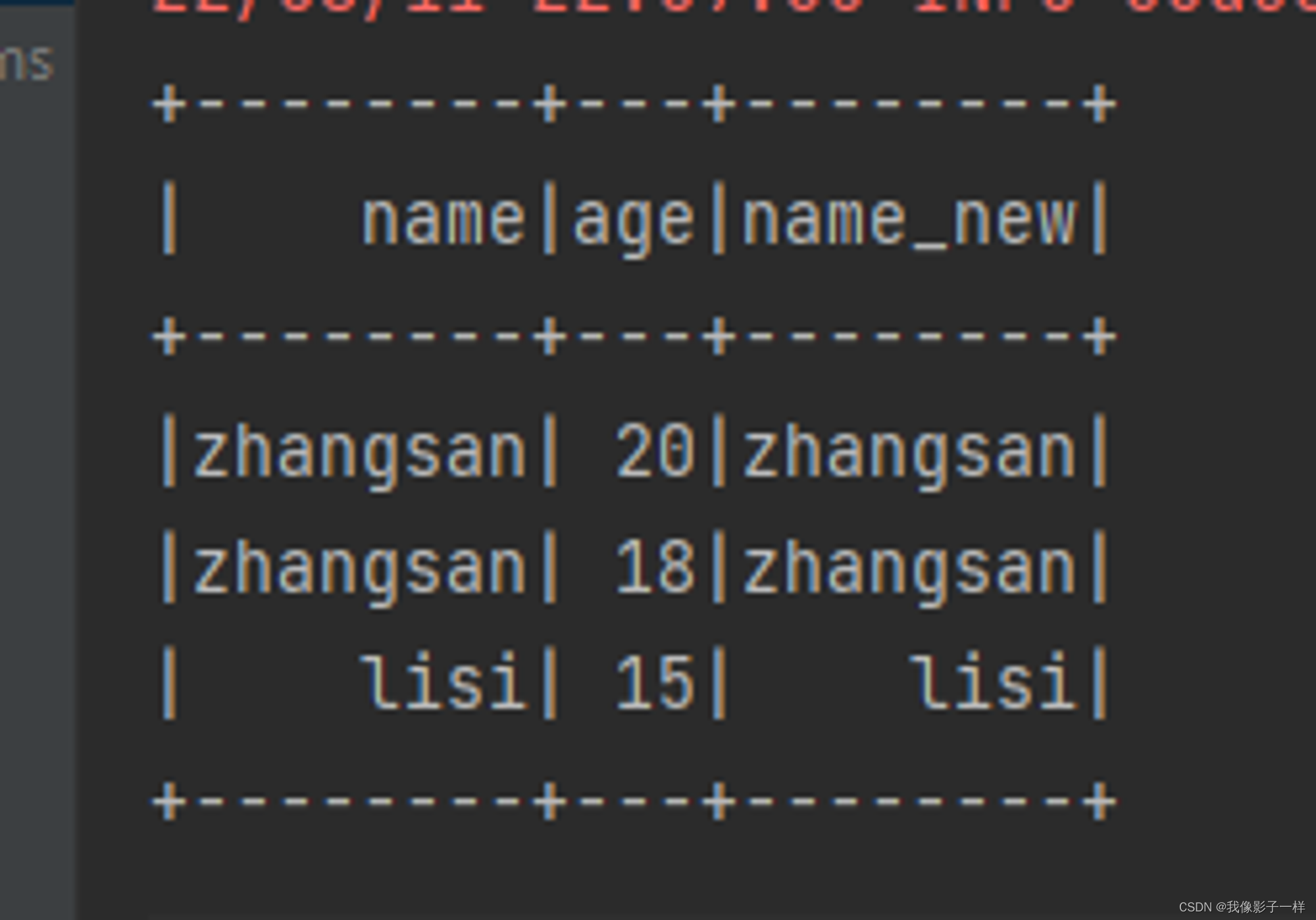
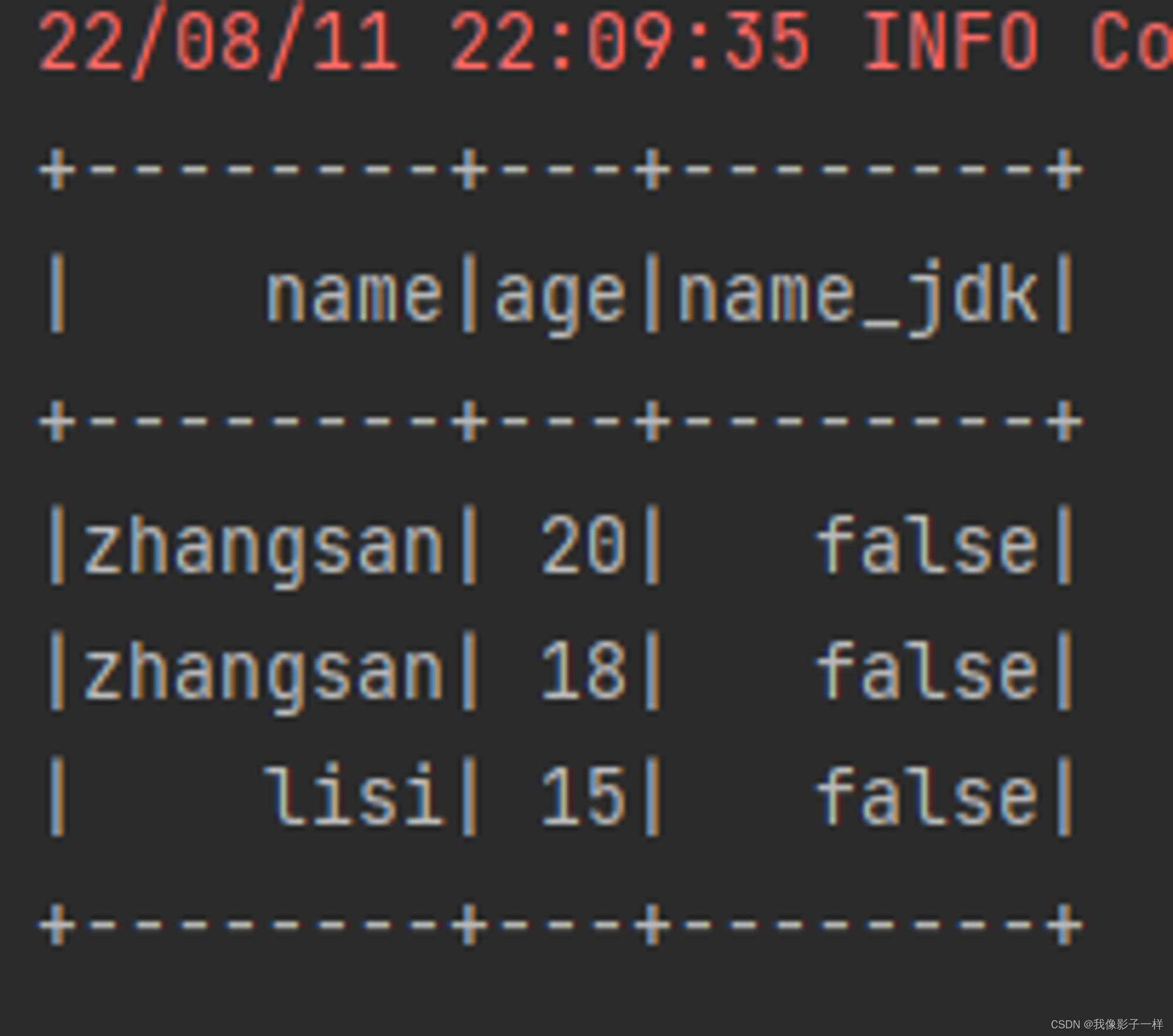
withColumn (新增列或修改列名)
通过 Column 对象在 Dataset 中创建一个新的列或者修改原来的列
@Test def column(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS //如果想使用函数功能 //1.使用functions.xx //2.使用表达式,可以使用expr("..."),随时随地编写表达式 // import org.apache.spark.sql.functions._ ds.withColumn("random",expr("rand()")).show() ds.withColumn("name_new",'name).show() ds.withColumn("name_jdk",'name === "" ).show() // 返回true 或 false }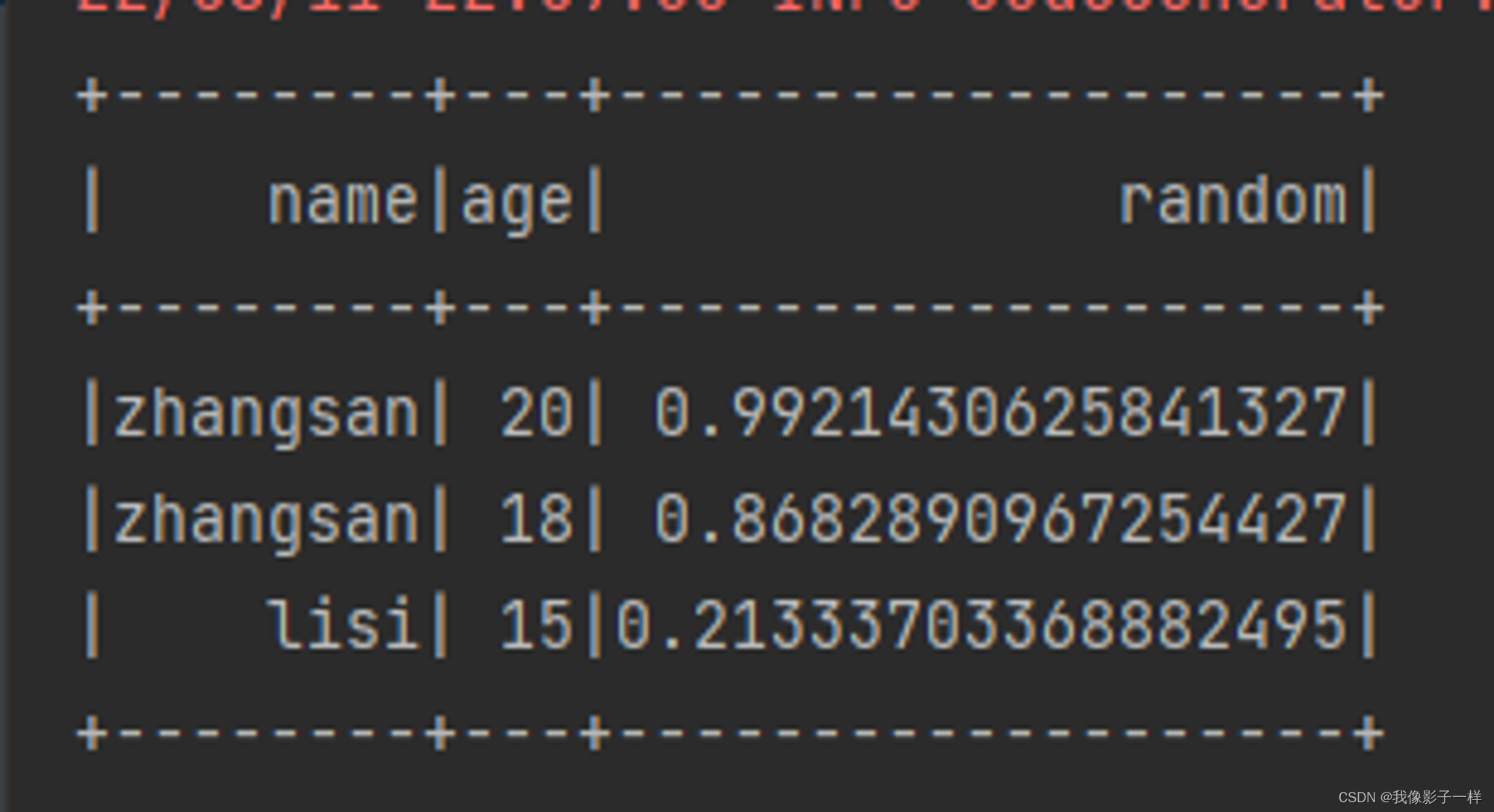
-
withColumnRenamed(修改列名)
修改列名
def column(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS ds.withColumnRenamed("name","new_name").show() }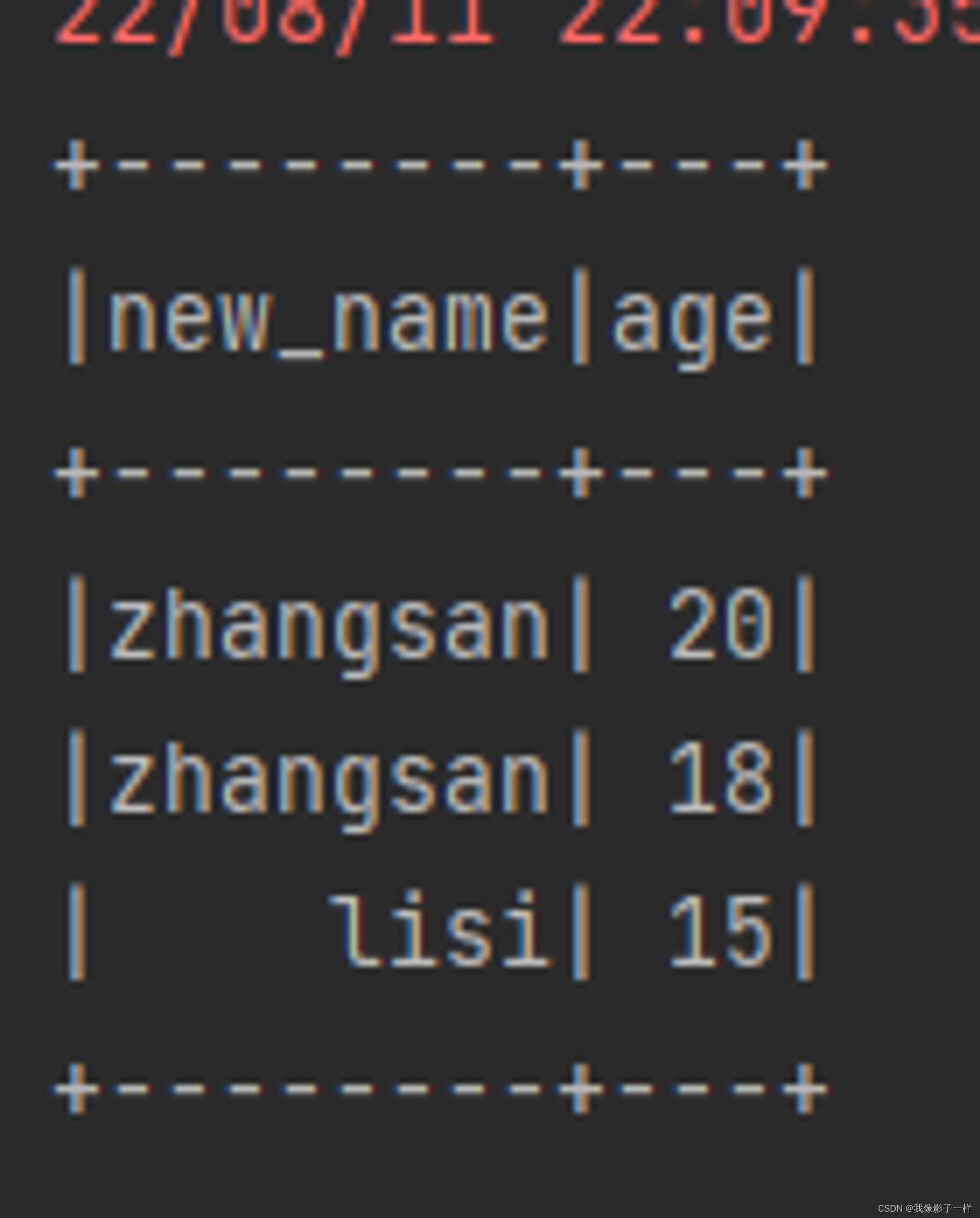
-
剪除 drop
-
剪除 drop
剪掉某个列
@Test def drop(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // drop ds.drop('age).show() }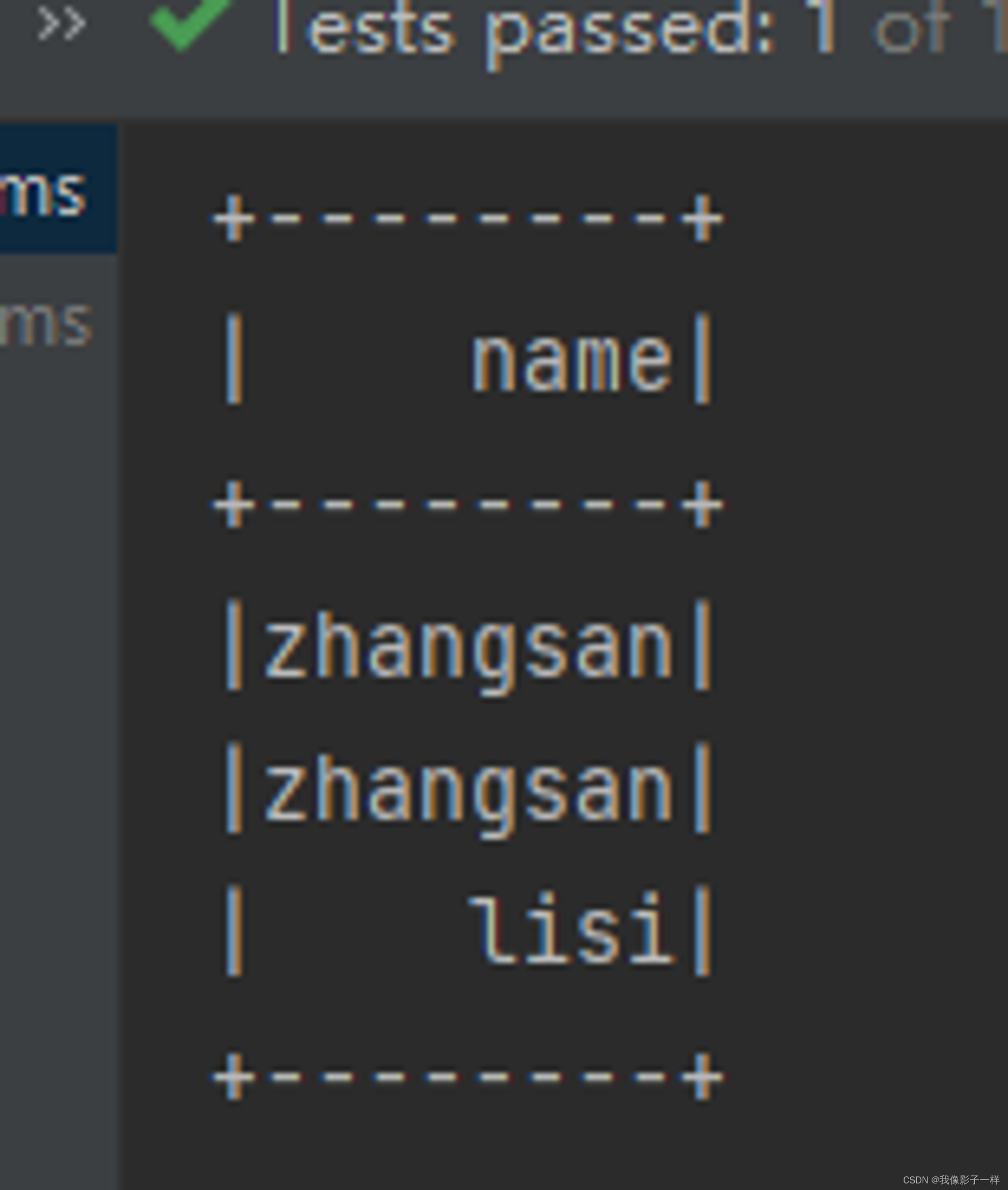
聚合 groupBy
-
聚合 groupBy
按照给定的行进行分组
@Test def groupBy(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // groupBy //为什么GroupByKey是有类型的,最主要原因是因为 GroupByKey 生成的对象的算子是有类型的 //为什么GroupBy是无类型的,因为GroupBy生成的对象的算子是无类型的,针对列进行处理的 ds.groupBy('name).agg(mean("age")).show() }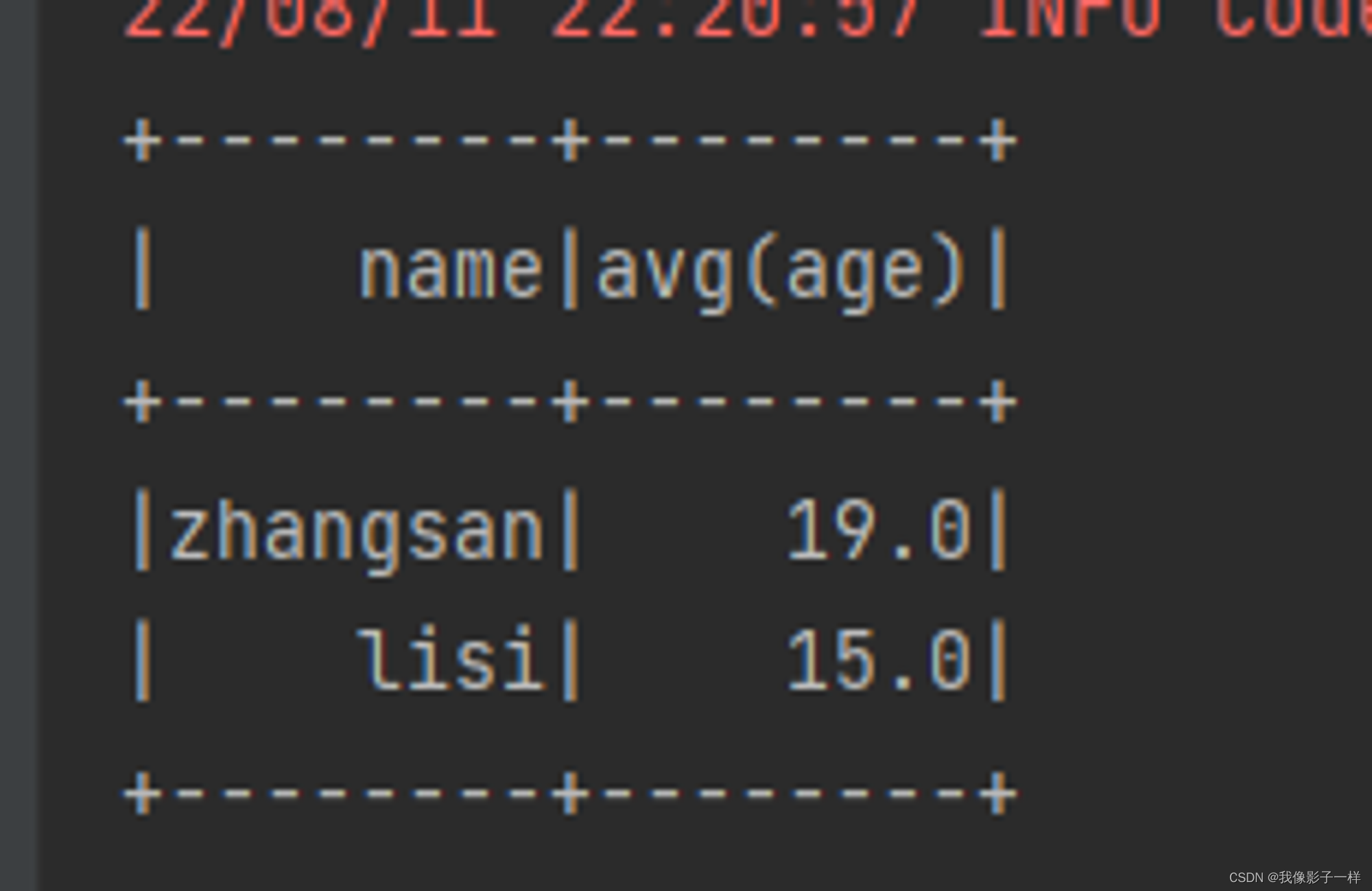


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









