







YOLOv3是YOLO系列的最新版本,通过多尺度预测和Darknet-53网络增强了小物体检测能力,与SSD和RetinaNet相比,YOLOv3在保持高速的同时提供了更高的准确性。论文中提到的改进包括边界框预测、类预测、特征提取和训练方法。尽管在某些指标上不如其他模型,但YOLOv3在0.5IOU的检测指标上表现出色,且整体速度快。
参考笔记:
YOLO v3网络结构分析_yolov3网络结构-优快云博客
【YOLO系列】YOLOv3论文超详细解读(翻译 +学习笔记)-优快云博客
学习视频:
【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
4.1、yolov3算法先导与背景_哔哩哔哩_bilibili
个人吐槽:YOLO2、YOLO3真的是一地鸡毛,很多博客博文讲的都互相矛盾。感觉概念最模糊的地方应该是正负样本的分配机制,本文此节撰写的内容不一定是正解,有问题希望大佬能指出,十分感谢!
目录
3.Bounding Box Prediction—边界框预测
4.Predictions Across Scales—跨尺度预测
1.BackBone
作者将YOLOv2中的Darknet-19替换成一个新的网络Darknet-53作为YOLOv3网络的特征提取器。如下是Darknet-53的网络结构
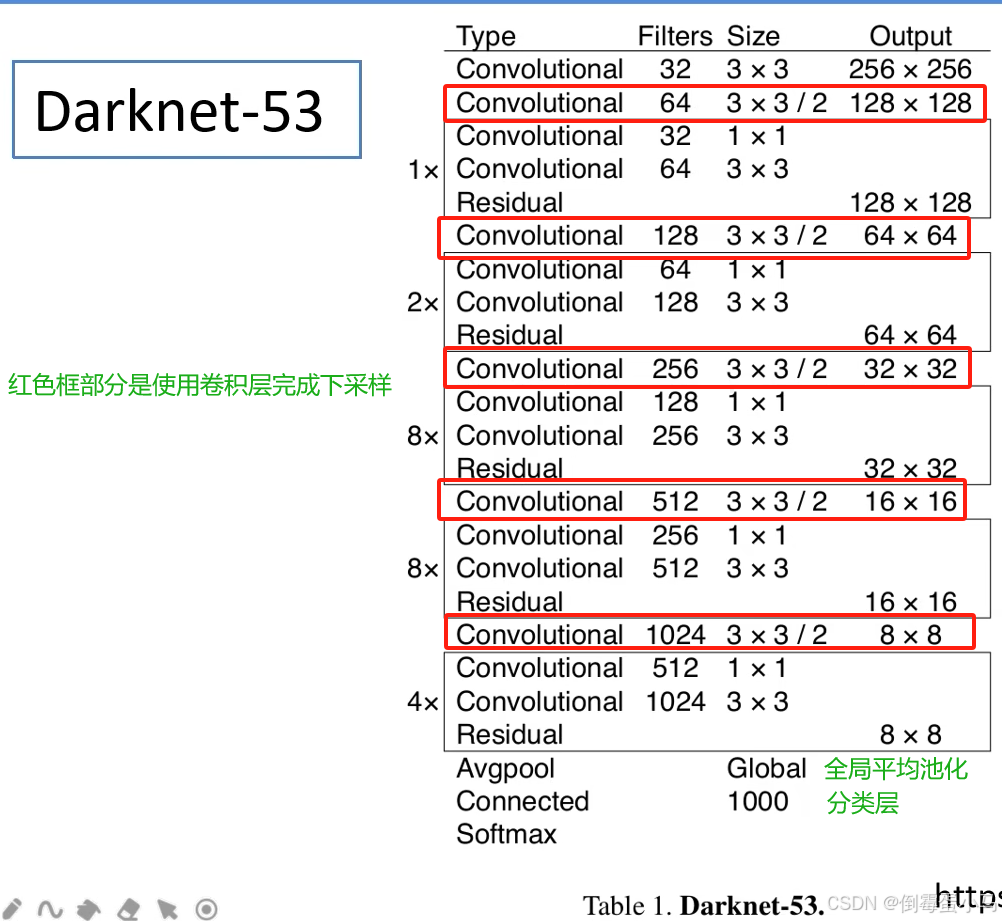
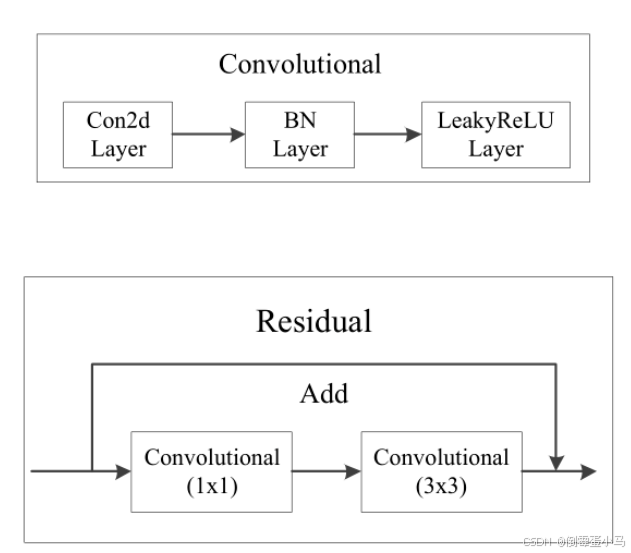
Darknet-53主要做了如下改进:
(1)没有采用最大池化MaxPooling层,采用stride=2,kernel_size=3的卷积层进行下采样。
(2)为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU(卷积层的Bias偏置设置为False)。
(3)引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
作者尝试各种模型作为YOLOv3的BackBone,下图是一些实验结果,可以看到Darknet-53的性能十分优秀。
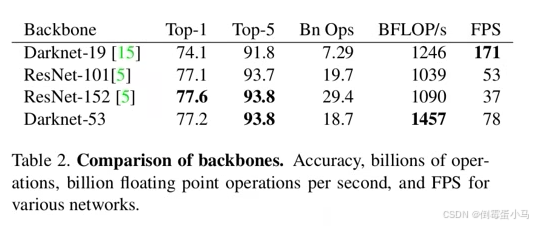
BLOPS/s:每秒钟可进行的浮点运算量,值越大表示更好的利用GPU性能
FPS:每秒可以处理的图片数量
Bn OPs:计算量
2.YOLOv3网络结构
YOLOv3中为每一个预测层的feature map的每一个网格预先设置3个先验anchor。
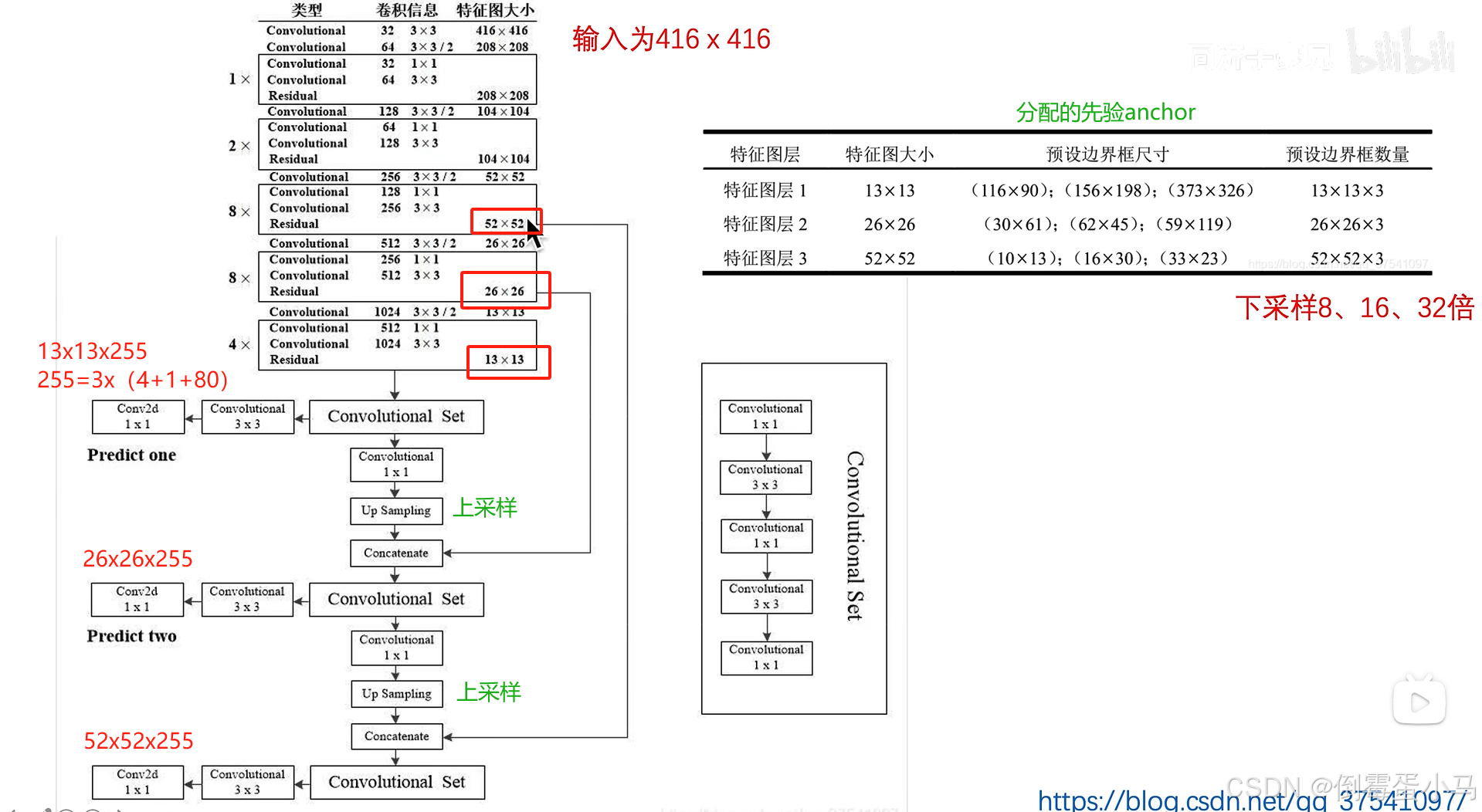
与YOLOv1,YOLOv2不一样的是,YOLOv3中是在三个预测特征层上进行预测,也就是模型最后会输出三种尺度下的feature map,这里假设输入图片是416x416,那么三个预测特征层的输出分别是,
,
。形式为
。
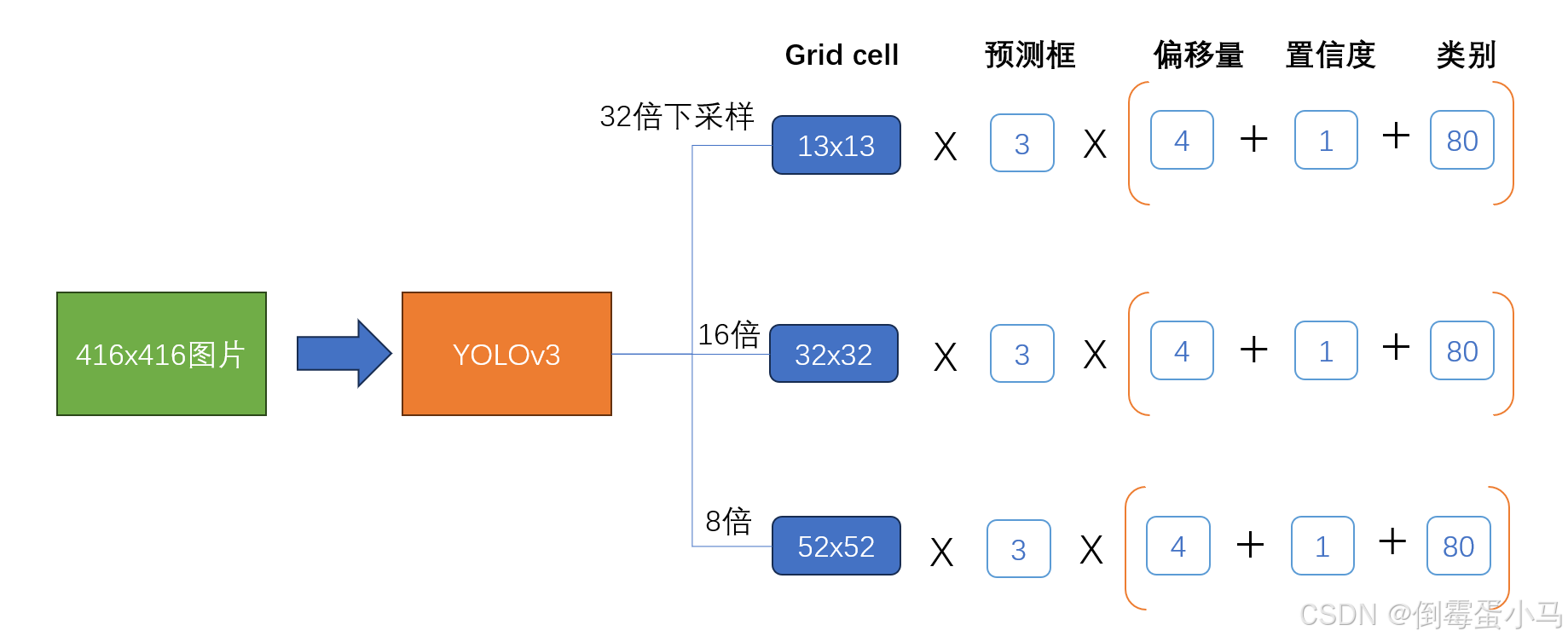
其中NxN为特征图大小(或网格数量),3为每个网格对应anchor预测生成的bbox个数,4为偏移量,1为confidence,80对应coco数据集的分类数。这三种尺度的feature map每个grid cell产生3个先验anchor,与YOLOv2中一样,先验anchor的尺寸大小是使用k-means聚类算法得到。每个anchor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









