






全是读代码的时候人工注释的,如有错误,还请指正。
希望大家点个赞和关注
原paper:https://arxiv.org/abs/1706.03762 attentioin is all you need
代码来源:Write With The Tone You Want Using Grammarly's Generative AI (youtube.com)
博主讲的非常好,适合初学者,我也是初学者。
首先导入torch库
import torch
import torch.nn as nnmulti_head attention的block
接着写multi_head attention的block
如下是multi_head attention的结构,是paper中的原图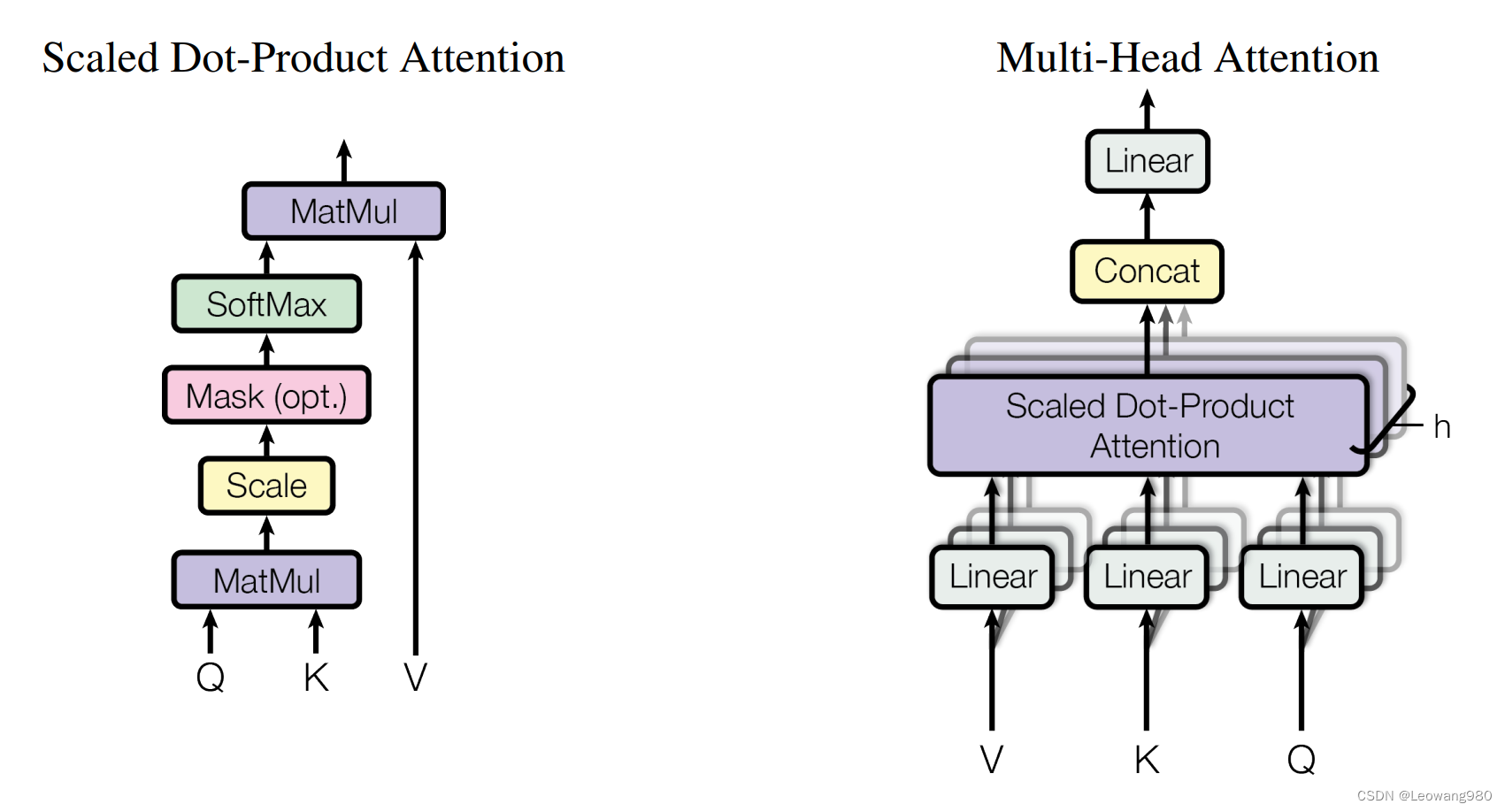 代码如下
代码如下
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
#embed_size一个词的维度,在paper中为512
#输入一句话有十个词语就是10*512
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
#通过线形层embed_size->embed_size
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, query, mask):
#batch_size 一次性输入的句子数
N = query.shape[0]
#v,k,q的维度=每个句子的单词数
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
#reshape为(句子数,embed_size,头数,每一头的维度)
#在同一个batch中,句子单词数要想等
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
#matrix multi Q*(K transpose)
#energy形状(N,heads,query_len,key_len)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
#对dim=3进行softmax,即(N,heads,query_len,key_len)key_len
#对每个单词,其他所有单词和他的相关程度相加为1
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
#matrix multi energy*V
#reshape,即paper中在attention以后,做concat操作,将多个heads合并起来
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
#再做一个linear层
out = self.fc_out(out)
return outtransformerblock
这是transformerblock,包含了残差连接和layernorm
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
#multi_head attention层
self.attention = SelfAttention(embed_size, heads)
#LayerNorm层
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
#两个线形层,和一个激活函数
#forward_expansion=神经元扩展的倍数,即隐藏层的节点倍数
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
# 残差连接+layernorm paper中为add&norm
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
#同上
out = self.dropout(self.norm2(forward + x))
return outencoder
如下是encoder部分的结构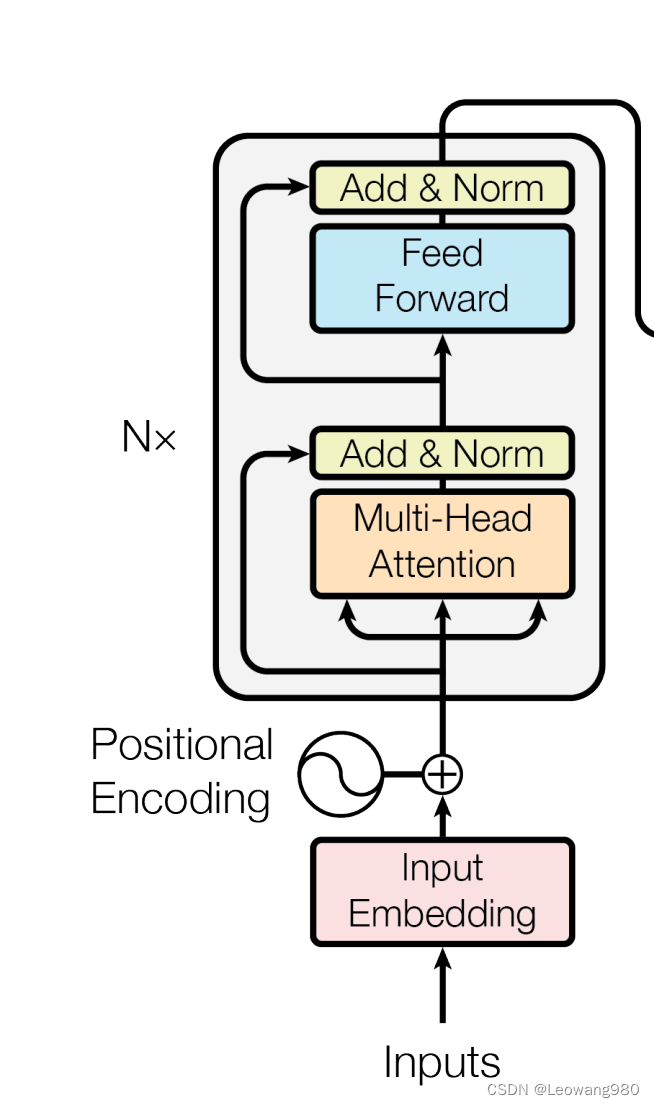
代码如下:
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
#word_embedding词嵌入 src_vocab_size=词源词汇表的大小
#position_embedding位置嵌入 max_length=一句话中最多的词数
#embed_size=嵌入维度,paper中为512
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
#num_layers=paper中的Nx,即encoder重复几次
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
#创建位置索引矩阵,形状为(N,seq_length)N=batch_size句子数,seq_length一句话中的单词数
#并将其传到设备中
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
#positional encoding
out = self.dropout(
(self.word_embedding(x) + self.position_embedding(positions))
)
#重复六次,将前一个block的输出当作下一个block的输入
for layer in self.layers:
out = layer(out, out, out, mask)
return outdecoder
结构如下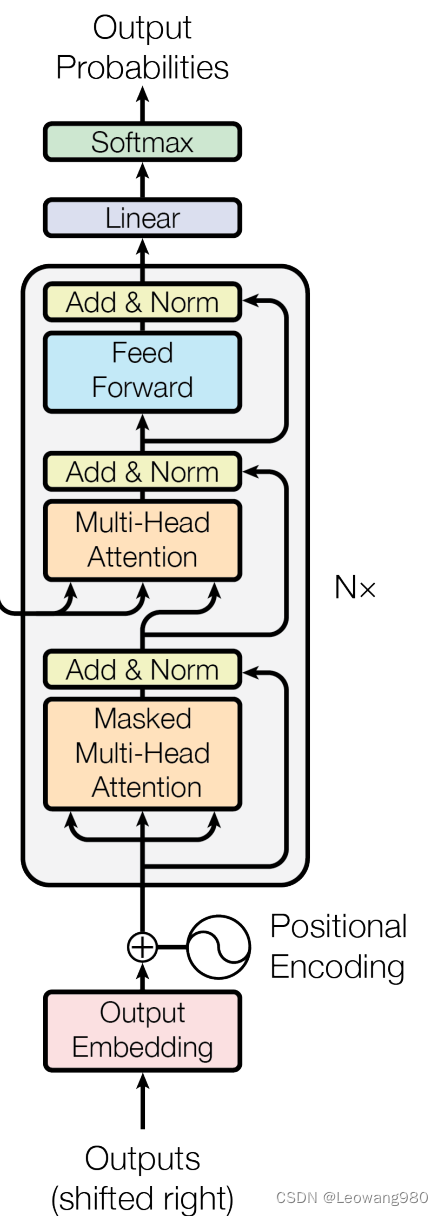
代码如下:
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
#decoder比encoder多出的部分,masked multi-heads attention
self.norm = nn.LayerNorm(embed_size)
self.attention = SelfAttention(embed_size, heads=heads)
#和encoder中相同的部分
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
#且需要掩码,不关注后面的单词
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
#残差连接,且layernorm
query = self.dropout(self.norm(attention + x))
#由paper中可知,value和key是来源于encoder中的out
#而query来源于decoder的positional encoding输出
out = self.transformer_block(value, key, query, src_mask)
return out
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
#word_embedding词嵌入 trg_vocab_size=目标词汇表的大小
#position_embedding位置嵌入 max_length=一句话中最多的词数
#embed_size=嵌入维度,paper中为512
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
#num_layers=paper中的Nx,即decoder重复几次
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
#同encoder
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
#decoder
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return out总结
整合一下就是一个完整的transfomer了
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=512,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cpu",
max_length=100,
):
super(Transformer, self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
)
#分别表示源语言和目标语言的填充词语的索引
#在之前进行matrix multi的时候我们默认了每句话的单词数量相等,否则无法进行乘法
#用于在后续的处理中识别填充词语
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









