






本教程部分来源于下面几个教程,对各方资料进行了整理汇总,同时也是笔者的学习记录,在这里希望能够帮助到大家:
OpenCV (yuque.com) ←这里有的公式无法显示,可以到语雀上查看全文
人工智能Description![]() https://spite-triangle.github.io/artificial_intelligence/#/
https://spite-triangle.github.io/artificial_intelligence/#/
《OpenCV轻松入门面向python》 - 知乎《OpenCV轻松入门面向python》的学习记录![]() https://www.zhihu.com/column/c_1374748833591742464
https://www.zhihu.com/column/c_1374748833591742464
官方文档
OpenCV: OpenCV modules![]() https://docs.opencv.org/4.10.0/
https://docs.opencv.org/4.10.0/
基础操作
图像的输入输出
1.读取图片
img=cv2.imread(图片路径,flags)#读取图片存储在img
'''
flags:
cv2.IMREAD_COLOR:以彩色读取(默认)
cv2.IMREAD_GRAYSCALE:以灰度图形式读取(黑白图片)
cv2.IMREAD_UNCHANGED: 读入一幅图像,并且包括图像的透明度alpha.'''
#存在中文的路径时可能出现问题,可以这样解决:
img=cv2.imdecode(np.fromfile(self.file,np.uint8),cv2.IMREAD_COLOR)警告:就算图像的路径是错的,OpenCV 也不会提醒你的,但是当你使用命令print(img)时得到的结果是None。
2.显示图片
cv2.imshow() 显示图像。窗口会自动调整为图像大小。
第一 个参数是窗口的名字,其次才是我们的图像。你可以创建多个窗口,只要你喜欢,但是必须给他们不同的名字。
cv2.waitKey(delay:int) ->int 是一个键盘阻塞函数。需要指出的是它的时间尺度是毫秒级。函数等待特定的几毫秒,看是否有键盘输入。特定的几毫秒之内,如果按下任意键,这个函数会返回按键的 ASCII 码值,程序将会继续运行;如果没有键盘输入,返回值为 -1;如果我们设置这个函数的参数为 0,那它将会无限期的等待键盘输入。它也可以被用来检测特定键是否被按下,例如按键 a 是否被按下。
cv2.destroyAllWindows() 删除任何建立的窗口。如果你想删除特定的窗口可以使用 cv2.destroyWindow(winname: str),在括号内输入你想删除的窗口名。
cv2.namedWindow(winname: str, flags: int=cv2.WINDOW_AUTOSIZE)可以先创建一个窗口,之后再加载图像。这种情况下,可以决定窗口是否可以调整大小。初始设定函数标签是cv2.WINDOW_AUTOSIZE。但是如果把标签改成cv2.WINDOW_NORMAL,就可以调整窗口大小了。
cv2.resizeWindow(winname:str, width:int, height:int)设置窗口大小
cv2.namedWindow('img',cv2.WINDOW_NORMAL)#可选设置,命名窗口为‘img’
cv2.resizeWindow('img',width=800,height=600)#可选设置,设置大小
cv2.imshow(窗口名称,img)#显示
cv2.waitKey(0)#0为一直等待至按下任意键关闭,非零为等待毫秒数
cv2.destroyAllWindows()#关闭所有窗口plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis
plt.show()#默认RGB,而opencv是BGR3.保存图片
cv2.imwrite(路径,img)import cv2
img=cv2.imread('computer.png')#读取进来的色彩为BGR
#print(img)#矩阵
print(img.shape)#(x,y,色彩)
cv2.imshow("img",img)#显示
k=cv2.waitKey(0)&0xFF#等待按下任意键
if k==27:#Esc
cv2.destroyAllWindows()#关闭所有窗口
elif k == ord('s'): # wait for 's' key to save and exit
cv2.imwrite('new.png', img)#保存图片
cv2.destroyAllWindows()
#plt.imshow(img)
#plt.show()#此方式颜色为RGB,直接显示色彩会变化图片的数组本质及处理
- 图片数据类型: 读取的图片类型为 <class 'numpy.ndarray'>,即图片其实是一个数据
-
- 数组类型: uint8,一字节的无符号整数
- 数组维度: 三维,[高度像素,宽度像素,BGR值]
- 由OpenCV读取的图片,其通道顺序为:B、G、R;并非一般的R、G、B
1.生成纯色图
blackImage = np.zeros(shape=(height,width,3),dtype=np.uint8)
whiteImage = np.full(shape=(10,10,3),fill_value=255,dtype=np.uint8)
redImage = blackImage.copy()
redImage[:,:] = [0,0,255]2.获取图像属性
img.shape 获取图像的形状。返回值是一个包含行数,列数,通道数的元组。
img.size 获取图像的像素数目( 宽*高*通道数,即shape元素的乘积,img的字节数 )。
img.dtype 获取图像的数据类型
注意:如果图像是灰度图,返回值仅有行数和列数。
3.获取并修改像素值
import cv2
img=cv2.imread('images.jpg')
img[100,100]=[255,255,255]
print (img[100,100])
## [255 255 255]Numpy 是经过优化了的进行快速矩阵运算的软件包。所以不推荐逐个获取像素值并修改,这样会很慢,能有矩阵运算就不要用循环。
用 Numpy 的 array.item() 和 ar- ray.itemset() 会更好。如果你想获得所有 B,G,R 的 值,你需要使用 array.item() 分割他们。
import cv2
import numpy as np
img=cv2.imread('./images/roi.jpg')
print (img.item(10,10,2))
img.itemset((10,10,2),100)
print (img.item(10,10,2))
## 50
## 1004.裁剪
# 裁剪图片:将原图片的高度 100 - 200 的像素;宽度 50 - 100 的像素。提取出来
img[ 100:200,50:100,: ]
import cv2
img=cv2.imread('images.jpg')
ball=img[280:340,330:390]
img[273:333,100:160]=ball5.颜色的拆分
# RGB 通道的拆分:结果为:高度像素 x 宽度像素 的二维数组
b,g,r = cv2.split(img)#法1
b = img[:,:,0]#法2
g = img[:,:,1]
r = img[:,:,2]
import cv2
img=cv2.imread('images.jpg')
b,g,r=cv2.split(img)#耗时
#b=img[:,:,0]
img=cv2.merge(b,g,r)#合并
img[:,:,2]=0#红色设为06.合并多个颜色通道
# 合并多个被拆分出来的通道:将三个二维数组,组合成三维的数组
img = cv2.merge((b,g,r))
可以用以下方法去除其他颜色
b,g,r = cv2.split(img)
b = img[:,:,0]
g = img[:,:,1] * 0
r = img[:,:,2] * 0
imgB = cv2.merge((b,g,r))
或
img[:,:,1]=0
img[:,:,2]=07.图片的缩放
#将img缩放为(w,h)尺寸,当设定(width, height)为(0,0)时,采用fx与fy分别表示图片两个方向上的缩放比列
img=cv2.resize(img, (width, height), fx=1, fy=1)
8.图片色彩格式转换
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#BGR->灰度
- 以下是一些常用的 cv2.COLOR_ 常量:
cv2.COLOR_BGR2GRAY:将 BGR 彩色图像转换为灰度图像。
cv2.COLOR_BGR2RGB:将 BGR 彩色图像转换为 RGB 彩色图像。
cv2.COLOR_BGR2HSV:将 BGR 彩色图像转换为 HSV 颜色空间。
cv2.COLOR_BGR2Lab:将 BGR 彩色图像转换为 Lab 颜色空间。
cv2.COLOR_RGB2GRAY:将 RGB 彩色图像转换为灰度图像。
cv2.COLOR_RGB2BGR:将 RGB 彩色图像转换为 BGR 彩色图像。
cv2.COLOR_RGB2HSV:将 RGB 彩色图像转换为 HSV 颜色空间。
cv2.COLOR_RGB2Lab:将 RGB 彩色图像转换为 Lab 颜色空间。
cv2.COLOR_GRAY2BGR:将灰度图像转换为 BGR 彩色图像。
cv2.COLOR_GRAY2RGB:将灰度图像转换为 RGB 彩色图像。
cv2.COLOR_HSV2BGR:将 HSV 颜色空间图像转换为 BGR 彩色图像。
cv2.COLOR_HSV2RGB:将 HSV 颜色空间图像转换为 RGB 彩色图像。
9.为图像扩边
cv2.copyMakeBorder(
src: MatLike,#img
top: int,#上边扩多少像素
bottom: int,
left: int,
right: int,
borderType: int,#扩充模式
dst: MatLike | None = ...,
value: Scalar = ...#当扩充模式为常数值时的值
) -> MatLikeborderType参数:
- cv2.BORDER_CONSTANT:添加一个常数值的边框。此时还需要提供 value 参数来指定这个常数值。
- cv2.BORDER_REPLICATE:复制最边缘的像素。例如: aaaaaa| abcdefgh|hhhhhhh
- cv2.BORDER_REFLECT:反射法,即边缘像素的镜像,包括它本身。例如: fedcba | abcdefgh | hgfedcb
- cv2.BORDER_REFLECT_101 或 cv2.BORDER_DEFAULT:与 cv2.BORDER_REFLECT 类似,但不包含边缘像素本身。例如: fedcb | abcdefgh | gfedcb
- cv2.BORDER_WRAP:外包装法,用图像边界外的像素来填充。例如: cdefgh| abcdefgh|abcdef


视频的输入输出
1.视频文件读取
video = cv2.VideoCapture('视频路径')video.get(propId: int) -> float 获取视频信息
video.set(propId: int, value: float) -> bool 设置视频参数
- propld参数:
| 参数 | 对应宏 | 说明 |
| VideoCapture.get(0) | cv2.CAP_PROP_POS_MSEC | 视频文件的当前位置(播放)以毫秒为单位 |
| VideoCapture.get(1) | cv2.CAP_PROP_POS_FRAMES | 基于以0开始的被捕获或解码的帧索引 |
| VideoCapture.get(2) | cv2.CAP_PROP_POS_AVI_RATIO | 视频文件的相对位置(播放):0=电影开始,1=影片的结尾 |
| VideoCapture.get(3) | cv2.CAP_PROP_FRAME_WIDTH | 在视频流的帧的宽度 |
| VideoCapture.get(4) | CV_CAP_PROP_FRAME_HEIGHT | 在视频流的帧的高度 |
| VideoCapture.get(5) | cv2.CAP_PROP_FPS | 帧速率/帧数/fps |
| VideoCapture.get(6) | cv2.CAP_PROP_FOURCC | 编解码的4字-字符代码 |
| VideoCapture.get(7) | cv2.CAP_PROP_FRAME_COUNT | 视频文件中的帧数 |
| VideoCapture.get(8) | cv2.CAP_PROP_FORMAT | 返回对象的格式 |
| VideoCapture.get(9) | cv2.CAP_PROP_MODE | 返回后端特定的值,该值指示当前捕获模式 |
| VideoCapture.get(10) | cv2.CAP_PROP_BRIGHTNESS | 图像的亮度(仅适用于照相机) |
| VideoCapture.get(11) | cv2.CAP_PROP_CONTRAST | 图像的对比度(仅适用于照相机) |
| VideoCapture.get(12) | cv2.CAP_PROP_SATURATION | 图像的饱和度(仅适用于照相机) |
| VideoCapture.get(13) | cv2.CAP_PROP_HUE | 色调图像(仅适用于照相机) |
| VideoCapture.get(14) | cv2.CAP_PROP_GAIN | 图像增益(仅适用于照相机)(Gain在摄影中表示白平衡提升) |
| VideoCapture.get(15) | cv2.CAP_PROP_EXPOSURE | 曝光(仅适用于照相机) |
| VideoCapture.get(16) | cv2.CAP_PROP_CONVERT_RGB | 指示是否应将图像转换为RGB布尔标志 |
| VideoCapture.get(17) | cv2.CAP_PROP_WHITE_BALANCE | × 暂时不支持 |
| VideoCapture.get(18) | cv2.CAP_PROP_RECTIFICATION | 立体摄像机的矫正标注(目前只有DC1394 v.2.x后端支持这个功能) |
fps=video.get(cv2.CAP_PROP_FPS)while video.isOpened():
# 读取一帧
flag,frame = video.read()#每次往后读一帧
# 显示
if flag == True:#如果帧正常读取
cv2.imshow('video',frame)
else: break
# 控制播放速度:以 60 帧的速度进行图片显示,按q退出(Esc为27)
if cv2.waitKey(1000 // 60) == ord('q'):
break video.release()
cv2.destroyAllWindows()2.摄像头捕获
Tip:
只要修改cv2.VideoCapture()的参数就行,其余和读取视频文件一样
video = cv2.VideoCapture(index)#index:摄像头的编号,从0开始
video.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
video.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)3.视频保存
class VideoWriter( filename: str, fourcc: int, fps: float, frameSize: Size, isColor: bool)/*
filename:保存的文件名
fourcc:格式(mp4v-mp4;XVID-avi;WMV1-wmv),传入cv2.VideoWriter_fourcc(*'mp4v')
fps:帧率
framesize:元组(宽,高)
isColor:默认True彩色图,False为灰度图*/videoSave.write(frame)videoSave.release()#不经过该函数视频文件打不开import cv2
# 调用摄像头,抓取图片。设备连接的摄像头从 0 开始编号
video = cv2.VideoCapture(0)
fps=video.get(cv2.CAP_PROP_FPS)
# 视频保存格式
videoForm = cv2.VideoWriter_fourcc(*'mp4v')
# 保存视频的类,输入参数为:
# 保存路径,保存格式,保存的 视频帧率,(宽度像素,高度像素)
videoSave = cv2.VideoWriter('./asset/capture.mp4',videoForm,fps,(640, 480))
# 视频读取
while video.isOpened():
# 读取一帧
flag,frame = video.read()
# 是否读取成功
if flag == True:
# 显示
cv2.imshow('video',frame)
# 保存
videoSave.write(frame)
if cv2.waitKey(1) == ord('q'):
break
# 释放
videoSave.release()
video.release()
cv2.destroyAllWindows()界面控件
1.鼠标事件
# 定义鼠标回调函数
def mouse_callback(event,x,y,flags,userdata:any):
if event == cv2.EVENT_LBUTTONDOWN:
print(event,x,y,flags,userdata)
# event:事件类型
'''EVENT_MOUSEMOVE 鼠标移动
EVENT_LBUTTONDOWN 左键按下
EVENT_RBUTTONDOWN 右键按下
EVENT_MBUTTONDOWN 滚轮按下
EVENT_LBUTTONUP 左键抬起
EVENT_RBUTTONUP 右键抬起
EVENT_MBUTTONUP 滚轮抬起
EVENT_LBUTTONDBLCLK 左键双击
EVENT_RBUTTONDBLCLK 右键双击
EVENT_MBUTTONDBLCLK 中间双击
EVENT_FLAG_LBUTTON 左键拖拽
EVENT_FLAG_RBUTTON 右键拖拽
EVENT_FLAG_MBUTTON 中键拖拽
EVENT_FLAG_CTRLKEY 按住ctrl不放
EVENT_FLAG_SHIFTKEY 按住shift不放
EVENT_FLAG_ALTKEY 按住alt不放'''
# x,y:鼠标所在像素值
# userdata:用户传入数据# 鼠标事件指定回调函数
cv2.setMouseCallback('Event Test',mouse_callback,"userdata")import cv2
import numpy as np
# 定义鼠标回调函数
# event:事件类型
# x,y:鼠标所在像素值
# userdata:用户传入数据
def mouse_callback(event,x,y,flags,userdata:any):
if event == cv2.EVENT_LBUTTONDOWN:
print(event,x,y,flags,userdata)
# 创建窗口
cv2.namedWindow('Event Test',cv2.WINDOW_NORMAL)
cv2.resizeWindow('Event Test',width=640,height=380)
# 鼠标事件指定回调函数
cv2.setMouseCallback('Event Test',mouse_callback,"userdata")
# 生成一个背景图片
bg = np.zeros((380,640,3),dtype=np.uint8)
cv2.imshow('Event Test',bg)
cv2.waitKey(0)
cv2.destroyAllWindows()bg = np.full((380,640,3),fill_value=255,dtype=np.uint8)
i=0
while True:#可以更新图片
bg2=bg.copy()
bg2[:,:,0]=i%255
bg2[:,:,1]=255-i%255
bg2[:,:,2]=(i+120)%255
i=i+1
cv2.imshow('Event Test',bg2)
if cv2.waitKey(4) == 27:
break
cv2.destroyAllWindows()2.TrackBar

def onTrackbarChange(value):
print(value)cv2.createTrackbar(
trackbarName: str,#Bar名
windowName: str,#窗口名
value: int,#默认值
count: int,#最大值(0~count)
onChange: (int) -> None#回调函数
)value = cv2.getTrackbarPos(trackbarname: str, winname: str) -> intcv2.setTrackbarPos(trackbarname: str, winname: str, pos: int)#设置当前bar值
cv2.setTrackbarMin(trackbarname: str, winname: str, minval: int)#设置最小值
cv2.setTrackbarMax(trackbarname: str, winname: str, maxval: int)#设置最大值import cv2
# trackbar 改变时的回调函数
def onTrackbarChange(value):
print(value)
# 创建界面
cv2.namedWindow('trackbar',cv2.WINDOW_NORMAL)
cv2.resizeWindow('trackbar',width=640,height=360)
# 创建trackbar
# createTrackbar(trackbarName, windowName, defaultValue, maxValue, onChangeCallback) -> None
cv2.createTrackbar('bar','trackbar',0,255,onTrackbarChange)
# 读取trackbar 的值
# getTrackbarPos(trackbarname, windowName) -> trackbarValue
value = cv2.getTrackbarPos('bar','trackbar')
print(value)
cv2.waitKey(0)
cv2.destroyAllWindows()绘图
1.画线
cv2.line(
img: MatLike,#图像数据,自动覆盖
pt1: Point,
pt2: Point,
color: Scalar,#(B,G,R)
thickness: int = ...,#线条粗细,默认为1
lineType: int = ...,#该值控制的是「抗锯齿」效果,值越大线条越光滑,取值通常为2^n
shift: int = ...
) -> MatLikeimport numpy as np
import cv2 as cv
# Create a black image
img = np.zeros((512,512,3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv.line(img,(0,0),(511,511),(255,0,0),5)
cv.imshow(img)2.画矩形
cv2.rectangle(img,(384,0),(510,128),(0,255,0),3)#参数用法同上,thickness填-1时为实心3.画圆
cv2.circle(
img: MatLike,
center: Point,
radius: int,
color: Scalar,
thickness: int = ...,
lineType: int = ...,
shift: int = ...
) -> MatLike4.画椭圆
cv2.ellipse(
img: MatLike,
center: Point,
axes: Size,#(长轴,短轴)
angle: float,#倾斜角度,顺逆时针
startAngle: float,#起始弧长和终止弧长,顺时针
endAngle: float,
color: Scalar,
thickness: int = ...,
lineType: int = ...,
shift: int = ...
) -> MatLike: ...5.多边形
cv2.polylines(
img: MatLike,
pts: Sequence[MatLike],#列表,元素为数组(不同数组间不连线),数组的元素为顶点坐标的元组
isClosed: bool,#True时封闭,False时收尾不相连
color: Scalar,
thickness: int = ...,
lineType: int = ...,
shift: int = ...
) -> MatLike: ...pts1 = np.array([ (20,60),(300,150),(50,300) ])
pts2 = np.array([ (400,60),(300,100) ])
cv2.polylines(canvas,[pts1,pts2],True,(255,0,0))cv2.fillPoly(img, [pts], color[, lineType[, shift[, offset]]]) -> img6.文字
# fontfamily:cv2.FONT_ 进行查看
putText(img, text, pos:tuple,#位置(文字左下角)
fontfamily,#字体
fontScale, #字号
color[, thickness['-1时填充', lineType[, bottomLeftOrigin]]]) -> img
'bottomLeftOrigin:当这个标志为 True 时,图像数据的原点(即 (0,0) 坐标)位于左下角;否则,它位于左上角。注意,这与 pos 参数中指定的坐标如何解释有关。import cv2
import numpy as np
import matplotlib.pyplot as plt
points=np.array([])
a=0
def mouse_callback(event,x,y,flags,userdata:any):
global points,a
if event == cv2.EVENT_LBUTTONDOWN:
a=1
if a:
if event == cv2.EVENT_LBUTTONUP:
a=0
#if event == cv2.EVENT_LBUTTONDOWN:
print(event,x,y,flags,userdata)
points=np.array([*points,(x,y,cv2.getTrackbarPos('b','video'),cv2.getTrackbarPos('g','video'),cv2.getTrackbarPos('r','video'),cv2.getTrackbarPos('bar','video'))])
def onTrackbarChange(value):
pass
# 设置分辨率
cv2.namedWindow('video',cv2.WINDOW_NORMAL)
cv2.resizeWindow('video',width=640,height=520)
cv2.setMouseCallback('video',mouse_callback,"userdata")
cv2.createTrackbar('bar','video',1,255,onTrackbarChange)
cv2.createTrackbar('r','video',0,255,onTrackbarChange)
cv2.createTrackbar('g','video',0,255,onTrackbarChange)
cv2.createTrackbar('b','video',0,255,onTrackbarChange)
while 1:
frame=np.full((720,1280,3),255,np.uint8)
value = cv2.getTrackbarPos('bar','video')
font=cv2.FONT_HERSHEY_COMPLEX_SMALL
for i in range(1,len(points)):
cv2.line(frame,points[i-1][:2],points[i][:2],points[i][2:5].tolist(),points[i][5]+1,16)
cv2.putText(frame,'OpenCV',(10,500), font, 10,0,value,16)
cv2.imshow('video',frame)
print(frame.shape,value)
if cv2.waitKey(1)==27:
break
cv2.destroyAllWindows()
性能检测
cv2.getTickCount 函数返回从参考点到这个函数被执行的时钟数。所以在一个函数执行前后都调用它的话,你就会得到这个函数的执行时间(时钟数)。
cv2.getTickFrequency 返回时钟频率,或者说每秒钟的时钟数。所以 你可以按照下面的方式得到一个函数运行了多少秒:
import cv2
e1 = cv2.getTickCount()
e2 = cv2.getTickCount()
time = (e2 - e1)/ cv2.getTickFrequency()OpenCV中的默认优化
OpenCV 中的很多函数都被优化过(使用 SSE2,AVX 等)。也包含一些没有被优化的代码。在编译时优化是被默认开启的。因此 OpenCV 运行的就是优化后的代码,如果把优化关闭就只能执行低效的代码了。
使用函数 cv2.useOptimized()->bool 来查看优化是否被开启了
使用函数 cv2.setUseOptimized(bool) 来开启优化。
图像变换
一、图像基础理论
色彩空间
1.1. RGB 模型
根据光学三原色而来,图像中的一个像素点由一个数组[R,G,B]构成,一般该数组的类型为「一个字节的无符号整型」。
而在 OpenCV 中,采用的是反人类的[B,G,R]。

1.2. HSV 模型
HSV 模型的像素点也是通过一个「三维向量」进行表示:
- Hue:色相,将所有颜色通过一个数值进行表示
- Saturation:饱和度,颜色与「白色」的混合程度
- Value:明度,颜色的明亮程度

RGB 转 HSV 公式:公式测试
1.3. HSL 模型
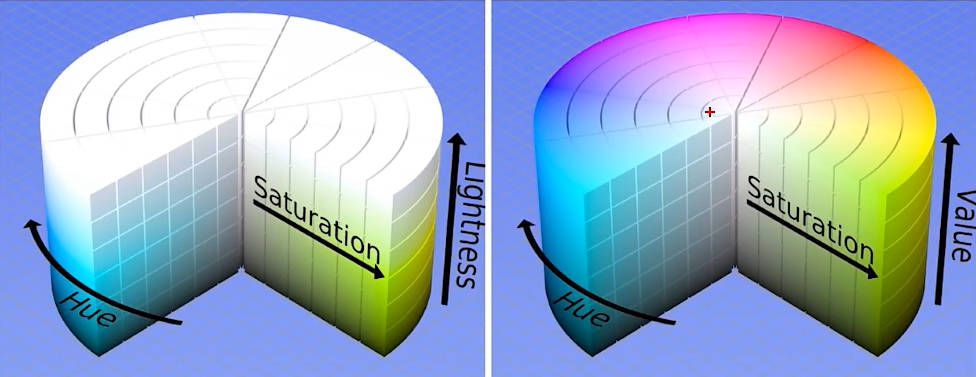
整个形式和 HSV 类似
- Hue:色相,与 HSV 一样
- Saturation:饱和度,颜色的稀释程度
- Lightness/Brightness:被灯光照射的亮度
| 色相 | 饱和度 | 明亮度 | |
| HSV | 所有颜色 | 色相中混入「白色」的量 | 色相中混入「黑色」的量 |
| HSL | 所有颜色 | 色相被稀释的程度 | 拿灯光照射的情况,没光线就黑,强烈光线就白 |
RGB转HSL公式:公式测试
1.4. YUV 模型
- 作用: 可以对色彩空间进行压缩,说人话就是 缩减了用来表示像素颜色的数据量,这就使得该模型在图像、视频压缩上应用广泛。
- 思想: 由于人眼对颜色的感知能力较弱,反而对光影关系(黑白图)更为敏感。所以,在 YUV 模型中,精确保留了图片的「黑白关系」,而对颜色信息进行了部分删除。
- 通道:
-
- Y:该通道储存的是「黑白关系」,即「灰度图」。
- UV:这两个通道储存了颜色信息。在对图片颜色时,首先就会对这个两个通道的颜色数据进行丢弃。
- 色彩空间压缩: 一共有 4 个像素,每个像素都有3个通道值表示颜色,一个通道为一个字节,那么所有数据一共就有4 x 3 x 1B = 12B。现在通过 YUV 模型对图片进行压缩,丢掉一半的颜色信息,Y 通道全部保留4 x 1B = 4B,UV 通道丢弃一半就是2 x 4 x 1B / 2 = 4B,最后数据大小就为4B + 4B = 8B。
- 采样方式: 对于 Y 全部保留,对 UV 进行不同程度的取舍。

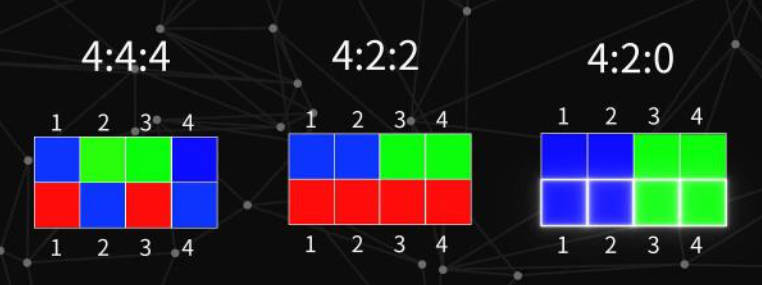
RGB与YUV转换:
1.5. 灰度图
OpenCV中的灰度图其实就是 YUV 模型中的 Y 通道:
Y=0.299R+0.587G+0.114B

1.6. OpenCV 色彩空间转换
# code : cv2.COLOR_ 指定图片色彩空间的转换方式
cv2.cvtColor(srcimage, code[, dst[, dstCn]]) -> dstImage图片的存储
- Python实现: 读取的图片类型为 <class 'numpy.ndarray'>,即图片其实是一个数据
-
- 数组类型: uint8,一字节的无符号整数
- 数组维度: 三维,[高度像素,宽度像素,RGB值]
- C++底层实现: Python 的 OpenCV 其实就是对 C++ 的版本进行了再次封装实现。在 C++ 中采用数据结构Mat来对图片进行存储。
class CV EXPORTS Mat{
public:
int dims;//维数
int roWs,cols;//行列数
unsigned char * data;//存储数据的指针
int* refcount;//引用计数
........
}二、算数运算
1.图像的加减
imgA + imgB:当数值大于一个字节时,大于一个字节的位数都被丢失了。
- =(𝐴+𝐵) % 256
cv2.add(imgA,imgB):当数值超过255时,取值为255
- =min(𝐴+𝐵,255)
cv2.addWeighted(imgA, alpha, imgB, beta, gamma):
- =min(round(A∗𝛼+B∗𝛽+𝛾),255)
imgA + imgB
cv2.add(imgA,imgB)
cv2.addWeighted(imgA, alpha, imgB, beta, gamma)#图像的混合
权重为0.7和0.3
cv2.subtract()#两个图像相减,与cv2.add()相似
2.按位运算
# 与 位运算
bitwise_and(src1:image, src2:image[, dst[, mask]]) -> dst
# 或 位运算
bitwise_or(src1:image, src2:image[, dst[, mask]]) -> dst
# 异或 位运算
bitwise_xor(src1:image, src2:image[, dst[, mask]]) -> dst
# 非 位运算
bitwise_not(src1:image[, dst[, mask]]) -> dst与、或、异或: 实质就是两个图像数组,相同位置的数据直接进行与、或、异或的位运算。
与: 图片亮度会整体变暗,与运算会将值变小,不超过255
或: 图片亮度会整体变亮,与运算会将值变大,不超过255
非: 与程序中按位取反不一样,OpenCV 中实现的是对颜色反转
位平面分解
将灰度图像中处于同一比特位上的二进制像素值进行组合, 得到一幅二进制值图像,该图像被称为灰度图像的一个位平面,这个过程被称为位平面分解。
在8位灰度图中,每一个像素值的取值范围[0,255],可组成 8 个二进制值图像,因此可以分解为 8 个位平面。
其中,第7位的值对图像的影响最大,所构成的位平面与原图像相关性最高,该位平面看起来通常与原图像最相似。而第0的值对图像的影响最小,所构成的位平面与原图像相关性最低,该平面看起来通常是杂乱无章的。

import cv2
import numpy as np
# 位平面分解
# 参考链接 https://blog.youkuaiyun.com/qq_39197555/article/details/103396781
# 以单通道灰度图像格式读取图片
flower = cv2.imread("flower.jpg",0)
cv2.imshow("flower",flower)
h,w = flower.shape
# 构造提取矩阵
extract_matrix = np.zeros((h,w,8),dtype=np.uint8)
for i in range(8):
extract_matrix[:,:,i] = 2**i
""" 提取矩阵如下所示
array([[[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128]],
...
[[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128]],
[[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128],
[ 1, 2, 4, 8, 16, 32, 64, 128]]], dtype=uint8)
"""
print("extract_matrix",extract_matrix,extract_matrix.shape) # (250, 250, 8)
print("extract_matrix[:,:,1].shape",extract_matrix[:,:,1].shape) #(250,250)
# 构造一个空数组,shape为(h,w,8),最后一位一定是8,表示容纳8个位平面的数值。
w = np.zeros((h,w,8),dtype=np.uint8)
for i in range(8):
# 将像素与一个数值为2**n进行按位与操作 bitwise_and,可以保持像素值的第n位不变化,其它位置为0.
# 00000001 -》 1
# 00000010 -》 2
# 00000100 -》 4
# 00001000 -》 8
# 00010000 -》 16
# 00100000 -》 32
# 01000000 -》 64
# 10000000 -》 128
# 这样按位与后,就可以获取像素值指定位置的值。因此可以获取该图像的8个位平面。
w[:,:,i] = cv2.bitwise_and(flower,extract_matrix[:,:,i])
# w[:,:,0] 表示第0个位平面
# w[:,:,1] 表示第1个位平面
# ...依次类比
# w[:,:,7] 表示第7个位平面
# 阈值处理
# mask.shape (250,250)
# w.shape (250,250,8)
# w[mask].shape (31440,8)
# mask = w[:,:,i]>0
# w[mask] = 255
cv2.imshow(str(i),w[:,:,i])
cv2.waitKey()
cv2.destroyAllWindows()
位平面图分解
在位平面的像素值中:
第0个位平面的只有两个值, 0和1
第1个位平面的只有两个值, 0和2
……
第6个位平面的只有两个值, 0和64
第7个位平面的只有两个值, 0和128
图像加密与解密
原理:通过数字的异或运算就可以实现简单的加密解密。
根据异或规则,有:
xor(a,b)=c
xor(b,c)=a
xor(a,c)=b可以把a看做数据(明文),b为加密的密钥,c为加密后的结果(密文)。
那么根据xor(b,c)=a,就可以得知,有了加密后的结果,再获取密钥,就可以获取原始的数据a。
import cv2
import numpy as np
# 以单通道灰度图为例
flower = cv2.imread("flower.jpg",0)
h,w = flower.shape
# key = np.random.randint(low=0,high=256,size=flower.shape,dtype=np.uint8)
key = cv2.imread("dollar.jpg",0)
encryption = cv2.bitwise_xor(flower,key)
decryption = cv2.bitwise_xor(encryption,key)
# encrypt
# 英 [ɪnˈkrɪpt] 美 [ɪnˈkrɪpt]
# v. 把……加密,将……译成密码
cv2.imshow("org",flower)
cv2.imshow("key",key)
cv2.imshow("encryption",encryption)
cv2.imshow("decryption",decryption)
cv2.waitKey()
cv2.destroyAllWindows()
隐藏水印
图片的二进制形式中的第0位也称为最低位,或者“最低有效位 Least Significant Bit”。
可以将一些其它信息隐藏到图片的最低有效位中,这称为最低有效位信息隐藏。因为图像的最低位不会影响原始图片的观感,因此将其它信息掺入最低位中具有非常高的隐蔽效果。


载体图中的水印信息隐藏与提取
import cv2
import numpy as np
# 以单通道灰度图为例
img = cv2.imread("flower.jpg",0)
watermark = cv2.imread("dollar.jpg",0)
cv2.imshow("org watermark",watermark)
# 将水印图的像素值处理为0和1,方便嵌入
mask1 = watermark[:,:]>100
mask2 = watermark[:,:]<=100
watermark[mask1] = 1
watermark[mask2] = 0
cv2.imshow("watermark--",watermark)
h,w = img.shape
# 构造矩阵
t254_matrix = np.ones((h,w),dtype=np.uint8)*254
# 按位与,获取img的高7位, 擦除最低有效位
img_H7 = cv2.bitwise_and(img,t254_matrix)
# 按位或,将水印嵌入高7位图中
embedding = cv2.bitwise_or(img_H7,watermark)
print("embedding:",embedding,embedding.shape)
# 从嵌入图中 提取出来 水印图
t1_matrix = np.ones((embedding.shape),dtype=np.uint8)
print("t1_matrix:",t1_matrix,t1_matrix.shape)
# 提取出来水印图
wm = cv2.bitwise_and(embedding,t1_matrix)
print("wm:",wm,wm.shape)
wm[wm[:,:]>0] = 255
# 显示
cv2.imshow("original",img)
cv2.imshow("t254_matrix",t254_matrix)
cv2.imshow("img_H7",img_H7)
cv2.imshow("watermark",watermark)
cv2.imshow("embedding",embedding)
cv2.imshow("t1_matrix",t1_matrix)
cv2.imshow("restore watermark",wm)
cv2.waitKey()
cv2.destroyAllWindows()
实际应用时候,可以使用彩色图,用多通道分解就可以操作。不过此法过于简单,实际上会有许多复杂的方式实现水印的嵌入。
三、翻转与旋转
1.翻转
# flip(src, flipCode[, dst]) -> dst
# flipCode = 0:垂直翻转
# flipCode < 0:垂直 + 水平翻转
# flipCode > 0:水平翻转
img0 = cv2.flip(img,0)
imgLow0 = cv2.flip(img,-1)
imgGreat0 = cv2.flip(img,1)
2.旋转
作用: 以图片中心,对图片进行旋转,角度只能为 180,顺时针 90,逆时针90。
# rotate(src, rotateCode[, dst]) -> dst
# roteCode:cv2.ROTATE_180 cv2.ROTATE_90_CLOCKWISE cv2.ROTATE_90_COUNTERCLOCKWISE
imgr = cv2.rotate(img,cv2.ROTATE_180)Copy to clipboardErrorCopiedTip
翻转不会改变原来图片的np.ndarray.shape,旋转90°会修改。
四、仿射变换
仿射变换中集合中的一些性质保持不变:
- 共线性:若几个点变换前在一条线上,则仿射变换后仍然在一条线上
- 平行性:若两条线变换前平行,则变换后仍然平行
- 共线比例不变性:变换前一条线上的两条线段的比例在变换后比例不变
数学表达式:
①平移

②缩放

③旋转

变换矩阵

变换叠加

变换矩阵的逆推

OpenCV代码
' 获取逆时针旋转转变换矩阵
# center,旋转中心
# angle,逆时针旋转角度
# scale,图片缩放值
cv2.getRotationMatrix2D(center: tuple, angle, scale) -> M
'仿射变换矩阵逆推
# src:3x2 的 numpy.ndarray 矩阵,数据类型为 np.float
# dst:3x2 的 numpy.ndarray 矩阵,数据类型为 np.float
cv2.getAffineTransform(src, dst) -> M
'根据变换矩阵生成图像
# M :仿射变换矩阵
# src : 图像
# dsize :输出图片的大小
# dst : 保存的目标
# flags:图片的插值算法,默认算法就不错
# borderMode:图像边界扩展,同上文的扩边,默认为cv2.BORDER_CONSTANT,(0,0,0),运算时先扩边再仿射变换
cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) -> dst
Tip
仿射变换矩阵M为2x3的numpy.ndarray矩阵且类型为dtype =np.float。因为最后一行都为[0,0,1],所以省略了。

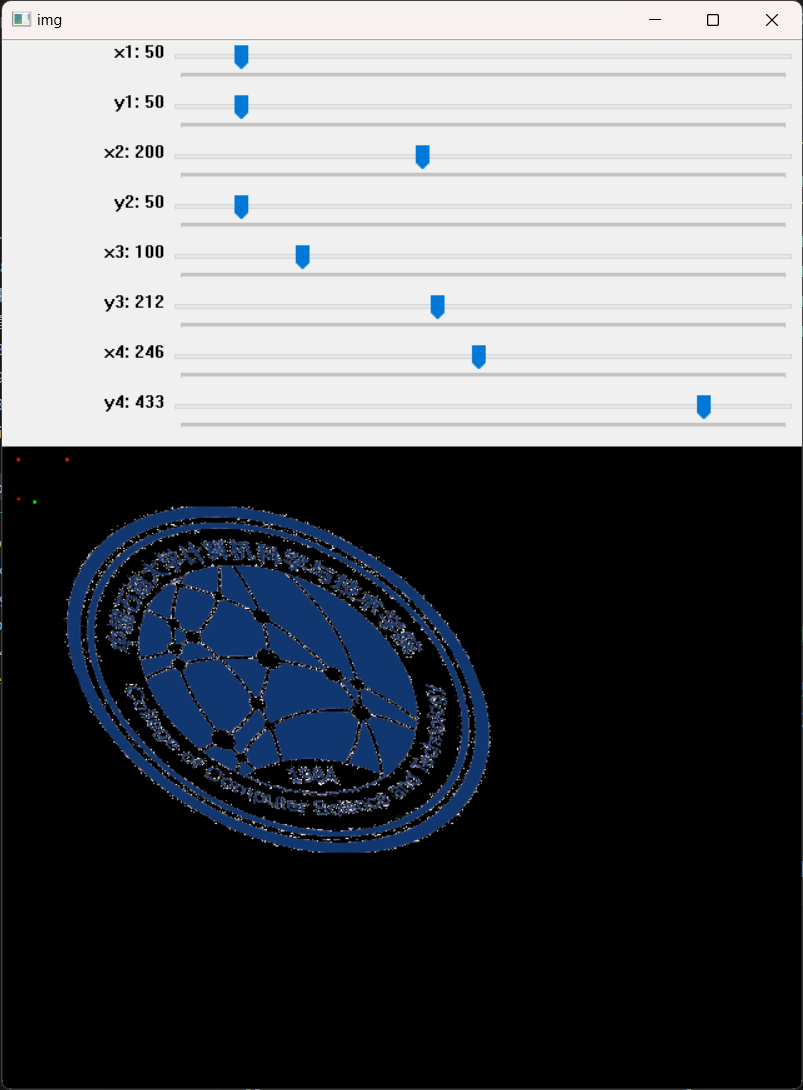
import cv2
import numpy as np
import matplotlib.pyplot as plt
def onTrackbarChange(x):
pass
img=cv2.imread('F:/program/python/computer.png')
cv2.namedWindow('img',cv2.WINDOW_NORMAL)
cv2.resizeWindow('img',640,840)
cv2.createTrackbar('x1','img',50,500,onTrackbarChange)
cv2.createTrackbar('y1','img',50,500,onTrackbarChange)
cv2.createTrackbar('x2','img',200,500,onTrackbarChange)
cv2.createTrackbar('y2','img',50,500,onTrackbarChange)
cv2.createTrackbar('x3','img',100,500,onTrackbarChange)
cv2.createTrackbar('y3','img',250,500,onTrackbarChange)
cv2.createTrackbar('x4','img',200,500,onTrackbarChange)
cv2.createTrackbar('y4','img',200,500,onTrackbarChange)
while 1:
x1 = cv2.getTrackbarPos('x1','img')
y1 = cv2.getTrackbarPos('y1','img')
x2 = cv2.getTrackbarPos('x2','img')
y2 = cv2.getTrackbarPos('y2','img')
x3 = cv2.getTrackbarPos('x3','img')
y3 = cv2.getTrackbarPos('y3','img')
x4 = cv2.getTrackbarPos('x4','img')
y4 = cv2.getTrackbarPos('y4','img')
#M=cv2.getRotationMatrix2D((img.shape[0]//2,img.shape[1]//2),angle,scale)
iimg=img.copy()
pts1=np.float32([[50,50],[200,50],[50,200]])
pts2=np.float32([[x1,y1],[x2,y2],[x3,y3]])
M=cv2.getAffineTransform(pts1,pts2)
M[0][2]=M[0][2]+x4-200
M[1][2]=M[1][2]+y4-200
print(M)
img2=cv2.warpAffine(iimg, M, (img.shape[0]*2,img.shape[1]*2))
for c in pts2.tolist():
cv2.circle(img2,(int(c[0]),int(c[1])),5,(0,255,0),-1,16)
for c in pts1.tolist():
cv2.circle(img2,(int(c[0]),int(c[1])),5,(0,0,255),-1,16)
cv2.imshow('img',img2)
if cv2.waitKey(1)==27: break
cv2.destroyAllWindows()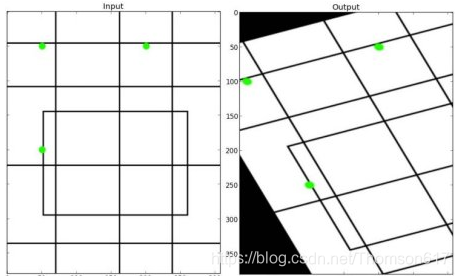

五、透视变换
1.齐次坐标
仿射变换中,用来表示「二维像素位置」的坐标为
从形式上来说,这就是用了「三维坐标」来表示「二维坐标」,即 降维打击。再将1进行符号化,用w进行代替
这种表达 n-1 维坐标的 n 维坐标,就被称之为「齐次坐标」。
2.透视
透视的目的就是实现 近大远小,也就是需要有纵向的深度,而像素位置 (x,y) 只能表示像素在平面上的位置关系,此时「齐次坐标」就能排上用场了。三维的齐次坐标虽然表示的二维的平面,但是其本质还是一个三维空间的坐标值,这样就能将图片像素由「二维空间」扩展到「三维空间」进行处理,齐次坐标的 w 分量也就有了新的含义:三维空间的深度。
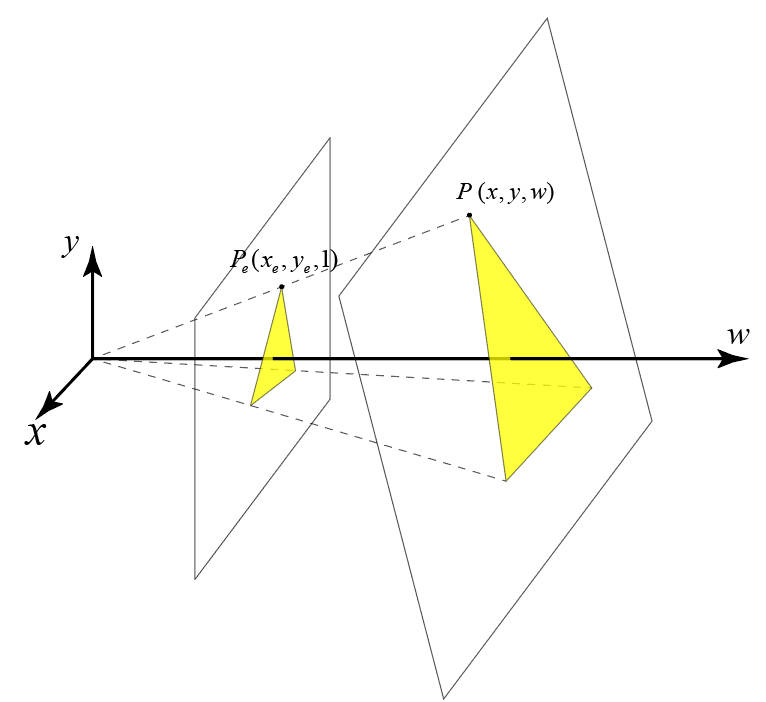
在「仿射变换」中,像素的齐次坐标为 [𝑥,𝑦,1]𝑇,可以解释为图像位于三维空间 的 𝑤=1 平面上,即 𝑤=1平面就是我们在三维空间中的视线平面(三维空间中的所有东西都被投影到 𝑤=1平面,然后我们才能看见)。「透视」就规定了所有物体如何投影到视线平面上,即「近大远小」。数学描述就是根据像素三维空间中的坐标点 𝑃(𝑥,𝑦,𝑤) 得出像素在视线平面上的坐标 𝑃𝑒(𝑥𝑒,𝑦𝑒,1),两个关系如图所示,根据三角形相似定理就能得出:
整理得:
上述公式就实现了三维空间像素坐标向视线平面的透视投影。
3.透视变换

根据「仿射变换」可知,上述矩阵就能实现图片像素坐标 [𝑥𝑒,𝑦e,1]𝑇 在三维空间中的旋转、缩放、切变的变换操作(没有三维空间的平移,变换矩阵差一个维度),得到像素位置变换后的三维坐标就为 [𝑥,𝑦,𝑤]𝑇。再将新的像素齐次坐标进行透视处理,将坐标映射到 𝑤=1 平面, 得到的像素位置就是最终「透视变换」的结果。
因此透视变换的变换矩阵就能改写为
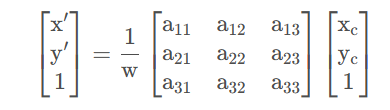
由于 w 是一个常量,也可以放入变换矩阵:

将矩阵拆解
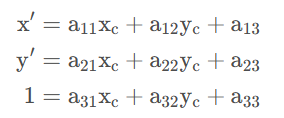

Tip
从最后的公式形式可以看出,仿射变换其实就是透视变换的一种特例,仿射变换只是 𝑤=1w=1 的平面内进行平移、缩放、旋转等。
4.透视变换逆推

对于视角变换,我们需要一个 3x3 变换矩阵。在变换前后直线还是直线。 要构建这个变换矩阵,你需要在输入图像上找 4 个点,以及他们在输出图 像上对应的位置。这四个点中的任意三个都不能共线。这个变换矩阵可以有 函数 cv2.getPerspectiveTransform() 构建。然后把这个矩阵传给函数 cv2.warpPerspective()。
5.OpenCV代码
'逆向计算透视变换矩阵
# srcPoints : 像素点坐标
# dstPoints : 像素点坐标
cv2.getPerspectiveTransform(srcPoints:np.ndarray, dstPoints:np.ndarray[, solveMethod]) -> retval
'透视变换
# src :图片
# M :透视变换矩阵 3x3
# dsize : 要显示的图片大小
cv2.warpPerspective(src:image, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) -> dst:imageNote
srcPoints,dstPoints的 dtype 必须写为 np.float32,而非np.float、np.float。
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
def mouse(event,x,y,flag,userdata):
print(event,x,y,flag)
img=cv.imread('read.jpg')
cv.namedWindow('img',cv.WINDOW_NORMAL)
cv.resizeWindow('img',640,480)
cv.namedWindow('img2',cv.WINDOW_NORMAL)
cv.resizeWindow('img2',640,480)
cv.setMouseCallback('img',mouse,None)
pts1=np.float32([(2370,700),(3760,890),(2438,1768),(3894,1722)])
pts2=np.float32([(0,0),(3000,0),(0,2400),(3000,2400)])
M=cv.getPerspectiveTransform(pts1,pts2)
img2=cv.warpPerspective(img,M,(3000,2400))
for p in pts1:
cv.circle(img,(int(p[0]),int(p[1])),15,(0,255,0),-1)
pts=np.array(pts1,int)
cv.polylines(img,[pts],1,(0,255,0),8,16)
cv.imshow('img',img)
cv.imshow('img2',img2)
cv.waitKey(0)
cv.destroyAllWindows()
图像处理
一、图像阈值
1.全局阈值
cv2.threshold()
当像素值高于阈值时,我们给这个像素 赋予一个新值,否则我们给它赋予另外一种颜色。
cv2.threshold(
src: MatLike,#原图,多为灰度图
thresh: float,#阈值
maxval: float,#高于(或低于)阈值时赋予的值
type: int,#方式,包含:
''' cv2.THRESH_BINARY
cv2.THRESH_BINARY_INV
cv2.THRESH_TRUNC
cv2.THRESH_TOZERO
cv2.THRESH_TOZERO_INV'''
dst: MatLike | None = ...
) -> tuple[float, MatLike]# 阈值,图像- cv2.THRESH_BINARY: 如果像素值大于阈值,则将其设置为 maxval,否则设置为 0。
- cv2.THRESH_BINARY_INV: 与 THRESH_BINARY 相反,如果像素值小于或等于阈值,则将其设置为 maxval,否则设置为 0。
- cv2.THRESH_TRUNC: 如果像素值大于阈值,则将其设置为阈值,否则保持不变。
- cv2.THRESH_TOZERO: 如果像素值大于阈值,则保持不变,否则将其设置为 0。
- cv2.THRESH_TOZERO_INV: 如果像素值小于或等于阈值,则保持不变,否则将其设置为 0
-

2.自适应阈值
全局阈值,整幅图像采用同一个数作为阈值。但这种方法并不适应一幅图像上有明暗分布。
cv2.adaptiveThreshold()
自适应阈值是根据图像上的 每一个小区域计算与其对应的阈值。因此在同一幅图像上的不同区域采用的是不同的阈值,从而在亮度不同的情况下得到更好的结果。
cv2.adaptiveThreshold(
src: MatLike,
maxValue: float,
adaptiveMethod: int,'''cv2.ADAPTIVE_THRESH_MEAN_C 阈值取自相邻区域的平均值
cv2.ADAPTIVE_THRESH_GAUSSIAN_C 阈值取值相邻区域的加权和,权重为一个高斯窗口'''
thresholdType: int,#同全局阈值
blockSize: int,#邻域的大小
C: float,#一个常数,阈值等于的平均值或者加权平均值减去这个常数
dst: MatLike | None = ...
) -> MatLike3.OTSU二值化(自动计算全局阈值)
在使用全局阈值时,要不停的尝试不同的阈值,十分麻烦。如果是一副双峰图像(简单来说双峰图像是指图像直方图中存在两个峰)呢? Otsu 二值化会在两个峰之间的峰谷选一个值作为阈值。就是对 一副双峰图像自动根据其直方图计算出一个阈值。(对于非双峰图像,这种方法得到的结果可能会不理想)即二值化两类图像面积相差不大时效果最好
任然是cv2.threshold()
参数flag:原来的参数+cv2.THRESH_OTSU。这时要把阈值设为 0。然后算法会找到最优阈值,这个最优阈值就是返回值 retVal。如果不使用 Otsu 二值化,返回的 retVal 值与设定的阈值相等。
cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)#灰度图工作原理:
因为是双峰图,Otsu 算法就是要找到一个阈值(t), 使得同一类加权方差最小,需要满足下列关系式:
![]()
其中:
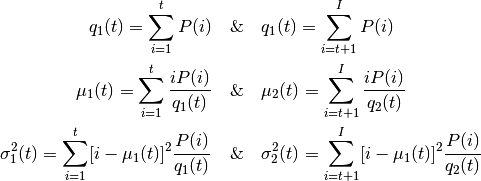
其实就是在两个峰之间找到一个阈值 t,将这两个峰分开,并且使每一个 峰内的方差最小。
二、图像滤波&边缘检测
1.2D卷积操作(图像过滤)
与一维信号一样,还可以使用各种低通滤波器(LPF),高通滤波器(HPF)等对图像进行滤波。LPF有助于消除噪声,使图像模糊等。HPF滤波器有助于在图像中找到边缘。OpenCV 提供的函数 cv.filter2D() 可以对一幅图像进行卷积操作。下面是一个 5x5 的平均滤波器核:
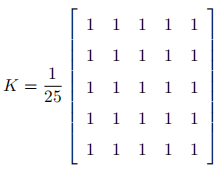
操作如下:将核放在图像的一个像素 A 上,求与核对应的图像上 25(5x5) 个像素的和,在取平均数,用这个平均数替代像素 A 的值。重复以上操作直到 将图像的每一个像素值都更新一遍。(该操作相当于平均模糊)

# ddepth:图片位深,-1 为默认值
# kernel:卷积核,数据类型为 np.float
# delta:卷积计算后的偏移量 src * kernel + delta
cv2.filter2D(src, ddepth, kernel:np.ndarray[, dst[, anchor[, delta[, borderType]]]]) -> dst- src: 输入图像。它应该是一个单通道或多通道的8位或32位浮点图像。
- ddepth: 输出图像的深度。常见的选择有 -1(与源图像相同)、cv2.CV_8U(8位无符号整数)、cv2.CV_16U(16位无符号整数)、cv2.CV_16S(16位有符号整数)、cv2.CV_32F(32位浮点数)和 cv2.CV_64F(64位浮点数) 等。这个参数决定了输出图像的数据类型和可能的范围。
- kernel: 一个 NumPy 数组,表示卷积核或滤波器。其大小和形状决定了滤波器如何与图像进行卷积。
以下参数是可选的:
- dst: 输出图像。如果未提供,则会自动创建一个与 src 相同大小和类型的图像。
- anchor: 卷积核的锚点,即卷积核与图像中某个点对齐的点。默认是卷积核的中心。
- delta: 在卷积结果上添加的可选值。默认是0。
- borderType: 指定如何处理图像边界的像素。常见的选择有 cv2.BORDER_DEFAULT, cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE 等。
2.低通滤波(模糊)
- 消除图片中的高斯噪声
- 消除图片中的椒盐噪声
- 图片模糊
①方盒滤波和均值滤波
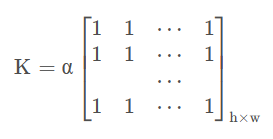
- 正交化:
,即将卷积核对应的值全部相加,再求平均。正交化的方盒滤波也称之为「均值滤波」
# 方盒滤波
cv2.boxFilter(src, ddepth, kernelSize:tuple[, dst[, anchor[, normalize[, borderType]]]]) -> dst
# 均值滤波
cv2.blur(src, kernelSize:tuple[, dst[, anchor[, borderType]]]) -> dst- src:输入图像,可以是灰度图(单通道)或彩色图(多通道)。
- ddepth:输出图像的深度。如果设置为 -1,则输出图像与输入图像具有相同的深度。通常,为了防止数据溢出,我们可以选择一个更大的数据类型
- kernelSize:一个二元组,表示滤波器的核大小(宽度和高度)。它必须是正奇数。例如,(3, 3) 表示一个 3x3 的滤波器。
- anchor:核的锚点,即滤波器中相对中心点的位置。锚点表示滤波器中哪个像素点将被视为与当前像素点对齐。默认情况下,锚点位于核的中心。如果核大小是奇数,它通常会被自动设置为中心。
- normalize:一个可选的布尔值,指定是否对滤波后的值进行归一化。如果为 True,则滤波器会计算其邻域内的像素值的平均值(即均值滤波);如果为 False,则滤波器会计算其邻域内的像素值的总和(这通常被称为积分图像)。默认情况下,normalize 是 True。
- borderType:像素外推法选择,用于确定图像边界外的像素值。例如,cv2.BORDER_DEFAULT、cv2.BORDER_CONSTANT 等。

②高斯滤波
现在把卷积核换成高斯核(原来每个方框的值是相等的,现在里面的值是符合高斯分布的,方框中心的值最大,其余方框根据距离中心元素的距离递减。原来的求平均数现在变成求加权平均数)。
实现的函数是 cv2.GaussianBlur()。我们需要指定高斯核的宽和高(必须是奇数)。以及高斯函数沿 X,Y 方向的标准差。如果我们只指定了 X 方向的的标准差,Y 方向也会取相同值。如果两个标准差都是 0,那么函数会根据核函数的大小自己计算。高斯滤波可以有效的从图像中去除高斯噪音。
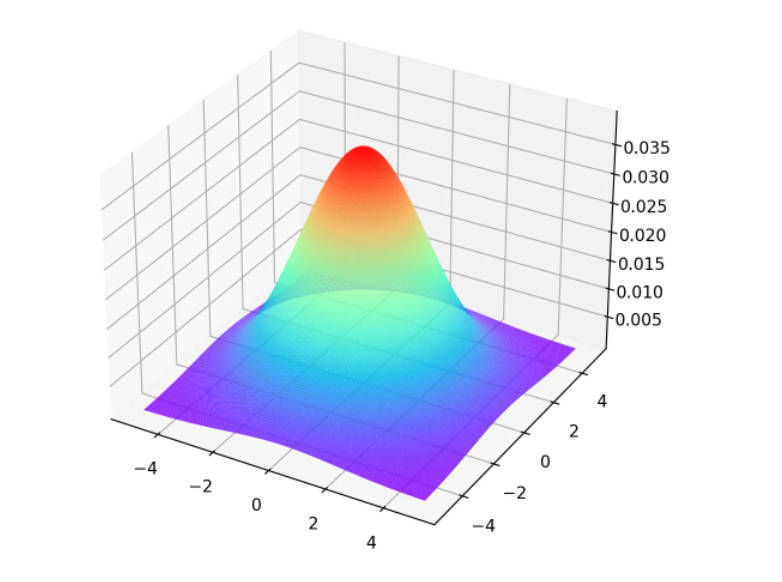
你也可以使用函数 cv2.getGaussianKernel() 自己构建一个高斯核。
cv2.GaussianBlur(src, kernelSize:tuple, sigmaX[, dst[, sigmaY[, borderType]]]) -> dst- kernelSize:高斯核的大小。元组,高斯核的宽和高。是正奇数(如 (3, 3),(5, 5) 等)
- sigmaX:X 方向的标准差。它决定了模糊的程度。值越大,模糊效果越明显。
- sigmaY(可选):Y 方向的标准差。如果 sigmaY 为零,那么它会等于 sigmaX。如果 sigmaY 和 sigmaX 都是零,那么它们将根据核大小计算。
- borderType(可选):像素外推法。当核覆盖图像的边界时,指定如何计算那些像素的值。常见的值有 cv2.BORDER_DEFAULT、cv2.BORDER_CONSTANT、cv2.BORDER_REPLICATE 等。如果未指定,则使用默认值。

③中值滤波
用与卷积框对应像素的中位数来替代中心像素的值。这个滤波器经常用来去除椒盐噪声。卷积核的大小也应该是一个奇数。
cv2.medianBlur(src, kernelSize:int[, dst]) -> dst
④双边滤波
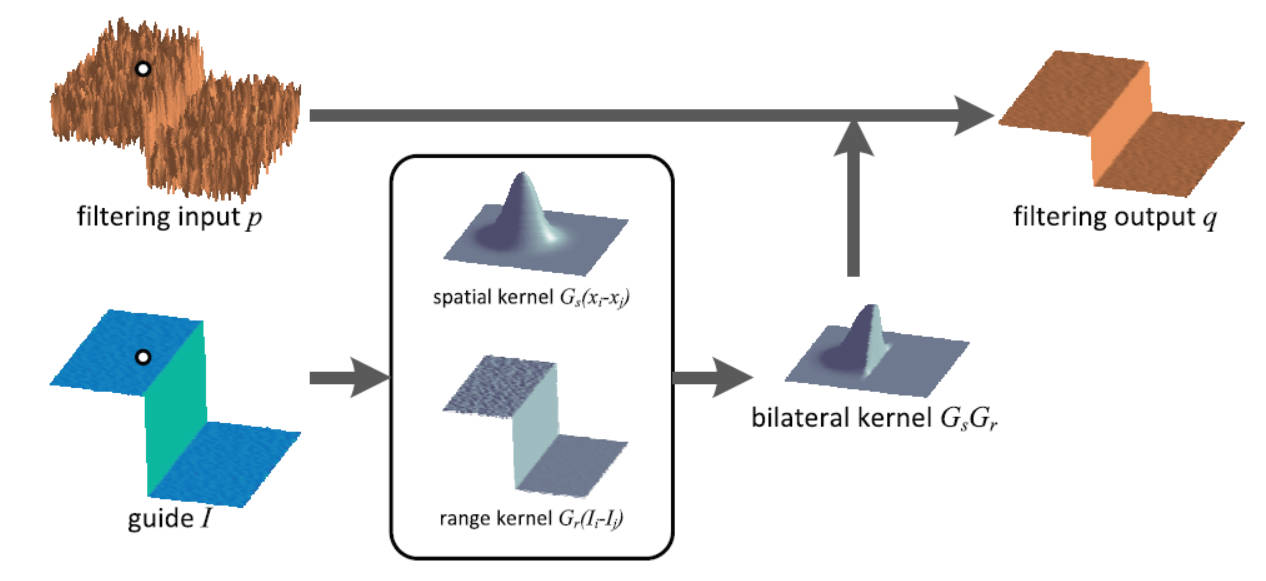
函数 cv2.bilateralFilter() 能在保持边界清晰的情况下有效的去除噪音。但是这种操作与其他滤波器相比会比较慢。
双边滤波在同时使用空间高斯权重和灰度值相似性高斯权重。空间高斯函数确保只有邻近区域的像素对中心点有影响,灰度值相似性高斯函数确保只有与中心像素灰度值相近的才会被用来做模糊运算。所以这种方法会确保边界不会被模糊掉,因为边界处的灰度值变化比较大。
算法思路: 在高斯滤波的基础上在添加一个灰度距离权重。灰度距离越大,灰度距离权重越小,这样像素在高斯模糊中的占比就越小,进而实现只对颜色相近的像素进行高斯滤波

cv2.bilateralFilter(src, kernelSize:int, sigmaColor, sigmaSpace[, dst[, borderType]]) -> dst- kernelSize:int:滤波器核的大小。
- sigmaColor:颜色空间的标准差。它决定了哪些颜色与中心颜色相近。较大的值意味着较远的颜色也会被认为是相似的,从而可能导致图像的边缘模糊。
- sigmaSpace:坐标空间的标准差。它决定了在多大的邻域内进行滤波。较小的值意味着只有颜色相近且空间距离近的像素才会影响输出。

3.高通滤波 (图像梯度)
- 边缘监测
- 图像边缘:图像的灰度图中,相邻像素灰度值差距较大的位置
①sober算子
- 原理:对图像邻近的灰度像素进行求导,斜率较大的地方,边缘的概率最大。
- 差分法:图像中近似求导的方法
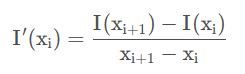
这里只对像素的一个方向进行求偏导(x方向或者y方向)。求导的实际操作仍然是卷积操作,所以对于分母差值也可以省略掉
![]()
- 卷积核
x方向求偏导:提取竖向的边缘,目标像素左右的像素进行差值计算
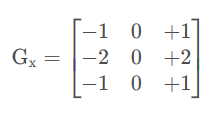
y方向求偏导:提取横向的边缘,目标像素上下的像素进行差值计算
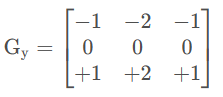
# ddepth:cv2.CV_, 结果图像的位深
# dx:对 x 方向求偏导
# dy:对 y 方向求偏导
# ksize:卷积核大小
cv2.Sobel(src, ddepth, dx:bool, dy:bool[, dst[, ksize:int[, scale[, delta[, borderType]]]]]) -> dst
# src中的数据取绝对值
cv2.convertScaleAbs(src[, dst[, alpha[, beta]]]) -> dst- ddepth:输出图像的深度(数据类型)。常见的选项有:
-
- cv2.CV_8U:8位无符号整数
- cv2.CV_16U:16位无符号整数
- cv2.CV_16S:16位有符号整数 <---
- cv2.CV_32F:32位浮点数
- cv2.CV_64F:64位浮点数
使用 cv2.CV_8U 可能会导致数据溢出,因此,在深度计算时通常建议使用较大的深度值,然后再将结果转换为 cv2.CV_8U,如果必要的话。
- dx 和 dy:分别表示沿 x 和 y 方向导数的阶数。通常,你会设置其中一个为 1,另一个为 0,以计算沿特定方向的边缘。例如,(dx=1, dy=0) 计算 x 方向的边缘,(dx=0, dy=1) 计算 y 方向的边缘。
- ksize:Sobel 核的大小。它必须是 1, 3, 5 或 7。默认值是 3。
- scale、alpha:可选参数,计算导数时的可选缩放因子。默认情况下,没有缩放(即 scale=1)。
- delta、bata:可选参数,一个常量值,会被加到像素值上。这可以用于调整图像的亮度。默认值为 0,即不添加任何偏移。
Note
- Sobel计算,会导致像素值为负,因此输出图像的位深ddepth应当使用「有符号类型」,例如cv2.CV_16S、cv2.CV_32F等
- 颜色通道数值不存在负数,所以还需要对计算结果取绝对值convertScaleAbs
- 对于横向、竖向的边界提取要分两次进行,然后add或位或运算,一起提取效果很差。

②scharr算子
- 对 Sobel 算子的改进。
- 卷积核: 卷积核大小固定3x3
-
- x方向求偏导:提取竖向的边缘,目标像素左右的像素进行差值计算
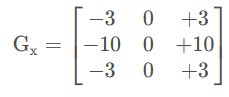
-
- y方向求偏导:提取横向的边缘,目标像素上下的像素进行差值计算
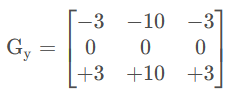
cv2.Scharr(src, ddepth, dx, dy[, dst[, scale[, delta[, borderType]]]]) -> dstdxdy不能同时为1
③Laplacian (拉普拉斯) 算子
思想: Sobel算子是对像素求解一阶导数,最大值处就是边缘;对一阶导数再求导,那么零值处就是边缘,但是,由于利用差分进行计算而且像素点也是离散的,进度丢失大,这个「零」的表现其实不明显。边界显示的还是主要两边的峰值。
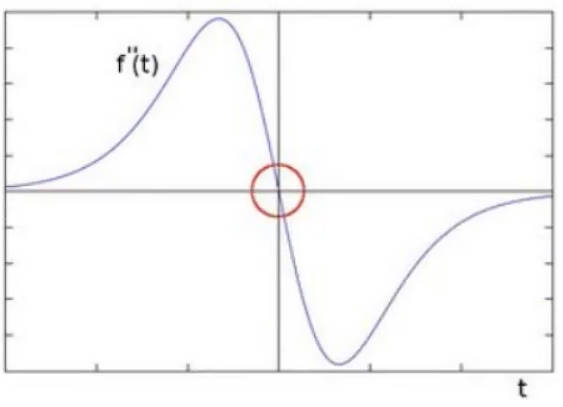
拉普拉斯(Laplacian)算子可以使用二阶导数的形式定义,可假设其离散实现类似于二阶 Sobel 导数,事实上,OpenCV 在计算拉普拉斯算子时直接调用 Sobel 算 子。计算公式如下:
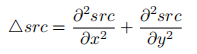
拉普拉斯滤波器使用的卷积核:
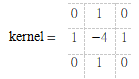
效果: 拉普拉斯算子处理渐变图的能力要强于Sobel算子
cv2.Laplacian(src, ddepth:cv2.CV_[, dst[, ksize:int[, scale[, delta[, borderType]]]]]) -> dstCopy to clipboardErrorCopied
4.Canny边缘检测
算法流程
1.使用5x5高斯滤波对图像进行滤波
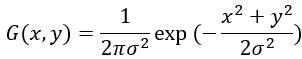
2.利用Sobel算子,计算x,y方向的梯度
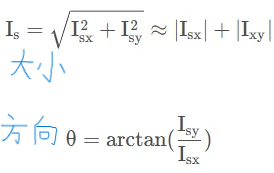
3.非极大值抑制
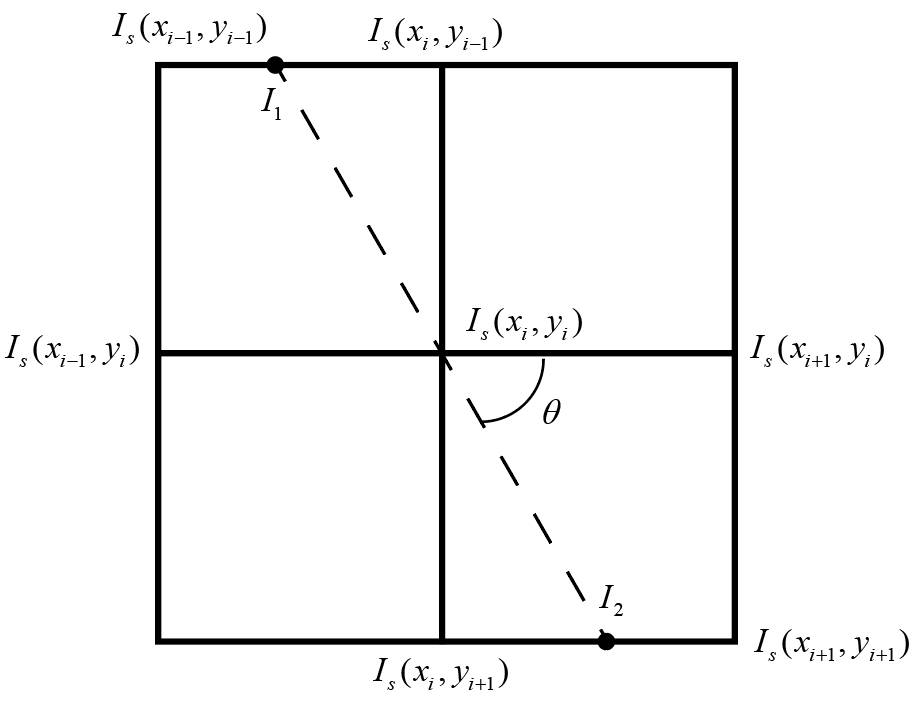
在获得梯度的方向和大小之后,对整幅图像做一个扫描,去除那些非边界上的点。对每一个像素进行检查,看这个点的梯度是不是周围具有相同梯度方向的点中最大的。有以下两个方法:
a. 线性差值法:对比 𝐼𝑠(𝑥𝑖 , 𝑦𝑖) 与 𝐼1 、𝐼2 的值,若 𝐼𝑠(𝑥𝑖 , 𝑦𝑖)最大,则保留作为边界,否则舍弃掉。𝐼1 、𝐼2根据 𝜃进行插值计算。
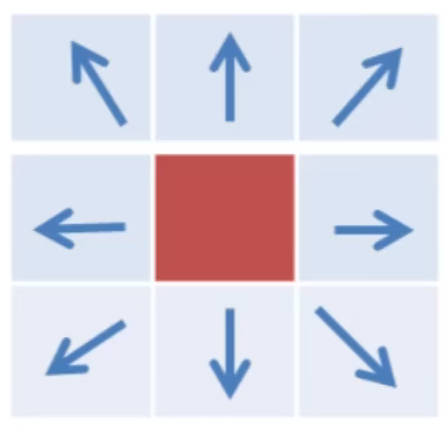
b. 角度近似:将中心点周围的像素非为8个方向(0°、45°、90°等),然后 𝜃 离哪个角度近,就用这个角度直线上的梯度值与中心点梯度进行比较,中心点最大就保留,否则舍弃。
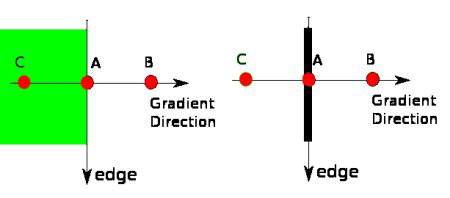
现在得到一个包含“窄边界”的二值图像。
4.双阈值检测:确定最终边缘
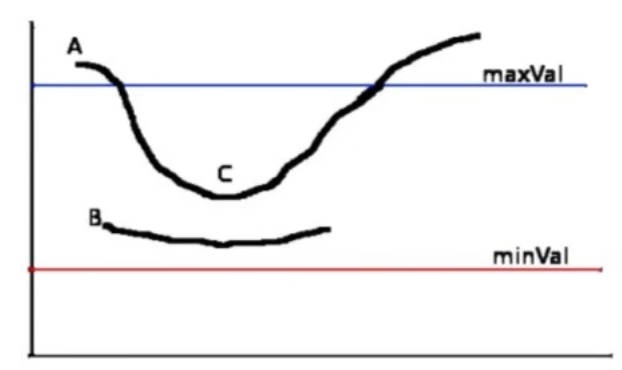
- 梯度 > maxVal :认为是边界像素
- 梯度 < minVal :绝对不是边界
- 梯度介于二者之间:判断当前像素是否和边界连着,若连着则保留,例如 `C`,否则舍弃掉,例如`B`
OpenCV代码

# threshold1:minVal
# threshold2:maxVal
# edges:可选,输出的图像
# apertureSize:(可选)用来计算图像梯度的 Sobel 卷积核的大小,默认值为 3
# L2gradient:布尔值,默认false,用来设定求梯度大小的方程。设为True使用更精确的sqrt(a**2+b**2),否则使用:|a|+|b|代替
cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]]) -> edges
import cv2
import numpy as np
from matplotlib import pyplot as plt
video=cv2.VideoCapture(0)
video.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
video.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
while video.isOpened():
flag,frame=video.read()
if flag:
frame=cv2.resize(frame,(frame.shape[1]//2,frame.shape[0]//2))
kernel = np.full((5,5),1,np.float32)/25
frame1=cv2.filter2D(frame,-1,kernel)
frame2=cv2.boxFilter(frame,-1,(5,5))
frame3=cv2.blur(frame,(5,5))
frame4=cv2.GaussianBlur(frame,(5,5),0)
frame5=cv2.medianBlur(frame,5)
frame6=cv2.bilateralFilter(frame,5,75,75)
frame71=cv2.Sobel(frame,cv2.CV_16S,1,0)
frame72=cv2.Sobel(frame,cv2.CV_16S,0,1)
frame7=cv2.add(cv2.convertScaleAbs(frame71),cv2.convertScaleAbs(frame72))
frame81=cv2.Scharr(frame,cv2.CV_16S,1,0)
frame82=cv2.Scharr(frame,cv2.CV_16S,0,1)
frame8=cv2.add(cv2.convertScaleAbs(frame81),cv2.convertScaleAbs(frame82))
frame9=cv2.Laplacian(frame,cv2.CV_16S,ksize=5)
frame9=cv2.convertScaleAbs(frame9)
frame10=cv2.Canny(cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY),30,50)
cv2.imshow('original',frame)
cv2.imshow('filter2D',frame1)
cv2.imshow('boxFilter',frame2)
cv2.imshow('blur',frame3)
cv2.imshow('GaussianBlur',frame4)
cv2.imshow('medianBlur',frame5)
cv2.imshow('bilateralFilter',frame6)
cv2.imshow('sober',frame7)
cv2.imshow('scharr',frame8)
cv2.imshow('laplacian',frame9)
cv2.imshow('canny',frame10)
if cv2.waitKey(1)==27:
break
e2 = cv2.getTickCount()
cv2.destroyAllWindows()三、形态学转换
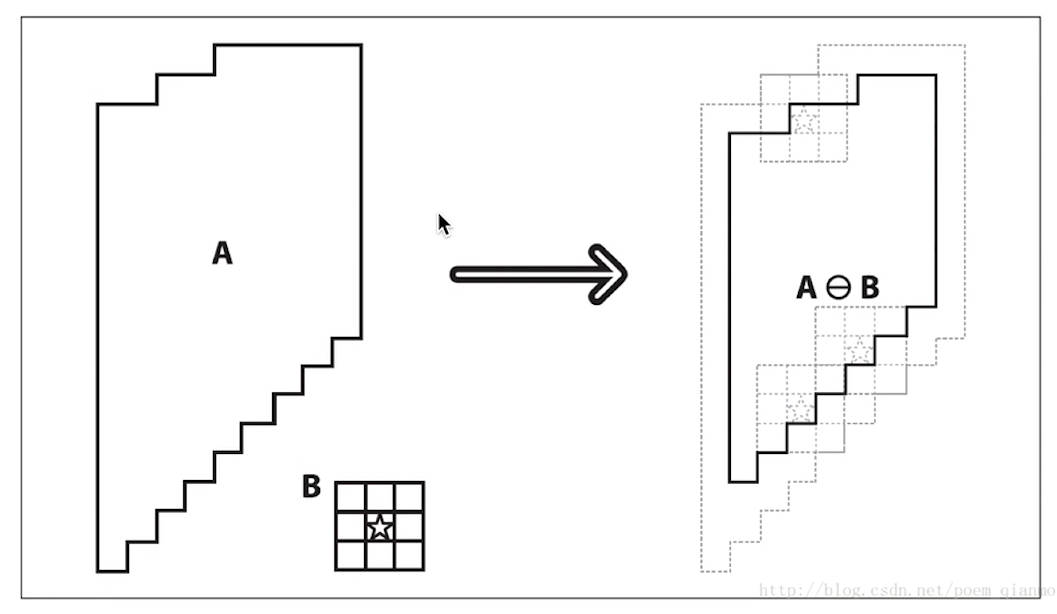
1.腐蚀
原理:卷积核沿着图像滑动,如果与卷积核值为1的对应的原图像的所有像素值都是 1,那么中心元素就保持原来的像素值,否则就变为零。
对于去除白噪声很有用,也可以用来断开两个连在一块的物体等
cv2.erode(src, kernel:np.ndarray[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) -> dst- kernel:腐蚀操作的核。这是一个 NumPy 数组,通常是一个二维矩阵,如 np.ones((5,5), np.uint8)。这个核决定了腐蚀操作的范围和形状。
- dst(可选):输出图像。与源图像具有相同的尺寸和类型。
- anchor(可选):核的锚点,指定了核的“中心”。默认是核的中心。这个参数通常不需要修改。
- iterations(可选):腐蚀操作的迭代次数。这决定了腐蚀的强度。默认值为1。
- borderType(可选):像素外推法。当核的一部分位于图像边界之外时,这个参数决定了如何处理这些边界像素。默认是 cv2.BORDER_CONSTANT。
- borderValue(可选):当使用 cv2.BORDER_CONSTANT 边界类型时,这个值会被用作边界值。默认是0。


· 结构化元素
# shape :cv2.MORPH_
cv2.getStructuringElement(shape, ksize[, anchor]) -> retval- shape:卷积核的形状。这可以是以下三种类型之一:
-
- cv2.MORPH_RECT:矩形
- cv2.MORPH_ELLIPSE:椭圆
- cv2.MORPH_CROSS:十字形
- ksize:卷积核的大小。它应该是一个二元组
- anchor(可选):锚点位置。默认是卷积核的中心点。
2.膨胀
若卷积核中值为1的地方存在1时,卷积核中心像素就为1
cv2.dilate(src, kernel:np.ndarray[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) -> dst

3.形态学操作
| 名称 | 操作 | OpenCV | 应用 |
| 开运算 | 先腐蚀、再膨胀 | cv2.MORPH_OPEN | 去除边界上的毛刺、去二值图的噪点 (去掉较小的形状) |
| 闭运算 | 先膨胀、再腐蚀 | cv2.MORPH_CLOSE | 中空形状或者邻近的形状形成一整块 |
| 梯度运算 | 膨胀 - 腐蚀 | cv2.MORPH_GRADIENT | 二值图的边缘 |
| 礼帽 | 原始 - 开运算 | cv2.MORPH_TOPHAT | 把由「开运算」去除的像素,从原图中截取出来。(去掉较大的形状) |
| 黑帽 | 闭运算 - 原始 | cv2.MORPH_BLACKHAT | 将「闭运算」填充的像素,从原图中截取出来 |
cv2.morphologyEx(src,op,kernel:np.ndarray[,dst[,anchor[,iterations[,borderType[,borderValue]]]]]) -> dst- op: 形态学操作的类型。它可以是以下值之一:
-
- cv2.MORPH_ERODE: 腐蚀
- cv2.MORPH_DILATE: 膨胀
- cv2.MORPH_OPEN: 开运算(腐蚀后膨胀)
- cv2.MORPH_CLOSE: 闭运算(膨胀后腐蚀)
- cv2.MORPH_GRADIENT: 梯度(膨胀减去腐蚀)
- cv2.MORPH_TOPHAT: 礼帽(原图像与开运算结果之差)
- cv2.MORPH_BLACKHAT: 黑帽(闭运算结果减去原图像)
- kernel: 结构元素或核。它定义了形态学操作的范围和形状。
- anchor: 结构元素的中心点的位置。默认为 (-1, -1),表示在核的中心。
- iterations: 操作的迭代次数。默认为 1。

开运算、闭运算、梯度运算、礼帽、黑帽
四、图像金字塔
有些情况下, 我们需要对同一图像的不同分辨率的子图像进行处理。比如,我们要在一幅图像中查找某个目标,比如脸,我们不知道目标在图像中的尺寸大小。这种情况下,我们需要创建一组图像,这些图像是具有不同分辨率的原始图像。我们把这组图像叫做图像金字塔(同一图像的不同分辨率的子图集合)。如果我们把最大的图像放在底部,最小的放在顶部,看起来像一座金字塔,故而得名图像金字塔。
1.高斯金字塔
高斯金字塔的顶部是通过将底部图像去除连续的行和列得到的。顶部图像中的每个像素值等于下一层图像中 5 个像素的高斯加权平均值。这样 操作一次一个 MxN 的图像就变成了一个 M/2xN/2 的图像。所以这幅图像 的面积就变为原来图像面积的四分之一。
- 向下采样(缩小图片):
-
- 首先进行高斯滤波
- 去除偶数的行、列
- 向上采用(放大图片):
-
- 用「零」填充偶数行、列

-
- 对放大的图片进行高斯卷积,将「零」值进行填充
# 向上采样,从一个低分辨率小尺寸的图像向下构建一个金子塔(尺寸变大,但分辨率不会增加)
cv2.pyrUp(src[, dst[, dstsize[, borderType]]]) -> dst
#dstsize:输出图像的大小。如果未指定,则使用 Size(src.cols*2, src.rows*2)。这是一个可选参数。
# 向下采样,从一个高分辨率大尺寸的图像向上构建一个金字塔(尺寸变小,分辨率降低)。
cv2.pyrDown(src[, dst[, dstsize[, borderType]]]) -> dst
#dstsize:输出图像的大小。如果未提供,则输出图像的大小将是源图像大小的一半(宽度和高度都减半)。2.拉普拉斯金字塔
![]()
迭代执行上面的公式,就能得到每一层的图像。
3.用金字塔实现图像融合拼接
图像金字塔的一个应用是图像融合。例如,在图像缝合中将两幅图叠在一起,但是由于连接区域图像像素的不连续性,整幅图的效果看起来会很差。这时图像金字塔就可以帮你实现无缝连接。这里的一个经典案例就是将两个水果融合成一个:

实现上述效果的步骤如下:
1. 读入两幅图像,苹果和橘子
2. 构建苹果和橘子的高斯金字塔(6 层)
3. 根据高斯金字塔计算拉普拉斯金字塔
4. 在拉普拉斯的每一层进行图像融合(苹果的左边与橘子的右边融合)
5. 根据融合后的图像金字塔重建原始图像。
下图是摘自《学习 OpenCV》展示了金子塔的构建,以及如何从金字塔重建原 始图像的过程。
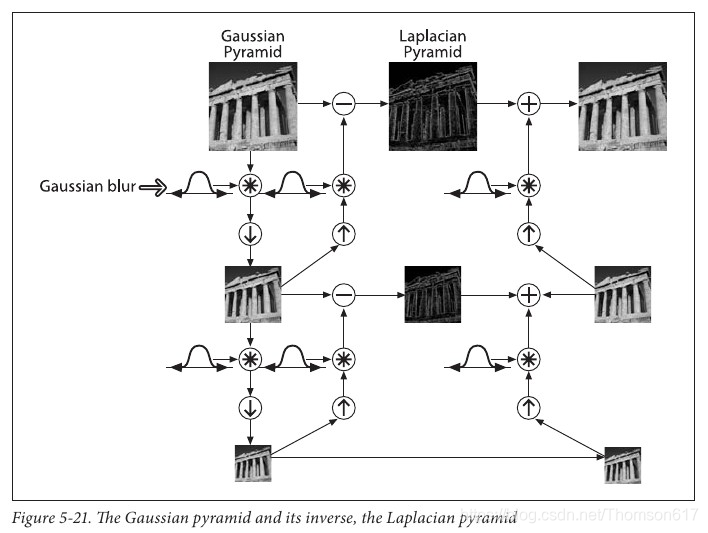
整个过程的代码如下。(为了简单,每一步都是独立完成的,这回消耗更多的内存,如果你愿意的话可以对他进行优化)
import cv2
import numpy as np
A = cv2.imread('apple.jpg')
B = cv2.imread('orange.jpg')
# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G)
# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G)
# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpA[i])
L = cv2.subtract(gpA[i-1],GE)
lpA.append(L)
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpB[i])
L = cv2.subtract(gpB[i-1],GE)
lpB.append(L)
# Now add left and right halves of images in each level
#numpy.hstack(tup)
#Take a sequence of arrays and stack them horizontally to make a single array.
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# now reconstruct
ls_ = LS[0]
for i in range(1,6):
ls_ = cv2.pyrUp(ls_)
ls_ = cv2.add(ls_, LS[i])
# image with direct connecting each half
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv2.imwrite('Pyramid_blending2.jpg',ls_)
cv2.imwrite('Direct_blending.jpg',real)五、直方图
1.对比度
定义: 一幅图像中明暗区域最亮的白和最暗的黑之间不同亮度层级的测量,即指一幅图像灰度反差的大小。差异范围越大代表对比越大,差异范围越小代表对比越小。 说人话,应该就是图片灰度图的明暗分布明显,数学上就是灰度值的差异大。

对比度计算案例
对比度计算案例

2.绘制直方图
直方图的横坐标为像素通道值的取值范围;纵坐标为数值出现的次数。
'OpenCV 方法'
# images:图像,输入 [ image ]
# channels:选择通道,输入 [ channel ],灰度图[0],bgr对应[0][1][2]
# mask:遮罩掩码,没有填None
# hisSize:有几根柱子,输入 [ hisSize ]
# range:取值范围
cv2.calcHist(images: List[Mat], channels: List[int],
mask: Mat | None, histSize: List[int], ranges: List[int]) -> hist
'matplotlib 方法'
# data :要绘制直方图的一维数据
# hisSize:柱子的个数
plt.hist(data,hisSize)Tip
推荐使用 matplotlib 方式,OpenCV 方式最后还得用 matplotlib 进行绘图。
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg',0)
plt.hist(img.ravel(),256,[0,256])
plt.show()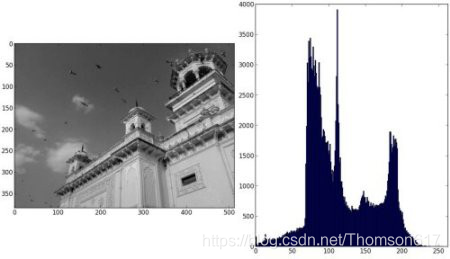
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg')
color = ('b','g','r')
# 对一个列表或数组既要遍历索引又要遍历元素时使用内置enumerrate函数会有更加直接,会将数组或列表组成一个索引序列。使我们再获取索引和索引内容的时候更加方便
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()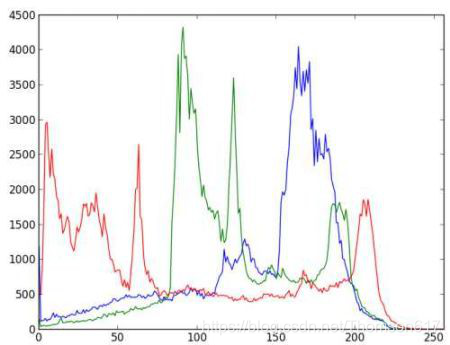
使用掩模
img = cv2.imread('home.jpg',0)
# create a mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
masked_img = cv2.bitwise_and(img,img,mask = mask)
# Calculate histogram with mask and without mask
# Check third argument for mask
hist_full = cv2.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv2.calcHist([img],[0],mask,[256],[0,256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask,'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0,256])
plt.show()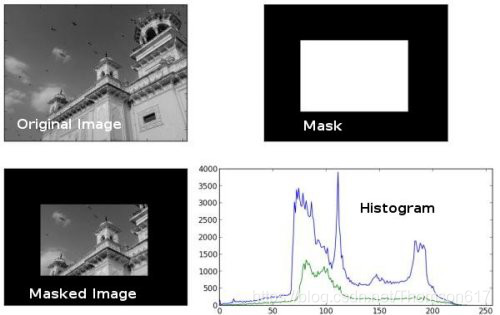
3.均衡化
如果一副图像中的大多是像素点的像素值都集中在一个像素值范围之内会怎样呢?例如,如果一幅图片整体很亮,那所有的像素值应该都会很高。但是一副高质量的图像的像素值分布应该很广泛。所以你应该把它的直方图做一个横向拉伸(如下图),这就是直方图均衡化要做的事情。通常情况下这种操作会改善图像的对比度。
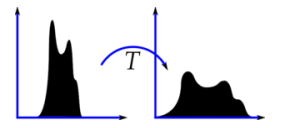
- 算法流程: 首先统计出灰度值与其出现次数的直方图;然后对灰度值升序排序;接着计算出现概率(出现次数 / 总像素),并根据灰度值从低到高计算累计概率(当前概率 + 之前的总概率);最后根据公式:累计概率 * (位深最大值 - 0),将数值映射到[位深最大值,0]。

cv2.equalizeHist(src:image[, dst]) -> dst:image#灰度图
4.CLAHE 有限对比适应性直方图均衡化
- 直方图均衡化问题:
-
- 为全局效果,这就导致图像中原来暗部和亮部的细节丢失,例如下图猫的帽子和左脚处。
- 可能导致噪点的放大。


- 思路: 将图片拆分为多个部分,然后每个部分分别进行均衡化处理,且对每个部分的直方图概率分布做限制(防止某个灰度值的概率分布过大,进而导致均衡化后的灰度值过大)。
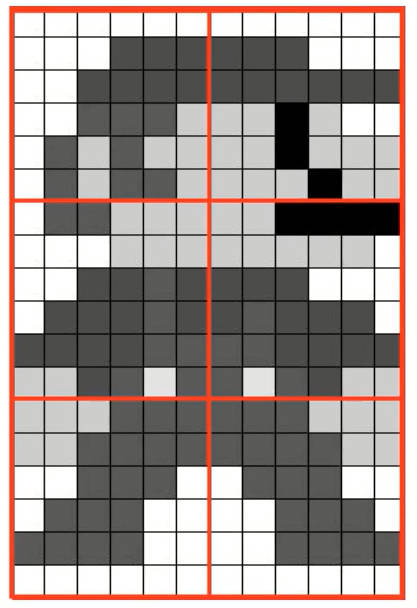
- 算法实现:
- 图像分块, 这些小块被称为“tiles”(在 OpenCV 中 tiles 的 大小默认是 8x8)
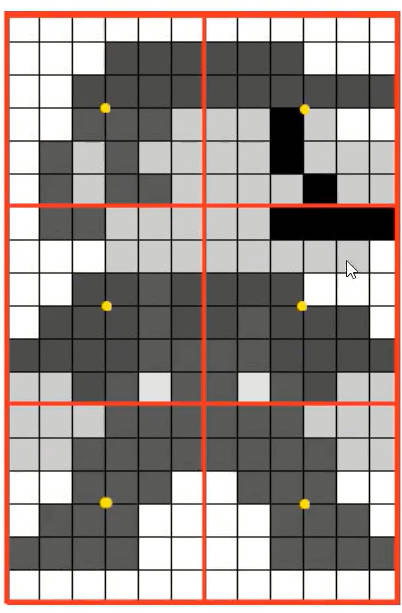
- 找每个块的中心点(黄色标记)
- 分别计算每个块的灰度直方图,并进行「阈值限制」
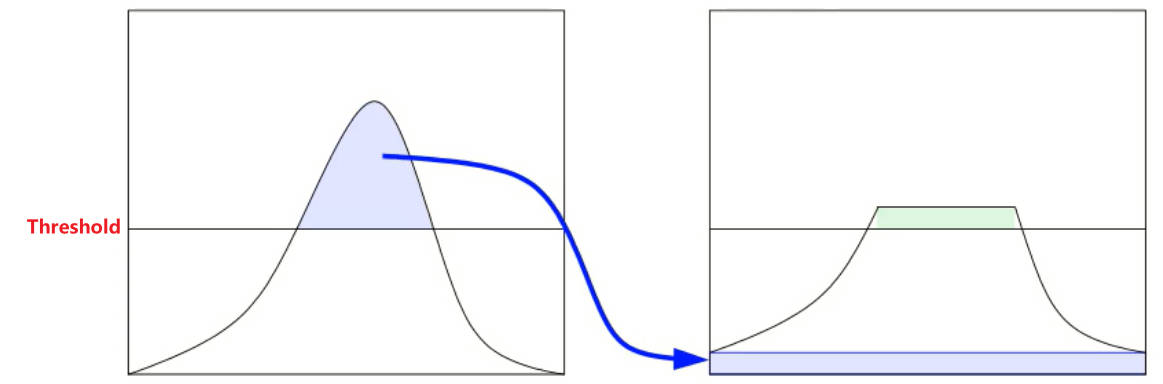
绘制好直方图后,柱子的分布值与设定「阈值」进行比较,超过阈值的部分则进行裁剪,并均匀分配给所有的柱子。分配后,直方图又要柱子超出时(绿色部分),继续重复上述操作,直至直方图柱子都在「阈值」下方。 现在只是对「直方图分布」进行修改,并没有修改原始图像的任何内容。
- 得到每个块的直方图分布后,根据直方图均衡化算法对每个块的中心点(黄色标记)进行均衡化处理。 只对中心点进行均衡化是为了加快计算速度,对每一个像素都进行处理会浪费很多时间。
- 根据中心点均衡化后的灰度值,利用插值算法计算图像块剩余像素的灰度值。插值算法计算效果和直接均衡化效果差不多,但是差值计算速度更快。
- 最后,为了去除每一个小块之间“人造的”(由于算法造成)边界,再使用双线性差值,对小块进行缝合。
# 生成自适应均衡化算法
# clipLimit :阈值,1 表示不做限制。值越大,对比度越大
# tileGridSize:如何拆分图像
clahe = cv2.createCLAHE([, clipLimit[, tileGridSize]]) -> retval
# 对像素通道进行自适应均值化处理
dst = clahe.apply(src)import numpy as np
import cv2
img = cv2.imread('tsukuba_l.png',0)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
cl1 = clahe.apply(img)
cv2.imwrite('clahe_2.jpg',cl1)
更多资源
1. 维基百科中的http://en.wikipedia.org/wiki/Histogram_equalization。
2. Masked arrays — NumPy v2.0 Manual
关于调整图片对比度 SOF 问题:
1. 在 C 语言中怎样使用 OpenCV 调整图像对比度.
六、傅里叶变换
1.原理
5.1. 二维傅里叶变换
- 思想: 二维傅里叶变换中,认为二维数据是由无数个「正弦平面波」所构成。
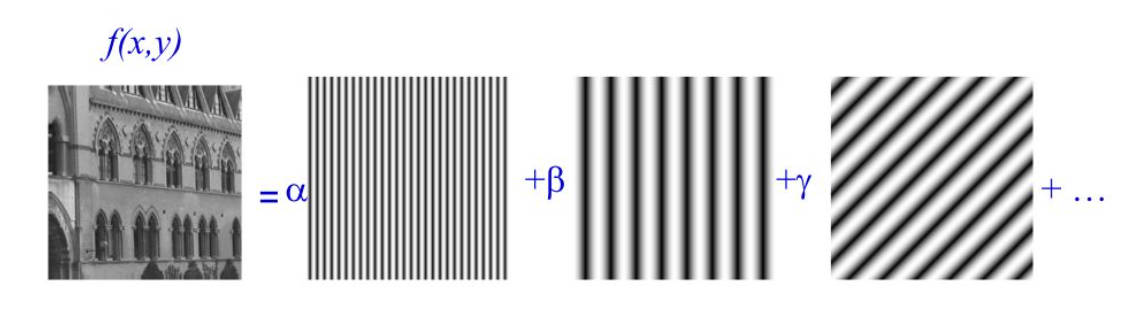
离散傅里叶变换公式:
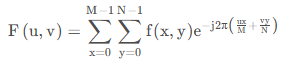
将二维数据进行傅里叶变换后得到的值 𝐹(𝑢,𝑢)F(u,u) 则代表了相应的「正弦平面波」
5.2. 正弦平面波
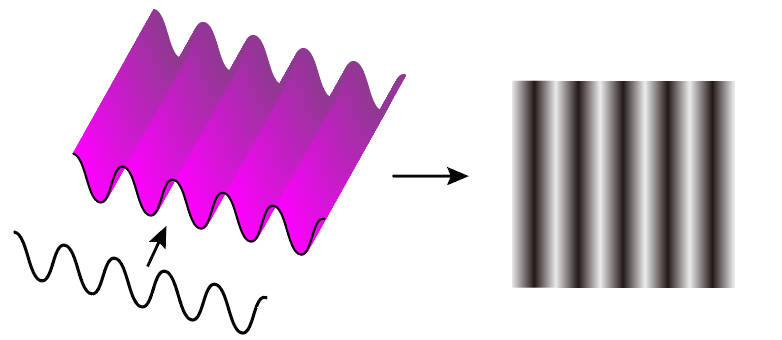
- 直观定义: 将一维正弦曲线朝着纵向的一个方向上将其拉伸得到一个三维的波形,然后将波形的幅值变化用二维平面进行表示,再将二维平面波绘制成灰度图,即波峰为白色、波谷为黑色。
- 数学参数:
-
- 正弦波:频率 𝑤 ,幅值 𝐴 ,相位 𝜑
- 拉伸方向:在二维坐标中,向量可以写为 𝑛⃗=(𝑢,𝑣)
5.3. 二维傅里叶变换结果𝐹(𝑢,𝑣)
- (𝑢,𝑣):拉伸方向的向量
- 𝑤=𝑢2+𝑣2:(𝑢,𝑣)向量的模表示正弦波频率
𝐹(𝑢,𝑣):复数,隐含了正弦波的幅值 𝐴 和相位 𝜑。下面用一维做解释,二维太复杂也不直观(主要是太难了,不想推。。。。)
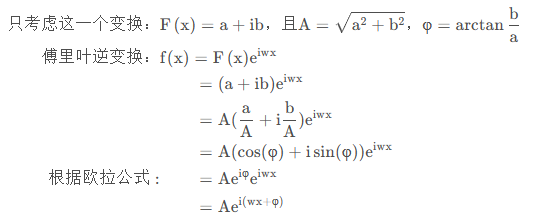
𝐴 就是幅值;𝜑 就是相位。
2.傅里叶变换
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('apple.jpg',0)
dft = np.fft.fft2(img) #傅里叶变换(numpy)
#dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT) #傅里叶变换(opencv)
dft_shift = np.fft.fftshift(dft) #将低频值移到中心
magnitude_spectrum = 20*np.log(np.abs(dft_shift)) #转换成灰度图能表示的格式
#magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))#opencv方法,需与变换对应
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()

而之前的几种滤波器经过傅里叶变换如下:

3.傅里叶滤波
- 思路:
-
- 对图像灰度进行傅里叶变换,得到频域结果
- 将要删除的频率所对应的傅里叶变换结果全部置为 0+𝑖00+i0
- 对修改后的傅里叶变换结果进行傅里叶反变换
低通滤波:只保留低频
高通滤波:只保留高频
import cv2
import numpy as np
# 图片读取
img = cv2.imread('./cat.jpeg')
yuv =cv2.cvtColor(img,cv2.COLOR_BGR2YUV)
# 将灰度值转浮点类型,傅里叶变换并中心化
yfloat = np.float32(yuv[:,:,0])
dft = cv2.dft(yfloat,flags=cv2.DFT_COMPLEX_OUTPUT)
dftShift = np.fft.fftshift(dft)
# 找到低频起始,中心化后频谱的中心位置
centerRow = int(dftShift.shape[0] / 2)
centerCol = int(dftShift.shape[1] / 2)
#低通滤波 掩模
mask = np.zeros(dftShift.shape,dtype=np.uint8)
mask[centerRow-50:centerRow+50,centerCol-50:centerCol+50,:] = 1
dftShift = dftShift * mask
'''#高通滤波 掩模
mask = np.ones(dftShift.shape,dtype=np.uint8)
mask[centerRow-50:centerRow+50,centerCol-50:centerCol+50,:] = 0
dftShift = dftShift * mask'''
# 反去中心。反傅里叶
dft = np.fft.ifftshift(dftShift)
idft = cv2.idft(dft)
# NOTE - 傅里叶变换结果仍然是一个复数,还要转为实数,
# 并且还要将浮点型映射为为(0 ~ 255)之间的 uint8 类型
iyDft = cv2.magnitude(idft[:,:,0],idft[:,:,1])
iy = np.uint8(iyDft/iyDft.max() * 255)
# 还原图片,还原颜色通道
yuv[:,:,0] = iy
imgRes = cv2.cvtColor(yuv,cv2.COLOR_YUV2BGR)
cv2.imshow('low pass',np.hstack((img,imgRes)))
cv2.waitKey(0)
cv2.destroyAllWindows()DFT 的性能优化
当数组的大小为某些值时 DFT 的性能会更好。当数组的大小是 2 的指数 时 DFT 效率最高。当数组的大小是 2,3,5 的倍数时效率也会很高。所以 如果你想提高代码的运行效率时,你可以修改输入图像的大小(补 0)。对于 OpenCV 你必须自己手动补 0。但是 Numpy,你只需要指定 FFT 运算的大 小,它会自动补 0。
那我们怎样确定最佳大小呢?OpenCV 提供了一个函数:cv2.getOptimalDFTSize()。 它可以同时被 cv2.dft() 和 np.fft.fft2() 使用。让我们一起使用 IPython 的魔法命令%timeit 来测试一下吧。
import cv2
img = cv2.imread('messi5.jpg',0)
rows,cols = img.shape
print("{} {}".format(rows,cols))
#342 548
nrows = cv2.getOptimalDFTSize(rows)
ncols = cv2.getOptimalDFTSize(cols)
print("{} {}".format(nrows,ncols))
#360 576数组的大小从(342,548)变成了(360,576)。现在我们 为它补 0,然后看看性能有没有提升。你可以创建一个大的 0 数组,然后把我 们的数据拷贝过去,或者使用函数 cv2.copyMakeBoder()。
nimg = np.zeros((nrows,ncols))
nimg[:rows,:cols] = img或者:
right = ncols - cols
bottom = nrows - rows
bordertype = cv2.BORDER_CONSTANT #just to avoid line breakup in PDF file
nimg = cv2.copyMakeBorder(img,0,bottom,0,right,bordertype, value = 0)现在我们看看 Numpy 的表现:
fft1 = np.fft.fft2(img)
#10 loops, best of 3: 40.9 ms per loop
fft2 = np.fft.fft2(img,[nrows,ncols])
#100 loops, best of 3: 10.4 ms per loop速度提高了 4 倍。我们再看看 OpenCV 的表现:
dft1= cv2.dft(np.float32(img),flags=cv2.DFT_COMPLEX_OUTPUT)
#100 loops, best of 3: 13.5 ms per loop
dft2= cv2.dft(np.float32(nimg),flags=cv2.DFT_COMPLEX_OUTPUT)
#100 loops, best of 3: 3.11 ms per loop也提高了 4 倍,同时我们也会发现 OpenCV 的速度是 Numpy 的 3 倍。
七、分水岭算法 图像分割
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成山峰,灰度值低的区域可以被看成山谷。我们向每一个山谷中灌不同颜色的水。随着水位的升高,不同山谷的水就会相遇汇合。为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝,直到所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。这就是分水岭算法背后的原理。
但这种方法通常都会得到过度分割的结果,这是由噪声或者图像中其它不规律的因素造成的。为了减少这种影响,OpenCV 采用了基于掩模的分水岭算法,在这种算法中我们要设置哪些山谷点会汇合,哪些不会。这是一种交互式的图像分割。我们要做的就是给已知的对象打上不同的标签。如果某个区域肯定是前景或对象,就使用某个颜色(或灰度值)标签标记它。如果某个区域肯定不是对象而是背景就使用另外一个颜色标签标记。而剩下的不能确定是前景还是背景的区域就用 0 标记。这就是我们的标签。然后实施分水岭算法。 每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后得到的边界对象(堤坝)的值为 -1。
下面的例子中将就和距离变换和分水岭算法对紧挨在一起的对象进行分割。如下图所示,这些硬币紧挨在一起。就算你使用阈值操作,它们任然是紧挨着的。

我们从找到硬币的近似估计开始。我们可以使用Otsu二值化。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('water_coins.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)结果:

现在我们要去除图像中的所有的白噪声。使用形态学中的开运算。 为了去除对象上小的空洞我们需要使用形态学闭运算。所以我们现在知道靠近对象中心的区域肯定是前景,而远离对象中心的区域肯定是背景。而不能确定的区域就是硬币之间的边界。 所以我们要提取肯定是硬币的区域。腐蚀操作可以去除边缘像素。剩下就可以肯定是硬币了。当硬币之间没有接触时,这种操作是有效的。但是由于硬币之间是相互接触的,我们就有了另外一个更好的选择:距离变换再加上合适的阈值。接下来我们要找到肯定不是硬币的区域。这时就需要进行膨胀操作了。 膨胀可以将对象的边界延伸到背景中去。这样由于边界区域被处理,我们就可以知道哪些区域肯定是前景,哪些肯定是背景。如下图所示:
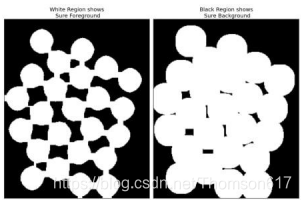
剩下的区域就是我们不知道该如何区分的了。这就是分水岭算法要做的。 这些区域通常是前景与背景的交界处(或者两个前景的交界)。我们称之为边界。从肯定是不是背景的区域中减去肯定是前景的区域就得到了边界区域。
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2)
# sure background area
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
'''距离变换的基本含义是计算一个图像中非零像素点到最近的零像素点的距离,也就是到零像素点的最短距离
一个最常见的距离变换算法就是通过连续的腐蚀操作来实现,腐蚀操作的停止条件是所有前景像素都被完全
腐蚀。这样根据腐蚀的先后顺序,我们就得到各个前景像素点到前景中心骨架像素点的
距离。根据各个像素点的距离值,设置为不同的灰度值。这样就完成了二值图像的距离变换'''
#cv2.distanceTransform(src, distanceType, maskSize)
dist_transform = cv2.distanceTransform(opening,1,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)#这里如果用腐蚀的话我们不知道需要腐蚀多少,而采用距离变换只需要设置最大距离的百分比
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)#图像相减距离变换cv2.distanceTransform(src, distanceType, maskSize)
- distanceType: 距离类型,它决定了用于计算距离的方法。OpenCV提供了两种距离类型:
-
cv2.DIST_L2:欧几里得距离(L2距离)。对于每个像素点,它计算该点到最近零像素点的直线距离。cv2.DIST_L1:城市街区距离(L1距离)。 |x1-x2| + |y1-y2|cv2.DIST_C:切比雪夫距离。max(|x1-x2|,|y1-y2|)
- maskSize: 距离变换的掩码大小。这个参数影响距离变换的计算精度和速度。较大的掩码大小可能产生更准确的距离值,但计算速度会更慢。OpenCV提供了几种预定义的掩码大小:
-
cv2.DIST_MASK_3:使用3x3的掩码。cv2.DIST_MASK_5:使用5x5的掩码。cv2.DIST_MASK_PRECISE:使用比cv2.DIST_MASK_5更精确的掩码,但速度更慢。
如结果所示,在阈值化之后的图像中,我们得到了肯定是硬币的区域,而且硬币之间也被分割开了。(有些情况下你可能只需要对前景进行分割,而不需要将紧挨在一起的对象分开,此时就没有必要使用距离变换了,腐蚀就足够了。当然腐蚀也可以用来提取肯定是前景的区域。)

现在知道哪些是背景哪些是硬币了,那我们就可以创建标签(一个与原图像大小相同,数据类型为 in32 的数组),并标记了其中的区域。对我们已经确定分类的区域(无论是前景还是背景)使用不同的正整数标记,对我们不确定的区域使用 0 标记。我们可以使用 cv2.connectedComponents() 函数来做这件事。它会将背景标记为 0,其它对象使用从 1 开始的正整数标记。
但如果背景标记为 0, 那分水岭算法就会把它当成未知区域了。所以我们想使用不同的整数标记它们。 而对不确定的区域标记为0(函数 cv2.connectedComponents 输出的结果中使用unknown定义未知区域)。
# Marker labelling
ret, markers1 = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers1+1
# Now, mark the region of unknown with zero
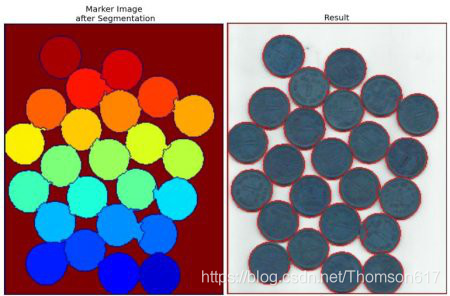
markers[unknown==255] = 0现在标签准备好了。最后一步:实施分水岭算法了。标签图像将会被修改,边界区域的标记将变为 -1.
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [255,0,0]结果如下。有些硬币的边界被分割的很好,也有一些硬币之间的边界分割 的不好。
综合前面介绍的知识,使用分水岭算法进行图像分割时的步骤为:
1. 通过形态学开运算对原始图像 O 去噪。
2. 通过腐蚀操作获取“确定背景 B”。需要注意,这里得到“原始图像-确定背景”即可。
3. 利用距离变换函数 cv2.distanceTransform()对原始图像进行运算,并对其进行阈值处理,得到“确定前景 F”。
4. 计算未知区域 UN(UN = O –B - F)。
5. 利用函数 cv2.connectedComponents()对原始图像 O 进行标注。
6. 对函数 cv2.connectedComponents()的标注结果进行修正。
7. 使用分水岭函数完成对图像的分割。
import cv2
import numpy as np
img=cv2.imread('coins.png')
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thesh=cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)#获取二值化图像
kernel=np.ones((3,3),np.uint8)
opening=cv2.morphologyEx(thesh,cv2.MORPH_OPEN,kernel)#开运算以去除噪声
opening=cv2.morphologyEx(opening,cv2.MORPH_CLOSE,kernel)#去除噪声
sure_bg=cv2.dilate(opening,kernel,iterations=1)#得到背景
dist=cv2.distanceTransform(opening,1,5)#距离变换,获取每个像素点距离最近的0的距离
ret,sure_fg=cv2.threshold(dist,0.6*dist.max(),255,0)
sure_fg = np.uint8(sure_fg)
unknow=cv2.subtract(sure_bg,sure_fg)
ret,marker1=cv2.connectedComponents(sure_fg)#创建标签,背景为0,其他从1开始编号
markers=marker1+1
markers[unknow==255]=0
markers3=cv2.watershed(img,markers)
cv2.imshow('original原图',img)
cv2.imshow('bagkground背景',cv2.bitwise_not(sure_bg))
cv2.imshow('frontground前景',sure_fg)
cv2.imshow('unknow无法确定的区域',unknow)
img2=cv2.cvtColor(img.copy(),cv2.COLOR_BGR2HSV)
img2[markers3==-1]=(0,255,255)
markers3*=255//markers3.max()
markers3[markers3<0]=0
img2[:,:,0]+=np.uint8(markers3)
cv2.imshow('watershed',cv2.cvtColor(img2,cv2.COLOR_HSV2BGR))
cv2.waitKey(0)八、GrabCut算法 交互式前景提取
使用很少的交互操作,就能够准确地提取出前景图像
在开始提取前景时,先用一个矩形框指定前景区域所在的大致位置范围,然后不断迭代地分割,直到达到最好的效果。经过上述处理后,提取前景的效果可能并不理想,此时需要用户干预提取过程。
干预过程:用户在原始图像的副本中(也可以是与原始图像大小相等的任意一幅图像),用白色标注要提取为前景的区域,用黑色标注要作为背景的区域。 然后将标注后的图像作为掩码,让算法继续迭代提取前景从而得到最终结果。
GrabCut 算法的具体实施过程:
- 将前景所在的大致位置使用矩形框标注出来。
- 根据矩形框外部的“确定背景”数据来区分矩形框区域内的前景和背景。
- 用高斯混合模型(Gaussians Mixture Model, GMM)对前景和背景建模。GMM 会根据用户的输入学习并创建新的像素分布。 对未分类的像素根据其与已知分类像素的关系进行分类。
- 根据像素分布情况生成一幅图,图中的节点就是各个像素点。除了像素点之外,还有两个节点:前景节点和背景节点。
- 图中的每个像素除了与前景节点或背景节点相连外,彼此之间还存在着连接。两个像素的颜色越接近,边的权重值越大。
- 使用 mincut 算法对上面得到的图进行分割。它会根据最低成本方程将图 分为 Source_node 和 Sink_node。成本方程就是被剪掉的所有边的权 重之和。在裁剪之后,所有连接到 Source_node 的像素被认为是前景, 所有连接到 Sink_node 的像素被认为是背景。
- 不断重复上述过程,直至分类收敛为止。
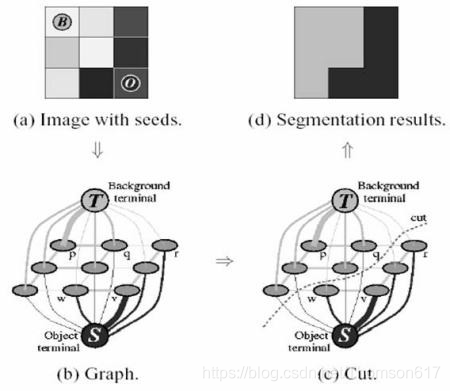
在 OpenCV 中,实现交互式前景提取的函数是 cv2.grabCut(),其语法格式为:
mask, bgdModel, fgdModel = cv2.grabCut(img, mask,rect, bgdModel,
fgdModel, iterCount[, mode])
其中:
#img 为输入图像,要求是 8 位 3 通道的。
#mask 为掩模图像,要求是 8 位单通道的。该参数用于确定前景区域、背景区域和
'''不确定区域,可以设置为 4 种形式。
cv2.GC_BGD:表示确定背景,也可以用数值 0 表示。
cv2.GC_FGD:表示确定前景,也可以用数值 1 表示。
cv2.GC_PR_BGD:表示可能的背景,也可以用数值 2 表示。
cv2.GC_PR_FGD:表示可能的前景,也可以用数值 3 表示。'''
#rect 指包含前景对象的区域,该区域外的部分被认为是“确定背景”。因此,
在选取时务必确保让前景包含在 rect 指定的范围内;否则, rect 外的前景部分是不会被提取出来的。
且只有当参数 mode 的值被设置为矩形模式 cv2.GC_INIT_WITH_RECT 时,参数 rect
才有意义,其格式为(x, y, w, h)。
#bgdModel 为算法内部使用的数组。你只需要创建两个大小为 (1,65),数据类型为 np.float64 的数组。
#fgdModel 为算法内部使用的数组。
#iterCount 表示迭代的次数。
#mode 表示迭代模式。
'''cv2.GC_INIT_WITH_RECT 使用矩形模板
cv2.GC_INIT_WITH_MASK 使用自定义模板。
cv2.GC_EVAL 修复模式
cv2.GC_EVAL_FREEZE_MODEL 使用固定模式首先,我们来看使用矩形模式。加载图片,创建掩模图像,构建 bdgModel 和 fgdModel,传入矩形参数,让算法迭代 5 次,修改模式设置为 cv2.GC_INIT_WITH_RECT。运行 grabcut。算法会修改掩模图像,在新的掩模图像中,所有的像素被分为四类: 背景,前景,可能是背景/前景使用 4 个不同的标签标记(前面参数中提到过)。
然后我们来修改掩模图像,所有的 0 像素和 2 像素都被归为 0(背景),所有的 1 像素和 3 像素都被归为 1(前景)。我们最终的掩模图像就这样准备好了。用它和输入图像相乘就得到了分割好的图像。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
# 函数的返回值是更新的 mask, bgdModel, fgdModel
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()结果如下:

在不使用掩模(掩模值都设置为默认值 0 时),函数 cv2.grabCut()的处理效果并不太好。为了得到完整的前景对象,需要做一些改进。这里对图像进行标注,将需要保留的部分设置为白色,将需要删除的背景设置为黑色。以标记好的图像作为模板,使用函数cv2.grabCut()完成前景的提取。
此过程主要包含以下步骤:
- 利用函数 cv2.grabCut()在 cv2.GC_INIT_WITH_RECT 模式下对图像进行初步的前景提取,得到初步提取的结果图像 og。
- 使用白色笔刷在希望提取的前景区域做标记。
- 使用黑色笔刷在希望删除的背景区域做标记。
- 将当前设置好的图像另存为模板图像 m0。
- 将模板图像 m0 中的白色值和黑色值映射到模板 m 中。将模板图像 m0 中的白色值(像素值为 255)映射为模板图像 m 中的确定前景(像素值为 1),将模板图像 m0 中的黑色值(像素值为 0)映射为模板图像 m 中的确定背景(像素值为 0)。
- 以模板图像 m 作为函数 cv2.grabCut()的模板参数(mask),对图像 og 完成前景提取。
# newmask is the mask image I manually labelled
newmask = cv2.imread('newmask.png',0)
# whereever it is marked white (sure foreground), change mask=1
# whereever it is marked black (sure background), change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1
mask, bgdModel, fgdModel = cv2.grabCut(img,mask,None,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()结果如下:

也可以不使用矩形初始化,直接进入掩码图像模式。使用 2像素和 3 像素(可能是背景/前景)对矩形区域的像素进行标记。然后对肯定是前景的像素标记为 1 像素。然后直接在掩模图像模 式下使用 grabCut 函数。
图像特征
一、图像轮廓
1.轮廓提取
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。
• 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理 或者 Canny 边界检测。
• 查找轮廓的函数会修改原始图像。如果在找轮廓之后还想使用原始图像的话,应该将原始图像存储到其他变量中。
• 在 OpenCV 中,查找轮廓就像在黑色背景中找白色物体。要找的物体是白色而背景是黑色。
# contours:从图像中查找出来的轮廓数组
# hierarchy:轮廓层级
# imageSrc:传入的图像,又返回了一份。不明白。。。。
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset]]]) -> contours, hierarchy参数
- image:源图像,必须是8位单通道图像。非零像素值被视为1,零像素值被视为0,因此它通常是二值化后的图像。
- mode:轮廓检索模式。
-
- cv2.RETR_EXTERNAL:只检索最外层的轮廓。
- cv2.RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中,不建立父子关系。
- cv2.RETR_TREE:建立一个等级树结构的轮廓,重构嵌套轮廓的整个层次; 最常用。
- RETR_CCOMP:检索所有的轮廓,并将它们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界:
- cv2.RETR_FLOODFILL:这个模式用于从点开始填充图像,并检索填充区域的边界。
- method:轮廓近似方法:
-
- cv2.CHAIN_APPROX_NONE:存储轮廓上的所有点。这可能会占用大量的内存。
- cv2.CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,该函数只保留它们的终点部分。
- cv2.CHAIN_APPROX_TC89_L1、cv2.CHAIN_APPROX_TC89_KCOS:这些是 Teh-Chin 的近似算法。
contours 和 hierarchy 是可选的输出参数,但在函数调用中通常会被使用以接收结果。
- contours:检测到的轮廓,作为点坐标的列表(即 numpy 数组)。
- hierarchy:图像拓扑信息的可选输出向量。对于每个轮廓,它包含有关其关系的信息(例如,哪个轮廓是内嵌的,哪个轮廓有相同的父轮廓等)。
- offset:(可选)轮廓点偏移量。这通常用于在找到轮廓后,将它们映射回原始图像(如果有偏移或ROI)。
返回值
- contours:如上所述,检测到的轮廓。
- hierarchy:如上所述,图像拓扑信息的向量。

轮廓的层次结构
OpenCV-Python (官方)中文教程(部分一)-优快云博客
2.轮廓绘制
cv2.drawContours() 可以被用来绘制轮廓。它可以根据提供的边界点绘制任何形状。
# canvas:轮廓要绘制在哪张背景图上,直接覆盖原图
# contours:findContours 找到的轮廓信息
# contourIdx:轮廓数组contours的索引值,-1 为全部,其他数为按照顺序的
# color:轮廓颜色
# thickness:轮廓厚度
cv2.drawContours(canva:image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]]) -> image
#有的库返回值为imageSrc, contours, hierarchy3.轮廓近似
这是函数 cv2.findCountours() 的第三个参数。它到底代表什么意思呢?
轮廓是一个形状具有相同灰度值的边界。它会存贮形状边界上所有的 (x,y) 坐标。但是需要将所有的这些边界点都存储吗?这就是这个参数要告诉函数 cv2.findContours 的。
这个参数如果被设置为 cv2.CHAIN_APPROX_NONE,所有的边界点都会被存储。而当我们选择cv2.CHAIN_APPROX_SIMPLE这个参数时,它会将轮廓上的冗余点都去掉,只保留顶点,从而节省内存开支
原理如下:
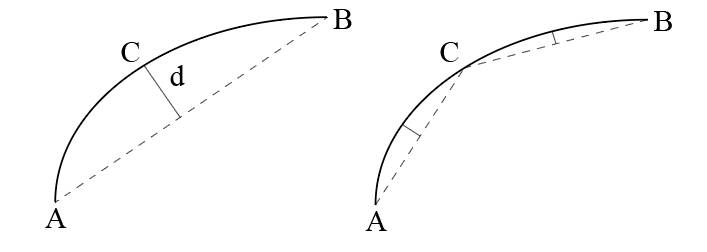
近似弧线 AB⌢,首先连接A、B两点做直线 𝐴𝐵;然后找 AB⌢ 到 𝐴𝐵 最长的距离,假设𝐶距离𝐴𝐵最大,且距离为 𝑑;最后对比 𝑑 与阈值 𝜖 的大小,若 𝑑<𝜖,则用直线 𝐴𝐵 近似曲线 AB⌢,否则将AB⌢ 拆分为 AC⌢ 与 CB⌢ 重复上述步骤。
# curve:轮廓,contour
# epsilon:阈值,按照周长百分比选取 arcLength
# closed:近似轮廓是否闭合
epsilon = 0.1*cv2.arcLength(cnt,True)
cv2.approxPolyDP(curve, epsilon, closed[, approxCurve]) -> approxCurve4.轮廓特征
# 轮廓索引
cnt = contours[0]
# 计算面积
area = cv2.contourArea(cnt)
# 计算周长
# arcLength(curve, closed) -> retval
arc = cv2.arcLength(cnt,True)①矩
图像的矩可以用于计算图像的质心,面积等。
函数 cv2.moments() 会将计算得到的矩以一个字典的形式返回。如下:
import cv2
img = cv2.imread('star.jpg', 0)
ret, thresh = cv2.threshold(img, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, 1, 2)
cnt = contours[0]
M = cv2.moments(cnt)
print(M)根据这些矩的值,我们可以计算出对象的重心:
![]()
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])
②轮廓面积
轮廓的面积可以使用函数 cv2.contourArea() 计算得到,也可以使用矩(0 阶矩),M['m00']。
area = cv2.contourArea(cnt)③轮廓周长
可以使用函数 cv2.arcLength() 计算得到
perimeter = cv2.arcLength(cnt,True)#第二个参数可以用true指定对象的形状是闭合的,否则是开放的2.凸包
凸包与轮廓近似相似但不同。 cv2.convexHull() 可以用来检测一个曲线是否具有凸性缺陷,并能纠正缺陷。一般来说,凸性曲线总是凸出来的,至少是平的。如果有地方凹进去了就被叫做凸性缺陷。例如下图中的手。红色曲线显示了手的凸包,凸性缺陷被双箭头标出来了。
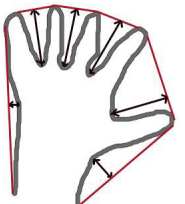
hull = cv2.convexHull(points[, hull[, clockwise[, returnPoints]]• points 我们要传入的轮廓
• hull 输出,通常不需要
• clockwise 方向标志。如果设置为 True,输出的凸包是顺时针方向的。 否则为逆时针方向。
• returnPoints 默认值为 True。它会返回凸包上点的坐标。如果设置 为False,就会返回与凸包点对应的轮廓上的下标。
要获得上图的凸包,下面的命令就够了:hull = cv2.convexHull(cnt)
如果你想获得凸性缺陷,需要把 returnPoints 设置为 False。以 上面的矩形为例,首先我们找到他的轮廓 cnt。现在我把 returnPoints 设置 为 True 查找凸包,我得到下列值:
[[[234 202]], [[ 51 202]], [[ 51 79]], [[234 79]]],其实就是矩形的四个角点。
现在把 returnPoints 设置为 False,我得到的结果是[[129],[67],[0],[142]]
凸性检测
cv2.isContourConvex() 可以用来检测一个曲线是不是凸的。返回 True 或 False。
k = cv2.isContourConvex(cnt)3.边界矩形(轮廓标记)
直边界矩形
一个直矩形不会考虑对象是否旋转。 所以边界矩形的面积不是最小的。用函数 cv2.boundingRect() 得到(x,y)为矩形左上角的坐标,(w,h)是矩形的宽和高。
x,y,w,h = cv2.boundingRect(cnt)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)旋转的边界矩形
cv2.minAreaRect()。返回的是一个 Box2D 结构,其中包含矩形左上角角点的坐标(x,y),矩形的宽和高(w,h),以及旋转角度。要绘制这个矩形需要矩形的 4 个角点,可以通过函数 cv2.boxPoints() 获得。
xy,wh,theta = cv2.minAreaRect(cnt)
cv2.boxPoints((xy,wh,theta),img)把这两中边界矩形显示在下图中,其中绿色的为直矩形,红的为旋转矩形。

4.最小外接圆
cv2.minEnclosingCircle() 可以帮我们找到一个对象的外切圆。
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
5.椭圆拟合
cv2.ellipse(),返回值其实就是旋转边界矩形的内切圆。
ellipse = cv2.fitEllipse(cnt)#ellipse:((x,y),(Ma长轴,ma短轴),angle)
im = cv2.ellipse(im,ellipse,(0,255,0),2)
6.直线拟合
rows,cols = img.shape[:2]
'''
#cv2.fitLine(points, distType, param, reps, aeps[, line ]) → line
#points – Input vector of 2D or 3D points, stored in std::vector<> or Mat.
#line – Output line parameters. In case of 2D fitting, it should be a vector of 4 elements (likeVec4f) - (vx, vy, x0, y0), where (vx, vy) is a normalized vector collinear to the line and (x0, y0) is a point on the line. In case of 3D fitting, it should be a vector of 6 elements (like Vec6f) - (vx, vy, vz,x0, y0, z0), where (vx, vy, vz) is a normalized vector collinear to the line and (x0, y0, z0) is a point on the line.
#distType – Distance used by the M-estimator
#distType=CV_DIST_L2
#ρ(r) = r2 /2 (the simplest and the fastest least-squares method)
#param – Numerical parameter ( C ) for some types of distances. If it is 0, an optimal value is chosen.
#reps – Sufficient accuracy for the radius (distance between the coordinate origin and the line).
#aeps – Sufficient accuracy for the angle. 0.01 would be a good default value for reps and aeps.'''
[vx,vy,x,y] = cv2.fitLine(cnt, cv2.DIST_L2,0,0.01,0.01)
lefty = int((-x*vy/vx) + y)
righty = int(((cols-x)*vy/vx)+y)
img = cv2.line(img,(cols-1,righty),(0,lefty),(0,255,0),2)cv2.fitLine(InputArray points, distType, param, reps, aeps) ->dx,dy,x,yInputArray points:待拟合的直线的集合,必须是矩阵形式。distType:距离类型。fitLine是一个距离最小化函数,拟合直线时,要使输入点到拟合直线的距离最小化。距离的类型有以下几种:
-
cv2.DIST_USER:用户自定义距离。cv2.DIST_L1:距离 = |x1 - x2| + |y1 - y2|。cv2.DIST_L2:欧式距离,与最小二乘法相同。cv2.DIST_C:距离 = max(|x1 - x2|, |y1 - y2|)。cv2.DIST_L12:L1-L2 metric,距离 = 2(sqrt(1 + x^2/2) - 1)。cv2.DIST_FAIR:距离 = c^2(|x|/c - log(1 + |x|/c)),其中 c = 1.3998。cv2.DIST_WELSCH:距离 = c^2/2(1 - exp(-(x/c)^2)),其中 c = 2.9846。cv2.DIST_HUBER:距离 = |x| < c ? x^2/2 : c(|x| - c/2),其中 c = 1.345。
param:距离参数,与所选的距离类型有关,通常设置为 0。reps和aeps:用于表示拟合直线所需的径向和角度精度,通常设定为 1e-2。
对于二维直线,输出 output 是一个 4 维数组,前两维代表拟合出的直线的方向,后两位代表直线上的一点(通常是点斜式直线)。
5.轮廓的属性
(1).纵横比(Aspect Ratio)
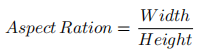
x,y,w,h = cv2.boundingRect(cnt)
aspect_ratio = float(w)/h(2).范围(Extent)
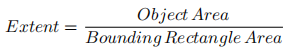
area = cv2.contourArea(cnt)
x,y,w,h = cv2.boundingRect(cnt)
rect_area = w*h
extent = float(area)/rect_area(3).固体度(Solidity)
![]()
area = cv2.contourArea(cnt)
hull = cv2.convexHull(cnt)
hull_area = cv2.contourArea(hull)
solidity = float(area)/hull_area(4).等效直径(Equivalent Diameter)
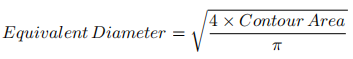
area = cv2.contourArea(cnt)
equi_diameter = np.sqrt(4*area/np.pi)(5).方向(Orientation)
方向是物体被指向的角度。下面的方法还会返回长轴和短轴的长度:
(x,y),(MA,ma),angle = cv2.fitEllipse(cnt)(6).掩模和像素点
有时我们需要构成对象的所有像素点,我们可以这样做:
mask = np.zeros(imgray.shape,np.uint8)
# 这里一定要使用参数-1, 绘制填充的的轮廓
cv2.drawContours(mask,[cnt],0,255,-1)
#返回数组的元组,每个数组对应一个维度a,其中包含该维度中非零元素的索引.
#结果总是一个二维数组,每个非零元素都有一行.
#若要按元素(而非维度)对索引进行分组,请使用:transpose(nonzero(a))
#>>> x = np.eye(3)
#>>> x
#array([[ 1., 0., 0.],
# [ 0., 1., 0.],
# [ 0., 0., 1.]])
#>>> np.nonzero(x)
#(array([0, 1, 2]), array([0, 1, 2]))
#>>> x[np.nonzero(x)]
#array([ 1., 1., 1.])
#>>> np.transpose(np.nonzero(x))
#array([[0, 0],
# [1, 1],
# [2, 2]])
pixelpoints = np.transpose(np.nonzero(mask))
#pixelpoints = cv2.findNonZero(mask)这里用了两种方法:第一种方法使用 Numpy 函数,第二种使用 OpenCV 函数。结果相同,但还是有点不同。Numpy 给出的坐标是(row, colum)形式的。而 OpenCV 给出的格式是(x,y)形式的。所以这两个结果基本是可以互换的。row=x,colunm=y。
(7).最大值和最小值及它们的位置
我们可以使用掩模图像得到这些参数:
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(imgray,mask = mask)(8).平均颜色及平均灰度
我们也可以使用相同的掩模求一个对象的平均颜色或平均灰度
mean_val = cv2.mean(img,mask = mask)(9).极点

一个对象最上面,最下面,最左边,最右边的点。
leftmost = tuple(cnt[cnt[:,:,0].argmin()][0])
rightmost = tuple(cnt[cnt[:,:,0].argmax()][0])
topmost = tuple(cnt[cnt[:,:,1].argmin()][0])
bottommost = tuple(cnt[cnt[:,:,1].argmax()][0])6.轮廓的其他函数
①凸缺陷 (Convexity Defects)
前面我们已经学习了轮廓的凸包,对象上的任何凹陷都被成为凸缺陷。cv2.convexityDefect() 可以帮助我们找到凸缺陷。函数调用如下:
hull = cv2.convexHull(cnt,returnPoints = False)
defects = cv2.convexityDefects(cnt,hull)注意:如果要查找凸缺陷,在使用函数 cv2.convexHull 找凸包时,参数returnPoints 一定要是 False。
它会返回一个数组,其中每一行包含的值是 [起点,终点,最远的点,到最远点的近似距离]。我们可以在一张图上显示它。我们将起点和终点用一条绿线连接,在最远点画一个圆圈,返回结果的前三个值是轮廓点的索引。 所以我们还要到轮廓点中去找它们。
import cv2
img = cv2.imread('star.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(img_gray, 127, 255,0)
contours,hierarchy = cv2.findContours(thresh,2,1)
cnt = contours[0]
hull = cv2.convexHull(cnt,returnPoints = False)
defects = cv2.convexityDefects(cnt,hull)
for i in range(defects.shape[0]):
s,e,f,d = defects[i,0]
start = tuple(cnt[s][0])
end = tuple(cnt[e][0])
far = tuple(cnt[f][0])
cv2.line(img,start,end,[0,255,0],2)
cv2.circle(img,far,5,[0,0,255],-1)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()②多边形点测试 (pointPolygonTest)
求解图像中的一个点到一个对象轮廓的最短距离。如果点在轮廓的外部, 返回值为负;如果在轮廓上,返回值为 0; 如果在轮廓内部,返回值为正。
下面我们以点(50,50)为例:
dist = cv2.pointPolygonTest(cnt,(50,50),True)此函数的第三个参数是 measureDist。如果设置为 True,就会计算最短距离。如果是 False,只会判断这个点与轮廓之间的位置关系(返回值为+1,-1,0)。
注意:如果不需要知道具体距离,建议将第三个参数设为 False,这样速 度会提高 2 到 3 倍.
③形状匹配(Match Shapes)
cv2.matchShape() 可以帮我们比较两个形状或轮廓的相似度。如果返回值越小,匹配越好。它是根据 Hu 矩值来计算的。
retval = cv2.matchShapes(contour1, contour2, method, parameter)- method: 比较方法,可以是以下之一:
cv2.CONTOURS_MATCH_I1: 计算
cv2.CONTOURS_MATCH_I2: 计算
cv2.CONTOURS_MATCH_I3: 计算
- parameter: 可选参数,目前未使用,应设置为0。
我们试着将下面的图形进行比较:
import cv2
img1 = cv2.imread('star.jpg',0)
img2 = cv2.imread('star2.jpg',0)
ret, thresh = cv2.threshold(img1, 127, 255,0)
ret, thresh2 = cv2.threshold(img2, 127, 255,0)
contours,hierarchy = cv2.findContours(thresh,2,1)
cnt1 = contours[0]
contours,hierarchy = cv2.findContours(thresh2,2,1)
cnt2 = contours[0]
ret = cv2.matchShapes(cnt1,cnt2,1,0.0)
print (ret)得到的结果是:

• A 与自己匹配 0.0
• A 与 B 匹配 0.001946
• A 与 C 匹配 0.326911即使发生了旋转对匹配的结果影响也不是非常大。
注意:Hu 矩是归一化中心矩的线性组合,之所以这样做是为了能够获取代表图像的某个特征的矩函数,这些矩函数对某些变化如缩放,旋转,镜像映射(除了 h1)具有不变形。
二、模板匹配
模板匹配是用来在一副大图中搜寻查找模版图像位置的方法。cv2.matchTemplate()和 2D 卷积一样,它也是用模板图像在输入图像(大图)上滑动,并在每一个位置对模板图像和与其对应的输入图像的子区域进行比较。返回的结果是一个灰度图像,每一个像素值表示了此区域与模板的匹配程度。
如果输入图像的大小是(WxH), 模板的大小是(wxh), 输出的结果 的大小就是(W-w+1,H-h+1)。得到这幅图之后,就可以使用函数 cv2.minMaxLoc() 来找到其中的最小值和最大值的位置。第一个值为矩形左上角的点(位置),(w,h)为 moban 模板矩形的宽和高。这个矩形就是 找到的模板区域了。
注意:如果你使用的比较方法是 cv2.TM_SQDIFF,最小值对应的位置才是匹配的区域。
# templ:模板图片
# method:匹配算法
cv2.matchTemplate(image, templ, method[, result[, mask]]) -> result- method:
-
- TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
- TM_CCORR:计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
- TM_CCORR NORMED:计算归一化相关性,计算出来的值越接近1,越相关
- TM_CCOEFF NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
result:每一步卷积操作记录一次结果,其数组大小就为(与卷积运算结果维度计算一样)
result数组的索引值,对应的是模板图片在原始图片重合的左上角像素的坐标。
# 导入图片
img = cv2.imread('./cat.jpeg')
imgTemp = img[80:250,250:440]
# 模板匹配
result = cv2.matchTemplate(img,imgTemp,cv2.TM_SQDIFF_NORMED)
# 统计出数组的中最大值、最小值以及对应的索引
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(result)
# 绘制矩形框
cv2.rectangle(img,minLoc,(minLoc[ 0 ]+imgTemp.shape[ 1 ],minLoc[ 1 ]+imgTemp.shape[ 0 ]),(255,0,0),2)
多对象的模板匹配
函数 cv2.imMaxLoc() 只会给出最大值和最小值。此时,我们就要使用阈值了。下面的的例子要在经典游戏Mario 的一张截屏图片中找到其中的硬币。
import cv2
import numpy as np
img_rgb = cv2.imread('mario.png')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('mario_coin.png',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
#umpy.where(condition[, x, y])
#根据条件从x或y返回元素。如果只给出了条件,那么返回condition.nonzero().
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv2.imwrite('res.png',img_rgb)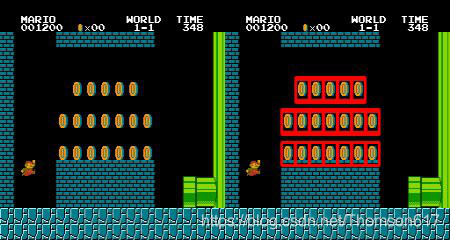
三、Hough变换
直线变换
使用霍夫变换检测直线。
一条直线可以用数学表达式 y = mx + c 或者 ρ= x cosθ + y sinθ 表示。 ρ 是从原点到直线的垂直距离,θ 是直线的垂线与横轴顺时针方向的夹角。如下图所示:
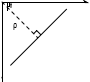
每一条直线都可以用 (ρ, θ) 表示。 所以首先创建一个 2D 数组(累加器),初始化累加器,所有的值都为 0。行表 示 ρ, 列表示 θ。这个数组的大小决定了最后结果的准确性。如果你希望角度精确到 1 度,你就需要 180 列。对于 ρ,最大值为图片对角线的距离。所以如果精确度要达到一个像素的级别,行数就应该与图像对角线的距离相等。
若我们有一个大小为 100x100 的直线位于图像的中央。取直线上的第一个点,我们知道此处的(x,y)值。把 x 和 y 带入上边的方程组, 然后遍历 θ 的取值:0,1,2,3,. . .,180。分别求出与其对应的 ρ 的值,这样我们就得到一系列(ρ, θ)的数值对,如果这个数值对在累加器中也存在相应的位置,就在这个位置上加 1。所以现在累加器中的(50,90)=1。(一个点可能存在与多条直线中,所以对于直线上的每一个点可能是累加器中的多个值同时加 1)。
现在取直线上的第二个点,重复上边的过程,更新累加器中的值。现在累加器中(50,90)的值为 2。对直线上的每个点都执行上边的操作,每次操作完成后,累加器中的值就加 1,但其他地方有时会加 1, 有时不会。按照这种方式下去,到最后累加器中(50,90)的值肯定是最大的。如果你搜索累加器中的最大值,并找到其位置(50,90),这就说明图像中有一条直线,这条直线到原点的距离为 50,它的垂线与横轴的夹角为 90 度。
下面的动画很好的演示了这个过程
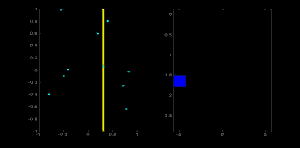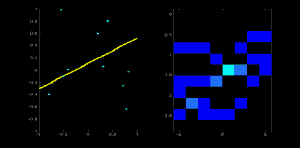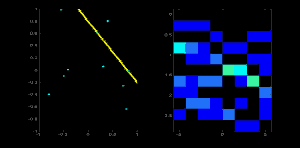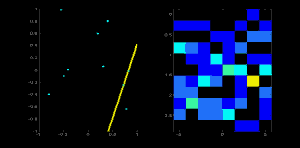
OpenCV中的霍夫变换
上面介绍的整个过程在 OpenCV 中都被封装进了一个函数:cv2.HoughLines()。 返回值就是(ρ, θ)。ρ 的单位是像素,θ 的单位是弧度。这个函数的第一个参数是一个二值化图像,所以在进行霍夫变换之前要首先进行二值化,或者进行Canny 边缘检测。第二和第三个值分别代表 ρ 和 θ 的精确度。第四个参数是 阈值,只有累加其中的值高于阈值时才被认为是一条直线,也可以把它看成能 检测到的直线的最短长度(以像素点为单位)。
def HoughLines(
image: MatLike,
rho: float,#像素距离的精度
theta: float,#角度精度(弧度)
threshold: int,#阈值
lines: MatLike | None = ...,#返回值
srn: float = ...,#可选参数,用于概率霍夫变换。
stn: float = ...,
min_theta: float = ...,#选参数,用于限制角度范围。
max_theta: float = ...
) -> MatLikeimport cv2
import numpy as np
img = cv2.imread('read.jpg')
img=cv2.resize(img,(640,480))
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,180,320,apertureSize = 3)
lines = cv2.HoughLines(edges,1,np.pi/180,150)
print(lines)
for rho,theta in [x[0] for x in lines]:
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),1,16)
cv2.imshow('houghlines3.jpg',img)
cv2.waitKey(0)Probabilistic Hough Transform
上面的算法仅仅是一条直线都需要大量的计算。Probabilistic Hough Transform 是对霍夫变换的一种优化。它不会对每一个点都进行计算,而是从一幅图像中随机选取(是不是也可以使用图像金字塔呢?)一个点集进行计算,对于直线检测来说这已经足够了。使用这种变换必须要降低阈值(总的点数都少了,阈值也要小)。下图是对两种方法的对比。
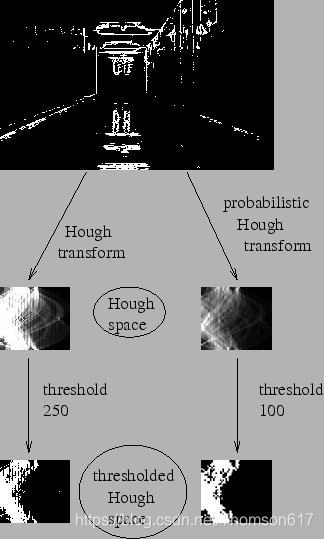
OpenCV 中使用的 Matas, J. ,Galambos, C. 和 Kittler, J.V. 提出的 Progressive Probabilistic Hough Transform。这个函数是 cv2.HoughLinesP()。 它有两个参数。
• minLineLength - 线的最短长度。比这个短的线都会被忽略。
• MaxLineGap - 两条线段之间的最大间隔,如果小于此值,这两条直线 就被看成是一条直线。
更加给力的是,这个函数的返回值就是直线的起点和终点。而在前面的例子中, 我们只得到了直线的参数,而且你必须要找到所有的直线。而在这里一切都很 直接很简单。
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
minLineLength = 100
maxLineGap = 10
lines = cv2.HoughLinesP(edges,1,np.pi/180,100,minLineLength,maxLineGap)
for x1,y1,x2,y2 in lines[0]: cv2.line(img,(x1,y1),(x2,y2),(0,255,0),2)
cv2.imwrite('houghlines5.jpg',img)圆形变换
圆形的数学表达式为
![]()
。从这个等式中我们可以看出:一个圆环需要 3个参数来确定。所以进行圆环霍夫变换的累加器必须是 3 维的,这样的话效率就会很低。所以 OpenCV 用一个比较巧妙的办法:霍夫梯度法,它可以使用边界的梯度信息。
cv2.HoughCircles(image, method, dp, minDist, param1=100, param2=100, minRadius=0, maxRadius=0)
'''参数说明
image:输入图像,必须是灰度图。
method:检测圆的方法,OpenCV 提供了唯一的方法 cv2.HOUGH_GRADIENT,它是基于边缘的梯度信息。
dp:累加器分辨率与图像分辨率的反比。例如,如果 dp=1,则累加器具有与输入图像相同的分辨率。如果 dp=2,累加器便有输入图像一半的宽度和高度。
minDist:检测到的圆心之间的最小距离。如果参数太小,则除了真实的圆之外,还可能错误地检测到多个邻近的圆。如果参数太大,则可能会漏掉一些圆。
param1:Canny 边缘检测器的高阈值(对于 cv2.HOUGH_GRADIENT 方法)。
param2:累加器阈值,即检测圆时圆心候选点所需的投票数。该参数越小,检测到的圆越多。
minRadius:圆半径的最小值。
maxRadius:圆半径的最大值。import cv2
import numpy as np
img = cv2.imread('opencv_logo.png',0)
img = cv2.medianBlur(img,5)
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,20,param1=50,param2=30,minRadius=0,maxRadius=0)
if circles:
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv2.circle(img,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv2.circle(img,(i[0],i[1]),2,(0,0,255),3)
cv2.imshow('detected circles',cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
四、角点检测
1.原理
角点: 两条边的交点,或者说角点的局部邻域应该具有两个不同区域的不同方向的边界
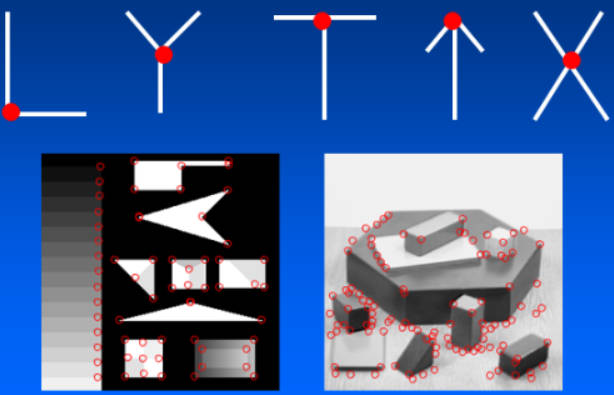
原理如下:
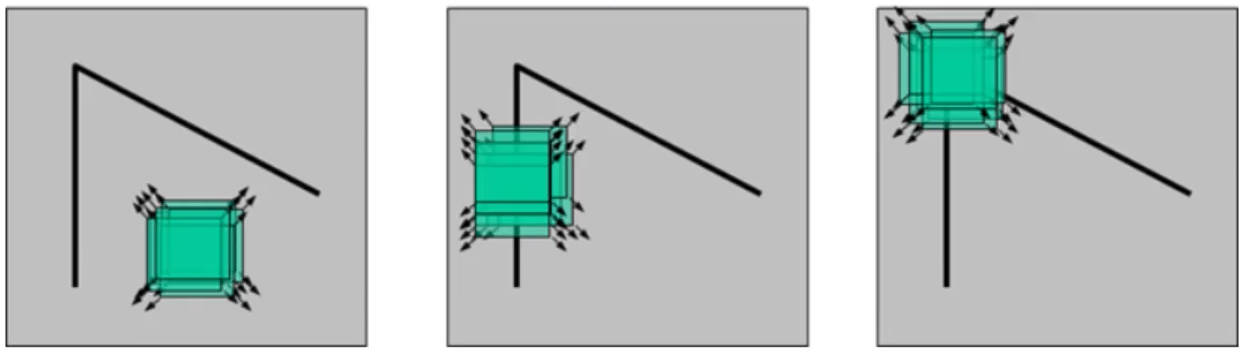
- 基本思想: 角点周围的灰度值变化肯定较大
- 检测原理: 使用一个滑动窗口在灰度图上进行任意方向上的滑动,比较滑动前与滑动后两个位置的灰度值:
-
- 几乎没有变化:滑动窗口处于颜色填充区域,例如左图所示
- 在一个方向上有变化:滑动窗口处于图片边缘,例如中间图所示
- 各个方向变化剧烈:滑动窗口极有可能处于角点位置,例如右图所示
2.Harris算法
定义灰度差异:
滑动窗口前后位置灰度值的变化程度,可以对前后两个位置处灰度值做差来衡量
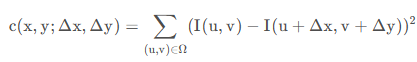
其中,Ω 表示滑动窗口;(𝑥,𝑦)为滑动窗口中心在原图中的坐标;𝐼(𝑢,𝑣) 表示窗口移动前的灰度值;𝐼(𝑢+Δ𝑥,𝑣+Δ𝑦)表示窗口移动 (Δ𝑥,Δ𝑦)距离后的灰度值。又由于上述一顿操作下来,只计算了原图「 (𝑥,𝑦) 点」在窗口移动前后的差异,按道理说,距离点 (𝑥,𝑦)越远点,对其影响应该越小,所以又添加了一个权值进行控制
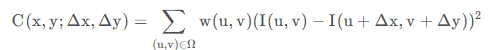
权值可为考高斯分布、也可取常值。
求解差异:
实际使用中,不可能对滑动窗口进行移动后,根据公式定义计算差异,计算量太大且窗口移动方向不定。 为了近似求解差异,首先 𝐼(𝑢,𝑣) 附近进行泰勒一阶展开
𝐼(𝑢+Δ𝑥,𝑣+Δ𝑦)=𝐼(𝑢,𝑣)+𝐼𝑥′(𝑢,𝑣)Δ𝑥+𝐼𝑦′(𝑢,𝑣)Δ𝑦
得
𝐼(𝑢+Δ𝑥,𝑣+Δ𝑦)−𝐼(𝑢,𝑣)=𝐼𝑥′(𝑢,𝑣)Δ𝑥+𝐼𝑦′(𝑢,𝑣)Δ𝑦
公式回代就是
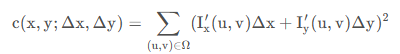
并根据线性代数,将上式转换为二次型
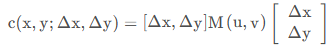
其中

最终得到
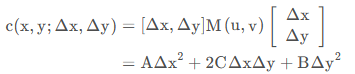
Note
𝐼𝑥′,𝐼𝑦′ 可以通过 Sobel 算子进行近似计算。
等效椭圆:
上述化简结果从形式上看就是一个非标准的椭圆
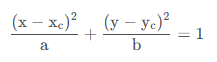
为了观察方便,肯定是要将椭圆标准化为
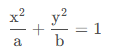
由于 M 为实对称矩阵
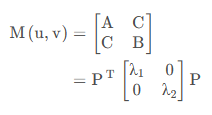
回代就为
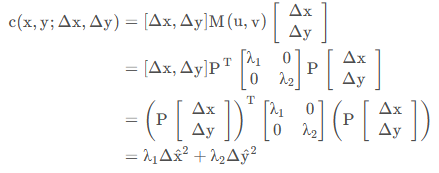
即对 [Δ𝑥Δ𝑦] 进行坐标变换,将原来的椭圆变换成了标准椭圆。𝜆1值越大,说明对
![]()
方向上的移动越敏感,也就是说该方向上灰度值变化很大,𝜆2同理。
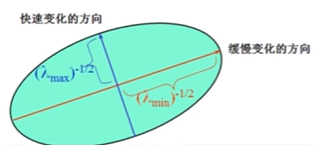
特征值与角点:
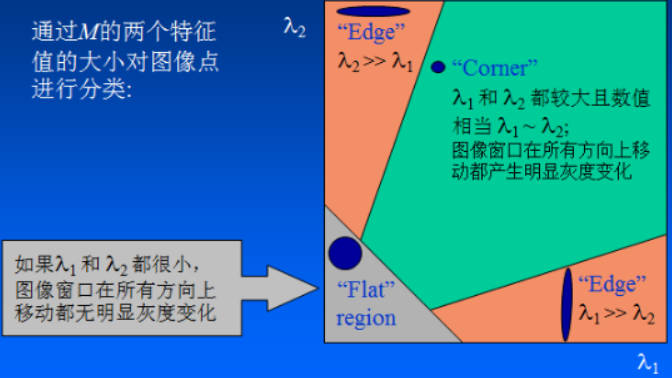
角点判断指标:
![]()
-
- 𝑅>0:角点的可能最大
- 𝑅≈0:光滑区域
- 𝑅<0:边缘
OpenCV代码
# blockSize: 滑动窗口
# ksize:sobel 算子计算梯度的卷积核尺寸
# k:R系数的k值
cornerHarris(src:np.float32, blockSize:int, ksize:int, k[, dst[, borderType]]) -> dstimport cv2
import numpy as np
img = cv2.imread('./card.jpg')
imgGray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
imgGray = np.float32(imgGray)
dst = cv2.cornerHarris(imgGray,2,3,0.04)
# 标记出角点
img[dst > 0.1 * dst.max()] = [0,0,255]
cv2.imshow('test',img)
cv2.waitKey(0)
cv2.destroyAllWindows()3. 亚像素级精确度的角点
OpenCV 提供了函数 cv2.cornerSubPix(), 提供亚像素级别的角点检测。首先我们要找到 Harris 角点,然后将角点的重心传给这个函数进行修正。在使用这个函数时要定义一个迭代停止条件。当迭代次数达到或者精度条件满足后迭代停止。我们同样需要定义进行角点搜索的邻域大小。
cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria)- corners: 输入角点的初始坐标,应是一个形状为
(N, 1, 2)的 NumPy 数组,N是角点数量,每个角点(x, y)表示。 - winSize: 搜索窗口的大小,单位:像素。用于在每个角点的周围进行搜索,以找到更精确的位置,应该是正奇数。
- zeroZone: 死区的大小的一半,单位:像素。这是一个在搜索窗口内部的较小区域,其中心与角点的当前估计位置重合。在这个区域内的像素不会被考虑在精细化过程中,有助于避免由于图像噪声导致的自相关矩阵的错误估计。应该是正奇数。
- criteria: 迭代搜索算法的终止条件。这个参数是
cv2.TermCriteria对象,可以通过cv2.TermCriteria_EPS | cv2.TermCriteria_MAX_ITER来指定,其中EPS表示最大移动距离(角点位置变化量),MAX_ITER表示最大迭代次数。
import cv2
import numpy as np
filename = 'chessboard2.jpg'
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 查找Harris 角点
gray = np.float32(gray)
dst = cv2.cornerHarris(gray,2,3,0.04)
dst = cv2.dilate(dst,None)
ret, dst = cv2.threshold(dst,0.01*dst.max(),255,0)
dst = np.uint8(dst)
# 查找重心
ret, labels, stats, centroids = cv2.connectedComponentsWithStats(dst)
# 定义停止和细化角点的标准
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.001)
# 返回值由角点坐标组成的一个数组(而非图像)
corners = cv2.cornerSubPix(gray,np.float32(centroids),(5,5),(-1,-1),criteria)
# Now draw them
res = np.hstack((centroids,corners))
#np.int0 可以用来省略小数点后面的数字(非四舍五入)。 res = np.int0(res) img[res[:,1],res[:,0]]=[0,0,255]
imgsg[np.int0(res[:, 3]), np.int0(res[:, 2])] = 255
cv2.imshow('subpixel5',img)
4. Shi-Tomasi角点检测 & 适合于跟踪的图像特征
Harris 角点检测的打分公式为:
![]()
但 Shi-Tomasi 使用的打分函数为: R = min (λ1, λ2)
如果打分超过阈值,我们就认为它是一个角点。我们可以把它绘制到 λ1 ~λ2 空间中,就会得到下图,只有当 λ1 和 λ2 都大于最小值时,才被认为是角点(绿色区域)。
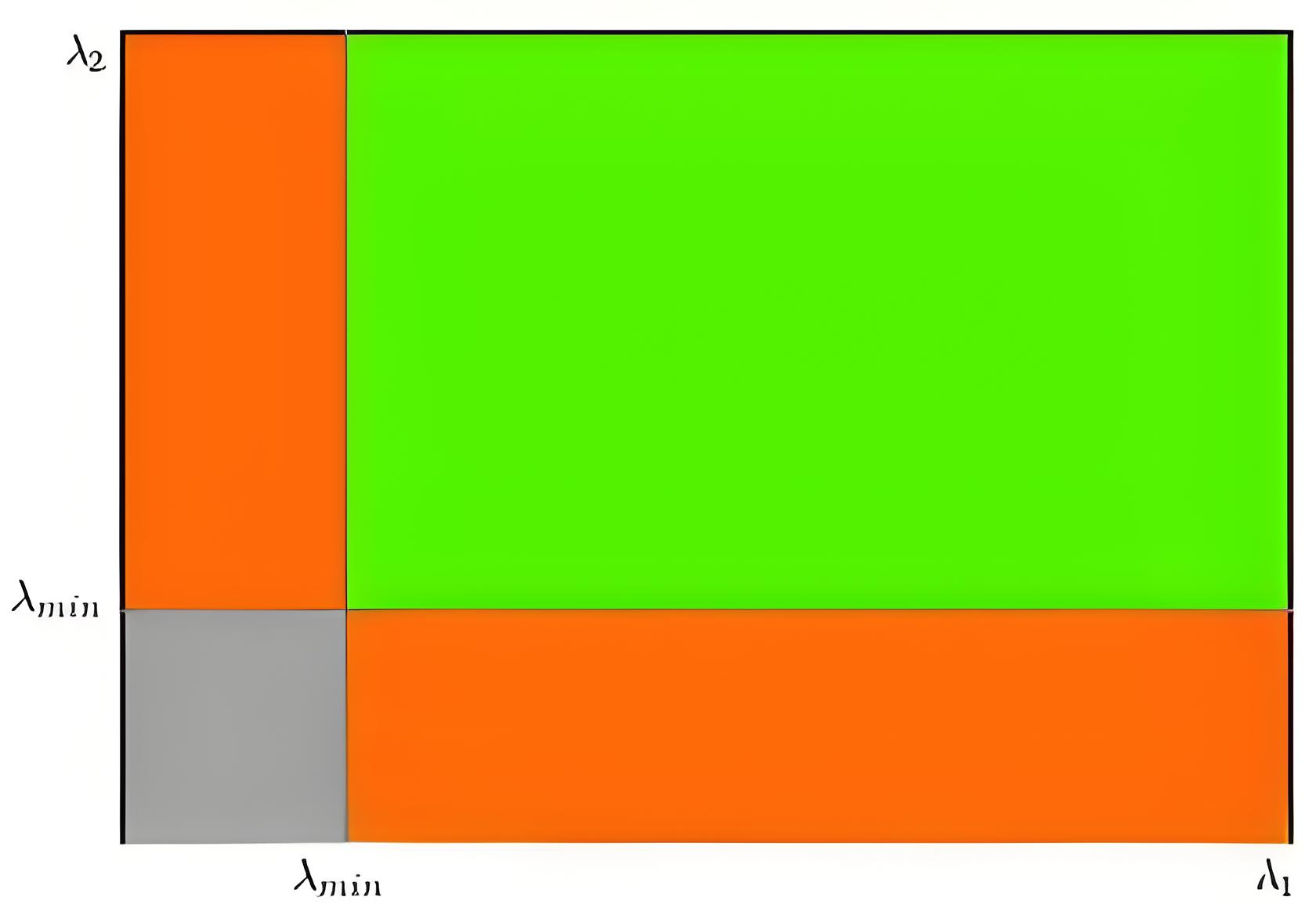
cv2.goodFeaturesToTrack() 函数使用 Shi-Tomasi 方法获取图像中 N 个最好的角点(也可以改变参数使用 Harris 角点检测)。通常情况下,输入的应该是灰度图像, 然后确定你想要检测到的角点数目。再设置角点的质量水平在0 到 1 之间, 代表了角点的最低质量,低于这个数的所有角点都会被忽略。最后在设置两个角点之间的最短欧式距离。
根据这些信息,函数就能在图像上找到角点。把合格角点按角点质量进行降序排列, 函数会采用角点质量最高的角点(排序后的第一个),然后将它附近(最小距离之内)的角点都删掉。按着这样的方式最后返回 N 个最佳角点。
cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance[, corners[, blockSize[, gradientSize[, useHarrisDetector[, k]]]]])
'''
maxCorners: 要返回的最大角点数。如果检测到的角点数超过该值,只返回响应值最强的角点。
qualityLevel: 参数表征可接受角点的最低质量水平,该值是强角点响应值占总响应值(可能是角点的所有候选点)的百分比。在 [0, 1] 之间。
minDistance: 角点之间的最小欧氏距离。用于避免角点过密。
corners: 输出的角点坐标数组。如果未提供,则会自动创建一个。
blockSize: 用于计算导数协方差矩阵的邻域大小(以像素为单位)。默认值为 3。
gradientSize: 用于计算图像梯度的 Sobel 算子的大小。默认值为 3。
useHarrisDetector: 布尔值,是否使用 Harris 角点检测(而不是Shi-Tomasi算法)。默认False。
k: Harris 角点检测方程中的自由参数,通常取值在 [0.04, 0.06] 之间。仅在 useHarrisDetector=True 时使用。
返回值 corners: 检测到的角点的坐标数组。每个角点由其 (x, y) 坐标表示。import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray,25,0.01,10)
# 返回的结果是 [[ 311., 250.]] 两层括号的数组。
corners = np.int0(corners)
for i in corners:
x,y = i.ravel()
cv2.circle(img,(x,y),3,255,-1)
cv2.imshow(img)
五、FAST 角点检测的快速算法
1. 使用FAST算法进行特征提取
1.在图像中选取一个像素点p,判断它是不是关键点。Ip等于像素点p的灰度值。
2.选择适当的阈值t。
3.如下图所示,在像素点p的周围选择16个像素点进行测试。

4.如果在这16个像素点中存在n个连续像素点的灰度值都高于Ip+t,或者低于Ip−t,那么像素点p就被认为是一个角点。如上图中的虚线所示,n选取的值为12。
5.为了更快,还可采用加速办法:首先对候选点的周围每个90度的点:1,9,5,13进行测试(先测试1和9,如果它们符合阈值要求再测试5和13)。如果p是角点,那么这四个点中至少有3个要符合阈值要求。对通过这步测试的点再继续进行测试(是否有12的点符合阈值要求)。这个检测器的效率很高,但是它有如下几条缺点:
- 当n<12时它不会丢弃很多候选点(获得的候选点比较多)。
- 像素的选取不是最优的,因为它的效果取决与要解决的问题和角点的分布情况。
- 高速测试的结果被抛弃
- 检测到的很多特征点都是连在一起的。
前3个问题可以通过机器学习的方法解决,最后一个问题可以使用非最大值抑制的方法解决。
2. 机器学习的角点检测器
- 选择一组训练图片(最好和最后应用相关)
- 使用FAST算法找出每幅图像的特征点
- 对每一个特征点,将其周围的16个像素存储构成一个向量。对所有图像都这样做构建一个特征向量P
- 每个像素点都属于下列三类中的一种。
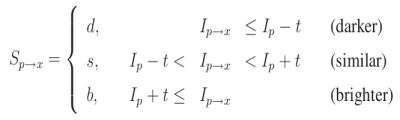
- 根据这些像素点的分类,特征向量P也被分为3个子集:Pd,Ps,Pb
- 定义一个新的布尔变量Kp,如果p是角点就设置为Ture,否则为False.
- 使用ID3算法(决策树分类器)通过变量Kp查询每个子集以获取真实类别的知识。它选择的x能够最有效地表明候选像素是否为角点,通过Kp的熵来测量。
- 递归地应用于所有的子集,直到它的熵为零。
- 将构建好的决策树运用于其它图像的快速的检测。
3. 非极大值抑制
使用极大值抑制解决检测到的特征点相连的问题:
1.对所有检测到到特征点构建一个打分函数V。即像素点p与周围16个像素点差值的绝对值之和。
2.计算临近两个特征点的打分函数V。
3.忽略V值最低的特征点.
4. OpenCV中的FAST
可以设置阈值、是否进行非最大值抑制、要使用的邻域大小等。
邻域设置为下列3种之一:
- cv2.FAST_FEATURE_DETECTOR_TYPE_5_8;
- cv2.FAST_FEATURE_DETECTOR_TYPE_7_12 ;
- cv2.FAST_FEATURE_DETECTOR_TYPE_9_16。
下面是使用 FAST 算 法进行特征点检测的简单代码。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('apple.jpg', 0)
# 使用默认值初始化 FAST 对象
fast = cv2.FastFeatureDetector.create()
# find and draw the keypoints
kp = fast.detect(img, None)
img2 = cv2.drawKeypoints(img, kp,None, color=(255, 0, 0))
# 打印所有默认参数
print( "Threshold: {}".format(fast.getThreshold()) )
print( "nonmaxSuppression:{}".format(fast.getNonmaxSuppression()) )
print( "neighborhood: {}".format(fast.getType()) )
print( "Total Keypoints with nonmaxSuppression: {}".format(len(kp)) )
cv2.imshow('fast_true', img2)
# 禁用非最大抑制:
fast.setNonmaxSuppression(0)
kp = fast.detect(img,None)
print("Total Keypoints without nonmaxSuppression: ", len(kp))
img3 = cv2.drawKeypoints(img, kp,None, color=(255, 0, 0))
cv2.imshow('fast_false', img3)
cv2.waitKey(0)
六、SIFT 尺度不变关键点描述(Scale-Invariant Feature Transform)
1. 尺度空间
对输入图片模拟出近大远小以及模糊的效果,从而使机器对同一张图片的感知与人眼近似。
- SIFT尺度空间:不同大小的高斯核函数对图像进行卷积滤波同时在层级变换之间进行下采样来构建金字塔模式下的尺度空间。
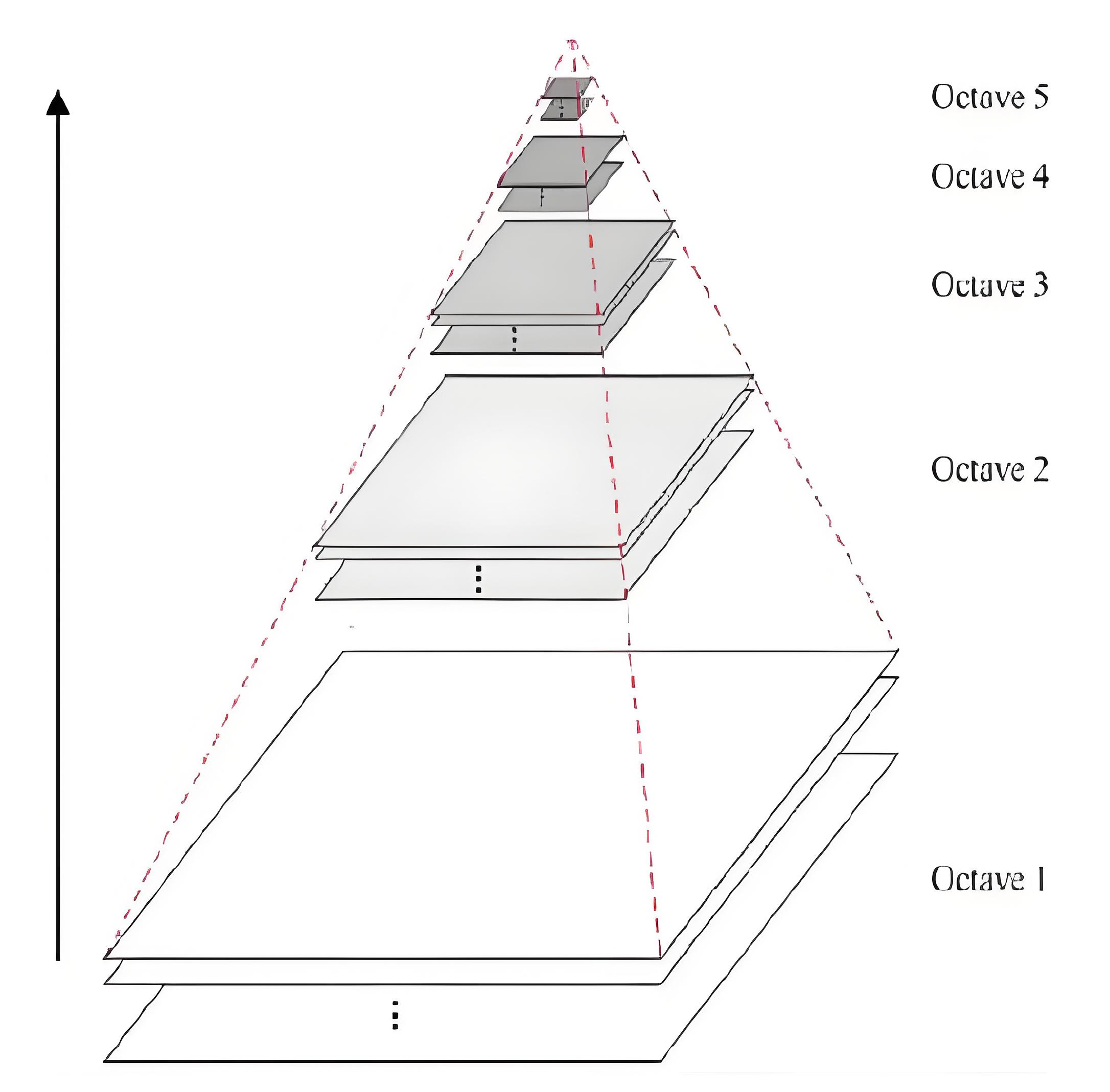
-
- 近大远小:不同的
Octave具有不同的分辨率。 - 模糊:同一
Octave下的图片,进行不同程度的「高斯滤波」
- 近大远小:不同的
高斯金字塔构建
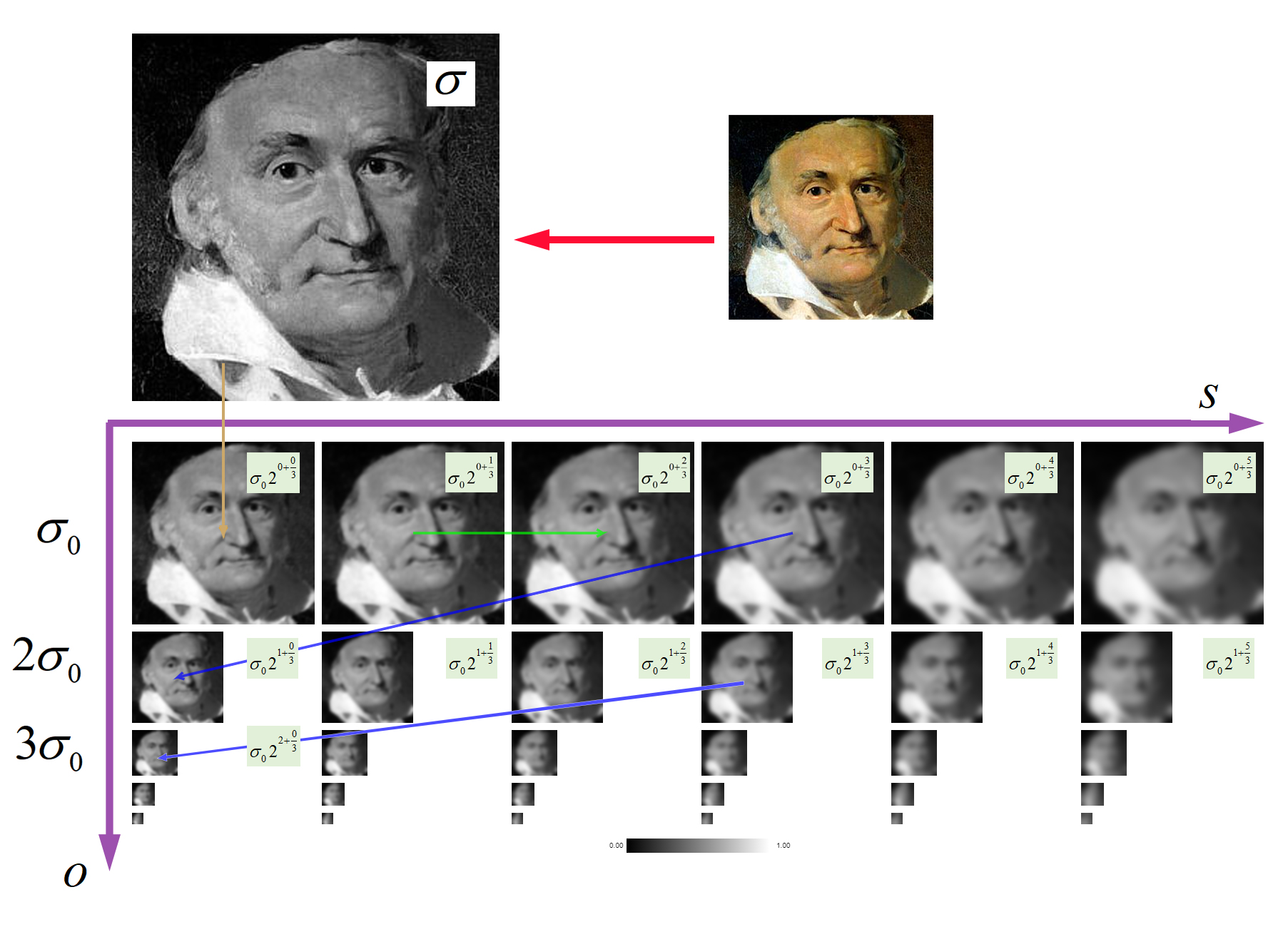
-
- 输入图像首先进行一次高斯上采样(放大,红色箭头),然后再进行高斯模糊、高斯下采样得到金字塔的第一张图片(黄色箭头)。
- 高斯模糊标准计算公式为
𝑜∈[0,⋯,𝑂−1],𝑠∈[0,⋯,𝑆−1]其中 𝑂为 Octave 总数目;𝑜为 Octave 索引号;𝑆为一级 Octave 所内包含图片的总数;𝑠 为一级 Octave 图片索引号;𝑛 为一级 Octave 所能产生的「特征层」(之后说明)总数。𝑆=𝑛+3
- 每一级 Octave 的第一张图片,都可以抽取上一 Octave 的倒数第三张图片(索引号𝑠=𝑆−2)进行一次「高斯下采样」获取(蓝色箭头)。
- 对图片进行高斯模糊实际上可以通过上一张图片得到,而不用从原图获取。具体计算公式为 (具体细节见 高斯滤波的叠加性)

- 高斯核的大小为 (3𝜎+1×3𝜎+1) ,因为高斯分布的置信区间为 [−3𝜎,3𝜎],利用上述「高斯滤波的叠加性」还能缩小每一次高斯核的尺寸,加快速度。
- 为了加速高斯滤波,高斯滤波还能分解为在水平方向一维滤波一次,然后再垂直方向再一维滤波一次。
2. 高斯差分金字塔
高斯金字塔中,同一级 Octave 中,不同模糊程度的相邻图片之间做差。
数学描述:
𝐷(𝑥,𝑦,𝜎)=[𝐺(𝑥,𝑦,𝑘𝜎)−𝐺(𝑥,𝑦,𝜎)]∗𝐼(𝑥,𝑦)=𝐿(𝑥,𝑦,𝑘𝜎)−𝐿(𝑥,𝑦,𝜎)
高斯差分的原因:
高斯核的差分计算结果可以当作是高斯拉普拉斯 𝜎2∇2𝐺 的近似值,研究已经表明高斯拉普拉斯的极大值与极小值产生的「图像特征」效果最好。

3. 特征关键点定位
3.1. 初步查找
关键点: 能稳定确定图像特征的点。在 SIFT 算法中,关键点是差分金字塔中的极大值与极小值位置对应的点。
在「高斯差分金字塔」中,当前点(x位置)与邻近点(绿色圆圈)进行比较,判断当前点是否为局部极值,若是,就把「当前位置」记录下来。
阈值检测: 去除一些噪点或其它一些不稳定像素点,大于阈值的点才进行初步检测

通常取:T=0.04
Note
设一级 Octave 包含有 S 张图片,S 张图片进行高斯差分能产生 S - 1 层,S - 1 层差分层的最上层与最下层无法构成特征层,所以将产生 S - 3 层特征层。因此特征层与高斯层的层数关系为
𝑆=𝑛+3
3.2. 精确定位
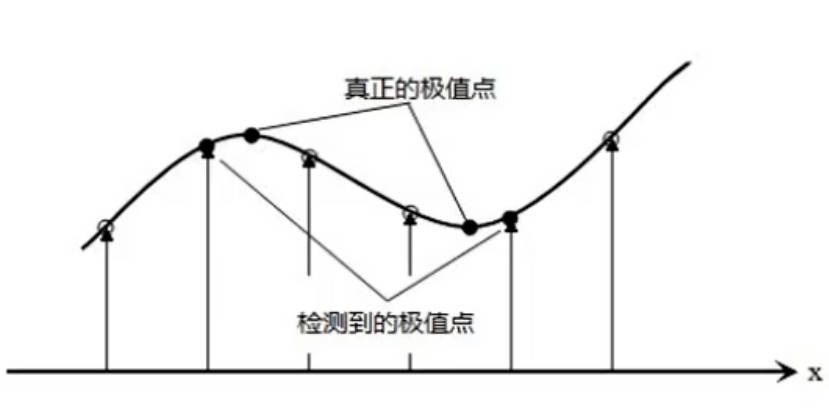
由于差分层中的点为离散点,查找出的关键点位置不一定是真正的极值点位置,还需要对其位置进行补偿。
对初步查找到的关键点 𝑋,在其领域(坐标附近一个很小范围)内进行泰勒展开

极值的条件就为
𝐷′(𝑋𝑖+1)=0
求解得

就是说在位置

取得真正的极值。将结果进行回代

对上述步骤进行迭代,当

小于一定值时,就终止;若计算发散、超出迭代次数,则舍弃掉该点。
最后,再对迭代计算得到的极值进行校验,不满足条件,则丢掉。

通常取:T=0.04
Tip
- 公式中所涉及的偏导数,均可通过差分公式进行计算,在图像滤波章节已进行过推导,因此不再重复。
- 经过校验得到的关键点坐标 [𝑥,𝑦,𝜎]𝑇其取值已经不在是「整数」,极大可能已经变为「浮点数」,但是,不用做整型处理。
3.3. 边缘效应
高斯差分对边缘有很强的灵敏度,这样就会选择出一些不稳定的边缘特征,因此需要排除这些特征。
求解高斯差分的 Hessian 矩阵

令矩阵的特征值为 𝜆1、𝜆2 且满足关系 𝜆1=𝑟𝜆2, 𝑟>1

极值的 Hessian 矩阵要满足下列条件才保留,否则剔除掉。

为指定阈值(比如10)

直观解释
首先回忆求 𝑓(𝑥,𝑦)极值的流程:
- 求解驻点
𝑓𝑥′(𝑥,𝑦)=0 𝑓𝑦′(𝑥,𝑦)=0
- 对驻点进行检验
𝐴=𝑓𝑥𝑥(𝑥,𝑦),𝐵=𝑓𝑥𝑦(𝑥,𝑦),𝐶=𝑓𝑦𝑦(𝑥,𝑦)
-
- 若 𝐴𝐶−𝐵2>0:是极点
- 若 𝐴𝐶−𝐵2<0:不是极点
- 若 𝐴𝐶−𝐵2=0:鞍点
将上述 𝐴,𝐵,𝐶 写成Hessian矩阵形式

𝐷𝑒𝑐(𝐻)=𝐴𝐶−𝐵2。和求解 𝑓(𝑥,𝑦)极值不同的是SFTI算法中是直接比较得到局部极值,然后再通过泰勒展开来进一步定位极值。 Hessian 矩阵的作用就是对得到的极值再进行一次理论上的判定。
此外,不同于二元函数极值检测,SFTI 算法中还对 Hessian 矩阵的特征值进行了阈值限定

绘制出 𝜆1∈[0.001,20], 𝜆2∈[0.001,20]区域内, 𝑓(𝜆1,𝜆2)=

的三维图,如下图所示。可以看见当 𝜆1 或 𝜆2 某一个值太大时,就会导致 𝑓(𝜆1,𝜆2) 的值过大。
为了观察 𝜆1 、𝜆2对平面的影响,定义一个简单的二维平面
𝑓(𝑥,𝑦)=𝑎𝑥2+𝑏𝑦2
其 Hessian 矩阵就为

其中 𝑎、𝑏 就是特征值 𝜆1、𝜆2
从图中可以直观感受,不能放任

的值过大,也不能让其为负数。该值过大时,就会导致所得到的极值点不明显;该值为负数时,得到的关键点为鞍点,不能要。
4. 关键点方向
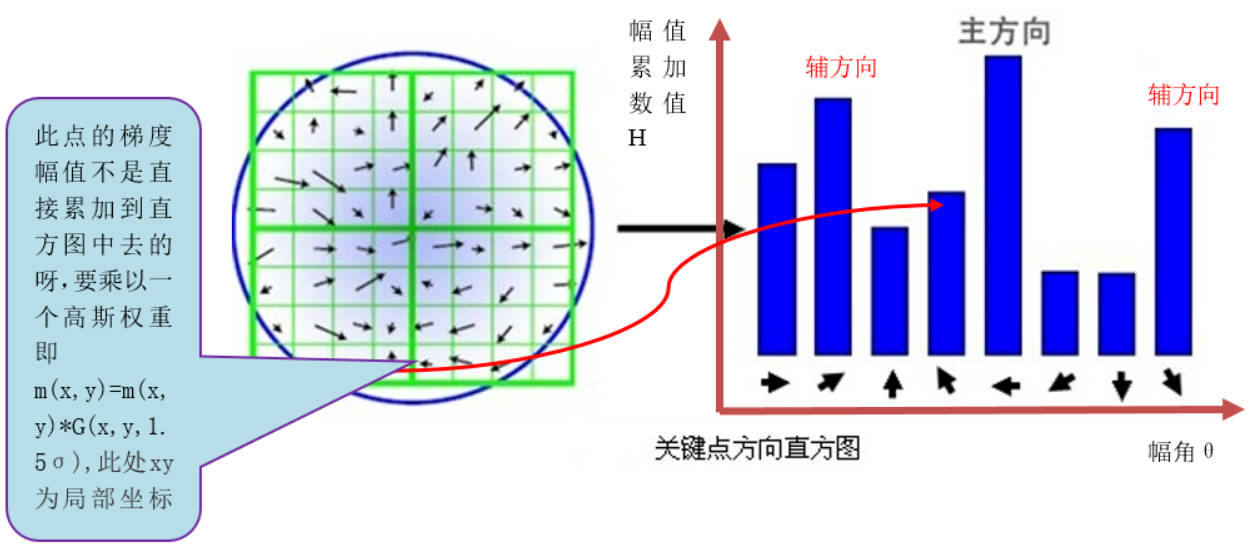
- 由于查找精确位置时,已经将 [𝑥,𝑦,𝜎]𝑇 的值变成浮点数,这就导致通过该坐标无法直接定位「高斯金字塔」的具体像素坐标了,例如图片中,根本不存在像素坐标
[3.5,4.2]。 - 定位图片:关键点坐标中的 𝜎 距离哪张图片最近就选择哪张图片。
- 定位像素:以关键点 (𝑥,𝑦) 为中心点,图像的高斯尺度 𝜎𝑖𝑚𝑔 的 1.5 倍为半径的邻域
- 幅值与角度:需要计算被框住的像素点的幅值与角度

其中 𝐿(𝑥,𝑦) 为高斯金字塔灰度值;𝑚(𝑥,𝑦) 为幅值;𝜃(𝑥,𝑦)为方向
- 𝜃(𝑥,𝑦) 简化:SIFT 算法只选取了
8个方向(每45°为一个方向), 𝜃(𝑥,𝑦) 离哪个方向最近,就选择哪个方向。 - 幅值处理: 为了秉承距离关键点越近,影响越大的原则,所有幅值还要添加权重。
- 直方图统计:以方向为横坐标,对加权后的幅值进行累加,如上图所示。统计:以方向为横坐标,对加权后的幅值进行累加,如上图所示。 为了防止某个梯度方向角度因受到噪声的干扰而突变,还可以对直方图进行平滑处理。
- 方向选择:
-
- 主方向: y值最大的
- 辅方向: 当y值大于主方向的
80 %时,定义为辅方向 - 后续处理中,主方向与辅方向看作是同一位置的两个不同关键点。
5. 关键点描述符
确定了关键点的位置、方向,接下来就对关键点进行数学上的定义。
- 定位像素: 同样以 (𝑥,𝑦)为中心点,取半径为

其中 𝑚 可以取 3(3𝜎𝑖𝑚𝑔 的置信度区间);𝑑 描述符的尺寸。
- 以特征点为中心朝关键点的方向旋转:将关键点特征归一化,使其在不同的角度下都能恒定不变。
- 像素点差值扩充: 选中的像素点还不够用于建立描述符,所以需要对原来的像素进行差值扩充,像素尺寸建议扩展到
16 x 16
- 计算幅值与方向: 同上文所述,计算
16 x 16中每个像素点的梯度幅值与方向 - 描述符创建: 将
16 x 16拆分为16个4x4的子区域,并且每个区域进行直方图统计,记录下8个方向上的幅值。因此,一个关键点描述符的维度就为4*4*8=128。 - 重复上述步骤,将高斯金字塔中的所有关键点描述符创建出来。
6. OpenCV
import cv2
img = cv2.imread('apple.jpg')
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建 SIFT 算法
# SIFT_create([, nfeatures[, nOctaveLayers[, contrastThreshold[, edgeThreshold[, sigma]]]]]) -> retval
' nfeatures:特征层数,要检查的特征数越多这个也应越大
' nOctaveLayers:高斯金字塔 octave 组数
' contrastThreshold:极值点阈值,低于阈值将被丢弃
' edgeThreshold:边缘效应阈值
' sigma: 平滑图像的参数
sift = cv2.SIFT.create()
# 查找关键点位置,第二个参数是掩模
kp = sift.detect(imgGray,None)
# 计算特征
# compute(img,KeyPoints:tuple) -> KeyPoints:tuple, descriptors:np.ndarray
' keypoints:所有关键点
' descriptors:关键点的描述符
kp,des = sift.compute(imgGray,kp)
# 将上面两步骤合并为一个函数: kp,des = sift.detectAndCompute(imgGray,None)
# 绘制关键点
# drawKeypoints(image, keypoints, outImage[, color[, flags]]) -> outImage
'flags:如果设置为 cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS 绘制关键点大小的圆圈甚至绘制关键点的方向
cv2.drawKeypoints(img,kp,img)
cv2.imshow('img',img)
cv2.waitKey(0)# 得到的是 KeyPoint 类的一个元组
kps = sift.detect(img,None)
kp = kps[0]
# 坐标位置
kp.pt
# 关键点的角度
kp.angle
# 关键点的幅值
kp.response7. SURF 加速鲁棒特征(Speed-Up Robust Features)
2006 年《SURF:Speeded Up Robust Features》中介绍了SURF。顾名思义它是 SIFT 的加速版本,处于专利保护状态
SIFT中尺度空间使用的是「高斯差分DoG」对「拉普拉斯差分LoG」近似,而SURF使用「盒式滤波」对LoG进行近似。下图显示了这种近似。在进行卷积计算时可以利用积分图像(积分图像的一大特点是:计算图像中某个窗口内所有像素和时,计算量的大小与窗口大小无关),是盒式滤波的一大优点。而且这种计算可以在不同尺度空间同时进行。同样SURF算法使用Hessian矩阵的行列式来确定尺度和位置。
为了保证特征矢量具有旋转不变性,需要对每一个特征点分配一个主要方向。需要以特征点为中心,以6s(s为特征点的尺度)为半径的圆形区域内,对图像进行「Harr小波」相应运算。这样做实际就是对图像进行梯度运算,但是利用积分图像,可以提高计算图像梯度的效率,为了求取主方向值,需哟啊设计一个以方向为中心,张角为60度的扇形滑动窗口,以步长为0.2弧度左右旋转这个滑动窗口,并对窗口内的图像Harr小波的响应值进行累加。主方向为最大的Harr响应累加值对应的方向。在很多应用中根本就不需要旋转不变性,所以没有必要确定它们的方向,又可以使算法提速。
SURF提供了成为U-SURF的功能,它具有更快的速度,同时保持了对+/-15度旋转的稳定性。OpenCV对这两种模式同样支持,只需要对参数upright进行设置,当upright为0时计算方向,为1时不计算方向,同时速度更快。
生成特征点的特征矢量需要计算图像的Haar小波响应。在一个矩形的区域内,以特征点为中心,沿主方向将20s*20s的图像划分成4*4个子块,每个子块利用尺寸2s的Haar小波模版进行响应计算,然后对响应值进行统计,组成向量v=(∑dx,∑dy,∑|dx|,∑|dy|)。这个描述符的长度为64。降低的维度可以加速计算和匹配,但又能提供更容易区分的特征。为了增加特征点的独特性,SURF还提供了一个加强版128维的特征描述符。当dy大于0和小于0时分别对dx和|dx|的和进行计算,计算dy和|dy|时也进行区分,这样获得特征就会加倍,但又不会增加计算的复杂度。OpenCV同样提供了这种功能,当参数extended设置为1时为128维,当参数为0时为64维,默认情况为128维。
在检测特征点的过程中计算了Hessian矩阵的行列式,与此同时,计算得到了Hessian矩阵的迹,矩阵的迹为对角元素之和。
按照亮度的不同,可以将特征点分为两种,第一种为特征点迹其周围小邻域的亮度比背景区域要亮,Hessian矩阵的迹为正;另外一种为特征点迹其周围小邻域的亮度比背景区域要暗,Hessian矩阵为负值。根据这个特性,首先对两个特征点的Hessian的迹进行比较。如果同号,说明两个特征点具有相同的对比度;如果异号的话,说明两个特征点的对比度不同,放弃特征点之间的后续的相似性度量。
对于两个特征点描述子的相似性度量,我们采用欧式距离进行计算。简单来说SURF算法采用了很多方法来对每一步进行优化从而提高速度。
分析显示在结果效果相当的情况下SURF的速度是SIFT的3倍。SURF善于处理具有模糊和旋转的图像,但是不善于处理视角变化和关照变化。
8. OpenCV
与SIFT相同OpenCV也提供了SURF的相关函数。首先我们要初始化一个SURF对象,同时设置好可选参数:64/128维描述符,Upright/Normal模式等。所有的细节都已经在文档中解释的很明白了。就像我们在SIFT中一样,我们可以使用函数SURF.detect(),SURF.compute()等来进行关键点搀着和描述。
首先从查找描述绘制关键点开始。由于和SIFT一样所以我们的示例都在Python终端中演示。
img = cv.imread('fly.png',0)
# 创建SURF对象。您可以在这里或稍后指定参数。这里将Hessian阈值设置为400
surf = cv.xfeatures2d.SURF_create(400)
# 直接查找关键字和描述符
kp, des = surf.detectAndCompute(img,None)
print(len(kp)) # 699在一幅图像中显示699个关键点太多了。我们把它缩减到50个再绘制到图片上。在匹配时,我们可能需要所有的这些特征,不过现在还不需要。所以我们现在提高Hessian的阈值。
# 检查当前Hessian阀值
print( surf.getHessianThreshold() ) # 400.0
# 我们把它定在50000左右。记住,它只是用来表示图像的。在实际情况中,值最好是300-500
surf.setHessianThreshold(50000)
# 再次计算关键点并检查它的编号.
kp, des = surf.detectAndCompute(img,None)
print( len(kp) ) # 47
img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)
plt.imshow(img2),plt.show()结果如下。你会发现SURF很像一个斑点检测器。它可以检测到蝴蝶翅膀上的白班。你可以在其它图片中测试一下。

现在我们试一下U-SURF,它不会检测关键点的方向。
# 检查upright标志,如果它是False,设置为True
print( surf.getUpright() ) #False
surf.setUpright(True)
# 重新计算特征点并绘制它
kp = surf.detect(img,None)
img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)
plt.imshow(img2),plt.show()结果如下。所有的关键点的朝向都是一致的。它比前面的快很多。如果你的工作对关键点的朝向没有特别的要求(如全景图拼接)等,这种方法会更快。

最后我们再看看关键点描述符的大小,如果是64维的就改成128维。
# 查找描述符的大小
print( surf.descriptorSize() ) # 64
# 这意味着"extended"为False.
surf.getExtended() # False
# 所以我们将其设置成True得到128个模糊描述符.
surf.setExtended(True)
kp, des = surf.detectAndCompute(img,None)
print( surf.descriptorSize() ) # 128
print( des.shape ) # (47, 128)9. BRIEF 二值稳健的独立补充特征
SIFT 算法使用的是 128 维的描述符,由于它是使用的浮点数,所以要使用 512 个字节。同样 SURF 算法最少使用 256 个字节(64 维描述符)。为成千上万的特征创建这样的向量需要大量的内存,匹配时还会消耗更多时间。
在实际的匹配过程中如此多的维度是没有必要的。我们可以使用 PCA, LDA 等方法来进行降维。甚至可以使用 LSH(局部敏感哈希)将 SIFT 浮点数的描述符转换成二进制字符串。对这些字符串再使用汉明距离进行匹配。汉明距离的计算只需要进行 XOR 位运算以及位计数。但我们还是要先找到描述符才能使用哈希,这不能解决最初的内存消耗问题。
BRIEF (Binary Robust Independent El-ementary Features)应运而生。它不去计算描述符而是直接找到一个二进制字符串,使用已经平滑后的图像,按照一种特定的方式选取一组像素点对 nd (x,y),然后在这些像素点对之间进行灰度值对比。例如,第一个对点的灰度值分别为 p 和 q。如果 p 小于 q,结果就是 1,否则就是 0。就这样对 nd 个点对进行对比得到一个 nd 维的二进制字符串。
nd 可以是 128,256,512。OpenCV支持这些值,但在默认情况下是 256(OpenCV 以字节表示它们,所以这些值分别对应与 16,32,64)。当我们获得这些二进制字符串之后就可以使用汉明距离对它们进行匹配了。
非常重要的一点是:BRIEF 是一种特征描述符,它不提供查找特征的方法。 所以我们不得不使用其它特征检测器,比如 SIFT 和 SURF 等。文献推荐使用 CenSurE 特征检测器,这种算法很快。而且 BRIEF 算法对 CenSurE 关键点的描述效果要比SURF关键点的描述更好。
简单来说 BRIEF 是一种对特征点描述符计算和匹配的快速方法。除非存在较大的平面旋转,它还能提供较高的识别率。
STAR 是从 CenSurE 演化而来的一个特征检测器。然而,与 CenSurE 不同,CenSurE 使用多边形如正方形、六边形和八边形来逼近圆形,而 STAR 则用两个重叠的正方形来模拟圆形:一个直立放置,另一个以 45 度角旋转。这些多边形是二值的。它们可以被视为具有粗边界的多边形。边界的权重和内部区域的权重符号相反。这比其他尺度空间检测器有更好的计算特性,并且能够实现实时处理。与 SIFT 和 SURF 不同,SIFT 和 SURF 在亚采样像素中寻找极值,这在较大尺度上会牺牲准确性,而 CenSurE 则在金字塔的所有尺度上使用全空间分辨率创建特征向量。
10. OpenCV
下面的代码使用了 CenSurE 特征检测器和 BRIEF 描述符。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('apple.jpg', cv.IMREAD_GRAYSCALE)
# Initiate STAR detector
star = cv.xfeatures2d.StarDetector.create()
# Initiate BRIEF extractor
brief = cv.xfeatures2d.BriefDescriptorExtractor.create()
# find the keypoints with STAR
kp = star.detect(img,None)
# compute the descriptors with BRIEF
kp, des = brief.compute(img, kp)
print( brief.descriptorSize() )
print( des.shape )
img3 = cv2.drawKeypoints(img, kp,None, color=(255, 0, 0))
cv2.imshow('BRIEF', img3)
cv2.waitKey(0)11. ORB
ORB是OpenCV中对于SIFT和SURF的替代方案,首先它使用 FAST 找到关键点,然后再使用 Harris 角点检测对这些关键点进行排序找到其中的前 N 个点。它也使用金字塔从而产生尺度不变性特征。它使用灰度矩的算法计算出角点的方向。以角点到角点所在(小块)区域质心的方向为向量的方向。为了进一步提高旋转不变性,要计算以角点为中心 半径为 r 的圆形区域的矩,再根据矩计算除方向。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg', cv.IMREAD_GRAYSCALE)
# Initiate ORB detector # 初始化 ORB 检测器
orb = cv2.ORB.create()
'''参数:
nfeatures:要保留的特征点数量(默认 500)。
scaleFactor:图像金字塔的缩放因子(默认 1.2)。
nlevels:金字塔层数(默认 8)。
edgeThreshold:边缘阈值,定义关键点检测范围(默认 31)。
firstLevel:金字塔的起始层(默认 0)。
WTA_K:BRIEF 描述符的每个特征点的比较数量(默认 2)。
patchSize:计算描述符时的邻域大小(默认 31)。
fastThreshold:FAST 关键点检测的阈值(默认 20)
'''
# 使用 ORB 找到关键点
kp = orb.detect(img,None)
# 计算 ORB 的描述符
kp, des = orb.compute(img, kp)
#或者也可以直接 kp,des= orb.detectAndCompute(img,None)
# 仅绘制关键点位置,不绘制大小和方向
img2 = cv2.drawKeypoints(img, kp, None, color=(0,255,0), flags=0)
plt.imshow(img2), plt.show()七、特征匹配
BF暴力匹配
暴力匹配器会取第一组中一个特征的描述符,并使用某种距离计算与第二组中的所有其他特征进行匹配。然后返回最接近的一个。
bf=cv2.BFMatcher(normType: int, crossCheck: bool)#创建 BFMatcher 对象
'normType: 用来指定距离测试类型, 默认cv2.Norm_L2。很适合SIFT和SURF等(cv2.NORM_L1 也可以)
' 对于使用二进制描述符的 ORB,BRIEF,BRISK 算法等,要使用 cv2.NORM_HAMMING,返回的汉明距离。
' 如果 ORB 算法的参数设置为 WTA_K==3 或 4,normType 就应该设置成cv2.NORM_HAMMING2。
'crossCheck:交叉检测,默认False。如果设为 True,
' 只有到 A 的第 i 个特征点与 B 的第 j 个特征点距离最近,并且B的第j特征点到A的i特征点也最近
' (A 中没有其它点到 j 的距离更近)时才会返回最佳匹配(i,j)。也就是这两个特征点要互相匹配才行
' 这样能提供统一的结果,这可以用来替代 D.Lowe 在 SIFT 文章中提出的比值测试方法。
bf.match(queryDescriptors,[trainDescriptors[,mask]])-> Sequence #返回最佳匹配
bf.knnMatch(qDes[,tDes],k[,mask],compactResult:bool) #每个关键点返回k个最佳匹配(降序排列之后取前 k 个)
#返回对象的属性:
'• DMatch.distance - 描述符之间的距离。越小越好。
'• DMatch.trainIdx - 目标图像中描述符的索引。
'• DMatch.imgIdx - 目标图像的索引。
'• DMatch.queryIdx - 查询图像中描述符的索引。
cv2.drawMatches(img1,keypoints1: Sequence[KeyPoint],
img2,keypoints2: Sequence[KeyPoint],
matches1to2: Sequence[DMatch],
outImg,matchColor,singlePointColor,
matchesMask,flags: DrawMatchesFlags)
#会将两幅图像水平排列,然后在最佳匹配的点之间绘制直线(从原图像到目标图像)
cv2.drawMatchesKnn()(1).对ORB描述符暴力匹配
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('apple.jpg',0) # queryImage
img2 = cv2.imread('apple.jpg',0) # trainImage
# Initiate ORB detector
orb = cv2.ORB.create()
# find the keypoints and descriptors with ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# create BFMatcher object
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1,des2)
# Sort them in the order of their distance.
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches,None,flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('out',img3)
cv2.waitKey(0)
(2).对SIFT的KNN暴力匹配
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('apple.jpg',0) # queryImage
img2 = cv2.imread('apple.jpg',0) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT.create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# BFMatcher with default params
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# Apply ratio test
# 比值测试,首先获取与A 距离最近的点B(最近)和C(次近),只有当B/C小于阈值时(0.75)才被认为是匹配,因为假设匹配是一一对应的,真正的匹配的理想距离为0
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance: good.append([m])
# cv2.drawMatchesKnn expects list of lists as matches.
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good,None, flags=2)
plt.imshow(img3), plt.show()
FLANN匹配器
FLANN 是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors) 的简称。它包含了一系列针对大型数据集和高维特征优化的快速最近邻搜索算法。在面对大数据集时快于 BFMatcher。
使用 FLANN 匹配,需要传入两个字典作为参数,以指定要使用的算法及其相关参数等。第一个是 IndexParams。各种不同算法的信息可以在 FLANN 文档中找到。总的来说,对于 SIFT 和 SURF 等可以传入的参数是:
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)但使用 ORB 时,我们要传入的参数如下。注释掉的值是文献中推荐使用的,但是它们并不适合所有情况,当前值效果可能会更好。
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2第二个字典是 SearchParams,用它来指定递归遍历的次数,值越高结果越准确,但是消耗的时间也越多。 如果想修改这个值,传入参数:searchparams = dict(checks = 100)。
import numpy as np
import cv2
import matplotlib.pyplot as plt
img1 = cv2.imread('box.png',cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv2.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT.create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# Need to draw only good matches, so create a mask,和上面的good筛选效果一致
matchesMask = [[0,0] for i in range(len(matches))]
# 根据Lowe论文中的比率测试
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),#使用字典传入参数
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = cv2.DrawMatchesFlags_DEFAULT)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
plt.imshow(img3,),plt.show()
特征匹配+单应性变换查找对象
——联合使用特征提取和 calib3d 模块中的 findHomography 在复杂图像中查找已知对象。
之前我们在图像中找到一些特征点(关键点),我们又在另一幅图像中也找到了一些特征点,最后对这两幅图像之间的特征点进行匹配。简单来说就是:我们在一张杂乱的图像中找到了一个对象(的某些部分)的位置。这些信息足以帮助我们在目标图像中准确找到该对象。
可以使用 calib3d 模块中的 cv2.findHomography() 函数。将这两幅图像中的特征点集传给这个函数,它就会找到这个对象的透视图变换。然后我们就可以使用函数 cv2.perspectiveTransform() 找到这个对象了。至少要 4 个正确的点才能找到这种变换。
在匹配过程可能会有一些错误,这些错误会影响最终结果。为了解决这个问题,算法使用随机抽样一致算法RANSAC 和 LEAST_MEDIAN(可以通过参数来设定):正确的估计被称为内点,剩下的被称为外点。cv2.findHomography() 返回一个掩模,这个掩模确定了内点和外点。
import numpy as np
import cv2
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10 #最小为4
img1 = cv2.imread('box.png', cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv2.imread('box_in_scene.png', cv.IMREAD_GRAYSCALE) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT.create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1,des2,k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)设置只有存在 10 个以上匹配时才去查找目标(MIN_MATCH_COUNT=10), 否则显示警告消息:“现在匹配不足!”如果找到了足够的匹配, 我们要提取两幅图像中匹配点的坐标, 把它们传入到函数中计算透视变换。一旦我们找到 3x3 的变换矩阵, 就可以使用它将查询图像的四个顶点(四个角)变换到目标图像中去了。
if len(good)>MIN_MATCH_COUNT:
# 获取关键点的坐标
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
# 第三个参数 用于计算单应矩阵的方法。以下是可能的方法:
# 0 - 使用所有点的常规方法
# CV_RANSAC - RANSAC-based robust method
# CV_LMEDS - Least-Median robust method
# 第四个参数取值范围在 1 到 10, 拒绝一个点对的阈值。原图像的点经过变换后点与目标图像上对应点的误差, 超过误差就认为是 outlier
# 返回值中 M 为变换矩阵。
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
# 获得原图像的高和宽
h,w = img1.shape
# 使用得到的变换矩阵对原图像的四个角进行变换,获得在目标图像上对应的坐标。
pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
# 原图像为灰度图
cv2.polylines(img2,[np.int32(dst)],True,255,10, cv2.LINE_AA)
else:
print ("Not enough matches are found - %d/%d" % (len(good),MIN_MATCH_COUNT))
matchesMask = None
draw_params = dict(matchColor = (0,255,0), # draw matches in green color
singlePointColor = None,
matchesMask = matchesMask, # draw only inliers
flags = 2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
cv2.imshow('pipei',img3)
cv2.waitKey(0)
八、HOG特征描述
视频分析
HDR高动态范围成像
多数数字成像设备每通道使用 8 位,从而将设备的亮度范围限制在 256 级,而人眼可以适应亮度范围达十个数量级。当我们拍摄现实场景的照片时,明亮区域可能会过曝,而暗区域可能会欠曝,因此我们无法使用单次曝光捕捉所有细节。高动态范围(HDR)成像使用每通道超过 8 位的图像(通常为 32 位浮点值),允许更宽的动态范围。
获取HDR图像的方法有多种,但最常见的方法是使用不同曝光值拍摄场景的照片。在将 HDR 图像融合之后,需要将其转换回 8 位,以便在普通显示器上查看,这个过程称为色调映射。当场景中的物体或相机在拍摄之间移动时,还会出现额外的复杂性,因为不同曝光的图像需要进行配准和对齐。
images, times = loadExposureSeq(args.input)首先,我们从用户定义的文件夹中加载输入图像和曝光时间。该文件夹应包含图像和 list.txt 文件,该文件包含文件名和逆曝光时间。我们的图像序列列表如下:
memorial00.png 0.03125
memorial01.png 0.0625
...
memorial15.png 1024
calibrate = cv.createCalibrateDebevec()
response = calibrate.process(images, times)需要知道相机响应函数(CRF)才能进行许多 HDR 构建算法。我们使用一种校准算法来估计所有 256 个像素值的逆 CRF。
merge_debevec = cv.createMergeDebevec()
hdr = merge_debevec.process(images, times, response)我们使用 Debevec 的加权方案,根据上一步计算出的响应来构建高动态范围图像。
tonemap = cv.createTonemap(2.2)
ldr = tonemap.process(hdr)为了在常见的 LDR 显示器上看到我们的结果,我们必须将 HDR 图像映射到 8 位范围,同时保留大部分细节。这是调光映射方法的主要目标。我们使用双边滤波的调光映射器,并将伽马校正的值设为 2.2。
merge_mertens = cv.createMergeMertens()
fusion = merge_mertens.process(images)在不需要 HDR 图像的情况下,有一种替代方法可以合并我们的曝光。这个过程称为曝光融合,会产生不需要进行伽马校正的 LDR 图像。它也不使用照片的曝光值
cv.imwrite('fusion.png', fusion * 255)
cv.imwrite('ldr.png', ldr * 255)
cv.imwrite('hdr.hdr', hdr)请注意,HDR 图像不能存储在一种常见的图像格式中,所以我们将其保存为辐射度图像(.hdr)。另外,所有 HDR 成像函数返回的结果范围为 [0, 1],所以我们应该将结果乘以 255。
你可以尝试其他色调映射算法:cv::TonemapDrago、cv::TonemapMantiuk 和 cv::TonemapReinhard 你也可以调整 HDR 校准和色调映射方法中的参数以适应你自己的照片。


from __future__ import print_function
from __future__ import division
import cv2 as cv
import numpy as np
import argparse
import os
def loadExposureSeq(path):
images = []
times = []
with open(os.path.join(path, 'list.txt')) as f:
content = f.readlines()
for line in content:
tokens = line.split()
images.append(cv.imread(os.path.join(path, tokens[0])))
times.append(1 / float(tokens[1]))
return images, np.asarray(times, dtype=np.float32)
parser = argparse.ArgumentParser(description='Code for High Dynamic Range Imaging tutorial.')
parser.add_argument('--input', type=str, help='Path to the directory that contains images and exposure times.')
args = parser.parse_args()
if not args.input:
parser.print_help()
exit(0)
images, times = loadExposureSeq(args.input)
calibrate = cv.createCalibrateDebevec()
response = calibrate.process(images, times)
merge_debevec = cv.createMergeDebevec()
hdr = merge_debevec.process(images, times, response)
tonemap = cv.createTonemap(2.2)
ldr = tonemap.process(hdr)
merge_mertens = cv.createMergeMertens()
fusion = merge_mertens.process(images)
cv.imwrite('fusion.png', fusion * 255)
cv.imwrite('ldr.png', ldr * 255)
cv.imwrite('hdr.hdr', hdr)背景减除
背景减除(Background subtraction,BS)是一种使用静态相机生成前景掩码(即包含场景中移动物体像素的二值图像)的常用技术。顾名思义,BS计算前景掩码,执行当前帧和背景模型之间的减法,包含场景的静态部分,或者更一般地说,考虑到所观察场景的特征,所有可以被视为背景的部分。
1. 帧差法
- 思想: 由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。
- 实现:
-
- 相邻两张图片做差值

-
- 标记出灰度变化大于阈值的部分

-
- 𝑅n 标记出来的部分就认为就是非背景部分
- 缺陷:
-
- 容易引入噪点: 摄像机稍微动一下,前后背景的像素位置就发生变化
- 输出结果具有空洞
bgimg = cv2.imread('./asset/diffFrame_background.jpg')
fgimg = cv2.imread('./asset/diffFrame_people.jpg')
bgimgGray = cv2.cvtColor(bgimg,cv2.COLOR_BGR2GRAY)
fgimgGray = cv2.cvtColor(fgimg,cv2.COLOR_BGR2GRAY)
# 灰度差值运算
diff = np.abs(cv2.subtract(bgimgGray,fgimgGray))
# 标记灰度变化较大的部分
mask = np.zeros_like(diff)#根据指定数组形状创建全零数组
mask[diff > 12] = 255
2. 混合高斯模型
高斯混合模型: 由K个单高斯模型组合而成的模型,这K个子模型是混合模型的隐变量(K常取3~5)
高斯模型: 一组数据的分布遵循高斯分布
背景建模思路: 一定时间范围内,位置固定的摄像机视角下, 背景可以视为不变,每个灰度值对应多个高斯模型,即一个像素点对应一个高斯混合模型,其中的每个高斯模型又对应一个权重值

一个像素点定位 𝐼(𝑥,𝑦,𝑡),一个高斯模型的确定 (𝜇,𝜎,𝑤)
- 模型建立步骤:
a. 根据第一帧图片 𝐼0(𝑥,𝑦) 对每个像素点的高斯混合模型中的第一个高斯模型进行初始化

b. 传入第 𝑖 帧图片 𝐼𝑖(𝑥,𝑦),对每个像素点的高斯混合模型进行更新
-
-
- 存在
:则认为该位置的像素值 𝐼(𝑥,𝑦,𝑖)满足高斯模型 (𝜇𝑗,𝜎𝑗,𝑤𝑗) 是背景像素点。并对该高斯模型进行更新(𝜆常取3)
- 存在
-

-
-
- 满足
:则认为 (𝑥,𝑦) 位置产生了新的高斯分布,需要新建一个高斯模型进行描述。若高斯模型的个数 𝑛=𝑘 (该像素位置的混合高斯模型数已经达到最大值),则需要对该像素位置的高斯模型进行删减,然后建立新的高斯模型,初始化同步骤1,其权重值给定一个小值,例如 𝑤𝑛+1(𝑥,𝑦)=0.0001
- 满足
-
c. 将权重归一化

d. 重复上述步骤
- 模型删减: 权重值越大,方差越小(像素变化不大)的模型应当保留。
-
- 根据 𝑘𝑒𝑦 值对高斯模型「降序」排序

-
- 若前 𝑁 个模型满足
则将 𝑁 之后的所有模型删除。
- 若前 𝑁 个模型满足
- 模型背景检测: 输入第 𝑖 帧图片 𝐼𝑖(𝑥,𝑦)
-
- 存在
:则认为像素点 𝐼(𝑥,𝑦,𝑖) 为背景(𝜆常取2)
- 满足
:则认为像素点 𝐼(𝑥,𝑦,𝑖) 非背景
- 存在
2.1. BackgroundSubtractorMOG2
这个也是以高斯混合模型为基础的背景/前景分割算法。这个算法为每个像素选择一个合适数目的高斯分布。(上面使用是 K 高斯分布)。这样就会对由于亮度等发生变化引起的场景变化产生更好的适应。
cv2.createBackgroundSubtractorMOG2(
history: int = 500, #处理的历史帧数.即多少帧参与背景建模,较大时,模型对较长时间的背景变化更加适应(适合静态背景)
varThreshold: float = 16, #用于区分前景和背景的阈值。值越大越易识别为背景
detectShadows: bool = True #是否启用阴影检测(阴影以灰色标记)
) -> BackgroundSubtractorMOG2import cv2
import numpy as np
cap = cv2.VideoCapture(0)
fgbg = cv2.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
fgmask=cv2.morphologyEx(fgmask,cv2.MORPH_OPEN,np.ones((3,3)))
contours,hi=cv2.findContours(fgmask,3,2)
move=0
for c in contours:
move+=cv2.contourArea(c)
cv2.imshow('frame',fgmask)
print(move)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
2.2. BackgroundSubtractorKNN
基于k近邻的背景/前景分割算法。该类实现了k近邻背景减法。如果前景像素的数量比较低将非常有效。用法同上
均值漂移 目标跟踪
Meanshift
Meanshift(均值偏移) 算法的基本原理很简单。假设我们有一堆点(可以是像直方图反投影那样的像素分布)和一个小窗口(可能是一个圆圈),我们要完成的任务就是将这个窗口移动到最大灰度密度处(点最多的地方)如下图所示:
初始窗口是蓝色“C1”,它的圆心为蓝色方框“C1_o”,而窗口中所有点的质心却是“C1_r”,圆心和点的质心没有重合。所以移动圆 心 C1_o 到质心 C1_r,这样就得到了一个新的窗口。这时又可以找到新窗口内所有点的质心,大多数情况下还是不重合的,所以重复上面的操作:将新窗口的中心移动到新的质心。就这样不停的迭代操作直到窗口的中心和其所包含点的质心重合(或者有一点小误差)。这样我们的窗口最终会落在像素值(和)最大的地方。如上图所示“C2”是窗口的最后位置,该窗口中的像素点最多。整个过程如下图所示:

通常情况下我们要使用直方图反向投影得到的图像和目标对象的起始位置。当目标对象的移动会反映到直方图反向投影图中。因此meanshift 算法把窗口移动到图像中灰度密度最大的区域。
在 OpenCV 中使用 Meanshift 算法首先要对目标对象进行设置,计算目标对象的直方图,这样在执行 meanshift 算法时就可以将目标对象反向投影到每一帧中。另外我们还需要提供窗口的起始位置。在这里我们值计算 H(Hue)通道的直方图,同样为了避免低亮度造成的影响,我们使用函数 cv2.inRange() 将低亮度的值忽略掉。
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # 硬编码目标初始位置,(c, r) 是目标区域左上角坐标,w, h 是目标的宽和高。
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((255.,255.,255.))) #过滤掉低亮度和非肤色的颜色,只保留 0-180 之间的 H(色调)通道。
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180]) #计算 ROI 的 H 通道直方图。
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)#归一化直方图,使得直方图值在 0-255 之间,增强对比度。
# 设置终止标准,进行10次迭代或移动的中心点变化小于 1
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# Draw it on image
x,y,w,h = track_window
img2 = cv2.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv2.imshow('img2',np.hstack([img2,cv2.cvtColor(dst,cv2.COLOR_GRAY2BGR)]))
k = cv2.waitKey(5) & 0xff
if k == 27:
break
else:
break
cv2.destroyAllWindows()
cap.release()
Camshift自适应的目标跟踪算法
该算法能够在跟踪目标的同时适应目标的大小和方向。这个算法首先要使用 meanshift,找到(并覆盖)目标之后, 再去调整窗口的大小。它还会计算目标对象的最佳外接椭圆的角度,并以此调节窗口角度。然后使用更新后的窗口大小和角度来在原来的位置继续进行 meanshift。重复这个过程知道达到需要的精度。如下图所示:
与 Meanshift 基本一样,但是返回的结果是一个带旋转角度的矩形(这是我们的结果),以及这个矩形的参数(被用到下一次迭代过程中)。下面是代码:
import numpy as np
import cv2
cap = cv2.VideoCapture('slow.flv')
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# Draw it on image
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame,[pts],True, 255,2)
cv2.imshow('img2',img2)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k)+".jpg",img2)
else:
break
cv2.destroyAllWindows()
cap.release()
光流估计
- 光流:空间运动物体在观测成像平面上的像素运动的「瞬时速度」,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。
- 分类
-
- 稀疏光流:选择运动物体的特征点进行光流估计
- 稠密光流:选择整个运动物体进行光流估计
Lucas-Kanade 稀疏光流
假设:
- 亮度恒定:待估计光流的两帧图像的同一物体的亮度不变,一瞬间前后两帧图片的亮度变化基本不变。
- 两帧之间为小运动:只有小运动情况下才能用前后帧之间单位位置变化的灰度变化近似灰度对位置的偏导数。
- 邻域光流相似:一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。
根据「亮度恒定」假设,可知前后两帧的亮度变化I(x,y,t)与I(x+dx,y+dy,t+dt)满足
![]()
对后者进行一阶泰勒展开
![]()
根据 「两帧之间为小运动」Ix',Iy',It' 均可以根据差分公式进行计算。化简上式得
![]()
两边除 dt
![]()
令u=dxdt,v=dydt得
(u,v)就是我们需要的「光流」,但是两个未知数只有一个方程。又根据「邻域光流相似」描述,相邻的像素点对应的光流是一样的
上述式子简写为
根据最小二乘法,可以求解得
当前我们假设运动都为小运动,如果有大的运动怎么办呢?我们可以用图像金字塔的顶层,此时小的运动被移除,大的运动装换成了小的运动,再使用 Lucas-Kanade 算法,就会得到尺度空间上的光流。
Tip
- Lucas-Kanade算法还借助了图像金字塔(Pyramid)的方式,在高层低分辨率图像上,大的偏移将变为小的偏移。
- 求解 (ATA)−1 需要保证 ATA 可逆。ATA 的展开形式与「Harris 算法」中的特征矩阵形式一样,而 Harris 的特征矩阵是能保证可逆的,因此,Lucas-Kanade算法可用于对「角点」进行光流估计。
# 获取角点
lastPoints = cv2.goodFeaturesToTrack(lastFrameGray,100,qualityLevel=0.2,minDistance=7)
# 光流估计
# winSize:领域区间
# maxLevel:金字塔层数
# criteria: 迭代搜索算法的终止条件,可以是迭代次数和/或所需的最小变化量。
# flags: 操作标志,可以是 cv2.OPTFLOW_LK_GET_INITIAL_ESTIMATES 或 0。如果设置 cv2.OPTFLOW_LK_GET_INITIAL_ESTIMATES,则使用 lastPoints 中的初始估计值作为搜索的起始点;否则,将 prevPts 中的点反射到金字塔的最高层,并从那里开始搜索。
# minEigThreshold: 算法计算光流方程的最小特征值阈值。只有那些至少有一个特征值大于 minEigThreshold 的点才会被认为是好的点并被跟踪。
curPoints,statas,err = cv2.calcOpticalFlowPyrLK(lastFrameGray,curFrameGray,lastPoints,None,winSize=(15,15),maxLevel=2[, criteria[, flags[, minEigThreshold]]])
# curPoints:上一步特征点当前跑到哪个位置了
# state:上一步的特征点当前找没找到,1为找到
# err: 输出错误数组,每个元素表示对应点的光流估计误差。#光流估计
import cv2
import numpy as np
video=cv2.VideoCapture('xm.mp4')
# 角点检测的参数
feature_params=dict(maxCorners=100,qualityLevel=0.3,minDistance=7,blockSize=7)
# 光流跟踪的参数
lk_params=dict(winSize=(15,15),maxLevel=2,criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,10,0.03))
# 生成一些随机颜色
color=np.random.randint(0,255,(100,3))
# 读取第一帧并检测角点
flag,old_frame=video.read()
old_gary=cv2.cvtColor(old_frame,cv2.COLOR_BGR2GRAY)
p0=cv2.goodFeaturesToTrack(old_gary,mask=None,**feature_params)
mask=np.zeros_like(old_frame)
while(True):
flag,frame=video.read()
if flag==False:break
frame_gary=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# 计算光流
p1,st,err=cv2.calcOpticalFlowPyrLK(old_gary,frame_gary,p0,None,**lk_params)
# 选取跟踪成功的点
good_new:np.ndarray=p1[st==1]
good_old=p0[st==1]
# 绘制跟踪线
for i,(new,old) in enumerate(zip(good_new,good_old)):
cv2.line(mask,new.astype(int),old.astype(int),color[i].tolist(),2,16)
cv2.circle(mask,new.astype(int),5,color[i].tolist(),-1)
cv2.imshow('frame',cv2.add(frame,mask))
k=cv2.waitKey(1) & 0xff
if k==27:
break
# 更新上一帧
old_gary=frame_gary.copy()
p0=good_new.reshape(-1,1,2) #将good_new转换为(n,1,2)的数组
#或 p0=p1.reshape(-1,1,2)
video.release()
稠密光流
Lucas-Kanade方法计算稀疏特征集的光流(在我们的示例中,使用Shi-Tomasi算法检测拐角)。OpenCV提供了另一种寻找稠密光流的算法。它计算帧中所有点的光流。它基于Gunner Farneback的算法,Gunner Farneback在2003年的“Two-Frame Motion Estimation Based on Polynomial Expansion 基于多项式展开的两帧运动估计”中解释了该算法。
下面的例子使用上面的算法计算稠密光流。结果是一个带有光流向量(u,v)的双通道数组。通过计算我们能得到光流的大小和方向。我们使用颜色对结果进行编码以便于更好的观察。方向对应于 H(Hue)通道,大小对应 于V(Value)通道。代码如下:
cv2.calcOpticalFlowFarneback(prev, next, pyr_scale, levels, winsize, iterations, poly_n, poly_sigma, flags[)
# pyr_scale – parameter, specifying the image scale (<1) to build pyramids for each image; pyr_scale=0.5 means a classical pyramid, where each next layer is twice smaller than the previous one.
# poly_n – size of the pixel neighborhood used to find polynomial expansion in each pixel; typically poly_n =5 or 7.
# poly_sigma – standard deviation of the Gaussian that is used to smooth derivatives used as a basis for the polynomial expansion; for poly_n=5, you can set poly_sigma=1.1, for poly_n=7, a good value would be poly_sigma=1.5.
# flag(可选) - 0或1,0计算快,1慢但准确import cv2
import numpy as np
cap = cv2.VideoCapture("xm.mp4")
flag, frame1 = cap.read()
prvs = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame1)
hsv[..., 1] = 255
while (1):
flag, frame2 = cap.read()
next = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
flow = cv2.calcOpticalFlowFarneback(prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# cv2.cartToPolar Calculates the magnitude and angle of 2D vectors.
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
hsv[..., 0] = ang * 180 / np.pi / 2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
rgb = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imshow('frame2', rgb)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
elif k == ord('s'):
cv2.imwrite('opticalfb.png', frame2)
cv2.imwrite('opticalhsv.png', rgb)
prvs = next
cap.release()
cv2.destroyAllWindows()
yolov8:
【目标检测】2024最新-用YOLOv8训练自己的数据集(保姆级教学)_yolov8 训练-优快云博客
数据增强:
ultralytics\data\augment.py是数据增强的代码:
YOLOv8数据增强预处理方式详解:包括数据增强的作用,数据增强方式与方法-优快云博客
yolo默认配置文件default.yaml:

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









