






文章目录
一、引用的概念
1. 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共同使用同一块内存空间。
int main()
{
//b是a的引用
int a = 10;
int& b = a;
//注意将引用和取地址区分
//当变量前面单独一个&时,是取地址;当&在类型和变量之间时,那个变量便是另一个变量的引用
//此处为取地址
int* p = &b;
return 0;
}
设置断点进行调试,可见b是a的别名,因为b和a地址相同,所以共用同一块内存空间。对a的修改和对b的修改会起到相同的效果。

2. 引用的特性
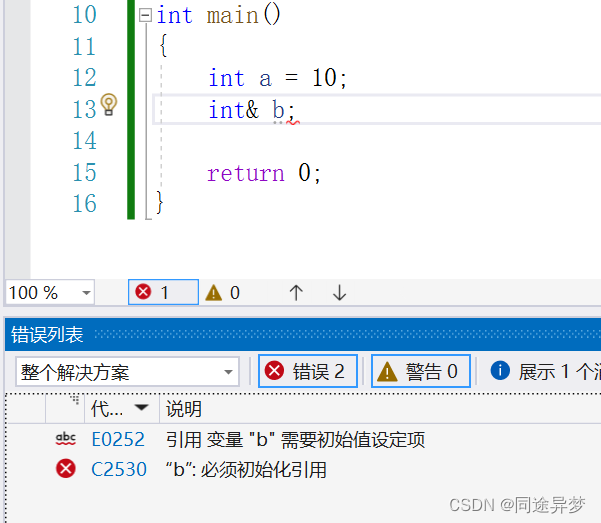
-
引用必须在定义的时候进行初始化
-
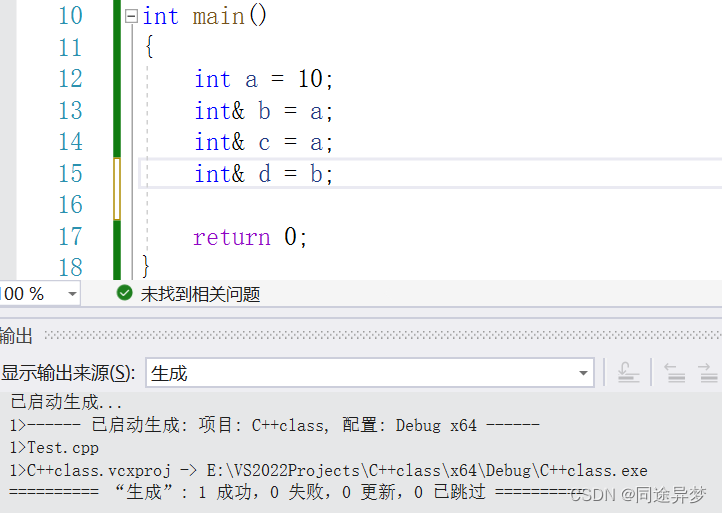
一个变量可以有多个引用
此时a、b、c、d的值全都是10
-
引用一旦引用一个实体,再不能引用其他实体

二、引用的应用
1. 引用做参数
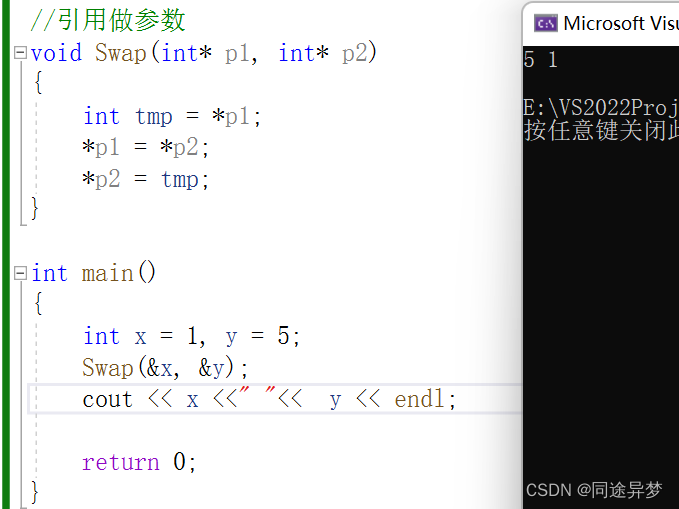
C语言中,如果我们想交换两个变量的值,则需要传指针。将x、y的地址传给p1和p2,这里相当于把x的地址拷贝给了p1,把y的地址拷贝给了p2。进行交换时,我们修改的是p1和p2,因为p1是x的地址,则*p1解引用就是x,同理,p2是y的地址,*p2解引用就是y,这样一来,就可以完成x和y值的互换。
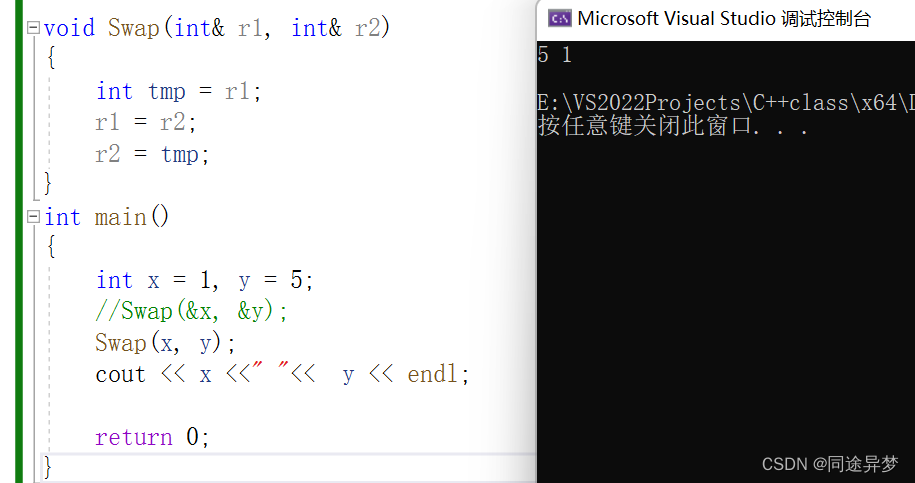
当使用C++时,我们可以传引用。Swap(x,y)中,我们将x、y作为实参传递给Swap()函数的形参,形参r1是x的引用,形参r2是y的引用,形参r1和r2分别是x、y的别名,r1和r2的交换就相当于x和y的交换。
2. 引用和二级指针

3. 引用做返回值
3.1 传值返回
所有的传值返回都会生成一个拷贝。
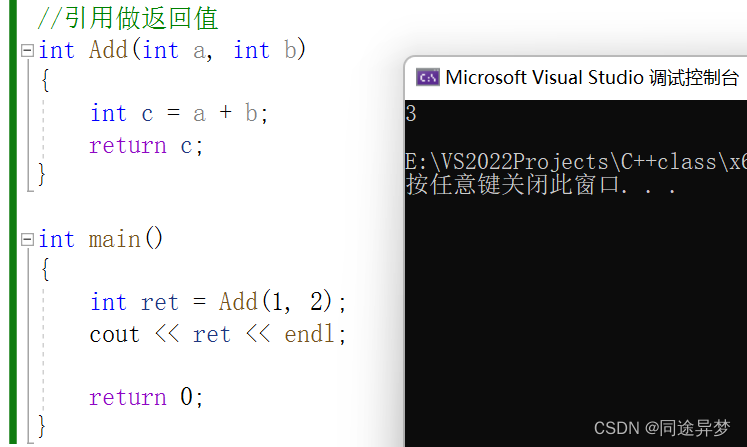
main函数建立栈帧,在栈帧中会调用Add函数,将1、2传给Add()。main()函数调用Add()函数,Add()函数建立新的栈帧,Add()函数的栈帧中存在a、b,同时有一个c接收a+b的值,由于是传值返回,c会生成一个临时变量,return c实际上返回的是c的拷贝也就是这个临时变量,最后这个临时变量赋给ret。为什么不能直接把c传给ret?这是因为当我们调用Add()函数时,当Add()函数执行完成后才会有返回值,将这个返回值给ret,但是当Add()函数执行完之后,Add()函数的栈帧就销毁了,销毁之后就无法取到c的值或者说很难取到c的值,因为这是非法访问。因此,传值返回时,应该生成一个临时变量,把临时变量返回。
临时变量存在哪呢?
1.如果c比较小(4字节或者8字节),一般是寄存器充当临时变量。
2.如果c比较大,临时变量存放在调用Add()函数的栈帧中。
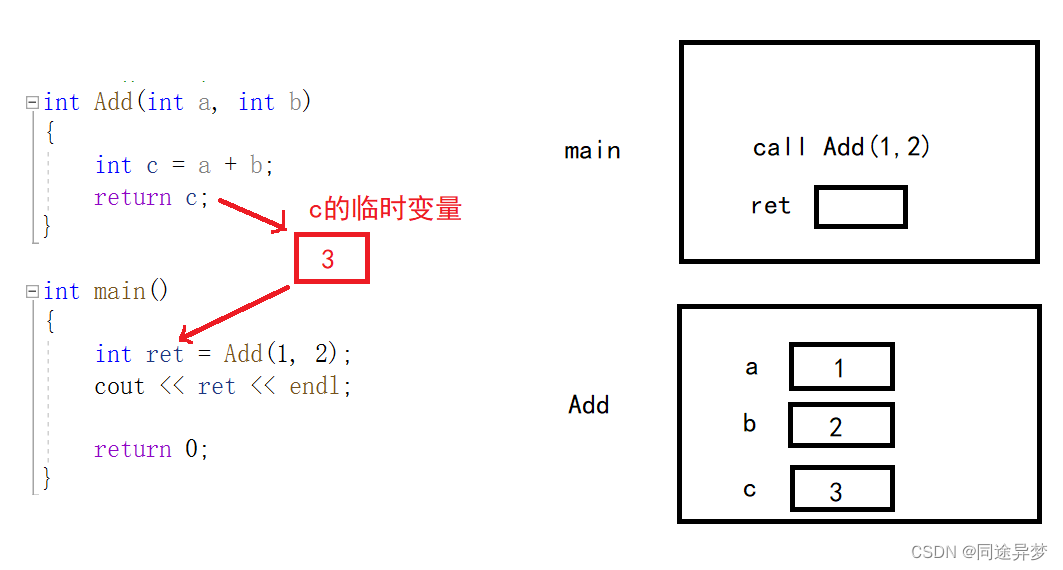
3.2 传引用返回
传引用返回可能会出现某些问题,比如,此时返回c引用,但是接收是用一个整型变量接收,所以ret是c的拷贝。

但是,此时Add()函数返回的是c的引用,ret是c的引用的引用,相当于ret就是c的引用。此时栈帧有可能被覆盖。
用int 接收和用int&接收是不一样的,int接收,会拷贝c空间里的值,也就是3 ;用int&接收,会指向c的空间, 但是c的空间出了Add函数就被释放了。
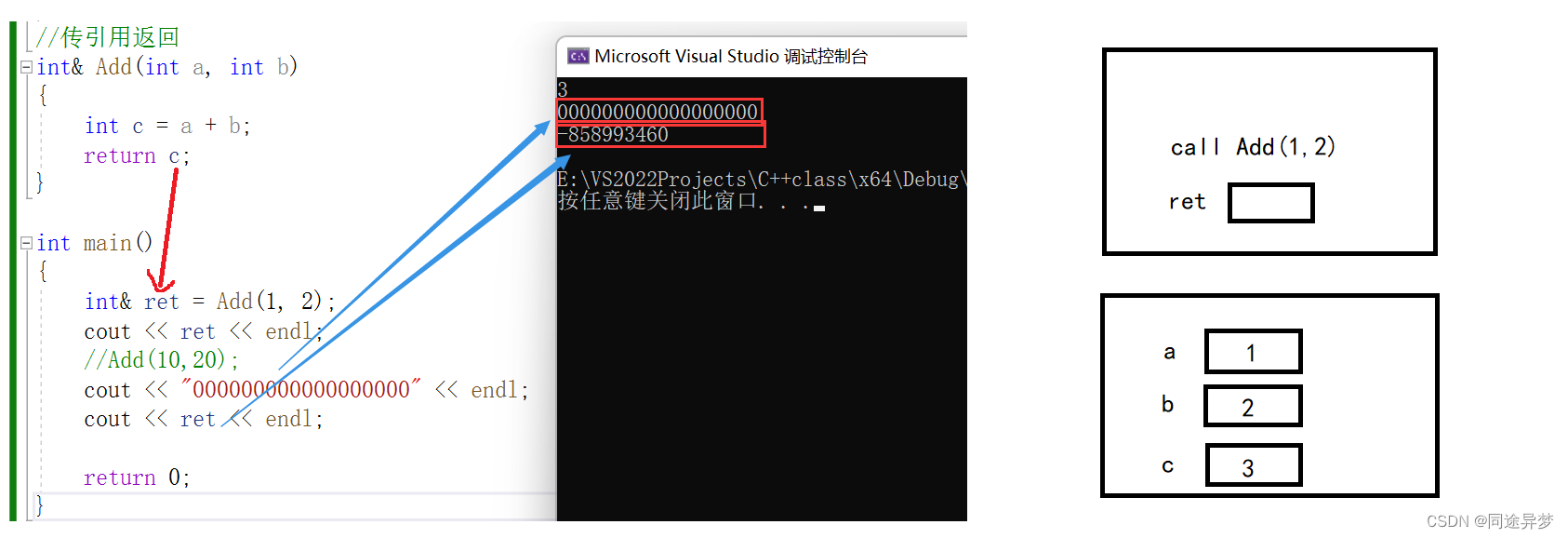
当前代码存在两个问题:
- 存在非法访问,因为Add(1,2)的返回值是c的引用,所以Add栈帧销毁了以后回去访问c位置空间。
- 如果Add函数栈帧销毁,清理空间,那么取c值得时候取到的就是随机值,给ret的就是随机值。
举两个例子,比如在执行完Add(1,2)后,将ret结果进行打印,确实就是对c引用,我们得出ret = 3,此时Add栈帧已经销毁,我们接着调用Add(10,20),再次打印ret,会发现ret变成了30,可是我们并没有将Add(10,20)的结果赋给ret。原因是因为Add(1,2)返回c = 3后,栈帧便销毁了,但是被销毁的栈帧的位置仍有c = 3,如果我们不进行管理,那么c将一直等于3,可是我们又调用了Add(10,20),Add(10,20)也要建立栈帧,刚好将之前Add(1,2)栈帧的位置覆盖了,所以之前的c = 3就没了,同时ret是c的引用,取而代之的是新的返回结果c = 30。
再比如,我们不调用Add(10,20),只是用cout函数打印一串值,如图所示,当我们再将ret进行输出的时候,发现ret变成了一串随机值。这是因为cout函数建立栈帧,栈帧的位置覆盖了原来Add(1,2)函数栈帧的位置,因此c = 3被覆盖,同时ret是c的引用,所以被覆盖后会被打印一串随机值。
传值返回还是传引用返回: 如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
4. 引用的优势
- 引用传参和传返回值,在某些场景(如:大对象和深拷贝对象)下,可以提高效率,但是不要返回局部变量的引用。
- 引用传参和传返回值,在某些场景下,形参的修改可以影响实参(输出型参数)。
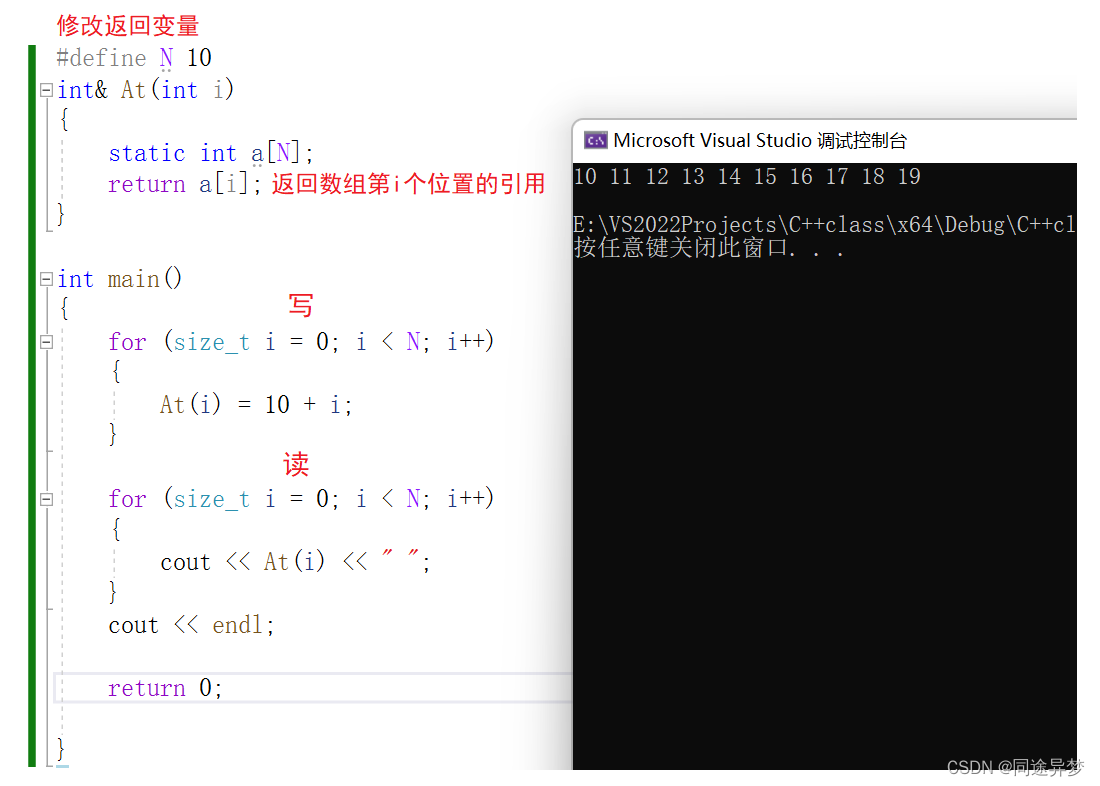
三、 常引用
void func1(int x)
{
cout << x << endl;
} // 此时在main()里可以调用func1(a)、func1(c)
void func2(int& x)
{
cout << x << endl;
} // 此时在main()里不能调用func2(a)
int main()
{
//权限被放大,这是错误的。
const int a = 10;
int& b = a;
//权限不变
const int a = 10;
const int& b = a;
//权限被缩小,这是可以的。
int c = 10;
const int& d = c; //c变成只读的
double e = 55.55;
//把e赋值给i1涉及隐式类型转换,会产生一个和i1相同类型的临时变量
//e的值先赋给临时变量,临时变量再把值赋给i1
int i1 = e;
int& i2 = e; //这是错误的
//把e赋值给i3涉及隐式类型转换,会产生一个和i3相同类型的临时变量
//e的值先赋给临时变量,临时变量再把值赋给i3,此时i3就是临时变量的别名
//临时变量是右值,具有常性,是不能修改的
//const Type& 可以接收各种类型的值
const int& i3 = e;
return 0;
}
- const是只读,&是可读和可写。
- const Type &可以接收各种类型的值。
- 使用引用传参,如果函数中不改变参数的值,建议使用const &。
四、 引用和指针的不同点
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针最好初始化,但是不初始化也不报错。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型的实体。
- 没有NULL引用,但是有NULL指针。
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数。
- 有多级指针,但是没有多级引用。
- 访问实体方式不同,指针需要显示解引用,引用编译器自己处理。
- 引用比指针使用起来相对更加安全。

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









