






1.输入输出
输入,默认输入格式为str
name=input()
name=input("请输入您的姓名:")
a, b = map(int,input().split(','))#输入一行以‘,’间隔的数赋值给a,b输出
print("hello world")
name="李白"
print("ta is {}".format(name))
print(f"ta is{name}")#Python3.6以上版本
print(1,2,3,sep=",")#默认间隔符为空格,sep设置间隔符
print(name,end='\0')#设置结束符,默认为'\n'
print('{:.3f}'.format(3.1000000))# 精确保留小数点后三位,保留位数不足补0,结果实质上是字符串类型
print('{:e}'.format(3.1415926)) #使用科学计数法输出
print(f'{'hello':10}')#输出10位长度,不足补空格,超过10位输出原数据,或者':010'即补0
print(f'{'hello':a>10}')#输出10位长度,不足'a',右对齐(>:右 / <:左 / ^:居中)
print(f'{100000:,}')#每3位数字加一个“,”
#使用""" """既可以注释多行,也可以用于多行字符串2.数学运算
+-* /--->除 //--->整除 a**b--->a的b次方
a,b=1,1
sign='+'
ans=eval(f'{a}{sign}{b}')# 2round(4.1415926,2)#四舍五入保留2位小数random库
import random
random.seed(0)#设置随机数种子
random.random()#生成0~1的随机数
random.randint(0, maximum) # 随机产生一个0到maximum以内整数
random.randrange(0, 101, 10)# 0、10、20、30 ……
random.uniform(5.5, 10.5)#浮点数
random.choice([1, 2, 3, 4, 5])#随机选一个
elements = ['apple', 'banana', 'cherry']
weights = [10, 5, 1]
selected_elements = random.choices(elements, weights, k=5)#根据权重随机选择 5 个元素
random.shuffle([1, 2, 3, 4, 5])#打乱顺序
random.sample([1,3,5,7,9], 3)#返回其中不重复的3个
random.normalvariate(0, 1)#生成高斯分布(正态分布)随机数,平均值为0,标准差为1
random.gaussian(0, 1)#同上math库
import math
#若用from math import pi --->则不需要再写math.pi直接写pi即可
#若用from math import * --->导入math中的全部函数
a=math.factorial(100)#计算100的阶乘
math.pi#圆周率
math.floor()
math.ceil()
math.sqrt()#开平方
math.factorial(x)#返回x的阶乘, 要求x为非负整数,x为负数或浮点数时返回错误
math.sum()#可以返回n多个数的和
math.fsum()#浮点数求和
math.max()
math.min()#n个数的最大最小值
math.gcd()#n个数的最大公约数
math.lcm()#n个数的最小公倍数
math.comb(n,m)#计算n个项目中选择m个的方式数
math.copysign(x, y)#返回一个具有x的绝对值但带有y的符号的浮点数
math.frexp()#返回科学计数法3.流程控制
range()等差数列
range(n)#一个从0到n-1的等差数列
range(start,stop,step)#从start开始,到stop前结束,步长为step的等差数列list列表
类似于vector,例如.append()、.extend()、.insert()、.remove()和.pop()
可以使用enumerate()获取列表的索引和值,如:
my_list = ['apple', 'banana', 'cherry']
for index, value in enumerate(my_list):
print(f'索引: {index}, 值: {value}')tuple元组
if语句
if True:
pass
elif False:
pass
else:
passfor循环
for i in range(5):
pass
for i in range(1,100,2):
pass
for i in list:
pass
else:#如果for语句正常结束则会运行else,如果break退出则不会运行
pass
'''continue
break
pass --->占位符,相当于一个什么也不执行的语句'''while循环
while 1:
pass
if ...:
break异常处理
try:
pass
except ValueErrer:
pass
except:
pass
else:
pass
finally:
pass
#将可能出现异常的语句放在try中,如果有异常则执行except,无异常执行else
#finally中的语句不管try有没有异常都会执行4.函数
pip install namelambda x, y: x + y#传递任意数量的位置参数
def func(*args):
for arg in args:
print(arg)
func(1, 2, 3, 4) # 输出:1 2 3 4
#传递任意数量的关键字参数
def func(**kwargs):
for key, value in kwargs.items():
print(key, value)
func(a=1, b=2, c=3) # 输出:a 1, b 2, c 3def fun():
return 1,2,3quit()函数可以结束程序
5.字符串
去除字符串首尾字符
txt.strip()可以去除字符串txt的开头结果的空白字符,如换行符'\n'等 如果想去除字符串首尾的其他字符,可以将要去除的字符做为参数放到括号中。
txt = '079李白:蜀道难\n'
print(txt.strip())
txt.strip('0')#去除开头末尾的‘0’字符串切分
txt.split(sep)可以根据参数sep将字符串txt切分为包含多个元素的列表
txt = '079李白:蜀道难\n' # 字符串
print(txt.split(':')) # 根据全角冒号切分为列表,输出 ['079李白', '蜀道难\n']
txt1,txt2= txt.split(':', maxsplit=1)#在切分时可以加maxsplit=1参数,限制最多切分一次查找
txt='abcdefg'
txt.find('abc')#返回下标,未找到返回-1
txt.index('c')#未找到报错
txt.count('abc')#查找txt中‘abc’出现了几次
txt=txt.replace(old,new,count)#替换,最多count次(第三个参数可不填)加密
a=''.maketrans(str1,str2)#产生密码本,将返回将str1转换str2的字典
str3.translate(a)#将str3按a字典转换文件读取
open(name[, mode[, buffering]])'''
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。
这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,
访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。
如果取负值,寄存区的缓冲大小则为系统默认。'''
#例如:
with open(file, 'r' ,encoding='utf-8') as temp:
content=temp.read() #读取全部
with open(file, 'r', encoding='utf-8') as temp:
for line in temp:
l=line#读取行txt.lower()和txt.upper()可以实现大小写转换,txt.title()将单词首字母大写,其他小写
'-'.join(txt) #可以返回txt每个字符之间添加一个“-”的字符串
txt.endswith()或txt.startswith()检测txt末尾或开始是否是指定子串
ord(ch) #返回ch这个字符的ascii码值
chr(ascii)#返回这个ASCII码对应的字符
常用函数:
string.capitalize() 把字符串的第一个字符大写;
string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数;
string.decode(encoding='UTF-8', errors='strict') 用于将 bytes 类型的二进制数据转换为 str 类型,这个过程也称为“解码”;
string.encode(encoding='UTF-8', errors='strict') 用于将 str 类型的数据转换为 byte 二进制数据,这个过程也称为“编码”;
string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1;
string.format() 格式化字符串;
string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False;
string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False;
string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False;
string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False;
string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False;
string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False;
string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False;
string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False;
string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串;
string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串;
string.lower() 转换 string 中所有大写字符为小写;
string.lstrip() 截掉 string 左边的空格;
max(str) 返回字符串 str 中最大的字母;
min(str) 返回字符串 str 中最小的字母;
string.replace(str1, str2, num=string.count(str1)) 返回string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次;
string.rstrip() 删除 string 字符串末尾的空格;
string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串;
string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果 beg 和 end 指定值,则在指定范围内检查;
string.swapcase() 翻转 string 中的大小写;
string.upper() 转换 string 中的小写字母为大写。字符串常量
import string
字符串常量 | 字符集 |
string.ascii_letters | 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' |
string.ascii_lowercase | 'abcdefghijklmnopqrstuvwxyz' |
string.ascii_uppercase | 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' |
string.digits | '0123456789' |
string.hexdigits | '0123456789abcdefABCDEF' |
string.octdigits | '01234567'. |
string.punctuation | '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~' |
string.printable | '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\t\n\r\x0b\x0c' |
| string.whitespace | ' \t\n\v\f\r' (转义字符)' \x09\x0a\x0b\x0c\x0d' (十六进制ASCII值)(从左到右依次为:制表符、换行符、垂直制表符、换页符、回车符) |
jieba中文分词库
1,精确模式:将句子最精确地切开,适合文本分析;
2,全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3,搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词;
import jieba
jieba.setLogLevel(jieba.logging.INFO)#关闭详细log输出
jieba.lcut(s) #精确模式,返回一个列表类型
jieba.lcut(s,cut_all=True) #全模式,返回一个列表类型
jieba.lcut_for_search(s) #搜索引擎模式,返回一个列表类型
jieba.add_word(w) #像分词词库中添加新词wimport jieba.analyse
ls=jieba.analyse.textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False)
#self:待处理的文本
#topK:返回权重前topK的词,重要性从高到低排序
#withWeight:是否同时返回每个关键词的权重,默认false
#allowPOS:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
#返回值为词和权重的元组组成的列表词性标注对应表如下:
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
6.序列类型
元组tuple
值不可修改
t1=tuple(range(5))
t1.count(n)#统计n的数量
t1.index(n)#返回n的索引序列list
- 用list() 函数,将字符串、 range对象、元组、集合等可迭代数据转换为列表
参数是字典时,将字典的键转为列表
当参数为空时生成一个空列表 - 用切片赋值的方法更新列表
新值也为列表
新值元素与切片元素数量可不相同
list2=list1#别名
list2=list1.copy()#浅拷贝,拷贝元素的标签
import copy
list2=copy.deepcopy(list1)#深拷贝list3=list1+list2 #用“+”拼接出一个新序列
list1.extend(list2)#将list2追加在list1后
list1.append(100)#在list1后添加一个元素:100
list1.insert(i,n)#下标为i处添加元素nlist = ['a', 'b', 'c', 'd']
list.index('c')#返回‘c'的索引号,‘c'不在list中n=list.pop(i)#删除下标为i的元素,不填参数时删除最后一个元素,返回值为删除元素的值
list.remove(n)#删除值为n的第一个元素
list.clear()
del list[1:3]#删除下标1~2的元素ls.sort()#升序,原地操作,无返回值
ls.sort(reverse=True)#降序
ls.sort(key=int)#按照
#key=len/str/str.lower
ls.reverse()
ls2=sorted(ls)#其他参数同上
ls2=list(reversed(ls))map()#映射:例如: list2=list(map(int,list))
zip()#将返回几个列表的第n个元素封装成的元组组成的列表
enumerate()#枚举,返回列表每个元素与其下标组成的元组的列表集合set
保存在大括号中的不可变数据(数值,字符串,元组等)
元素不重复,可消除重复元素
元素无固定顺序,不支持索引和切片等序列操作
a_set = set()
city_set = {'吉林', '武汉', '北京'}
f_set = set('cheeseshop')#set() 函数可将可迭代对象转为集合new_city_set = city_set.copy()
set.add(x)
set.remove(x)#删除集合s 中的一个指定元素 x
set.discard(x)#删除s中的元素x,如果s中没有x不报错
x=set.pop()#随机移除一个元素并返回该元素的值
set.clear()
del sets.issubset(t)#s是t的子集
s<=t
s<t
s.issuperset(t)#s是t的超集
s>=t
s>t
s.isdisjoint(t)#相等
s==ts.union(t)
s | t #并集
s.intersection(t)
s & t #交集
s.difference(t)
s – t #差集
s.symmetric_difference(t)
s ^ t #对称差集
s.update(t)
s = s | t
s.intersection_update(t)
s = s & t
s.difference_update(t)
s = s - t
s.symmetric_difference_update(t)
s = s ^ t
字典(映射类型)dict
·字典中不允许重复的键存在,键相同的元素保留最后一个
my_dict = dict(name='张三', age=19, gender='M')
my_dict = dict([('name', '张三'), ('age', 19), ('gender', 'M')])
my_dict = dict(zip(('name', 'age', 'gender'), ('张三', 19, 'M')))
my_dict = {'name': '张三', 'age': 19, 'gender': 'M'}
dict.fromkeys(iterable[, value])#根据键的序列创建包含相同值的字典, iterable 是字典键键序列的值,value字典元素的共用值
'''如'''my_dict = dict.fromkeys(course, 60)#{'Python': 60, 'Java': 60, 'C': 60}
my_dict = {k: v for k, v in zip(name, phone)}#推导式if key in my_dict:#成员测试仅对key有用
value=my_dict[key]
dict.get(k[, default])#字典中存在以“k”为键的元素时,返回对应的值,否则返回值default
dict.keys()#获取字典dict的所有键
dict.values()#获取字典dict的所有值
dict.items()#获取字典dict的所有键值对(元组)my_dict[key]=value
my_dict.update(k1=v1[, k2=v2,…])
dict1.update(dict2)#把另一个字典中的键值对一次性全部加到当前字典中
dict1|=dict2#同上
dict.setdefault(key[, value])#存在键key时,返回key对应的值;
#键key不存在时,在字典中增加key: value 键值对
#值value缺省时,默认设其值为None
dict.pop(key[, default])''' 返回字典中键key 对应的值,并将键为key的键值对删除
若dict中不存在键key时返回预设的default值
若未提供default值,会触发“KeyValue”异常 '''
dict.popitem()'''从字典中移除并返回一个元组形式的(键, 值) 对
键值对会按LIFO(后进先出)顺序被返回'''
del dict[key]
del dict#删除dict对象
dict.clear()#将dict清空7.文件读写
打开文件
f=open(file[, mode='r'[, encoding=None]])
#file:绝对路径'D:\\test\\temp.txt'
# 相对路径:'./data/temp.txt'
# 同目录下的文件:'temp.txt'
#mode:'r'--> read only
# 'w'--> write only 如果没有文件就创建/如果已有文件就覆盖
# 'a'--> appending 如果没有文件就创建/如果已有文件就续写
# 'x'--> creat file 创建文件/若文件已存在,打开失败
# 'r+'/'w+'/'a+' 可读可写
#encoding:中文windows10 一般默认GBK 编码
# Mac 和Linux等一般默认编码为UTF-8 编码
# 纯英文文件,可以省略此参数
for line in f:
print(line.strip())
f.write()
f.close()#忘记关闭文件或程序在执行f.close()语句之前遇到错误,导致文件不能正常关闭
print(f.closed)#False,打开状态 True,关闭状态读写文件
file.seek(offset)#移动文件指针到指定的位置
file.read(size=-1)#读取size个字符,当size<0,读取全部
file.readline(size=-1)#读取一行,如果指定了size ,将在当前行读取最多size 个字符
file.readlines(hint=-1)#可以指定hint 来读取的直到指定字符所在的行file.write(b)
file.writelines(lines)# 将一个元素全为字符串的列表写入文件CSV文件
逗号分隔值,以纯文本形式存储表格数据
由任意数目的记录组成 ,记录间以换行符分隔
每条记录由字段组成,字段间用逗号或制表符分隔
每条记录都有同样的字段序列
如有列名,位于文件第一行
每条记录数据不跨行,无空行
csv库
csv.reader(csvfile, dialect='excel', **fmtparams)'''
csvfile,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象,如果是文件对象,打开时需要指定newline=''(但是实际上不指定似乎也没影响,只有写入时才需要指定,不过官方文档建议,为了安全,还是指定比较好)。
dialect,编码风格,默认为excel的风格,也就是用逗号,分隔,dialect 方式也支持自定义,通过调用register_dialect方法来注册,下文会提到。
delimiter: 默认",",内容分隔符,默认是英文逗号。
quotechar:指定引用使用到的字符,这个参数似乎跟quoting一起使用。
escapechar:转义字符,对于writer,在 quoting 设置为 QUOTE_NONE 的情况下转义delimiter(定界符),在 doublequote 设置为 False 的情况下转义 quotechar。对于reader,去除其后所跟字符的任何特殊含义。
quoting:指定引用方式。该属性可以等于任何 QUOTE_* 常量,
从csv文件读取的每一行数据都会以list的形式返回,这个list的元素都是string。csv库不会自动识别数字,除非指定quoting= QUOTE_NONNUMERIC。'''
#例如:
with open(filename,"r",encoding="utf-8") as f:
reader=csv.reader(f)
ls=list(reader)#可以直接转列表,也可以像下面:
f.seek(0)
header=next(reader)# 获取标题
title1=header[0]
title2=header[1]
title3=header[2]
for row in reader:
# row是一个列表,csv文件中以逗号分割的数据就是列表的每个元素
print("{}:{},{}:{},{}:{}".format(title1,row[0],
title2,row[1],title3,row[2]))
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)'''
和csv.reader一样读取数据,但是会把每行映射到一个dict,dict的键由fieldnames指定。
fieldnames:字典的键,其实就是表格的header,必须是一个Sequence,如果忽略,文件的第一行会被当做header。
restkey:如果header的个数小于data的列数,每行剩余列的data会被放入一个list中,键会被指定为restkey(default None)
restval : 若header的个数大于数据列数,则缺失值都会被填充为restval(default None)。
不管是csv.reader还是csv.DictReader,都有一个__next__()方法,将下一行内容用Dialect解析后,以list或者dict的形式返回。'''
csv.writer(csvfile, dialect='excel', **fmtparams)#delimiter:指定分隔符,默认是英文逗号。
#值得注意的是,在写入时一定要指定newline='',否则写入时每两行之间都会多出一个空行。
csv.DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds)
#fieldnames就是需要传入的列名,这些列名需要作为DictWriter的writerow方法传入的字典的键。
csvwriter.writerow(row)
#将 row 形参(被dialect格式化后)写入到 writer 的文件对象中,一次写入一行。
csvwriter.writerows(rows)
#rows是一个以上述row作为元素的迭代器。一次写入多行。
#例如:
with open(filename,"w",encoding="utf-8",newline="") as f:
# 以写方式打开文件。注意添加 newline="",否则会在两行数据之间都插入一行空白。
headers=["姓名","性别","年龄"]
# 即使打乱键的顺序,写入也不会出错
data=[{"年龄":"20","性别":"男","姓名":"张三"},{"姓名":"王五","性别":"男","年龄":"18"}]
# 将header作为参数传入
writer=csv.DictWriter(f,headers)
writer.writeheader()
# # 方式一
# writer.writerows(data)
# 方式二
for row in data:
writer.writerow(row)
pandas库
- 读文本文件和csv文件进列表,对列表中的数据进行统计分析
- 读取常规分隔符分隔的文本文件到DataFrame使用read_csv()方法
import pandas as pd
data=pd.read_csv(filepath_or_buffer, sep='\t', delimiter=None,
header='infer', names=None,dtype=None, engine=None,
encoding=None)
'''
1. filepath_or_buffer:带路径文件名或URL,字符串类型
2. sep:分隔符,缺省值为'\t',当文本中的分隔符不是制表符时,可用sep=’分隔符’来指定
3. delimiter:参数sep的替代参数,缺省值为None。
4. header:整型或整型列表,用作列名的行号和数据的开头。
5. names:要使用的列名的列表,如果文件不包含标题行,则应显式传递header = None
6. dtype: 设置读取列的数据类型,可以直接传入一个类型,应用于所有行,或一个字典
7. engine:解析器引擎,值为'c'或'python'。c引擎速度更快,Python引擎功能更加完善
8. encoding:默认None,编码在读/写时用UTF(例如'utf-8')
9. index_col:指定某列作为索引。
10. usecols:只读取指定的列。
11.prefix:自动加一个前缀。
12.skiprows:需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
13.na_values:一组用于替换 NA 的值。
14.comment:用于将注释信息从行尾拆分出去的字符。
'''
column=data.columns.tolist()
datals=data.values.tolist()
frame = pandas.DataFrame(data)#将字典data转换为DataFrame格式
frame.to_csv(path_or_buf=None, sep=',', na_rep='', index=False, header=True,moode='w')'''
path_or_buf:写入CSV文件的路径或文件对象。
sep:列分隔符,默认为逗号。
na_rep:缺失值的表示,默认为空字符串。
index:是否写入行索引,默认为 False。
header:是否写入列名,默认为 True。'''import pandas as pd # 导入pandas库起别名为pd
score = pd.read_csv('8.2 score.csv') # 读文件中的数据dataframe对象中
scoreSum = [sum(x[1:]) for x in score.values.tolist()] # 计算总分
print(scoreSum) # 查看计算的总分
score['总分'] = scoreSum # 在数据最后加上score一列
score = score.sort_values(by=['总分'], ascending=False) # 总分降序排序
score.to_csv('8.2 scoreSum.csv', index=False) # 写回到文件,JSON文件(json库)
JSON 是一种跨语言的轻量级通用数据交换格式
JSON是文本格式,键必须用双引号,字符串类型
import json
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)#返回json格式的数据
json.dump(obj,fp, ensure_ascii=True, indent=None,sort_keys=False)#写入json文件
# dump(obj, fp) 将“obj”转换为JSON 格式的字符串,将字符串写入到文件对象fp 中
# dumps()返回json格式的数据
# ensure_ascii: True会将中文等非ASCII字符转为unicode编码,设置=False 可以保持中文原样输出
# indent: 可用来对JSON数据格式化输出,可设一个大于0 的整数表示缩进量,可读性更好
#sort_keys:True使转换结果按照字典升序排序json.loads(s)#返回字典,s为数据
json.load(fp)#返回字典,fp为文件Excel文件(pandas库)
- 读取Excel文件中的数据为Dataframe类型
- 应用read_excel()方法
- 先用“pip install xlrd”安装xlrd模块
import pandas as pd
data=pd.read_excel(io, sheet_name=0, header=0, names=None,
usecols=None, squeeze=False, converters=None,
skiprows=None, nrows=None, skipfooter=0)
'''
1. io: Excel的存储路径和文件名
2. sheet_name:要读取的工作表名称,默认读取第一个工作表
3. header:用哪一行作列名,默认为0
4. names:自定义最终的列名,names的长度必须和Excel列长度一致
5. index_col:用作索引的列
6. usecols:需要读取哪些列。可以用整型 [0,2,3];列名如“A:C, E” = “A, B, C, E”,
7. squeeze:当数据仅包含一列且squeeze为True时,返回Series,反之返回DataFrame。
8. converters:强制规定列数据类型,主要用途是保留以文本形式存储的数字。
pandas默认将文本类的数据读取为整型,converters 参数可以指定各列数据的类型,如converters = {'出货量':float, '月份':str }, 将“出货量”列数据类型规定为浮点数,“月份”列规定为字符串类型。
9. skiprows:跳过特定行。skiprows= n 跳过前n行; skiprows = [a, b, c] 跳过第a+1,b+1,c+1行
10. nrows:需要读取的行数,nrows = n 读取前n行。
11. skipfooter: 跳过末尾行数,skipfooter = n 跳过末尾的n行
'''
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)'''
excel_writer:文件路径或现有的ExcelWriter。如果我们创建的ExcelWriter对象的文件名已经存在,会删除原文件,创建新的文件。
sheet_name:指包含DataFrame的工作表的名称。
na_repr:缺少数据时候的表示形式。
float_format:可选参数, 用于格式化浮点数字符串。
columns:要写入的列。
header:写出列名。如果给出了字符串列表, 则假定它是列名的别名。不需要列名时参数设置为false即可。
index:写入索引。
index_label:引用索引列的列标签。如果未指定, 并且标头和索引为True, 则使用索引名称。如果DataFrame使用MultiIndex, 则应给出一个序列。
startrow:默认值0。它指向转储DataFrame的左上单元格行。
startcol:默认值0。它指向转储DataFrame的左上方单元格列。
engine:可选参数, 用于写入要使用的引擎, openpyxl或xlsxwriter。
merge_cells:返回布尔值, 其默认值为True。它将MultiIndex和Hierarchical行写为合并的单元格。
encoding:可选参数, 可对生成的excel文件进行编码。仅对于xlwt是必需的。
inf_rep:可选参数, 默认值为inf。通常表示无穷大。
verbose:返回一个布尔值。它的默认值为True,用于在错误日志中显示更多信息。
frozen_panes:可选参数, 用于指定要冻结的最底部一行和最右边一列。'''文件与文件夹的操作(os库)
import os
import os
result = os.getcwd()#返回当前程序工作目录的绝对路径
print(result)os.chdir('D:\\testpath\\path')os.listdir(path)#获取指定文件夹中所有文件和文件夹的名称列表,path默认为当前文件夹os.mkdir() #创建文件夹
os.makedirs() #创建嵌套的一系列文件夹os.rmdir() #删除空目录
os.removedirs() #删除嵌套的一系列空目录os.rename(oldname, newname) #文件更名
os.remove(filename) #删除文件
os.path.exists(filename) #检测存在性os.system(command)#执行程序或命令command,在Windows系统中,返回值为cmd的调用返回信息
直接打印出命令行的返回值8.NumPy科学计算库
ndarry对象
- NumPy中最重要的一个特点就是其N维数组对象,即ndarray(别名array)对象,该对象具有矢量算术能力和复杂的广播能力,可以执行一些科学计算。不同于Python内置的数组类型,ndarray对象拥有对高维数组的处理能力,这也是数值计算中缺一不可的重要特性。
|
|
|
|
|
|
|
|
|
|
|
|
创建数组
import numpy as np
arr3d = np.array([
[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]
[,dtype='int32'])np.zeros((3, 3))#创建元素值都是0的3*3数组
np.ones((3, 3))# 创建元素值都为1的数组
np.full((3, 3),fill_value=255,dtype=np.uint8)# 创建元素值都为255的数组
np.empty((3, 3))#该数组只分配了内存空间,它里面填充的元素都是随机的。
np.arange(1, 20, 5)#range
np.mat('0 1 2;1 0 3;4 -3 8')#创建矩阵
np.random.rand(3,3)#3*3的随机数数组
np.linspace(start,stop[,num=50[,endpoint=True]])
#产生从start到stop一共50个元素的等差数列,endpoint为True时包括stop这个数数据类型
arr_one.dtype.name#默认情况下zeros()、ones()、empty()函数创建的数组中元素的数据类型为float64data = np.array([[1, 2, 3], [4, 5, 6]])
float_data = data.astype(np.float32)
float_data.dtype.name索引
在同列表索引的基础上,还有以下索引方式:
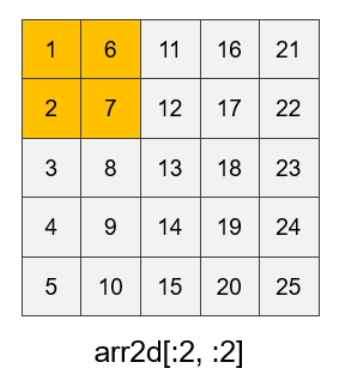
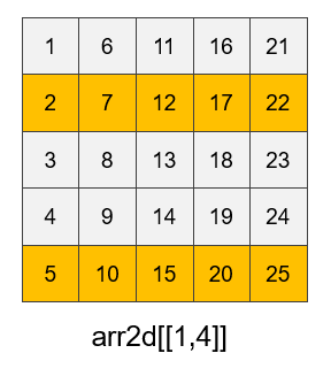
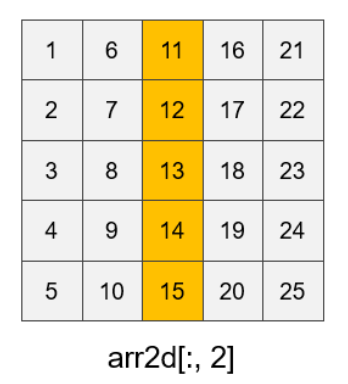
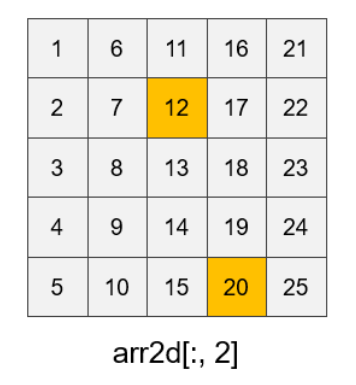
arr2d[[1,4], [2, 3]]
5.
arr = np.array([10, 6, 5, 11, 18, 16, 9, 0, 3, 20])
print(arr[[0, 1, 5]] )
6.布尔索引
返回布尔数组或布尔列表中与True位置对应的元素。
(布尔数组或布尔列表的长度必须与被索引轴的长度一致。)
算术运算
矩阵运算
广播机制
数组的重塑
array_1d = np.arange(1, 13)
print('原数组的形状:' +
str(array_1d.shape))
array_2d =
array_1d.reshape((6,2))
print('新数组的形状:' + str(array_2d.shape))- arr.T 转置
- transpose方法:
如果希望对两个以上的轴上的元素进行转置,则可以通过transpose()方法实现。transpose()方法需要接收一个由轴编号构成的元组,返回一个按轴编号互换后的新数组。
arr = np.arange(24).reshape(
(2, 3, 4))
arr.transpose((0, 1, 2)) 其他
条件逻辑
条件逻辑在NumPy中,where() 函数相当于三元表达式x if condition else y的矢量化版本,用于根据条件返回x或者y中的元素,如果满足条件返回x 中的元素,不满足条件返回y 中的元素。
arr_x = np.array([1, 5, 7])
arr_y = np.array([2, 6, 8])
arr_con = np.array([True, False, True])
result = np.where(arr_con, arr_x, arr_y)统计运算(np.)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
排序
array.sort(axis=-1,kind='quicksort',order)#直接操作数组
numpy.sort(a, axis=-1, kind='quicksort', order)#返回排序后的数组
# axis: 沿着它排序数组的轴。如果没有指定,数组会被展开,然后沿着最后的轴排序。默认值为 -1,表示沿着最后一个轴排序。
# kind: 排序算法,默认为 'quicksort'(快速排序)。
# order: 如果数组包含字段,则是要排序的字段。此外,还有其他排序相关的函数,例如:
- numpy.argsort(): 返回数组值从小到大的索引值。
- numpy.lexsort(): 用于对多个序列进行排序,类似于对电子表格进行排序,每一列代表一个序列。
检索数组元素是否满足条件
在NumPy中,all()函数用于判断整个数组中的元素的值是否全部满足条件,如果满足条件返回True,否则返回False。any()函数用于判断整个数组中的元素至少有一个满足条件就返回True,否则就返回False。
arr = np.array([[1, -2, -7], [-3, 6, 2], [-4, 3, 2]])
np.any(arr > 0)
np.all(arr > 0) 查找数组的唯一元素
np.unique()函数用于找出一维数组中的唯一值,并返回一个升序排列的数组。
arr = np.array([12, 11, 34, 23, 12, 8, 11])
arr=np.unique(arr) 判断元素是否在其他数组中
in1d()用于判断一维数组中的元素是否在另一个数组中,返回一个布尔数组,与一维数组的长度相等。
np.in1d(ar1, ar2, assume_unique=False, invert=False)
#ar1:待判断的数组。
#ar2:判断ar1的每个元素所依据的值。
#assume_unique:是否假设数组ar1的唯一性,默认值是False。
#invert:是否倒转数组的元素,默认值为False。 线性代数
+-*/作用与数组时,是两个数组对元素的运算
| 函数(np.) | 说明 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
随机数模块
np.random.rand(3, 3,3) 生成3*3*3、元素都是随机数的数组
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.pandas数据分析库
数据结构
ser_obj = pd.Series(data[,index[,dtype]])
# data:表示数据,它的值可以是ndarray对象、列表、字典、标量等。
# index:表示索引,它的值必须是可散列的,且与数据的长度相同。如果没有给index参数传值,则默认会使用RangeIndex 类的对象;如果data参数的值是字典且index参数的值为None,则字典的键会用做索引。
# dtype:表示数据的类型,它的值可以是numpy.dtype。
'series的属性:'
ser_obj.values#返回 Series 中的值,类型为 ndarray。
ser_obj.index#返回 Series 中的索引,类型为 Index。
ser_obj.dtype#返回 Series 中元素的数据类型。
ser_obj.name#返回 Series 的名称。
ser_obj.ndim#返回 Series 的维度,固定为 1。
ser_obj.shape#返回 Series 中数据的形状,固定为 (n,),其中 n 表示 Series 的长度。
ser_obj.size#返回 Series 中元素的数量,等同于 len(series)。
ser_obj.empty#返回一个布尔值,表示 Series 是否为空。
ser_obj.axes#返回一个包含 Series 索引和数据轴标签的列表。
ser_obj.values_counts()#返回一个包含 Series 中唯一值及其出现次数的 Series。
ser_obj.astype(dtype)#将 Series 中的数据类型转换为指定的类型。
ser_obj.isnull()#返回一个布尔型的 Series,表示 Series 中的缺失值。
ser_obj.notnull()#返回一个布尔型的 Series,表示 Series 中的非缺失值。df_obj = pd.DataFrame(data=None, index=None, columns=None,dtype=None, copy=None)
# data:表示数据,该参数可以接收ndarray对象、列表、字典或其他DataFrame类的对象。
# index:表示行索引。如果没有传入该参数,则默认会自动生成0~N的整数。
# columns:表示列索引。如果没有传入索引参数,则默认会自动生成0~N的整数。
result = df_obj.No2#No2是一个columns号,返回series对象
'dataframe的属性:'
df_obj.info()#查看详细信息
df_obj.info()#返回 DataFrame 对象的简要摘要,包括行列数量、数据类型、缺失值情况等。
df_obj.values#返回 DataFrame 中的值,类型为 ndarray。
df_obj.index#返回 DataFrame 中的索引,类型为 Index。
df_obj.columns#返回 DataFrame 中的列名,类型为 Index。
df_obj.dtypes#返回 DataFrame 中每一列的数据类型,类型为 Series。
df_obj.shape#返回 DataFrame 中数据的形状,类型为 tuple。
df_obj.size#返回 DataFrame 中元素的数量,等同于 shape[0] x shape[1]。
df_obj.empty#返回一个布尔值,表示 DataFrame 是否为空。
df_obj.axes#返回一个包含行和列轴标签的列表。
df_obj.ndim#返回 DataFrame 的维度,固定为 2。
df_obj.describe()#返回 DataFrame 中数值型数据的统计信息。
df_obj.head(n)#返回 DataFrame 的前 n 行。
df_obj.tail(n)#返回 DataFrame 的后 n 行。
df_obj.T#返回 DataFrame 的转置矩阵,即行列互换。
df_obj.sort_index(axis, ascending)#按轴排序。
df_obj.sort_values(by, axis, ascending)#按值排序。
df_obj.loc[]#通过标签选择行或列。
df_obj.iloc[]#通过位置选择行或列。
df_obj.dropna()#删除缺失值。
df_obj.fillna(value)#填充缺失值。
df_obj.astype(dtype)#将 DataFrame 中的数据类型转换为指定的类型。
df_obj.isnull()#返回一个布尔型的 DataFrame,表示 DataFrame 中的缺失值。
df_obj.notnull()#返回一个布尔型的 DataFrame,表示 DataFrame 中的非缺失值。索引对象
- index的子类:
在pandas中,无论是位置索引还是标签索引,它们都属于Index类的对象,也就是索引对象。Index类是一个基类,它派生了很多子类,每个子类代表不同形式的索引。

- 不可变性——索引对象一旦创建是不可以被修改的
- 可重复性——索引对象的值是可以重复的。
ser_index.is_unique- 重置索引
reindex()方法会对Series类或DataFrame类对象的原索引和新索引进行匹配,如果新索引跟原索引的值相同,则新索引对应的数据会被设置为原数据;如果新索引跟原索引的值不同,则新索引对应的空缺位置会被填充为NaN或指定的其他值。
reindex(labels=None, index=None, columns=None, axis=None,
method=None, copy=True, level=None, fill_value=nan,
limit=None, tolerance=None)'''
index, columns :表示新的行索引、列索引。
method:表示空缺位置的填充方式,包括'None'(默认值)、'ffill'或'pad'、'bfill或backfill'、'nearest'这几个值,
其中'None'代表不填充空缺位置;'ffill'或'pad'代表前向填充空缺位置;'bfill或backfill'代表后向填充空缺位置;'nearest'代表根据最近的值填充空缺位置。
copy:是否返回新的对象,默认值为True。
fill_value:表示空缺位置被填充的值,默认值为NaN。
limit:表示前向或者后向填充时的最大填充量。'''import pandas as pd
df_obj = pd.DataFrame({'no1': [1.0, 2.0, 3.0],
'no2': [4.0, 5.0, 6.0]},
index=['a', 'b', 'c'])
new_df = df_obj.reindex(index=['a', 'c', 'e'],fill_value=6)- 通过索引或切片获取数据
- 可以通过单个索引获取单行/列数据,也可以通过切片/列表获取多行/列数据
- 通过逻辑运算,为True时则包含(如ser_obj[ser_obj > 20])
- 使用.loc[标签索引]、.iloc[位置索引]
与numpy类似
读写数据
to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, ..., storage_options=None)'''
path_or_buf:表示文件路径,文件路径可以是绝对路径和相对路径。如果该参数的值是一个文件的名称,则该文件会被保存到当前路径。
sep:表示文件使用的字段分隔符,默认值是','。分隔符的长度必须为1。
na_rep:表示缺失数据的表示方式,默认值是空字符串。
columns:表示向文件中写入哪几列的数据。
header:表示文件显示的列标题。
index:表示是否向文件中写入行索引,默认值为True。'''read_csv(filepath_or_buffer, sep=NoDefault.no_default, delimiter=None, header='infer', ..., storage_options=None)'''
读取成功后会根据数据形式转换成一个Series或DataFrame类的对象。
filepath_or_buffer:表示文件的路径。
sep:表示文件使用的分隔符。如果没有指定分隔符,则会尝试使用逗号进行分隔。
header:指定文件中的哪一行作为列索引以及数据的开头。
names:表示要使用的列名称的列表。
encoding:表示读取文件时使用的编码格式。'''
read_table()#读txt,默认以/t为分隔符head()方法用于预览前N行数据,默认是前5行数据;tail()方法用于预览后N行数据,默认是后5行数据。
- excel:
to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, ..., storage_options=None)'''
excel_writer:表示写入文件的路径。
sheet_name:表示工作表的名称,可以接收字符串,默认值为“Sheet1”。
na_rep:表示缺失数据的表现形式。
index:表示是否向文件中写入行索引,默认为True。'''read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, ..., storage_options=None)'''
根据数据的形式转换成Series或DataFrame类的对象。
io:表示文件的路径。
sheet_name:指定要读取的工作表的名称,默认值为0,说明读取第一个工作表。
header:指定文件中的哪一行数据作为DataFrame类对象的列索引。
names:表示要使用的列名称。
index_col:指定文件中的哪一列数据作为DataFrame的行索引。
usecols:指定读取哪几列的数据,默认值为None,说明会读取所有列的数据。该参数可以接收一个列表,列表中的元素分别对应列的编号,编号从0开始。'''- HTML:
read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, ..., displayed_only=True)
#读取成功后会返回一个列表,该列表中包含对应网页表格的DataFrame类的对象。
"io:表示HTML网页的字符串、路径对象或类似文件的对象。若参数io的值是字符串,则字符串的内容可以是URL,也可以是HTML。
"match:表示返回包含与正则表达式或字符串匹配的文本的一组表格,默认值为'.+',说明匹配任何非空字符串。
"header:用于指定列标题所在的行。
"index_col:用于指定行标题所在的列。
- 数据库:

read_sql(sql, con, index_col=None, coerce_float=True, params=None,
parse_dates=None, columns=None, chunksize=None)'''
sql:表示被执行的SQL语句。
con:接收数据库连接,表示数据库的连接信息。
index_col:表示将数据表中的列标题作为DataFrame类对象的行索引。
coerce_float:将非字符串、非数字对象的值转换为浮点型数据。
params:传递给执行方法的参数列表,如params = {‘name’:’value’}。'''to_sql(name,con,schema = None,if_exists ='fail',index = True,
index_label = None,chunksize = None,dtype = None)'''
name:表示数据表的名称。
con:表示数据库的连接信息。该参数的值可以是Engine类或Connection类的对象。若希望创建一个Engine类的对象,则需要通过create_engine()函数实现,该函数需要接收一个符合格式要求的字符串,具体格式为“数据库类型+数据库驱动名称://用户名:密码@机器地址:端口号/数据库名”。
if_exists:当数据表存在时如何操作数据表,该参数可以取值为fail、replace或append,默认值为fail。其中fail表示不执行写入操作;replace表示将原数据表删除后再重新创建;append表示在原数据表的基础上追加数据。
index:表示是否将DataFrame的行索引作为数据传入数据库,默认为True。
index_label:表示是否引用索引名称。如果index设为True,此参数为None,表示使用默认名称;如果index为分层索引,则它的值必须是序列类型的。'''数据排序
1.根据行索引或列索引的大小对Series类和DataFrame类的对象进行排序。
sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort',
na_position='last', sort_remaining=True, ignore_index=False, key=None)'''
axis:表示沿着哪个方向的轴排序,该参数的取值可以是0或'index'、 1或'columns',其中0或'index'表示按行方向排序,1或'columns'表示按列方向排序。
ascending:表示是否升序排列,默认值为True。
kind:表示排序算法,可以取值为‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’,其中‘quicksort’表示快速排序算法,‘mergesort’表示归并排序算法,‘heapsort’表示堆排序算法,‘stable’表示稳定排序算法。
inplace:默认False,否则排序之后的数据直接替换原来的数据框
na_position:缺失值默认排在最后{"first","last"},参数“ first”将NaN放在开头,“ last”将NaN放在结尾。2.按值排序的方法sort_values()
sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last',
ignore_index=False, key=None)'''
by:表示排序的列。
na_position:表示NaN值的位置,它只有first和last两种取值,默认值为last。若设为first,则会将NaN值放在开头;若设为False,则会将NaN值放在最后。统计运算
- 对应相加
obj_one + obj_two #直接加,对应位置值相加,没有对齐的地方用NaN补齐
obj_one.add(obj_two, fill_value=0) #对应位置相加,用fill_value补齐- 统计

- 一次性描述Series类或DataFrame类对象的多个统计指标,比如平均值、最大值、最小值、求和等,则可以调用describe()方法实现,而不用逐个调用各个统计计算方法计算。
describe(percentiles=None, include=None, exclude=None)'''
percentiles:表示结果包含的百分数,位于[0,1]之间。若不设置该参数,则默认为[0.25,0.5,0.75],即展示25%、50%、75%分位数。
include:表示结果中包含数据类型的白名单,默认为None。
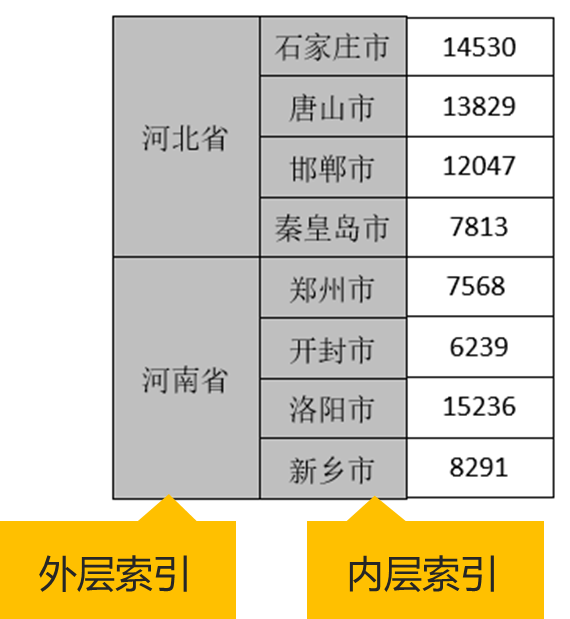
exclude:表示结果中忽略数据类型的黑名单,默认为None。分层索引操作
- 创建:
from pandas import MultiIndex
list_tuples = [('A','A1'), ('A','A2'), ('B','B1'),
('B','B2'), ('B','B3')]
multi_index = MultiIndex.from_tuples(tuples=list_tuples,
names=['外层索引', '内层索引'])from pandas import MultiIndex
multi_array = MultiIndex.from_arrays(arrays =
[['A', 'B', 'A', 'B', 'B'],
['A1', 'A2', 'B1', 'B2', 'B3']],
names=['外层索引','内层索引'])from pandas import MultiIndex
import pandas as pd
numbers = [0, 1, 2]
colors = ['green', 'purple']
multi_product = pd.MultiIndex.from_product(
iterables=[numbers, colors], names=['number', 'color'])- 使用方法
ser_obj['小说', '平凡的世界']
ser_obj[:, '自在独行']
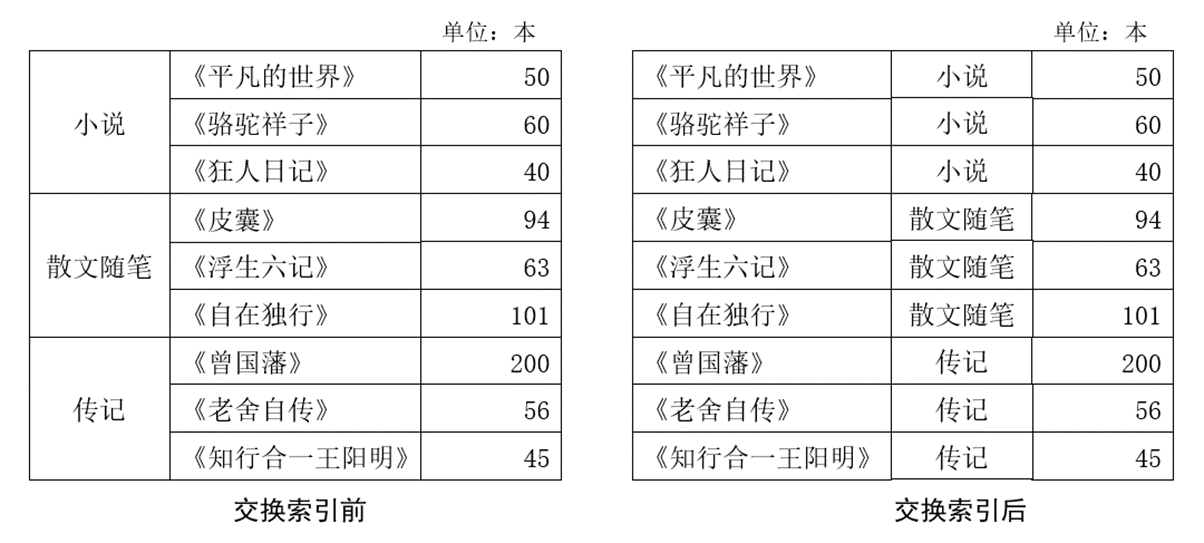
- 交换层级索引:
ser_obj.swaplevel()
数据预处理
数据聚合与分组计算
时间序列分析
10.数据可视化
Matplotlib
plt.figure()#创建一个新的图像
plt.subplot(nrows, ncols, index, **kwargs)#分割成子图,以下是n行n列第index个图
plt.subplots()
plt.title('北京未来15天的最高气温和最低气温')
plt.xlabel('日期')
plt.ylabel('气温/摄氏度')
plt.xlim()#设置坐标轴范围
plt.legend()#添加图例
plt.axhline([50,100,150,200]) #添加4个水平线
plt.axvline(0, linestyle='--', linewidth=1)#添加竖直线
plt.grid(visible=True, linewidth=0.5)#添加网格线
plt.savefig('filename.png')#将图表保存为文件,放在show前
plt.show()
plt.rcParams["font.sans-serif"]=['SimHei']#设置字体以显示中文
plt.rcParams['axes.unicode_minus'] = False#解决-号显示为□的问题折线图
import numpy as np
# 1.导入pyplot模块
import matplotlib.pyplot as plt
# 2.绘制线条
x = np.arange(1, 16)
y_max = np.array([32, 33, 34, 34,
33, 31, 30, 29, 30, 29, 26, 23,
21, 25, 31])
plt.plot(x, y_max)
plt.plot(x,np.random.randint(1,32,15))
# 3.展示图表
plt.show()plt.plot(x, y) # 绘制一条线(x=y)
plt.plot(x1, y1, x2, y2)# 可传入多组xy,也可以为二维的(多组数据)
plt.plot(x, y, "ob:") # "b"为蓝色,"o"为圆点,":"为点线,具体如下:
'''点形状marker=['.',',','o','v','^','<','>','1','2','3','4','s','p','*','h','H','+','x','D','d','|','_','.',',']
线颜色color=['b','g','r','c','m','y','k','w']
线型linestyle=['-','--','-.',':']'''
plt.plot(y, color="blue", linewidth=20, marker="o", markersize=50,
markerfacecolor="red", markeredgewidth=6, markeredgecolor="grey")
#几个参数简称:lw/ms/mfc/mew/mec
#color:可以是英文名称或16进制如:‘#FF0000’
#markersize/markerfacecolor/markeredgewidth/markeredgecolor:数据点的大小/颜色/边框大小/边框颜色柱状图
import numpy as np
import matplotlib.pyplot as plt
# 1. 导入pyplot模块
# 2. 绘制柱形
x = np.arange(1, 6)
y_a = np.array([15970, 18770, 22020, 26890, 31150])
y_b = np.array([8470, 12150, 15650, 21310, 26120])
# 设置柱形的宽度
bar_width = 0.3
# 创建柱形图
rect_a = plt.bar(x, y_a, width=bar_width, tick_label=["FY2018", "FY2019", "FY2020", "FY2021", "FY2022"])
rect_b = plt.bar(x + bar_width, y_b, width=bar_width)#可设置bottle参数确定柱的底点
# 添加注释文本
def autolabel(rects):
for rect in rects:
rect_height = rect.get_height()
rect_x = rect.get_x()
rect_width = rect.get_width()
plt.text(rect_x + rect_width / 2, rect_height + 30, s='{}'.format(rect_height),
ha='center', va='bottom', fontsize=9)
autolabel(rect_a)
autolabel(rect_b)
# 添加图例
plt.legend([rect_a, rect_b], ['品牌A', '品牌B'])
# 显示图形
plt.show()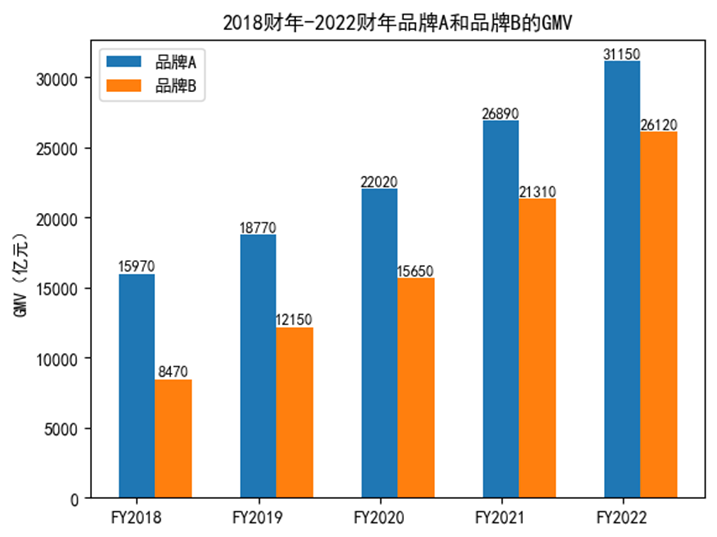
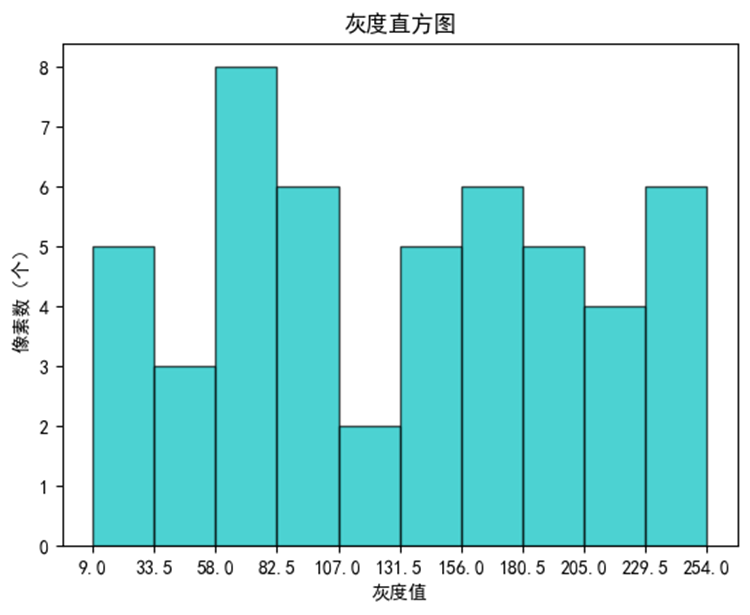
直方图
...
# 2.绘制矩形
np.random.seed(0)
arr_random = np.random.randint(0,
256, 50)
nums, bins, patches = plt.hist(arr_random, bins=10, color='c', edgecolor='k', alpha=0.7)
# 3.完善图表
plt.xlabel('灰度值')
plt.ylabel('像素数(个)')
plt.title('灰度直方图')
plt.xticks(bins, bins)
# 4.展示图表
plt.show()
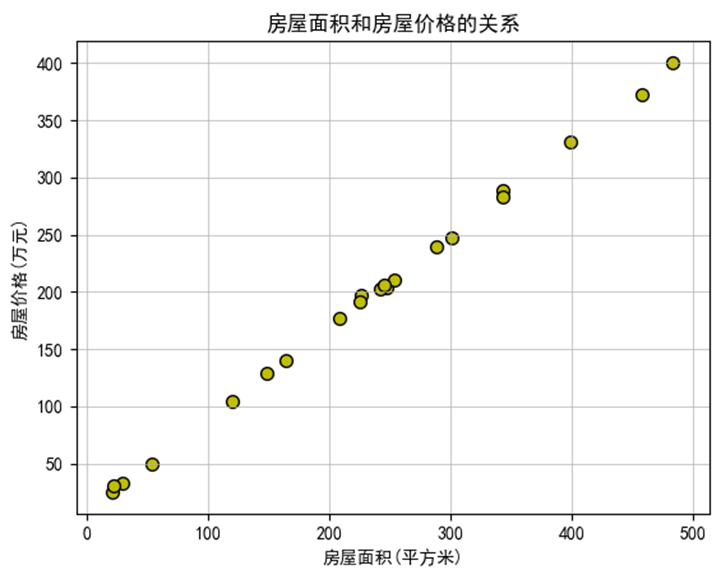
散点图
import numpy as np
# 1.导入pyplot模块
import matplotlib. pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
# 2.绘制点
house_area = np.array([225.98,...])
house_price = np.array([196.63, ...])
plt.scatter(house_area, house_price, s=50, c='y', edgecolors='k')
# 3.完善图表
plt.title('房屋面积和房屋价格的关系')
plt.xlabel('房屋面积(平方米)')
plt.ylabel('房屋价格(万元)')
plt.grid(visible=True, linewidth=0.5)#添加网格线
plt.xlim(house_area.min()-30, house_area.max()+30) #设置x轴范围
# 4.展示图表
plt.show()
饼图
import matplotlib.pyplot as plt
import numpy as np
sales = np.random.randint(10000,100000,10)
labels = [str(m) + '月' for m in range(1,11)]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.figure(figsize=(5,3)) # 设置画布大小
# 设置饼状图颜色
colors = ['yellow', 'red', 'pink' , 'gold' , 'slateblue' , 'green' , 'magenta' , 'cyan' , 'darkorange' , 'lawngreen']
plt.pie(sales, # 绘图数据
labels=labels, # 添加区域水平标签
colors=colors, # 设置饼图的自定义填充色
labeldistance=1.1, # 设置各扇形标签与圆心的距离
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
startangle=90, # 设置饼图的初始角度
radius=0.5, # 设置饼图的半径
center=(0.2,0.2), # 设置饼图的原点
textprops={'fontsize':8,'color':'k'}, # 设置文本标签的属性值
explode=(0.1,0.1,0.1,0,0,0,0,0,0,0),#分裂饼状图是将主要的饼块分裂出来
pctdistance=0.6) # 设置百分比标签与圆心的距离
# 设置x,y轴刻度一致,保证饼形图为原型
plt.axis('equal')
plt.title('2023年1到10月份销量占比 情况分析')
plt.show()
'''pie参数说明
x:每一块饼状图的比例,如果sum(x)>1会使用sum(x)进行归一化。
labels:每一块饼状图外侧显示的说明文字。
explode:每一块饼状图离中心的距离。
startangle:起始绘制角度,默认是从x轴正方向逆时针画起,如设置值为90,则从y轴正方向画起。
shadow:在饼图下面画一个阴影,默认值为False,即不画阴影。
labeldistance:标记的绘制位置,相对于半径的比例,默认值为1.1,如<1,则绘制在饼图内侧。
autopct:设置饼图百分比,可以使用格式化字符串或format函数。如"%1.1f"保留小数点的后一位。
pctdistance:类似于labeldistance参数,指定百分比的位置刻度,默认值为0.6。
radius:饼图半径,默认值为1。
counterclock:指定指针方向,布尔型,可选参数,默认值为True,表示逆时针;如果值为False,则表示顺时针。
wedgeprops:字典类型,可选参数,默认值为None。字典传递给wedge对象用来画一个饼图。例如wedgeprops={'linewidth':2}设置wedge线宽为2.
textprops:设置标签和比例文字的格式,字典类型,可选参数,默认值为None。传递给text对象的字典参数。
center:浮点类型的列表,可选参数,默认值为(0,0),表示图表中心位置。
frame:布尔型,可选参数,默认值为False,不显示轴框架(也就是网格);如果值为True,则显示轴框架,与grid函数配合使用。在实际应用中建议使用默认设置,因为显示轴框架会干扰饼状图效果。
rotatelabels:布尔型,可选参数,默认值为False;如果值为True,则旋转到每个标签到指定的角度。'''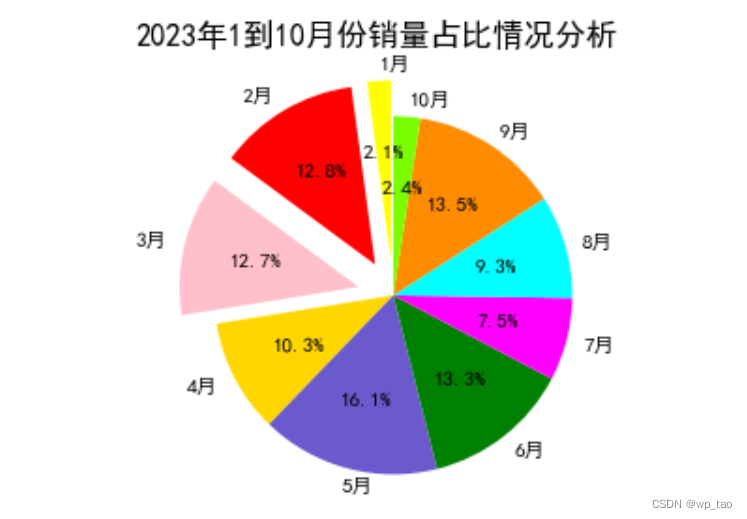
plt.pie()#饼图
plt.boxplot()#箱型图
plt.imshow();plt.pcolor()#热力图
plt.scatter3D();Axes3D.plot()#3D图Seaborn
import seaborn as sns
import matplotlib.pyplot as plt
#下载并打开数据集:
tips=sns.load_dataset('tips',cache=True,data_home=r"D:\Microsoft VS Code\seabornData")
#or:
data=pd.read_csv(r"C:\Users\29513\Downloads\tips.csv")
tips=pd.DataFrame(data)
#绘图:
sns.displot(tips['total_bill'],bins=10)
#or:
sns.jointplot(x='total_bill', y='tip', data=tips)
#or:
sns.stripplot(x="day", y="total_bill", data=tips)
plt.show()seaborn.load_dataset(name, cache=True, data_home=None, **kws)
#缓存文件所在文件夹:data_home,文件名:name(不含扩展名.csv),返回pandas.DataFrame类型
#是否从网络下载数据集。布尔值。可选参数。当取值为True时,首选从本地缓存加载数据,如果下载数据会将数据缓存在本地。可视化数据的分布
单变量数据的分布
sns.displot(tips['total_bill'], bins=10,ked=False)
#以total_bill为横坐标,出现次数为纵坐标,宽度为bins,密度曲线为falsesns.displot(tips['total_bill'], kind='kde')sns.displot(tips['total_bill'], kind='kde', rug=True)双变量数据的分布
sns.jointplot(x='total_bill', y='tip', data=tips)sns.jointplot(x='total_bill', y='tip', data=tips, kind="hex")sns.jointplot(x ='total_bill', y='tip', data=tips, kind='kde', fill=True)用分类数据绘图
sns.stripplot(x="day", y="total_bill", data=tips)#数据点会重叠
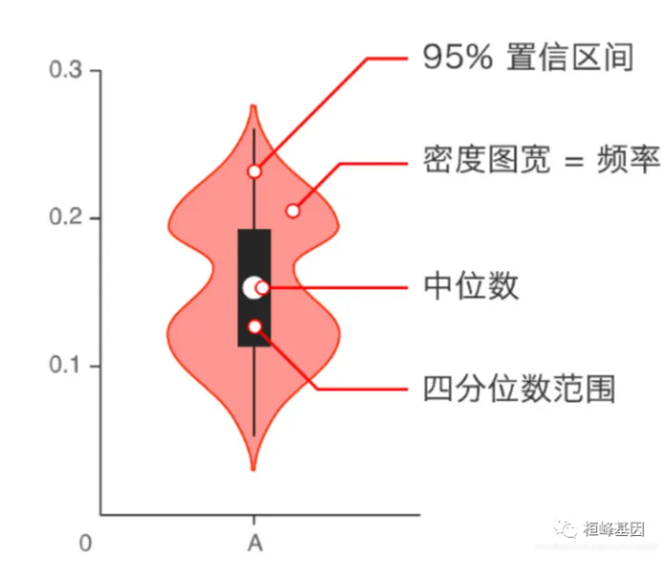
sns.swarmplot(x="day", y="total_bill", data=tips)#数据点不会重叠sns.boxplot(x="day", y="total_bill", data=tips)sns.violinplot(x="day", y="total_bill", data=tips)小提琴图是箱式图与核密度图的结合,它与箱型图相比,能够展示更多的信息。小提琴图不仅能显示一组数据的中位数、上四分位数、下四分位数等信息,还能显示数据在不同数值下的概率密度,这对分析数据而言是非常有利的。
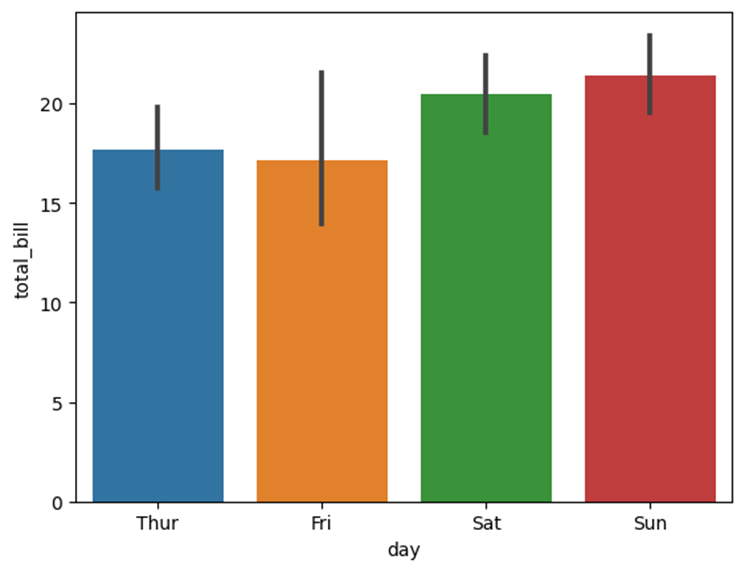
sns.barplot(x="day", y="total_bill", data=tips)使用barplot()函数绘制柱形图。默认情况下,柱形图中每个柱形的上方会显示误差线,这些误差线可以提供关于数据的不确定性或变化的信息。
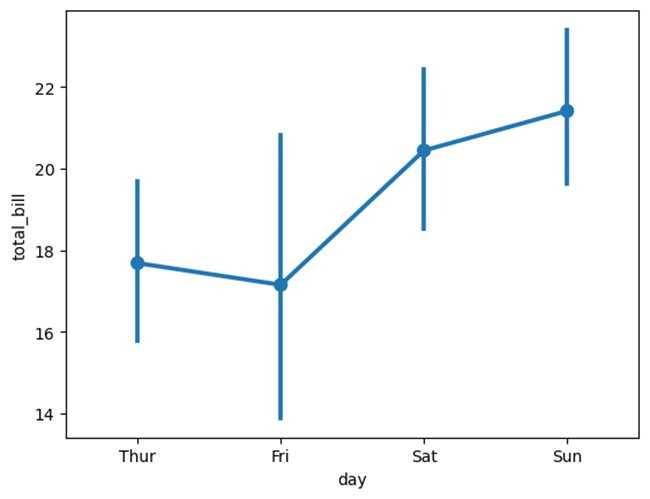
sns.pointplot(x="day", y="total_bill", data=tips)使用pointplot()函数绘制点图,点图中没有显示完整的图形,而是显示点和误差线,其中点代表平均值或其他估计值,误差线代表代表置信区间。
Pyecharts
pyecharts - A Python Echarts Plotting Library built with love.
- 在不了解JavaScript语言的前提下,通过自身封装的一些方法绘制基于JavaScript实现的Echarts图表
创建图表对象
Bar(init_opts=opts.InitOpts())
#init_opts参数表示初始化配置项,该参数需要接收一个InitOpts类的对象from pyecharts.charts import Bar
bar = Bar()添加数据
bar.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
bar.add_yaxis("商家A", [5000, 2000, 3600, 1000, 7500, 900])添加图标配置项
- 全局配置项:
from pyecharts import options as opts
opts.TitleOpts(title="我是柱形图", subtitle="我是副标题")bar.set_global_opts(title_opts=opts.TitleOpts(
title="我是柱形图", subtitle="我是副标题"))- 系列配置项:
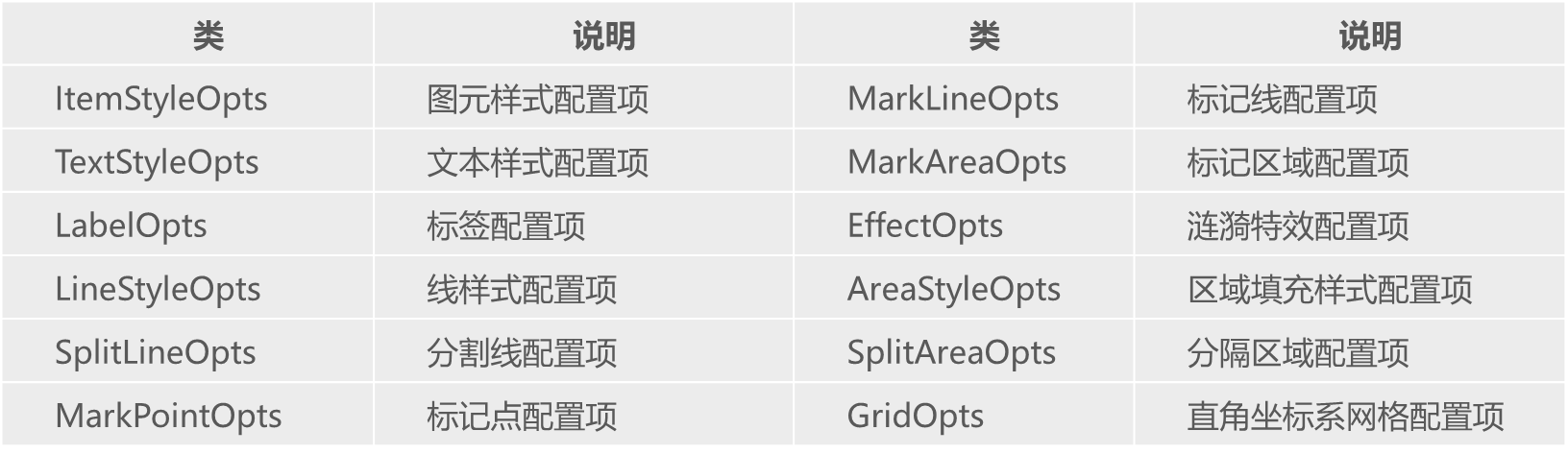
opts.LabelOpts(position='inside', color='white', font_size=10)
#标签会被标注于图形的里面
#标签文本的颜色为白色
#标签文本的字体大小为10号bar.add_yaxis("商家A", [5000, 2000, 3600, 1000, 7500, 900],
label_opts = opts.LabelOpts(position='inside',
color='white', font_size=10))- 显示:
bar.render_notebook()#渲染到Jupyter Notebook工具
map_chart.render("pie_chart.html")#渲染到HTML文件链式调用
简化对象的调用
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (
Bar()
.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子",
"高跟鞋", "袜子"])
.add_yaxis("商家A", [5000, 2000, 3600, 1000, 7500, 900],
label_opts=opts.LabelOpts(is_show=True,
position='inside', color='white', font_size=10))
.set_global_opts(title_opts=opts.TitleOpts(
title="我是柱形图", subtitle="我是副标题"))
)
bar.render_notebook()- 例子:
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.globals import ThemeType
# 创建 Map 对象
map_chart = Map(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
# 添加数据
data = [("China", 100000), ("United States", 50), ("Russia", 80), ("Brazil", 70), ("Australia", 90)]
# 设置全局配置选项
map_chart.add("World Map", data, maptype="world", label_opts=opts.LabelOpts(is_show=False))
map_chart.set_global_opts(
title_opts=opts.TitleOpts(title="世界地图示例"),
visualmap_opts=opts.VisualMapOpts(is_piecewise=True),
)
map_chart.render("pie_chart.html")绘制组合图表
并行多图 Grid()
from pyecharts.charts import Map,Bar,Pie,Grid
map_chart=()
bar_chart=()
grid = (
Grid() # GridOpts:直角坐标系网格配置项
.add(map_chart,
grid_opts=opts.GridOpts(pos_bottom="60%"), # grid 组件离容器下侧的距离
is_control_axis_index=True
)
.add(bar_chart,
grid_opts=opts.GridOpts(pos_bottom="10%", pos_top="60%",
pos_left="35%",pos_right="40%"),
is_control_axis_index=True
)
)
grid.render("map.html")add(
chart, # 表示图表,仅 `Chart` 类或者其子类
grid_opts, # 表示直角坐标系配置项
grid_index=0, # 表示直角坐标系网格索引,默认为0
is_control_axis_index=False # 表示是否由自己控制坐标轴索引
)# 直角坐标系配置项
class GridOpts(
# 是否显示直角坐标系网格。
is_show: bool = False,
# 所有图形的 zlevel 值。
z_level: Numeric = 0,
# 组件的所有图形的z值。
z: Numeric = 2,
# grid 组件离容器左侧的距离。
# left 的值可以是像 20 这样的具体像素值,可以是像 '20%' 这样相对于容器高宽的百分比,
# 也可以是 'left', 'center', 'right'。
# 如果 left 的值为'left', 'center', 'right',组件会根据相应的位置自动对齐。
pos_left: Union[Numeric, str, None] = None,
# grid 组件离容器上侧的距离。
# top 的值可以是像 20 这样的具体像素值,可以是像 '20%' 这样相对于容器高宽的百分比,
# 也可以是 'top', 'middle', 'bottom'。
# 如果 top 的值为'top', 'middle', 'bottom',组件会根据相应的位置自动对齐。
pos_top: Union[Numeric, str, None] = None,
# grid 组件离容器右侧的距离。
# right 的值可以是像 20 这样的具体像素值,可以是像 '20%' 这样相对于容器高宽的百分比。
pos_right: Union[Numeric, str, None] = None,
# grid 组件离容器下侧的距离。
# bottom 的值可以是像 20 这样的具体像素值,可以是像 '20%' 这样相对于容器高宽的百分比。
pos_bottom: Union[Numeric, str, None] = None,
# grid 组件的宽度。默认自适应。
width: Union[Numeric, str, None] = None,
# grid 组件的高度。默认自适应。
height: Union[Numeric, str, None] = None,
# grid 区域是否包含坐标轴的刻度标签。
is_contain_label: bool = False,
# 网格背景色,默认透明。
background_color: str = "transparent",
# 网格的边框颜色。支持的颜色格式同 backgroundColor。
border_color: str = "#ccc",
# 网格的边框线宽。
border_width: Numeric = 1,
# 本坐标系特定的 tooltip 设定。
tooltip_opts: Union[TooltipOpts, dict, None] = None,
)顺序多图 Page()
from pyecharts.charts import Map,Bar,Pie,Grid,Page
page = Page(layout=Page.SimplePageLayout)
page.add(bar_chart,pie_chart,map_chart)#之前定义的图标
page.render("page.html")Page(
page_title="Awesome-pyecharts", # 表示HTML网页的标题。
js_host= "", # 表示远程的主机地址,默认为"https://assets.pyecharts.org/assets/"。
interval=1, # 表示每个图例之间的间隔,默认为1。
layout=PageLayoutOpts() # 表示布局配置项。
)# 布局配置项
class PageLayoutOpts(
# 配置均为原生 CSS 样式
justify_content: Optional[str] = None,
margin: Optional[str] = None,
display: Optional[str] = None,
flex_wrap: Optional[str] = None,
)选项卡多图 Tab()
tab = (
Tab() # 创建Tab类对象
.add(
bar, # 图表类型
"柱形图" # 选项卡的标签名称
)
.add(line,"折线图")
)
# tab.render("./选项卡多图示例.html")
tab.render_notebook()Tab(
page_title="Awesome-pyecharts", # HTML 标题
js_host="" # 远程 HOST,默认为 "https://assets.pyecharts.org/assets/"
)add(
chart, # 任意图表类型
tab_name # 选项卡的标签名称
)时间线轮播图 Timeline()
# 绘制时间线轮播图
from pyecharts.faker import Faker
from pyecharts import options as opts
from pyecharts.charts import Bar,Timeline
x = Faker.choose() # 准备x轴数据
tl_demo = Timeline() # 创建Timeline类对象
for i in range(2015,2020):
bar = (
Bar() # 创建Bar类对象
.add_xaxis(x) # 横坐标的数据
.add_yaxis(
"商家A", # 图例
Faker.values() # 系列数据
)
.add_yaxis("商家B",Faker.values())
.set_global_opts(title_opts=opts.TitleOpts("某商店{}年营业额".format(i)) # 标题
)
)
tl_demo.add(
bar, # 图例
"{}年".format(i) # 时间线标签
)
tl_demo.render("./时间线轮播图示例.html")
tl_demo.render_notebook()- add_schema()用于为图表添加指定样式的时间线,其语法格式如下所示:
add_schema(
axis_type="category", # 表示坐标轴的类型1,可以取值为'value'(数值轴)、
# 'category'(类目轴)、'time'(时间轴)、'log'(对数轴)
orient="horizontal", # 表示时间线的类型,可以取值为'horizontal'(水平)和'vertical(垂直)。
play_interval=None, # 表示播放的速度(跳动的间隔),单位为ms。
is_auto_play=False, # 表示是否自动播放,默认为False
is_loop_play=True, # 表示是否循环播放,默认为True
is_rewind_play=False, # 表示是否反向播放,默认为False
is_timeline_show=True, # 表示是否显示时间线组件,默认为True,如果设置为 false,不会显示,但是功能还存在。
is_inverse=False, # 是否反向放置 时间线,反向则首位颠倒过来
symbol=None, # timeline 标记的图形。# ECharts 提供的标记类型包括 'circle', 'rect', 'roundRect', 'triangle', 'diamond',.
symbol_siz =None, # timeline 标记的大小,例如 [20, 10] 表示标记宽为 20,高为 10。
control_position="left", # 表示播放按钮的位置。可选值:'left'、'right'。
width=None, # 时间轴区域的宽度, 影响垂直的时候时间轴的轴标签和轴之间的距离
height=None, # 时间轴区域的高度
pos_left=None,# Timeline 组件离容器左侧的距离。
# left 的值可以是像 20 这样的具体像素值,可以是像 '20%' 这样相对于容器高宽的百分比,
# 也可以是 'left', 'center', 'right'。
# 如果 left 的值为'left', 'center', 'right',组件会根据相应的位置自动对齐
# pos_right、pos_top、pos_bottom
linestyle_opts=None, # 时间轴的坐标轴线配置,
controlstyle_opts= None,# 控制按钮』的样式。『控制按钮』包括:『播放按钮』、『前进按钮』、『后退按钮』。
)add(
chart, # 表示图表
time_point # 表示时间点
)WordCloud
from wordcloud import WordCloud
import matplotlib.pyplot as plt
graph=plt.imread('ball.jpg')
wc=WordCloud(width=600,height=400,max_font_size=150,margin=5,background_color='white',random_state=False,mask=graph)
#法1:
wc.fit_words(frequency)#传入 词频/权重 字典
#法2:
wc.generate(text)#传入文本(空格分词)
plt.imshow(wc)
plt.axis('off')#关闭坐标轴
wc.to_file('result/result.png') # 词云保存为图片
plt.show()class
wordcloud.WordCloud(font_path=None, # 字体路径(默认为 wordcloud 库下的 DroidSansMono.ttf 字体)。
width=400, # 画布宽度(默认为400像素)。
height=200, # 画布高度(默认为200)。
margin=2, # 每个单词间的间隔 (默认为2)
ranks_only=None,
prefer_horizontal=0.9, # 词语水平方向排版出现的频率(默认为0.9。因为水平排版和垂直排版概率之和为 1,所以默认垂直方向排版为0.1。)
mask=None, # nd-array or None (default=None), 可简单理解为绘制模板。当 mask 不为 0 时,“画布”形状大小由 mask 决定,height 和 width 设置无效。
scale=1, # float (default=1)。计算和绘图之间的比例(就是放大画布的尺寸,也可以叫比例尺)。对于大型词云图,使用比例尺比设置画布尺寸会更快,但是单词匹配不是很好。
color_func=None,
max_words=200, # number (default=200) 最大显示单词字数。
max_font_size=None, # int or None (default=None) 最大单词的字体大小,如果没有设置的话,直接使用画布的大小。
min_font_size=4,
stopwords=None, # set of strings or None (停用词,被淘汰不用于显示的词语,默认使用内置的 stopwords)。
random_state=None,
background_color='black', # color value (default=”black”) (词云图像的背景色,默认为黑色。)
font_step=1, mode='RGB',
relative_scaling='auto', # float (default=’auto’) 词频大小对字体大小的影响度。如果设置为1的话,如果一个单词出现两次那么其字体大小为原来 的两倍。
regexp=None, # string or None (optional) 使用正则表达式分割输入的字符。没有指定的话就使用r"\w[\w']+"。
collocations=True, # bool, default=True 是否包括两个词的搭配(双宾语)
colormap=None, # string or matplotlib colormap, default=”viridis”。颜色映射方法,每个单词对应什么颜色,就是根据这个colormap的。如果设置 color_func ,则设置的这个作废。
normalize_plurals=True,
contour_width=0,
contour_color='black',
repeat=False, # bool, default=False 是否需要重复单词以使得总单词数量达到max_words。
)| 方法名 | 使用场景 |
| fit_words(frequencies) | 根据词频生成词云,参数为包含词与词频的字典,为generate_from_frequencies的别名 |
| generate(text) | 根据文本生成词云,是generate_from_text的别名 |
| generate_from_frequencies(frequencies) | 根据词频生成词云,参数为词频字典 |
| generate_from_text(text) | 根据文本生成词云,如果参数是排序的列表,需设置'collocations=False',否则会导致每个词出现2次。 |
| process_text(text) | 将英文长文本text分词并去除屏蔽词后生成词云。 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









