






大模型训练与微调(8)——LoRA详解与示例
- 1. **背景与核心思想**
- 2. **核心原理**
- 3. **实现步骤**
- 4. **示例:用 LoRA 微调 GPT-2 生成任务**
- **场景**
- **步骤**
- 5. **LoRA 的优势与适用场景**
- 6. **与其他方法的对比**
- 7. **数学细节补充**
1. 背景与核心思想
大模型(如 GPT-3、BERT)的全参数微调需要巨大的计算资源和存储成本。LoRA(Low-Rank Adaptation) 是一种参数高效微调的方法,核心思想是通过低秩矩阵分解,仅训练少量参数来适配下游任务,同时冻结原始模型参数。
2. 核心原理
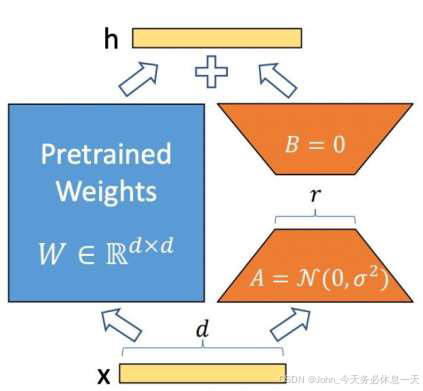
- 低秩分解:对于预训练模型的权重矩阵
W
∈
R
d
×
d
W \in \mathbb{R}^{d \times d}
W∈Rd×d,LoRA 将其更新量分解为两个低秩矩阵的乘积:
Δ W = A ⋅ B ( A ∈ R d × r , B ∈ R r × d , r ≪ d ) \Delta W = A \cdot B \quad (A \in \mathbb{R}^{d \times r}, B \in \mathbb{R}^{r \times d}, \, r \ll d) ΔW=A⋅B(A∈Rd×r,B∈Rr×d,r≪d)
其中 r r r 是秩(通常为 8-64)。微调时只需训练 A A A 和 B B B,而原始 W W W保持固定。 - 前向传播:输入
x
x
x 经过修改后的权重:
h = W x + Δ W x = W x + A B x h = Wx + \Delta Wx = Wx + ABx h=Wx+ΔWx=Wx+ABx
3. 实现步骤
- 选择目标层:通常作用于 Transformer 的注意力矩阵(如 Query 和 Value 的投影矩阵)。
- 插入低秩矩阵:为每个目标权重矩阵 W W W 添加 A A A 和 B B B。
- 冻结原参数:仅训练 A A A 和 B B B,大幅减少可训练参数量。
- 合并参数(推理时可选):训练完成后,可将 W ′ = W + A B W' = W + AB W′=W+AB 合并,避免推理时额外计算。
4. 示例:用 LoRA 微调 GPT-2 生成任务
场景
将预训练的 GPT-2 模型微调为特定领域的文本生成(如医疗问答)。
步骤
-
加载预训练模型:
from transformers import GPT2LMHeadModel, GPT2Tokenizer model = GPT2LMHeadModel.from_pretrained("gpt2-medium") tokenizer = GPT2Tokenizer.from_pretrained("gpt2-medium") -
配置 LoRA 参数(使用 Hugging Face PEFT 库):
from peft import LoraConfig, get_peft_model lora_config = LoraConfig( r=8, # 秩为8 lora_alpha=32, # 缩放因子 target_modules=["c_attn"],# 作用于注意力层的投影矩阵 lora_dropout=0.1, task_type="CAUSAL_LM" # 因果语言模型任务 ) lora_model = get_peft_model(model, lora_config) lora_model.print_trainable_parameters() # 输出:可训练参数量 ≈ 0.1% 原始参数量 -
训练模型(仅更新 LoRA 参数):
import torch from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="lora_gpt2", per_device_train_batch_size=4, gradient_accumulation_steps=4, num_train_epochs=3, learning_rate=3e-4, save_steps=1000, ) trainer = Trainer( model=lora_model, args=training_args, train_dataset=train_dataset, # 假设已加载训练数据 ) trainer.train() -
推理与合并参数(可选):
# 直接使用 lora_model 生成文本(自动应用 LoRA) inputs = tokenizer("Patient: What is COVID-19?", return_tensors="pt") outputs = lora_model.generate(**inputs, max_length=100) # 合并参数后保存完整模型 merged_model = lora_model.merge_and_unload() merged_model.save_pretrained("merged_gpt2_lora")
5. LoRA 的优势与适用场景
- 优势:
- 参数高效:训练参数量减少 100-1000 倍。
- 计算轻量:适合单卡微调(如 24GB 显存微调 7B 模型)。
- 无损性能:在多项任务中表现接近全参数微调。
- 灵活部署:支持参数合并或独立保存 LoRA 权重。
- 适用场景:
- 资源有限的大模型垂直领域适配(如医疗、法律)。
- 需要快速迭代多个下游任务。
- 边缘设备上的轻量级微调。
6. 与其他方法的对比
| 方法 | 参数量 | 修改结构 | 推理延迟 | 典型任务 |
|---|---|---|---|---|
| 全参数微调 | 100% | 无 | 无 | 通用任务 |
| Adapter Tuning | 1-5% | 插入层 | 增加 | 文本分类 |
| Prefix Tuning | 0.1-1% | 添加前缀 | 无 | 生成任务 |
| LoRA | 0.1-1% | 无 | 无 | 所有任务 |
7. 数学细节补充
- 低秩的直观解释:矩阵 Δ W \Delta W ΔW 的秩 r r r 表示其信息压缩维度。即使原始权重变化空间很大,实际有效更新可能存在于低秩子空间。
- 梯度计算:反向传播时,仅计算 A A A 和 B B B 的梯度,对 W W W 的梯度为 0(因其被冻结)。
通过 LoRA,大模型微调变得高效且易于部署,成为当前最主流的参数高效微调方法之一。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









