




摘要
在机器学习领域,基础模型(Foundation Models, FMs)应用广泛,它是在海量的数据上完成预训练,然后经过微调来适应下游任务。目前的FM主要基于Transformer及其核心注意力层。自注意力能够在上下文窗口内紧密地跟踪信息,这使得它能够对复杂数据进行建模。然而,这也使得模型不能对有限窗口之外的任何东西进行建模以及相对于窗口长度的二次缩放。虽然,有很多研究者提出了各种更有效的注意力变体来克服这些缺陷,但是,目前这些变体都没有在跨领域的大规模实践上被证明有效。
结构化状态空间序列模型(structured state space sequence models, SSM)可以理解为RNN和CNN的组合。这个模型的计算非常有效,并且序列长度具有线性或近线性缩放。此外,它们还拥有在某些数据模式中对远程依赖性进行建模的原则性机制。SSM在处理连续信号数据(例如音频和视觉)方面取得了成功。但是,它们在离散和信息密集的数据(例如文本)建模方面的表现较差。
据此,本文提出了一类新的选择性状态空间模型(Mamba),它改进了先前在多个轴上的工作,以实现 Transformer 的建模能力,同时线性缩放序列长度。
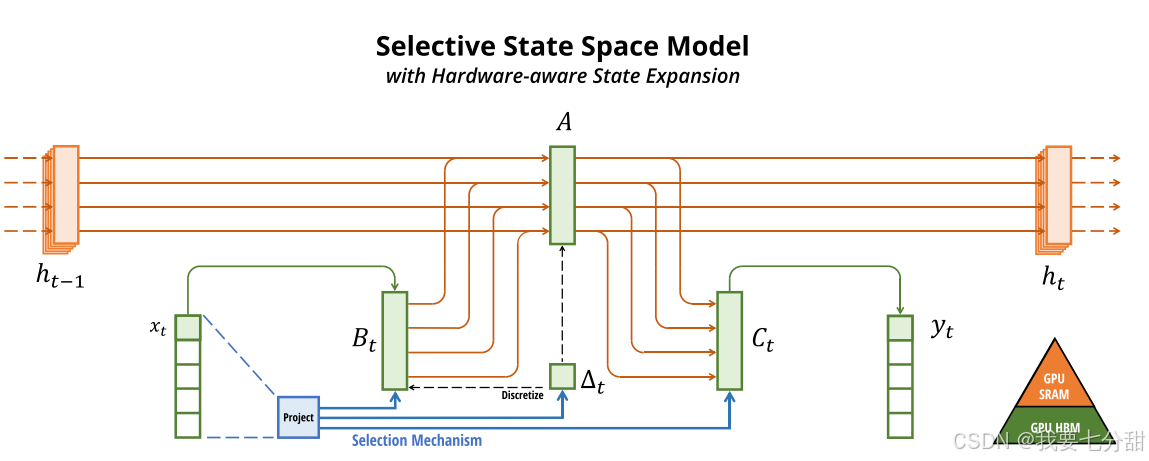
- 选择机制:根据输入参数化SSM参数。
- 硬件感知算法:算法通过扫描扫描而不是卷积来计算模型,但不会具体化扩展状态,以避免GPU内存层次结构的不同级别之间的IO访问。
- 结构:将SSM与Transfomer的MLP模块组合成一个简单的块来简化模型结构。
状态空间模型(State Space Model, SSM)
结构状态空间序列模型(S4)分两步并完成序列到序列的转换公式如下:
- 连续时间形式:
- 离散时间形式:
- 卷积形式:
离散化。这个过程通过离散化规则将连续参数转换为离散参数
。这种离散化规则有很多,例如下式所示的零阶保持方法(zero-order hold, ZOH):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









